1. Introduction to attention
Attention means attention in Chinese. This mechanism is put into computer vision, which is similar to showing us a picture of a beautiful and handsome man. Where is the person we first pay attention to 😏
Where did you first see 😏

The earliest attention mechanism was applied to computer vision. The mechanism here is actually a module in neural network, similar to the change of U-Net and attention mechanism.
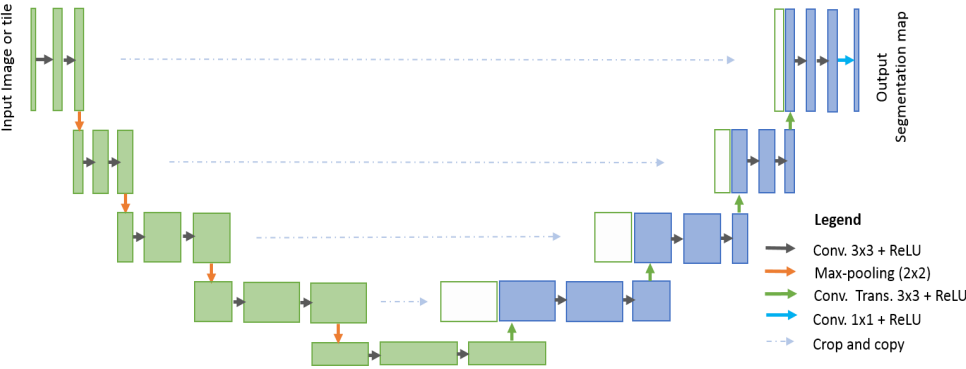
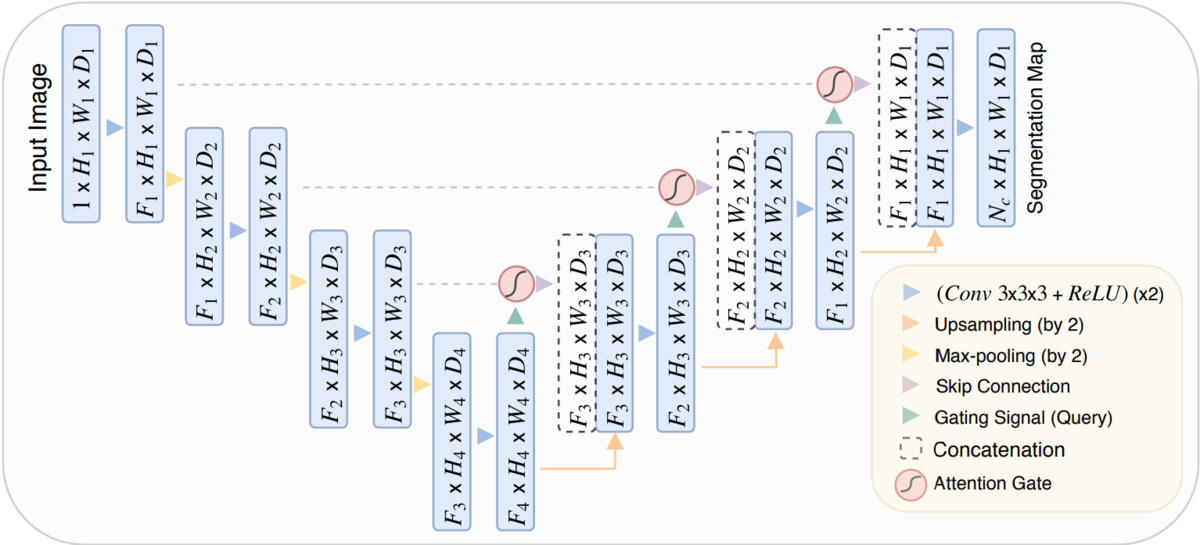
See what has changed? In fact, it is to add some structural modules to the original network structure.
With the development of NLP field, atteniton mechanism has also been applied. In addition to this, there are cyclic neural networks (RNNs), gated cyclic units (GRUs), long-term and short-term memory (LSTMs), sequence pair sequence (Seq2Seq), memory networks, etc. These are different frameworks of encoder decoder.
However, attention can be separated from encoder decoder and used by other model frameworks.
2. Principle of attention
In Taobao, the most commonly used algorithm for photo recognition of objects, in fact, the mechanism of attention is used.
