Concurrent SkipListMap Concurrent Container
1. The underlying data structure of Concurrent SkipListMap
To learn Concurrent SkipListMap, first of all, we need to know what is the SkipList, an upgraded version of the linked list of jump lists, and it is orderly. In addition, the jump table is a hierarchical structure (whose time complexity is O(n)=log2n), which is comparable to the balanced binary tree in search, add or delete efficiency. More importantly, the implementation of the jump table is much simpler and clearer.
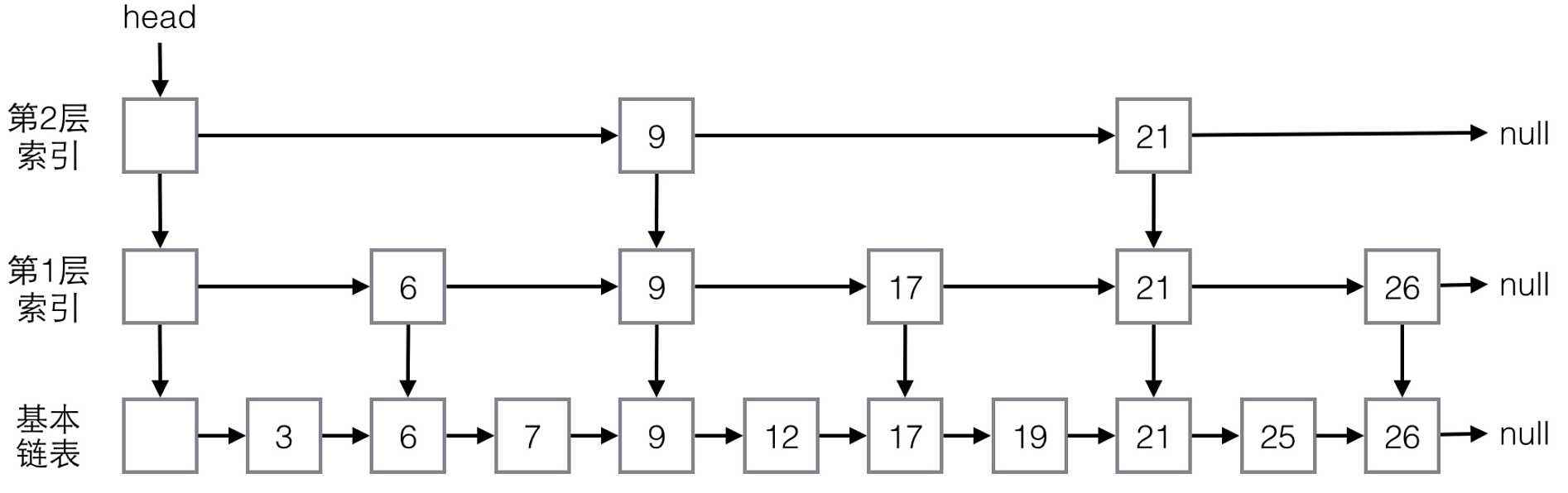
The graph above is a hierarchical structure of a jump table, which has the following characteristics:
1. The jump table is divided into several layers, and the higher the level, the greater the jumping ability.
2. The bottom list of the jump table contains all the data.
3. Jump tables are orderly.
4. The header node of the jump table always points to the first element at the highest level.
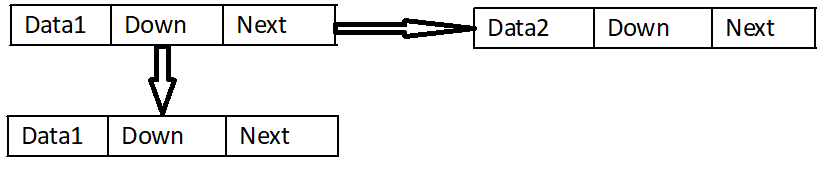
Next, let's look at the structure of index nodes in jump tables: they are generally divided into three regions: two pointer domains and one data storage area; two pointer domains are the next pointer to the next index at the same level, and the down pointer to the next level with the same data, as shown in the figure below.
