Hello, I'm Xiao Hei, a migrant worker who lives on the Internet.
A new Fork/Join thread pool is introduced in JDK1.7, which can split a large task into multiple small tasks for parallel execution and summarize the execution results.
Fork/Join adopts the basic idea of divide and conquer. Divide and conquer is to divide a complex task into multiple simple small tasks according to the specified threshold, and then summarize and return the results of these small tasks to get the final task.
Divide and conquer
Divide and conquer is one of the commonly used algorithms in the computer field. The main idea is to decompose a problem with scale N into K smaller subproblems, which are independent of each other and have the same properties as the original problem; The solution of the subproblem is solved and combined to obtain the solution of the original problem.
Ideas for solving problems
- Split the original problem;
- Solving subproblems;
- The solution of the merged subproblem is the solution of the original problem.
Usage scenario
Binary search, factorial calculation, merge sort, heap sort, fast sort and Fourier transform all use the idea of divide and conquer.
ForkJoin parallel processing framework
The ForkJoinPool thread pool introduced in JDK1.7 is mainly used for the execution of ForkJoinTask tasks. ForkJoinTask is a thread like entity, but it is lighter than ordinary threads.
Let's use the ForkJoin framework to complete the following 100-1 billion summation code.
public class ForkJoinMain {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinTask<Long> rootTask = forkJoinPool.submit(new SumForkJoinTask(1L, 10_0000_0000L));
System.out.println("Calculation results:" + rootTask.get());
}
}
class SumForkJoinTask extends RecursiveTask<Long> {
private final Long min;
private final Long max;
private Long threshold = 1000L;
public SumForkJoinTask(Long min, Long max) {
this.min = min;
this.max = max;
}
@Override
protected Long compute() {
// Calculate directly when it is less than the threshold
if ((max - min) <= threshold) {
long sum = 0;
for (long i = min; i < max; i++) {
sum = sum + i;
}
return sum;
}
// Split into small tasks
long middle = (max + min) >>> 1;
SumForkJoinTask leftTask = new SumForkJoinTask(min, middle);
leftTask.fork();
SumForkJoinTask rightTask = new SumForkJoinTask(middle, max);
rightTask.fork();
// Summary results
return leftTask.join() + rightTask.join();
}
}
The above code logic can be more intuitively understood through the following figure.
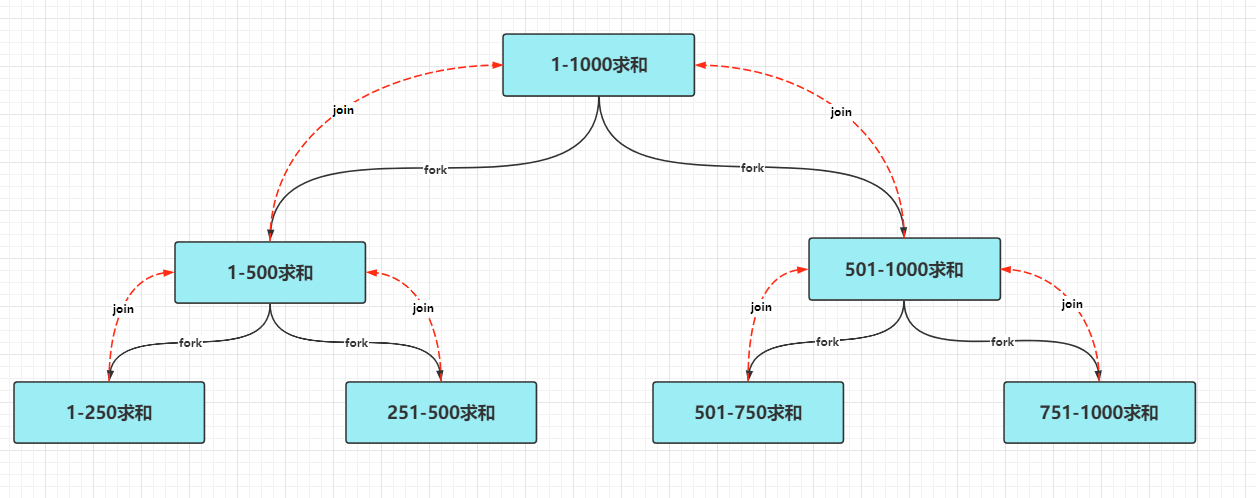
ForkJoin framework implementation
Some important interfaces and classes in the ForkJoin framework are shown in the figure below.
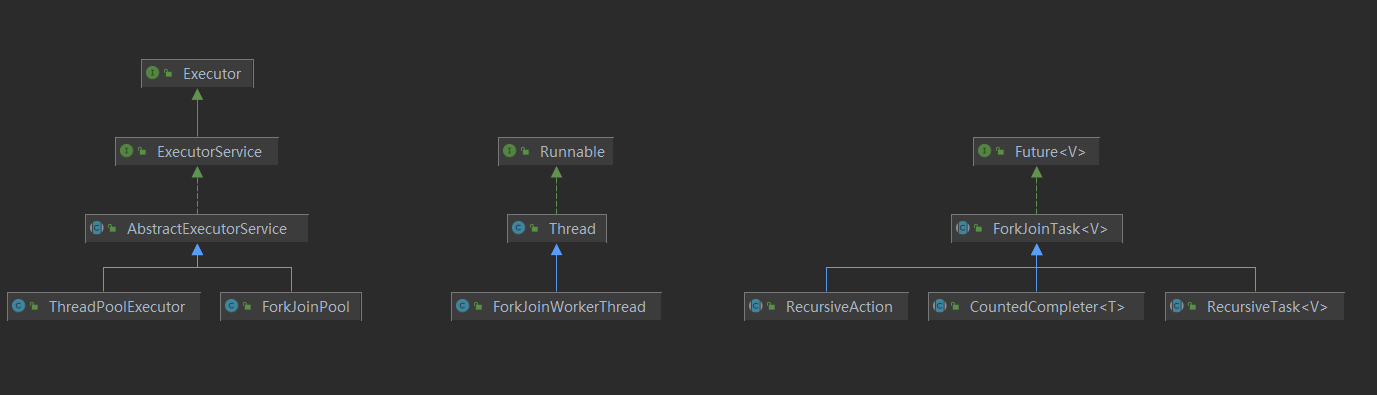
ForkJoinPool
ForkJoinPool is a thread pool used to run ForkJoinTasks and implements the Executor interface.