Three step decomposition of Attention principle:
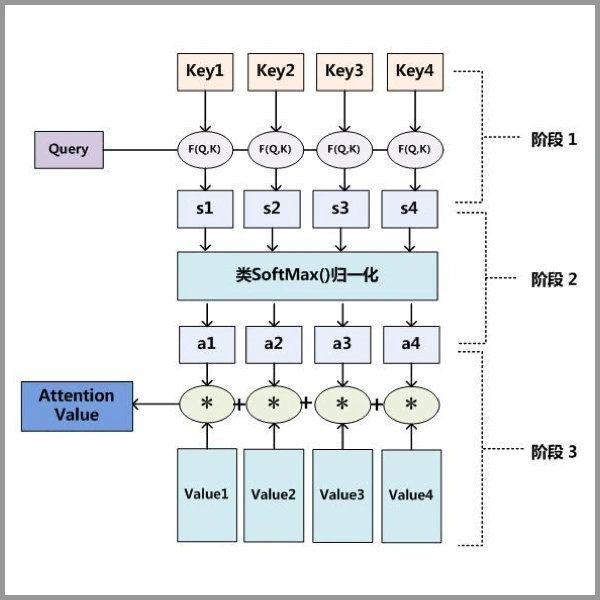
Step 1: query and key multiply the phase matrix
Step 2: normalize the results obtained by multiplying the matrix according to different weights
Step 3: multiply the result and value by the matrix again
The query, key and value mentioned in this step are actually the three vectors obtained by convoluting our feature maps with a 1x1 convolution kernel. As shown in the figure below.
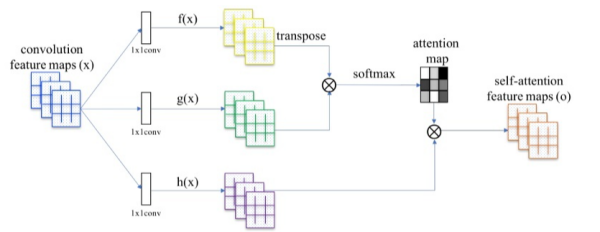
The overall steps can be understood as follows:
- The first step is to create an image containing pixel features
- In the second step, we generate the feature image query we need to find. For example, we need to find the details of the shoes (soles, laces...) in the image.
- In the third step, we number all the features in the image.
- Our method is to find the key in the image through query, extract the key we need, combine it with value, and use the weight to get the actual key area of the image we want to find.