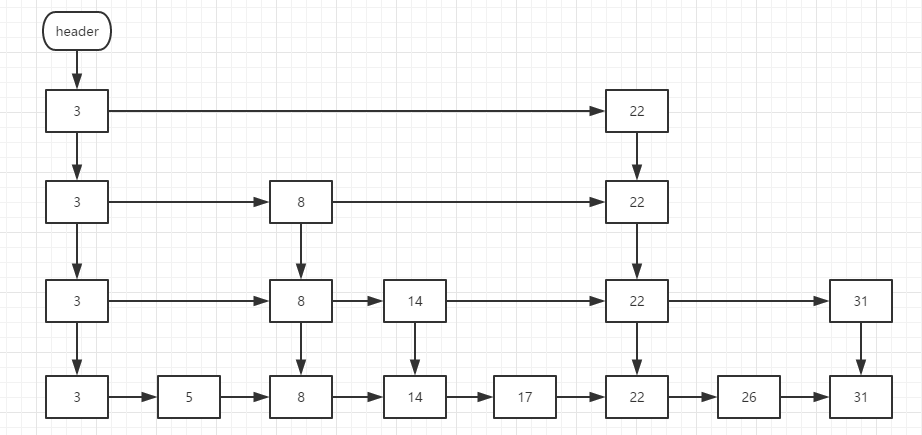
The look-up of jump tables is much simpler and clearer, starting from the head pointer of the highest level, such as look-up 14 in the figure below, start from the top 3, 14 is greater than 3, and look for the next 22, 14 is less than 22, indicating that there is no 14 number in the highest level. Entering the next level, 14 to 8, and 22 novels show that there is no such element in this layer. Entering the next level. Look back at Big 8 and find 14.
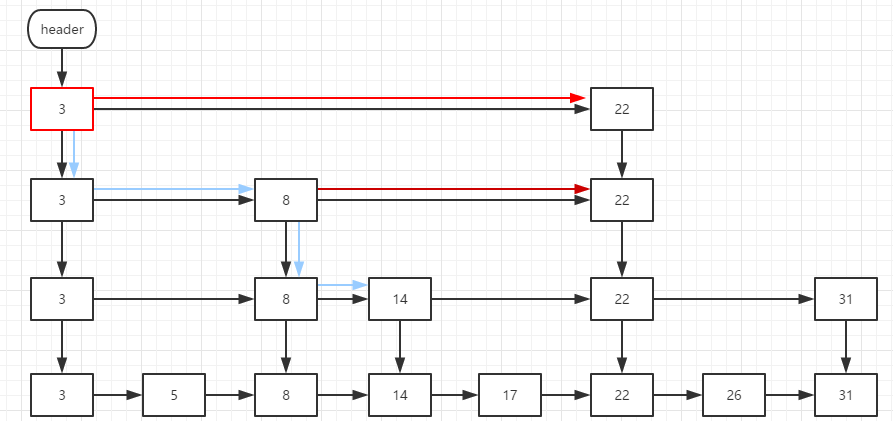
The following figure shows the search route of 14. The red line indicates the route that is larger than 14 after comparison and does not enter the index.
