First of all, what do we need to know about the process?

Narrow sense: a process is an ongoing program
Generalized: it is the basic unit of operating system allocation
Program: it is an inanimate entity waiting for the processor to give life. Once the program has life, it becomes a process.
Differences between procedures and processes:
1. Program is an ordered collection of instructions and data. It has no meaning in itself. It is a static resource.
Process is an execution process of a program in the system.
2. Programs can exist as software for a long time, and processes have a certain life cycle.
Process 3 status:
Ready status: the running conditions have been met and are waiting for CPU execution Execution status: the CPU is executing the function of the actuator Waiting status: wait for certain conditions to be met
With a preliminary understanding of the process, how to create a process?
import time
# Guide Package
import multiprocessing
def test1():
while True:
print("Big fool")
time.sleep(1)
def test2():
while True:
print("Little fat hand")
time.sleep(1)
# Define a main function to execute the code of two processes respectively
def main():
# Create test1 and test2 processes respectively, and the value of target represents the process to be executed
p1 = multiprocessing.Process(target=test1)
p2 = multiprocessing.Process(target=test2)
# Start p1 and p2
p1.start()
p2.start()
# General writing method of program entry:
if __name__ == "__main__":
main()Here, we introduce a concept of parallelism and concurrency
Let's take an example, for example, the two of us are having lunch. In the whole process of eating, you ate rice, vegetables and beef. Eating rice, vegetables and beef are actually executed concurrently. For you, the whole process seems to be completed at the same time. But you actually switch back and forth between eating different things.
Or the two of us for lunch. During the meal, you ate rice, vegetables and beef. I also had rice, vegetables and beef. The meal between us is parallel. Two people can eat beef together at the same time, or one can eat beef and the other can eat vegetables. There is no interaction between them.
See here, is it still a little confused? Let's look at another picture and intuitively feel the difference between the two
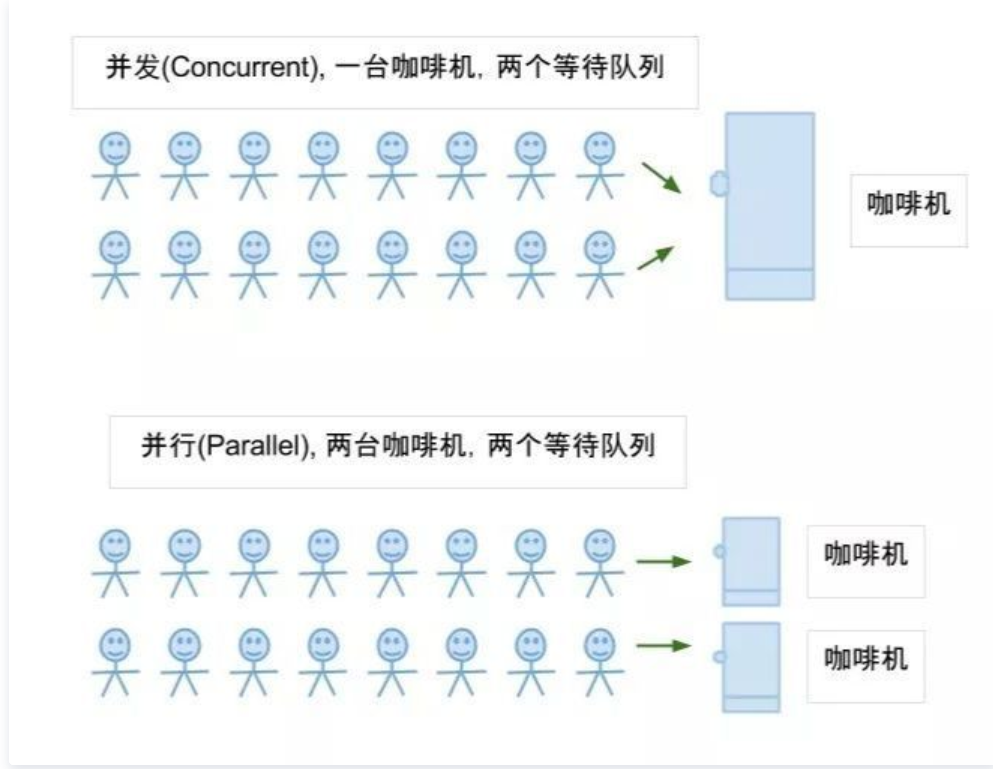
As can be seen from the above,
Parallel: multiple tasks are executed simultaneously at the same time
Concurrency: multiple tasks are executed at the same time
The difference between parallelism and Concurrency:
Microcosmic: parallelism means that multiple tasks are executed at the same time
Macroscopically: concurrency refers to the stop and go of multiple tasks in a period of time
There are processes, of course, there are sub processes. Let's implement it in code!