🤩 To put it bluntly, the attention mechanism is a kind of weight distribution of the feature graph, which increases the useful feature weight and decreases the non feature weight, then applies the learned weight to the original feature graph, and finally performs weighted summation.
3. Different types of attention
At present, attention has been applied to computer vision, natural language processing and other fields. Although the structure of attention remains unchanged, the calculation methods of query, key and value are different. The calculation area is also different (a convolution kernel product, not all feature maps are products).
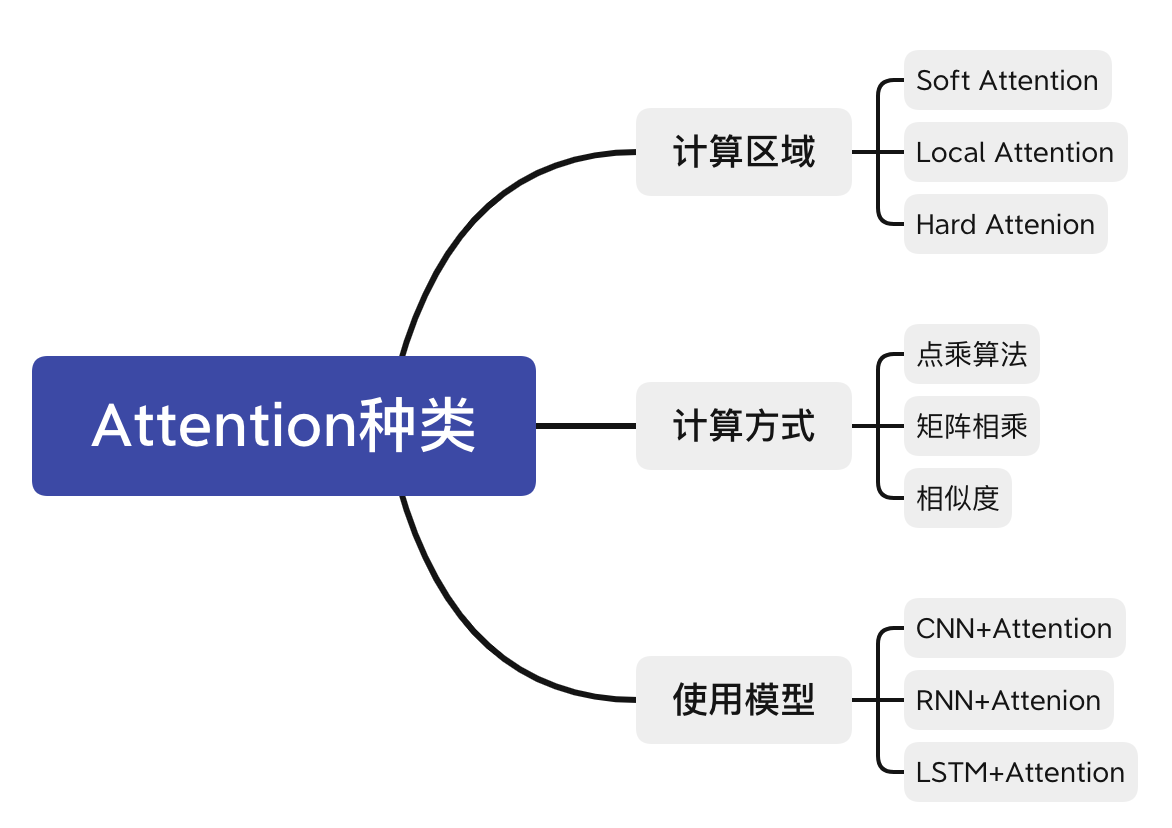
The previous principle of attention introduces the general version of attention. Here I only mention the attention in computer vision. There are three main types of attention in computer vision, namely:
- spatial attention: for convolutional neural networks, each layer of CNN will output a characteristic graph of C x H x W. C is the channel, and also represents the number of convolution cores, which is also the number of features. H and W are the height and width of the compressed graph of the original picture. spatial attention is for all channels on a two-dimensional plane, A weight is learned for the feature map of H x