2. Realization of Bottom Jump Table
Definition of Node, the lowest link node:
static final class Node<K,V> { final K key; //Storage key volatile Object value; //Storage value volatile Node<K,V> next; //Next node Node(K key, Object value, Node<K,V> next) { this.key = key; this.value = value; this.next = next; } Node(Node<K,V> next) { this.key = null; this.value = this; this.next = next; } //Insecure operation variables for implementing CAS operations private static final sun.misc.Unsafe UNSAFE; //value memory address offset private static final long valueOffset; //Memory address offset at the next node private static final long nextOffset; static { try { UNSAFE = sun.misc.Unsafe.getUnsafe(); Class<?> k = Node.class; valueOffset = UNSAFE.objectFieldOffset (k.getDeclaredField("value")); nextOffset = UNSAFE.objectFieldOffset (k.getDeclaredField("next")); } catch (Exception e) { throw new Error(e); } } }
Definition of Index:
static class Index<K,V> { final Node<K,V> node; //Reference of nodes in linked list final Index<K,V> down; //Index to the next level volatile Index<K,V> right; //Index on the right Index(Node<K,V> node, Index<K,V> down, Index<K,V> right) { this.node = node; this.down = down; this.right = right; } //Unsafe operational variables private static final sun.misc.Unsafe UNSAFE; private static final long rightOffset; //right memory offset static { try { UNSAFE = sun.misc.Unsafe.getUnsafe(); Class<?> k = Index.class; rightOffset = UNSAFE.objectFieldOffset (k.getDeclaredField("right")); } catch (Exception e) { throw new Error(e); } } }
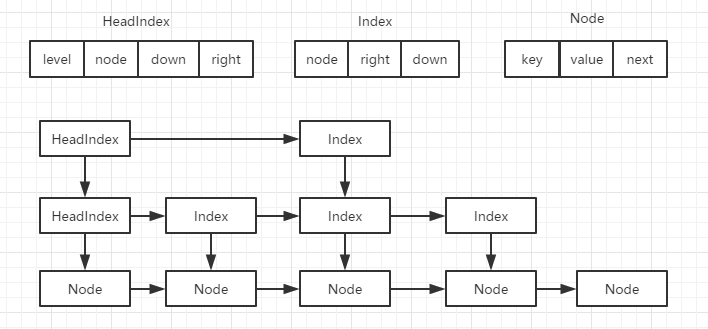
HeadIndex is a definition specifically used at the header node of each level. It inherits Index and adds a level attribute representing the level of each level.
static final class HeadIndex<K,V> extends Index<K,V> { final int level; //Hierarchical index HeadIndex(Node<K,V> node, Index<K,V> down, Index<K,V> right, int level) { super(node, down, right); this.level = level; } }
The relationship between HeadIndex, Index and Node is shown in the following figure:
3. Inheritance of Concurrent SkipListMap
The inheritance relationship of Concurrent SkipListMap is shown in the following figure. It inherits the AbstractMap class and implements it.
Concurrent Navigable Map and
ConcurrentMap interface. So, Concurrent SkipListMap must be an orderly, concurrent, safe and scalable set of Maps.
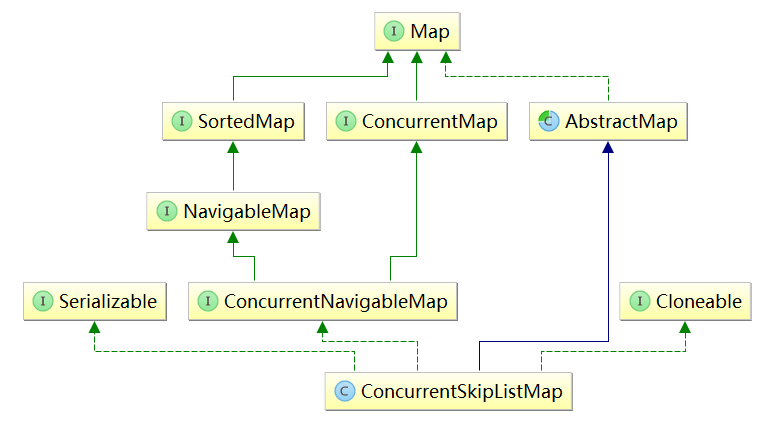
Previously, most of the interfaces and abstract classes in the above figure have been learned in the process of learning data structure and source code, only one of them has been learned.
