JDK1.7
First, the data is stored section by section, and then each section of data is equipped with a lock. When a thread occupies the lock to access one section of data, the data of other sections can also be accessed by other threads.
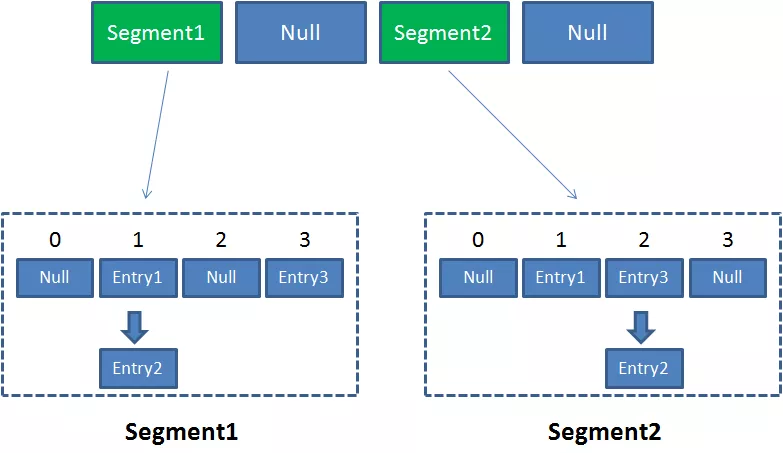
ConcurrentHashMap is composed of Segment array structure and HashEntry array structure.
Segment is a reentrant lock, which plays the role of lock in concurrent HashMap; HashEntry is used to store key value pair data.
A concurrent HashMap contains an array of segments. The structure of segments is similar to that of HashMap. It is an array and linked list structure. A Segment contains a HashEntry array. Each HashEntry is an element of a linked list structure. Each Segment guards the elements in a HashEntry array. When modifying the data of the HashEntry array, you must first obtain the corresponding Segment lock.
It can be said that ConcurrentHashMap is a secondary hash table. Under a general hash table, there are several sub hash tables (segments).
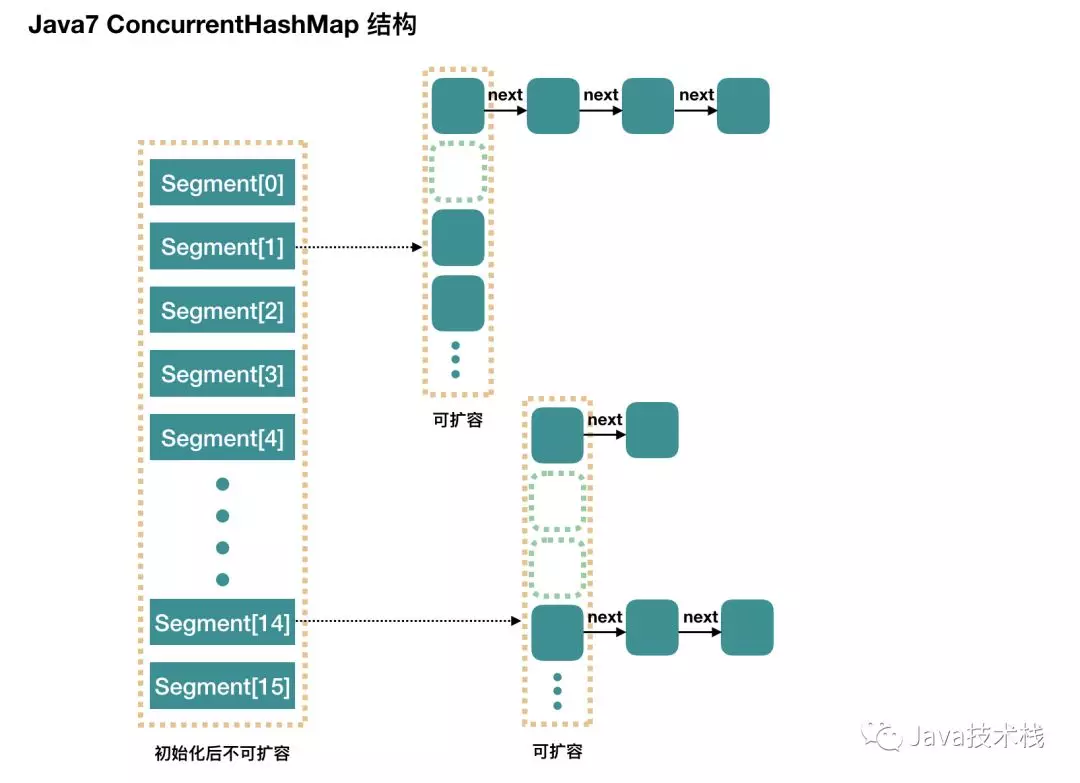
Advantages: multiple threads access different segments without conflict, which can improve efficiency
Disadvantages: the default size of the Segment array is 16. This capacity cannot be changed after initialization, and it is not lazy loading
initialization
- initialCapacity: initial capacity, that is, the number of hashentries. The default value is 16
- loadFactor: load factor, which is 0.75 by default
- concurrencyLevel: concurrency level. This value is used to determine the number of segments. The number of segments is the first one greater than or equal to the concurrencyLevel 2 n 2^n 2n. For example, if the concurrencyLevel is 12, 13, 14, 15, 16, the number of segments is 16 (the fourth power of 2). The default value is 16. Ideally, the real concurrent access volume of ConcurrentHashMap can reach concurrentlevel, because there are concurrentlevel segments. If there are concurrentlevel threads that need to access the Map, and the data to be accessed just fall in different segments, these threads can access freely without competition (because they do not need to compete for the same lock), Achieve the effect of simultaneous access. This is why this parameter is called "concurrency level".