W size, and a weight is learned for each pixel. You can imagine that a pixel is a vector in the C dimension, and the depth is C. in the C dimensions, the weights are the same, but in the plane, the weights are different.
- Channel attention: for each C (channel), different weights are learned in the channel dimension, and the weights are the same in the plane dimension. Therefore, attention based on channel domain usually directly pools the information in a channel, ignoring the local information in each channel. The SENet algorithm is the channel attention used.
- Integration of spatial attention and channel attention: CBAM (revolutionary block attention module) [5] is one of the representative networks, with the following structure:
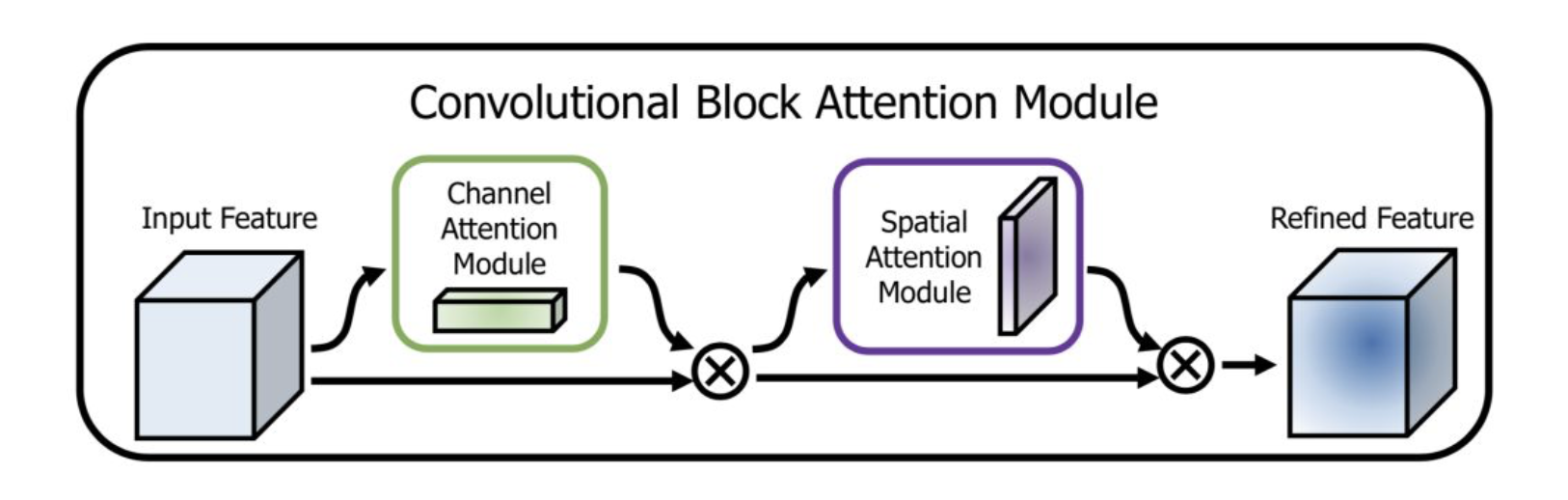
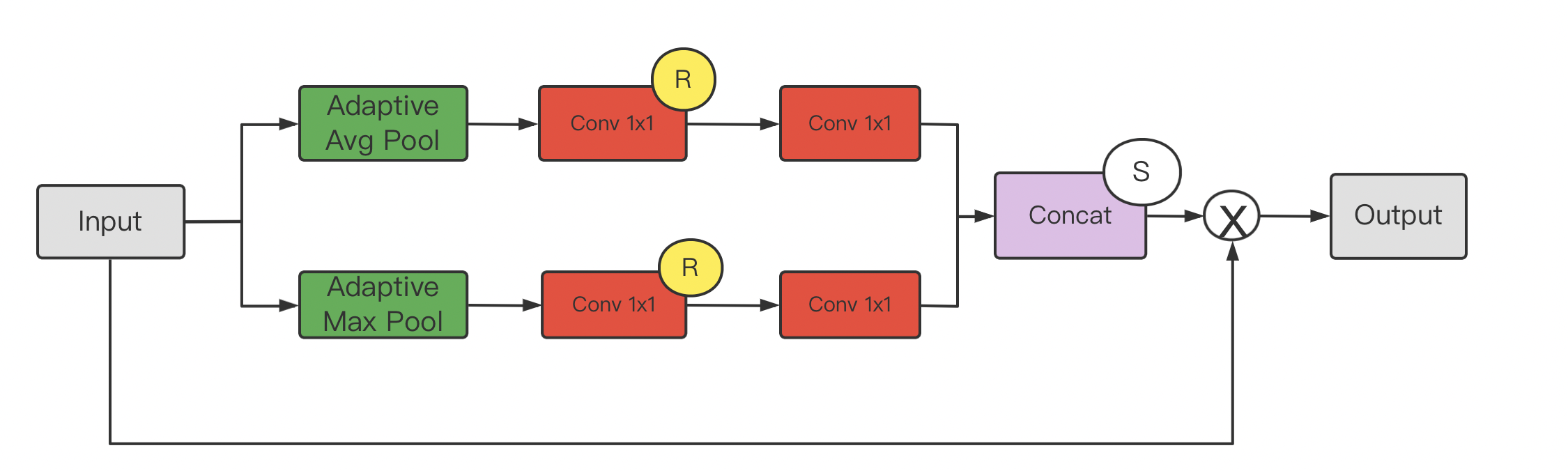
Channel Attention Module:
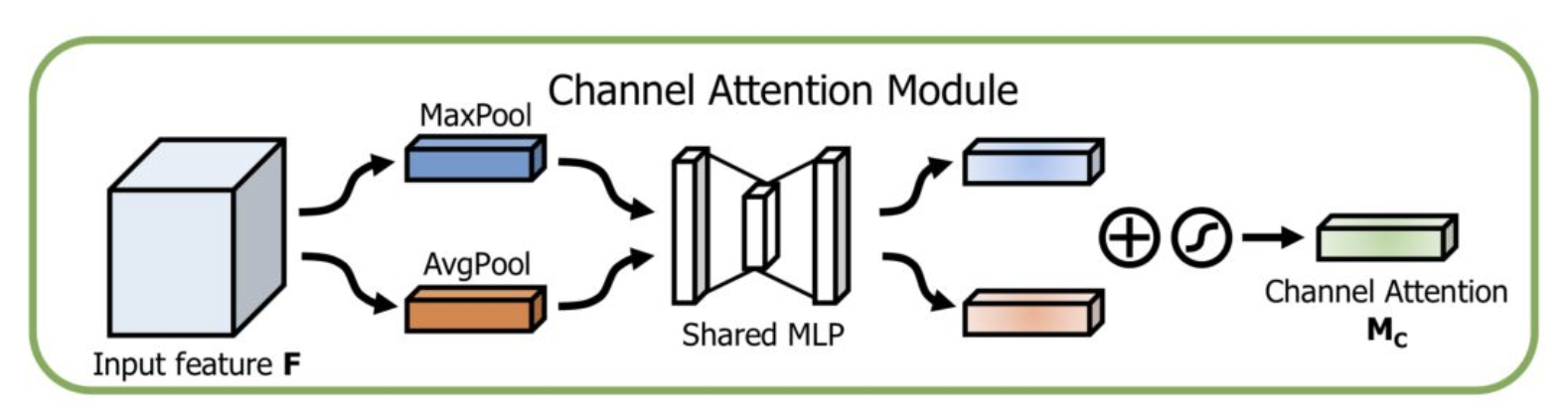
At the same time, the maximum pooling and mean pooling algorithms are used, and then the transformation results are obtained through several MLP layers. Finally, they are applied to two channels respectively, and the attention results of channels are obtained by sigmoid function.