Concurrent Navigable Map interface is not known:
public interface ConcurrentNavigableMap<K,V> extends ConcurrentMap<K,V>, NavigableMap<K,V> { //Return to the submap of the current map, which intercepts the subset from fromKey to toKey, from Inclusive and to Inclusive //Represents whether two critical key pairs, fromKey and toKey, are included in a subset ConcurrentNavigableMap<K,V> subMap(K fromKey, boolean fromInclusive, K toKey, boolean toInclusive); //Returns a subset not larger than toKey, and whether to include toKey is determined by inclusive ConcurrentNavigableMap<K,V> headMap(K toKey, boolean inclusive); //Returns a subset not less than fromKey, and whether to include fromKey is determined by inclusive ConcurrentNavigableMap<K,V> tailMap(K fromKey, boolean inclusive); //Returns a subset of about fromKey and less than or equal to toKey ConcurrentNavigableMap<K,V> subMap(K fromKey, K toKey); //Returns a subset less than toKey ConcurrentNavigableMap<K,V> headMap(K toKey); //Returns a subset greater than or equal to fromKey ConcurrentNavigableMap<K,V> tailMap(K fromKey); //Returns a map whose order is reverse (i.e., the original positive order Map is reverse-ordered) ConcurrentNavigableMap<K,V> descendingMap(); //Returns the set set set set of all key s public NavigableSet<K> navigableKeySet(); //Returns the set set set set of all key s NavigableSet<K> keySet(); //Returns a set view of a key, and the key in this set is in reverse order public NavigableSet<K> descendingKeySet(); }
After understanding the interface, let's look at the construction method of Concurrent SkipListMap and some important attributes:
public class ConcurrentSkipListMap<K,V> extends AbstractMap<K,V> implements ConcurrentNavigableMap<K,V>, Cloneable, Serializable { //Special values for private static final Object BASE_HEADER = new Object(); //Header Index of Jump Table private transient volatile HeadIndex<K,V> head; //Comparator, for comparison of keys, if null, using natural sorting (key's own Comparable implementation) final Comparator<? super K> comparator; //Key view private transient KeySet<K> keySet; //Views of key-value pairs private transient EntrySet<K,V> entrySet; //View of value private transient Values<V> values; //Maps in reverse order private transient ConcurrentNavigableMap<K,V> descendingMap; private static final int EQ = 1; private static final int LT = 2; private static final int GT = 0; //Empty structure public ConcurrentSkipListMap() { this.comparator = null; initialize(); } //Construction Method with Comparator public ConcurrentSkipListMap(Comparator<? super K> comparator) { this.comparator = comparator; initialize(); } //A Method for Constructing Sets of Initial Elements public ConcurrentSkipListMap(Map<? extends K, ? extends V> m) { this.comparator = null; initialize(); putAll(m); } //Comparator Construction Method Using m Set public ConcurrentSkipListMap(SortedMap<K, ? extends V> m) { this.comparator = m.comparator(); initialize(); buildFromSorted(m); } //initialize variable private void initialize() { keySet = null; entrySet = null; values = null; descendingMap = null; //Create a new HeadIndex node, and the head points to the headIndex node head = new HeadIndex<K,V>(new Node<K,V>(null, BASE_HEADER, null), null, null, 1); } }
4.put process
public V put(K key, V value) { if (value == null) //Here you can see that the Value requirement cannot be null throw new NullPointerException(); return doPut(key, value, false); //How to actually perform put operations } private V doPut(K key, V value, boolean onlyIfAbsent) { Node<K,V> z; // added node if (key == null) //Ordered map, key can't be null, otherwise it can't be compared throw new NullPointerException(); Comparator<? super K> cmp = comparator; //Get the comparator, null if not, and use natural sorting outer: for (;;) { //Outer circulation //findPredecessor Finds the node b corresponding to the precursor index of key for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) { //Determine whether the b node is the end of the list, that is, whether the b node has a successor node? //If there are successor nodes (n is not null for successor nodes), then insert the node corresponding to key between b and n //If b is the endpoint, the key corresponding endpoint will be the new endpoint. if (n != null) { Object v; int c; Node<K,V> f = n.next; //Get the successor node of n //Judging whether n is a successor to b? //If n is not a successor node of b, it means that threads have already preempted to insert a new node after B node. //Exit the inner loop and relocate the insert if (n != b.next) break; //Determine whether n nodes should be deleted (value is null for logical deletion), and relocate key after auxiliary deletion if ((v = n.value) == null) { // n is deleted n.helpDelete(b, f); //Let