If initialCapacity=64 and concurrencyLevel=16, the HashEntry capacity under each Segment is 64 / 16 = 4.
By default, the HashEntry capacity under each Segment is 16 / 16 = 1.
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
// Verify the validity of parameters
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
// concurrencyLevel, that is, the number of segments cannot exceed the specified maximum number of segments. The default value is static final int max_ SEGMENTS = 1 << 16;, If this value is exceeded, set it to this value
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
int sshift = 0;
int ssize = 1;
// Use the loop to find the number ssize greater than or equal to the n-th power of the first 2 of the concurrencyLevel. This number is the size of the Segment array
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// Calculate the average number of elements that should be placed in each Segment. For example, if the initial capacity is 15 and the number of segments is 4, an average of 4 elements need to be placed in each Segment
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0);
this.segments = ss;
}
get()
The get() method does not lock, but uses UNSAFE.getObjectVolatile() to ensure visibility
- Get the hash value of the input key
- Locate the corresponding Segment object through the hash value
- Again, through the hash value, locate the HashEntry object corresponding to the Segment
- Search in this HashEntry (similar to the search method of HashMap)
public V get(Object key) {
Segment<K,V> s;
HashEntry<K,V>[] tab;
int h = hash(key);
// u is the subscript of the Segment object
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
// s is the Segment object
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
// e is the HashEntry located
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
put()
- Get the hash value of the input key
- Locate the corresponding Segment object through the hash value
- Obtain the reentrant lock and locate the specific location of HashEntry in the Segment (enter the get() method of the Segment)
- Insert (header insert) or overwrite the HashEntry object (similar to the addition method of HashMap in JDK1.7)
- Release lock
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
// Get the hash value of the input key
int hash = hash(key);
// Calculate the subscript of Segment
int j = (hash >>> segmentShift) & segmentMask;
// Locate the corresponding Segment object and judge whether it is null. If so, create a Segment
if ((s = (Segment<K,V>)UNSAFE.getObject
(segments, (j << SSHIFT) + SBASE)) == null)
// CAS ensures that segment s are not created repeatedly
s = ensureSegment(j);
// Enter the put() process of Segment
return s.put(key, hash, value, false);
}
JDK1.8
The implementation of ConcurrentHashMap in 1.8 has basically changed compared with the version of 1.7. Firstly, the data structure of Segment lock is cancelled and replaced by the structure of array + linked list + red black tree. For the granularity of locks, it is adjusted to lock each array element (chain header / tree root Node). Then the hash algorithm for locating nodes is simplified, which will aggravate the hash conflict. Therefore, when the number of linked list nodes is greater than 8, the linked list will be transformed into a red black tree for storage. In this way, the time complexity of the query will change from O(n) to O(logN). The following is its basic structure:
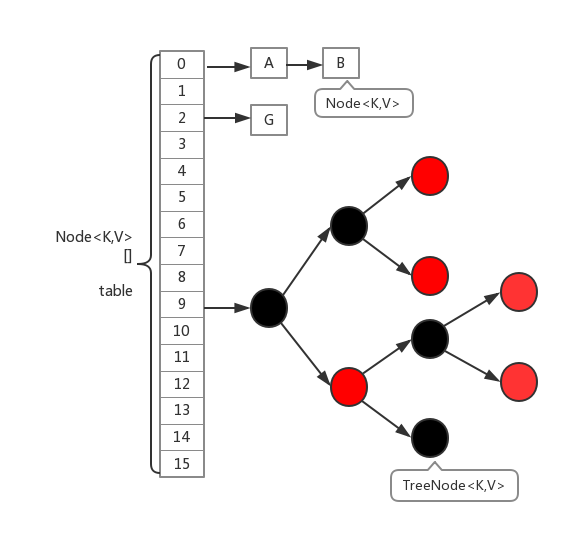
Important properties and inner classes
// The default is 0
// - 1 at initialization
// During capacity expansion - (1 + number of capacity expansion threads)
// After initialization or capacity expansion is completed, it is the threshold size of the next capacity expansion
private transient volatile int sizeCtl;
// The entire ConcurrentHashMap is an array table of Node type
static class Node<K,V> implements Map.Entry<K,V> {}
// Lazy loading, responsible for storing Node nodes
transient volatile Node<K,V>[] table;
// New array during capacity expansion
private transient volatile Node<K,V>[] nextTable;
initialization
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
// When the initial capacity is less than the concurrency, the initial capacity will be changed to the concurrency
if (initialCapacity < concurrencyLevel)
initialCapacity = concurrencyLevel;