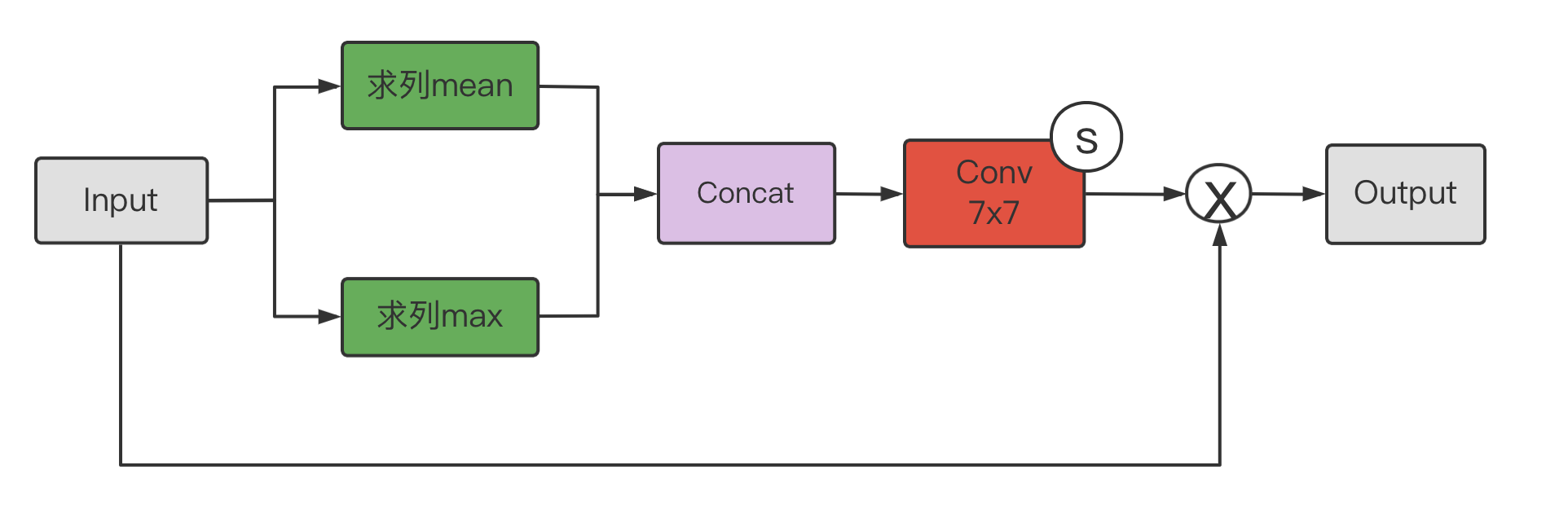
The Spatial Attention Module:

Firstly, the dimension of the channel itself is reduced to obtain the maximum pooling and mean pooling results respectively, and then spliced into a feature map, and then a convolution layer is used for learning.
These two mechanisms learn the importance of channel and space respectively, and can also be easily embedded into any known framework.