# Guide Package
# import time
# from multiprocessing import Process
# Create function -- child process
def work1():
while True:
print("I'm a child, hee hee")
time.sleep(1)
# Program entry
if __name__ == "__main__":
# Create child process object
p1 = Process(target=work1)
# start-up
p1.start()
while True:
print("I am the main process, hahaha")
time.sleep(1)
Learn more about process Parameter Description: target: if a function reference is passed, it can be considered to execute the code of the child process args: pass parameters to the function specified by target. The parameters are passed in tuples. If there is only one value in the tuple, you need to add a comma kwargs: pass parameters to the function specified by target in the form of dictionary Name: name the process Group: Specifies the process group
import time
from multiprocessing import Process
# Create function -- child process
def work1(*args,**kwargs):
while True:
print(args)
print(kwargs)
time.sleep(1)
# Program entry
if __name__ == "__main__":
# Create child process object
p1 = Process(target=work1,args=("Big wood",19),kwargs={"Gender":"male"})
# start-up
p1.start()
while True:
print("Big wood second goods, ha ha ha")
time.sleep(1)Note: 1. When you right-click run, a process will be created, which is called the main process
2. work1 created in the program is a child process
3. You need to use the target parameter and the start() method when creating and starting a process
4. Judge whether args and kwargs parameters need to be passed in process according to the meaning of the question
Note: program entry must be written
Common methods for creating Process instance objects: Start: start the child process Terminate: terminate the child process immediately regardless of whether it is considered complete or not join ([timeout]): whether to wait for the child process to finish before executing the main process, or how many seconds to wait is_alive: determine whether the child process is still alive Common properties for creating Process instance objects: Name: process name pid: ID of the process -- pid multiprocessing is a module
Now that we have a basic understanding of processes, how do processes communicate?
# Data isolation between processes
# Define a list of global variables
lst = [11,22]
# Guide Package
import multiprocessing
import time
# The first process adds data to the list
def work1():
for i in range(3):
lst.append(i)
time.sleep(1)
print(lst)
# The second process makes no changes to the list
def work2():
print(lst)
# Program entry
if __name__ == '__main__':
p1 = multiprocessing.Process(target=work1)
p1.start()
# join ([timeout]): whether to wait for the child process to finish before executing the main process, or how many seconds to wait
# Let p1 execute the process and then execute p2
p1.join()
p2 = multiprocessing.Process(target=work2)
p2.start()
# Output result: [11, 22, 0]
# [11, 22, 0, 1]
# [11, 22, 0, 1, 2] results after process 1 operation
# [11, 22] results after process 2 operation
# Summary: data between processes is isolated, and global variables cannot be shared between processesQueue: a data structure Features: first in first out When full data is stored again, blocking will occur When all the data has been fetched, there will be blocking when you continue to fetch data
import multiprocessing
ret = multiprocessing.Queue(3) #The queue has 3 values
#Save data put
ret.put(11)
ret.put("22")
ret.put({"Xiao Ming":"white and fat"})
# Check whether it is full
# print(ret.full())
# Check whether it is empty
# print(ret.empty())
# get data
print(ret.get()) #11
print(ret.get()) #22
print(ret.get()) #[11,22]
# print(ret.get()) #block
# get_nowait tells us that the data has been retrieved in an abnormal way
print(ret.get_nowait())Next, let's take a look at the process pool!
Process pool: when you need to create multiple processes, such as thousands of processes, it takes a lot of time to manually create them using process
Synchronous and asynchronous: there are two ways to submit tasks
Synchronization: wait in place after submitting the task, and do not proceed to the next line of code until the return value of the task is obtained
Asynchronous: after submitting the code, do not wait in place and proceed directly to the next time
Blocking and non blocking:
Blocking: once a program is blocked, it will stop in place and immediately release CPU resources
Non blocking: even if I/O is blocked, it will not stop in place
# Define a pool. There are a fixed number of processes in the pool. There is a demand,
# Add a task to the process pool. If the task is full, you need to wait
import multiprocessing
import os
import time
# Create process
def func(data):
print("process%s--Print incoming parameters%s" %(os.getpid(),data))
time.sleep(1)
# Program entry:
if __name__ == '__main__':
# The create process pool parameter represents the maximum number of processes
po = multiprocessing.Pool(3)
for i in range(10):
# po.apply(func,args=(i,))
po.apply_async(func,args=(i,))
print("I am the main process")
po.close()
po.join()Apply and apply_ Differences between async submission methods: apply: synchronous commit is executed sequentially apply_async: asynchronous submission tasks are asynchronous
Today, we learned about processes, sub processes, inter process communication and process pool. In the next section, we continue to learn threads. Bye!