// Lazy loading, only the capacity of the array is calculated in the constructor, and it will be created only when it is used for the first time later (put())
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
// tableSizeFor() guarantees that the array capacity is 2^n
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
get()
There is no need to lock the whole process of get() because the value of the Node object is decorated with volatile (volatile V val)
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
// spread() ensures that the returned result is a positive integer
int h = spread(key.hashCode());
// The index of the array where the positioning chain header is located
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
// If the header node is the key to find, directly return value
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// In the process of capacity expansion or linked list tree, go to the new linked list or red black tree to find it
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
// Follow the list to find it normally
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
put()
- Locate the bucket directly through the hash, and judge after getting the first node
- If the array is empty, CAS initializes the array first (lazy loading)
- If the first node is empty, CAS will be inserted
- If the hash of the first node is - 1, it indicates that the capacity is being expanded, and it is helpful to expand the capacity
- Otherwise, lock the first node and add it after the linked list (or tree)
public V put(K key, V value) {
return putVal(key, value, false);
}
// onlyIfAbsent: whether to choose to overwrite the old value with the new value
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
// f is the head node of the linked list
// fh is the hash of the chain header node
// i is the subscript of the linked list in the table array
Node<K,V> f; int n, i, fh;
// At this time, the table array has not been initialized (lazy loading)
if (tab == null || (n = tab.length) == 0)
// CAS initialization
tab = initTable();
// The first node is null
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// CAS to add
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break;
}
// Help expand capacity
// static final int MOVED = -1;
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
// Lock the first node and then add it after the linked list (or tree)
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
difference
The data structure of concurrent HashMap in JDK1.8 is close to HashMap. Relatively speaking, concurrent HashMap in JDK1.8 only adds synchronous operations to control concurrency.
JDK1.7: ReentrantLock + Segment + HashEntry
JDK1.8: synchronized + CAS + HashEntry + Node
- The implementation of JDK1.8 reduces the granularity of locks. The granularity of JDK1.7 locks is based on Segment and contains multiple hashentries, while the granularity of JDK1.8 locks is HashEntry (first node)
- The data structure of JDK1.8 becomes simpler, making the operation clearer and smoother. Because synchronized has been used for synchronization, the concept of Segment lock is not required, and the data structure of Segment is not required. However, due to the reduction of granularity, the complexity of implementation is also increased
- JDK1.8 uses the red black tree to optimize the linked list. The traversal based on the long linked list is a long process, and the traversal efficiency of the red black tree is very fast. Instead of the linked list with a certain threshold, it forms an optimal partner
- JDK1.8 why use the built-in lock synchronized to replace the reentrant lock ReentrantLock: because the granularity is reduced, synchronized is no worse than ReentrantLock in the relatively low granularity locking mode. In coarse granularity locking, ReentrantLock may control the boundaries of each low granularity through Condition, which is more flexible. In low granularity, the advantage of Condition is lost
- The JVM development team has never given up on synchronized, and the JVM based synchronized optimization has more space. It is more natural to use embedded keywords than API s
- Under a large number of data operations, for the memory pressure of the JVM, the ReentrantLock based on API will cost more memory. Although it is not a bottleneck, it is also a basis for selection