You can create a ForkJoinPool object directly through new ForkJoinPool().
public ForkJoinPool() {
this(Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors()),
defaultForkJoinWorkerThreadFactory, null, false);
}
public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
boolean asyncMode){
this(checkParallelism(parallelism),
checkFactory(factory),
handler,
asyncMode ? FIFO_QUEUE : LIFO_QUEUE,
"ForkJoinPool-" + nextPoolId() + "-worker-");
checkPermission();
}
By looking at the source code of the construction method, we can find that when creating ForkJoinPool, there are the following four parameters:
- parallelism: expected number of concurrencies. The value of Runtime.getRuntime().availableProcessors() is used by default
- Factory: the factory that creates ForkJoin worker threads. The default is defaultForkJoinWorkerThreadFactory
- Handler: the handler when an unrecoverable error is encountered during task execution. It is null by default
- asyncMode: whether the worker thread uses FIFO mode or LIFO mode to obtain tasks. The default is LIFO
ForkJoinTask
ForkJoinTask is an abstract class definition for running tasks in ForkJoinPool.
A large number of tasks and subtasks can be processed through a small number of threads. ForkJoinTask implements the Future interface. It mainly arranges asynchronous task execution through fork() method, and waits for the result of task execution through join() method.
If you want to use ForkJoinTask to handle a large number of tasks with a small number of threads, you need to accept some restrictions.
- Avoid synchronization methods or synchronization code blocks in split tasks;
- Avoid blocking I/O operations in subdivided tasks, ideally based on variables accessed completely independent of other running tasks;
- It is not allowed to throw a checked exception in a subdivision task.
Because ForkJoinTask is an abstract class and cannot be instantiated, the JDK provides us with three specific types of ForkJoinTask parent classes for us to inherit and use when customizing.
- RecursiveAction: the subtask does not return results
- Recursive task: results returned by subtasks
- Counterdcompleter: the execution will be triggered after the task is completed
ForkJoinWorkerThread
The thread in the ForkJoinPool that executes the ForkJoinTask.
Since ForkJoinPool implements the Executor interface, what is the difference between it and the ThreadPoolExecutor we commonly use?
If we use ThreadPoolExecutor to complete the logic of divide and conquer, each subtask needs to create a thread. When the number of subtasks is large, it may reach tens of thousands of threads, so it is obviously infeasible and unreasonable to use ThreadPoolExecutor to create tens of thousands of threads;
When ForkJoinPool processes tasks, it does not start threads according to the task, but only creates threads according to the specified expected parallel number. When each thread works, if you need to continue to disassemble molecular tasks, the current task will be placed in the task queue of ForkJoinWorkerThread and processed recursively until the outermost task.
Job theft algorithm
Each working thread of ForkJoinPool will maintain its own task queue to reduce the task competition between threads;
Each thread will first ensure that the tasks in its own queue are executed. When its own tasks are executed, it will check whether there are unfinished tasks in the task queue of other threads. If so, it will help other threads execute;
In order to reduce competition when helping other threads execute tasks, dual ended queues will be used to store tasks. The stolen tasks will only get tasks from the head of the queue, while the normal processing threads get tasks from the tail of the queue every time.
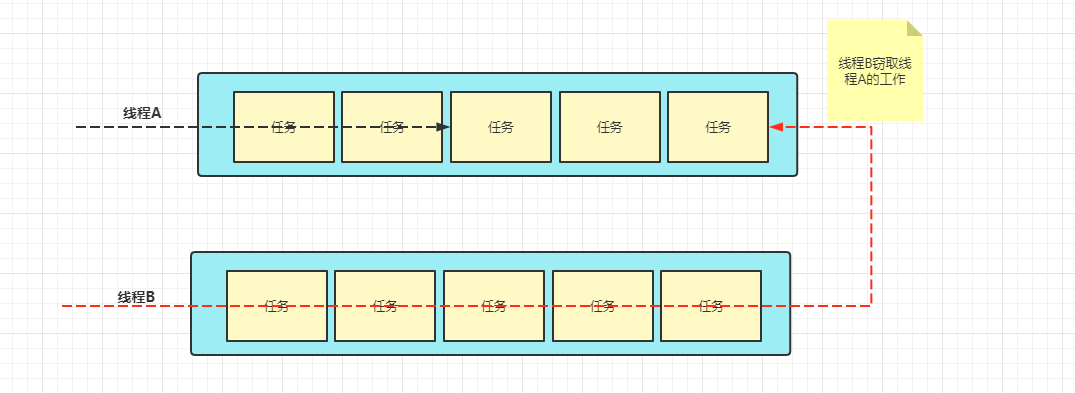
advantage
It makes full use of thread resources, avoids the waste of resources, and reduces the competition between threads.
shortcoming
You need to open up a queue space for each thread; In work queue java Tutorial There is also thread contention when there is only one task in the.