4.CBAM implementation (pytoch)
CBAM module details:
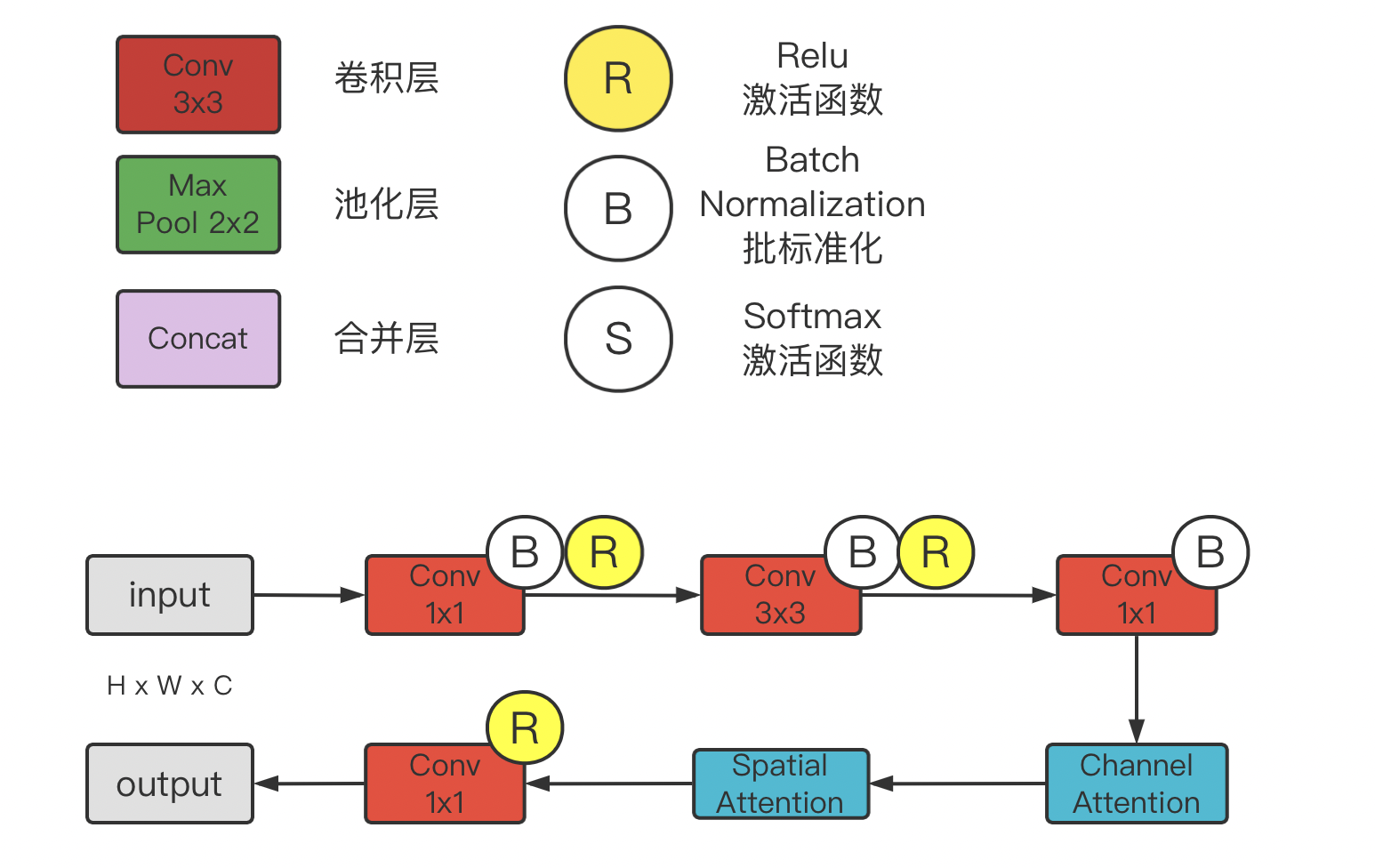
Channel Attention module:
The Spatial Attention module:
The code is as follows:
import torch
import torch.nn as nn
import torchvision
#ratio is the number of channels
class ChannelAttention(nn.Moudel):
def __init__(self, channel, ratio=16):
super(ChannelAttentionModule, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.shared_MLP = nn.Sequential(
nn.Conv2d(channel, channel // ratio, 1, bias=False),
nn.ReLU(),
nn.Conv2d(channel // ratio, channel, 1, bias=False)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = self.shared_MLP(self.avg_pool(x))
print(avgout.shape)
maxout = self.shared_MLP(self.max_pool(x))
return self.sigmoid(avgout + maxout)
class SpatialAttentionModule(nn.Module):
def __init__(self):
super(SpatialAttentionModule, self).__init__()
self.conv2d = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avgout, maxout], dim=1)
out = self.sigmoid(self.conv2d(out))
return out
class CBAM(nn.Module):
def __init__(self, channel):
super(CBAM, self).__init__()
self.channel_attention = ChannelAttentionModule(channel)
self.spatial_attention = SpatialAttentionModule()
def forward(self, x):
out = self.channel_attention(x) * x
print('outchannels:{}'.format(out.shape))
out = self.spatial_attention(out) * out
return out