the current thread assist deletion (physical deletion) break; } //Determine if b is to be deleted or if it is to be deleted, exit the current loop and relocate key if (b.value == null || v == n) // b is deleted break; //Judging the key of n Node and the Size of key //Here we begin to precisely locate the key in the list, and find out the actual precursor nodes of the key in the list. //If the key is larger than the key of the n node, the key of the subsequent node is continued to be compared. if ((c = cpr(cmp, key, n.key)) > 0) { b = n; n = f; continue; } //If the key is equal to n.key (c==0), the node corresponding to the key already exists. //Then decide whether to override the old value based on onlyIfAbsent if (c == 0) { if (onlyIfAbsent || n.casValue(v, value)) { @SuppressWarnings("unchecked") V vv = (V)v; return vv; //Update success, return old value directly } break; //Update Failure Continue Loop Attempt } // else c < 0; fall through } //So b is the precursor of key. //Create a new key node Z and try to update the next of b to z, then exit the outer loop successfully //Update Failure Continue Attempt z = new Node<K,V>(key, value, n); if (!b.casNext(n, z)) break; // restart if lost race to append to b break outer; } } /** * The above step is to insert the new node into the list at the bottom of the jump table. * Next is to generate the index of each level up, whether to generate a certain level of index by tossing a coin. * Decision is to randomly decide whether to recommend an index at the top level from the bottom, and to generate an index at the top level for true. * And continue to toss coins to decide whether to index the upper layer or not; if it fails, index the upper layer, and end it directly. */ //Generate a random number int rnd = ThreadLocalRandom.nextSecondarySeed(); //Determine whether to update the hierarchy (the random number must be positive or even to update the hierarchy) //What is decided here is whether the newly added nodes should be indexed upwards. if ((rnd & 0x80000001) == 0) { // test highest and lowest bits int level = 1, max; //Determine the level of level, that is to say, the nodes should be indexed up to the grass-roots level. //The value of level has several consecutive 1 decisions starting at the lower two bits of rnd. //For example: rnd==0010 0100 0001 1110, then level is 5 //From this we can see that the highest level of jump table can not exceed 31 (level <=31) while (((rnd >>>= 1) & 1) != 0) ++level; Index<K,V> idx = null; HeadIndex<K,V> h = head; //Determine whether level exceeds the highest level of the current jump table (that is, whether it is larger than the level of the header index) //If not, create a vertical index column directly from 1 to level if (level <= (max = h.level)) { //Create a new index column, and the down pointer of the subsequent index points to the previous index for (int i = 1; i <= level; ++i) idx = new Index<K,V>(z, idx, null); } //If the level of the new node is larger than that of the header node, a new level layer should be built. else { // try to grow by one level level = max + 1; //It is meaningless to add two or more layers for a node. @SuppressWarnings("unchecked") Index<K,V>[] idxs = (Index<K,V>[])new Index<?,?>[level+1]; //Create a new index column of node z and put all the indexes of the index column into the array for (int i = 1; i <= level; ++i) idxs[i] = idx = new Index<K,V>(z, idx, null); for (;;) { h = head; //Get the header index int oldLevel = h.level; //Get the old level //Determine whether the level of the old hierarchy has changed (that is, whether there are other threads updating the level of the jump table in advance, there is competition) if (level <= oldLevel) // lost race to add level break; //Competition fails, ending the current cycle directly HeadIndex<K,V> newh = h; Node<K,V> oldbase = h.node; //Generate a new HeadIndex node //Normally, loops are executed only once, and if the value of oldLevel is unstable due to concurrent operations on other threads, multiple loops are executed. for (int j = oldLevel+1; j <= level; ++j) newh = new HeadIndex<K,V>(oldbase, newh, idxs[j], j); //Attempt to update the value of the header index if (casHead(h, newh)) { h = newh; idx = idxs[level = oldLevel]; break; } } } //Insert the new idx into the jump table splice: for (int insertionLevel = level;;) { int j = h.level; //Get the highest level //Find the index to be cleaned up for (Index<K,V> q = h, r = q.right, t = idx;;) { //The concurrent operation of other threads causes the header node to be deleted and exits the outer loop directly. //The probability of this happening is very small unless the concurrency is too large. if (q == null || t == null) break splice; //Judging whether q is the endpoint if (r != null) { Node<K,V> n = r.node; //Get the node n corresponding to index r // compare before deletion check avoids needing recheck int c = cpr(cmp, key, n.key); //Compare the size of key and n.key of the new node //Determine whether n should be deleted if (n.value == null) { if (!q.unlink(r)) //Delete r Index break; r = q.right; continue; } //c is greater than 0, indicating that the current node n.key is less than the key of the new node // Continue to look to the right for an index where the key of a node is larger than the new key of the node //The index corresponding to the new node should be inserted between q and r. if (c > 0) { q = r; r = r.right; continue; } } //Judge whether if (j == insertionLevel) { //Trying to interpolate t between q and r, if it fails, exit the inner loop and retry if (!q.link(r, t)) break; // restart //If the t node is deleted after insertion, the insertion operation is terminated if (t.node.value == null) { // Find the node and delete the node that needs to be deleted in the process of finding findNode(key); break splice; } //At the bottom, there is no index layer to insert into the new index if (--insertionLevel == 0) break splice; } //Continue linking down to other index layers if (--j >= insertionLevel && j < level) t = t.down; q = q.down; r = q.right; } } } return null; } //Find the precursor node of key's position in map private Node<K,V> findPredecessor(Object key, Comparator<? super K> cmp) { if (key == null) throw new NullPointerException(); // don't postpone errors for (;;) { //Get the head er index and traverse the jump table for (Index<K,V> q = head, r = q.right, d;;) { //Determine whether there is a subsequent index, if any if (r != null) { Node<K,V> n = r.node; //Get the node corresponding to the index K k = n.key; //Get the key corresponding to the node //Determine that the value of the node is null enough to indicate that the node has been deleted //When a node is deleted from the list, it assigns value to null, because indexes at other levels of the jump table may also be present. //It refers to the node, value assigns null, identifies that the node has been discarded, and the corresponding index (if it exists) should also be deleted from the jump table. //Then call the unlink method to delete the index if (n.value == null) { //Try to remove the r index from the jump table and continue to look up if you succeed //If you fail, keep trying. if (!q.unlink(r)) break; // restart r = q.right; // reread r continue; } //Compare the size of the key k and key of the node in the current index //If the key is larger than k, continue looking for the next index to compare if (cpr(cmp, key, k) > 0) { q = r; r = r.right; //Next right index continue; } } //If the key is less than k, the judgement is enough to reach the bottom of the jump table. //If it reaches the bottom layer, it means that the current index is the predecessor index of key, and node is the corresponding node. //If it is not the lowest level, then continue to compare and search. if ((d = q.down) == null) return q.node; q = d; r = d.right; } } } //Method in Index to disconnect the relationship between the two indexes final boolean unlink(Index<K,V> succ) { return node.value != null && casRight(succ, succ.right); } //Update the right index of the current index in CAS mode final boolean casRight(Index<K,V> cmp, Index<K,V> val) { return UNSAFE.compareAndSwapObject(this, rightOffset, cmp, val); } //Help delete b nodes from the list void helpDelete(Node<K,V> b, Node<K,V> f) { //Determine if other threads have deleted n (competing) and returned directly if deleted if (f == next && this == b.next) { //Determine whether f is null, that is, whether the current this node to be deleted is the endpoint //If this is the end point, try to update this to new Node < K, V > (f), which is not understood here. if (f == null || f.value != f) // not already marked casNext(f, new Node<K,V>(f)); else b.casNext(this, f.next); //Try to update the next of the precursor node b of the current node this to the successor node f of this } } //CAS updates the current node's successor val boolean casNext(Node<K,V> cmp, Node<K,V> val) { return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val); }
There are a lot of process codes for doPut above, which generally do a few things: 1. Find and confirm the location of key in the jump table. 2. Clean up the spreadsheet and check whether the spreadsheet has been changed by other threads, if the key has been relocated. 3. To determine whether the key already exists in the jump table, the existence is determined by onlyIfAbsent. 4. Insert the node generated by key into the underlying list. 5. Decide whether to create index columns corresponding to keys, and how many layers of index columns should be built. 6. Finally, the new index column is linked to the jump table.
5.get process
public V get(Object key) { return doGet(key); } private V doGet(Object key) { if (key == null) throw new NullPointerException(); Comparator<? super K> cmp = comparator; outer: for (;;) { //Outer circulation //Find the node corresponding to the precursor index of key for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) { Object v; int c; //n is null, indicating that b is a node, then key does not exist if (n == null) break outer; Node<K,V> f = n.next; //The succession of b is not n, which means that the succession of b is changed by other threads and the key is relocated. if (n != b.next) // inconsistent read break; //Determine whether n has been deleted, if so, assist deletion, and relocate key if ((v = n.value) == null) { // n is deleted n.helpDelete(b, f); break; } //Determine whether b has been deleted, if so, assist deletion, and relocate key if (b.value == null || v == n) // b is deleted break; //Determine whether n is the node to look for? //c==0, which means key==n.key. Find the frontal node to look for. , //If c is less than 0, then the key does not exist and the lookup ends. //c is greater than 0, indicating that it has not been found, then continue to traverse the search if ((c = cpr(cmp, key, n.key)) == 0) { @SuppressWarnings("unchecked") V vv = (V)v; return vv; } if (c < 0) break outer; b = n; n = f; } } return null; }
6.remove process
public V remove(Object key) { return doRemove(key, null); } final V doRemove(Object key, Object value) { if (key == null) throw new NullPointerException(); Comparator<? super K> cmp = comparator; outer: for (;;) { //Find Predecessor Finds the node corresponding to the precursor index of key for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) { Object v; int c; //n is null, indicating that b is a node, then key does not exist if (n == null) break outer; Node<K,V> f = n.next; //The successor of b is not n, which means that the successor of b is changed by other threads and the key is relocated. if (n != b.next) // inconsistent read break; //Determine whether n has been deleted, if so, assist deletion, and relocate key if ((v = n.value) == null) { // n is deleted n.helpDelete(b, f); break; } //Determine whether b has been deleted, if so, assist deletion, and relocate key if (b.value == null || v == n) // b is deleted break; //The key does not exist, and the deletion is terminated directly. if ((c = cpr(cmp, key, n.key)) < 0) break outer; //The current node is not the one to be deleted. Continue traversing to find if (c > 0) { b = n; n = f; continue; } //Find the node to delete, but it has been deleted by other threads first, then terminate the deletion directly. if (value != null && !value.equals(v)) break outer; //Attempt to logically delete, fail to continue trying if (!n.casValue(v, null)) break; //Add Delete Identity to Node (next Node is changed to a Node that points to itself) //Then, the next node CAS of the predecessor node is changed to the next.next node (the link of n node is completely removed) if (!n.appendMarker(f) || !b.casNext(n, f)) findNode(key); //Clear deleted nodes else { //Delete the index corresponding to n nodes. findPredecessor has steps to clear the index findPredecessor(key, cmp); // clean index //Judging whether to reduce the level of jump table if (head.right == null) tryReduceLevel(); } @SuppressWarnings("unchecked") V vv = (V)v; return vv; //Returns the value of the deleted node } } return null; } //Self-looping indicates that the node is to be deleted boolean appendMarker(Node<K,V> f) { return casNext(f, new Node<K,V>(f)); }
7.size statistics
Concurrent SkipListMap size is also an instantaneous value and can be overly dependent on:
//Traversing the underlying list to count the number of nodes public int size() { long count = 0; for (Node<K,V> n = findFirst(); n != null; n = n.next) { if (n.getValidValue() != null) ++count; } return (count >= Integer.MAX_VALUE) ? Integer.MAX_VALUE : (int) count; } //Getting the header node of the underlying list final Node<K,V> findFirst() { for (Node<K,V> b, n;;) { if ((n = (b = head.node).next) == null) return null; if (n.value != null) return n; n.helpDelete(b, n.next); //Help delete marked deleted nodes } }
Concurrent SkipListSet Concurrent Container
1.ConcurrentSkipListSet
The underlying implementation of ConcurrentSkipListSet is to use ConcurrentSkipListMap to add data as the key of ConcurrentSkipListMap, while value is always a Boolean object.
Boolean.
TRUE. Therefore, the source code is not too much analysis.