Learning reference Videos: [crazy God says Java] Redis
Redis
1, Overview of redis
redis is a non relational database.
1. Introduction to non relational database
A non relational database, that is, NoSQL (Not Only SQL).
Relational database: column + row. The data structure under the same table is the same.
Non relational database: data storage has no fixed format and can be expanded horizontally.
NoSQL generally refers to non relational databases. With the birth of web2.0 Internet, traditional relational databases are difficult to deal with the web2.0 era! In particular, large-scale and highly concurrent communities have exposed many insurmountable problems. NoSQL is developing very rapidly in today's big data environment, and Redis is the fastest growing community.
Features of NoSQL
- Easy to expand (there is no relationship between data, it is easy to expand!)
- Large amount of data and high performance (Redis can write 80000 times and read 110000 times a second. NoSQL's cache record level is a fine-grained cache with high performance!)
- Data types are diverse! (there is no need to design the database in advance, and it can be used at any time)
Classification of NoSQL
| type | Partial representative | characteristic |
|---|---|---|
| Column storage | Hbase Cassandra HypertableHypertable | As the name suggests, data is stored by column. The biggest feature is to facilitate the storage of structured and semi-structured data, facilitate data compression, and have great IO advantages for queries against a column or several columns. |
| Document storage | MongoDB CouchDB | Document storage is generally stored in a format similar to json, and the stored content is document type. In this way, there is an opportunity to index some fields and realize some functions of relational database. |
| Key value storage | Tokyo Cabinet/Tyrant Berkeley DB MemcacheDB Redis | You can quickly query its value through key. Generally speaking, regardless of the format in which the value is stored, all orders are received. (Redis includes other functions) |
| Graph storage | Neo4J FlockDB | Optimal storage of graphical relationships. Using traditional relational database to solve the problem has low performance and inconvenient design and use. |
| Object storage | db4o Versant | Operate the database through syntax similar to object-oriented language and access data through object. |
| xml Database | Berkeley DB XML BaseX | Efficiently store XML data and support the internal query syntax of XML, |
2. What is redis
Redis is an in memory cache database. The full name of redis is Remote Dictionary Server (remote data service), which is written in C language. Redis is a key value storage system (key value storage system), which supports rich data types, such as String, list, set, zset and hash.
3.redis application scenario
Many languages support Redis. Because Redis exchanges data quickly, it is often used to store some data that needs to be accessed frequently in the server, which saves memory overhead and greatly improves the speed.
Some hot data is stored in Redis. When it needs to be used, it is directly fetched from memory, which greatly improves the speed and saves the server overhead.
1. Session cache (most commonly used)
2. Message queue (payment)
3. Activity ranking or counting
4. Publish and subscribe to messages (message notification)
5. Product list and comment list
2, Five data types
Before introducing the five data types, let's first understand the basic commands for key operation
| command | explain |
|---|---|
| keys * | View all key s in the current database |
| exists | Judge whether the specified key exists |
| del | Delete the specified key |
| expire | Set the expiration time of the key |
| type | View the type of key |
127.0.0.1:6379> keys * 1) "name" 127.0.0.1:6379> exists name (integer) 1 127.0.0.1:6379> type name string 127.0.0.1:6379> expire name 10 #Set 10s expiration time (integer) 1 127.0.0.1:6379> exists name (integer) 1 127.0.0.1:6379> exists name (integer) 1 127.0.0.1:6379> exists name #Expired after 10s (integer) 0 127.0.0.1:6379> keys * #When viewing all the keys in the current database, it is found that there are no keys (empty list or set)
String (string)
Since redis will be prompted after entering the command, I will write his keyword here
| command | describe |
|---|---|
| APPEND | Appends a string to the value of the specified key |
| DECR/INCR | The value value of the specified key is + 1 / - 1 (for numbers only) |
| INCRBY/DECRBY | Adds and subtracts values in specified steps |
| INCRBYFLOAT | Adds a floating-point value to the value |
| STRLEN | Gets the string length of the key save value |
| GETRANGE | Get the string according to the start and end position (closed interval, start and end positions) |
| SETRANGE | Replace the value from offset in the key with the specified value |
| GETSET | Set the value of the given key to value and return the old value of the key. |
| SETNX | set only when the key does not exist |
127.0.0.1:6379> keys * 1) "name" 2) "age" 127.0.0.1:6379> get name "thenie" 127.0.0.1:6379> get age "18" 127.0.0.1:6379> append name Shuai #Adds Shuai to the specified string (integer) 11 127.0.0.1:6379> get name "thenieShuai" 127.0.0.1:6379> DECR age #Self subtraction (integer) 17 127.0.0.1:6379> INCR age #Self increasing (integer) 18 127.0.0.1:6379> DECRBY age 5 #Specify reduction (integer) 13 127.0.0.1:6379> INCRBY age 5 (integer) 18 127.0.0.1:6379> STRLEN age #Return string length (integer) 2 127.0.0.1:6379> getrange name 0 -1 #Returns the full string "thenieShuai" 127.0.0.1:6379> getrange name 0 6 #Returns a string with subscripts 0 to 6 "thenieS" 127.0.0.1:6379> setrange name 6 Haokan #Cover with Haokan from position 6 (integer) 12 127.0.0.1:6379> get name "thenieHaokan" 127.0.0.1:6379> GETSET name kuaijieshule #Returns the value of name and makes the specified modification "thenieHaokan" 127.0.0.1:6379> GET name "kuaijieshule" 127.0.0.1:6379> setnx name , #Failed to create because the key is name (integer) 0 127.0.0.1:6379> get name "kuaijieshule"
String similar usage scenario: value can be either a string or a number. For example:
- Counter
- Count the quantity of multiple units: uid:123666: follow 0
- Number of fans
- Object storage cache
Hash (hash)
Redis hash is a mapping table of field and value of string type. Hash is especially suitable for storing objects.
| command | describe |
|---|---|
| HSET | Set the value of the field field in the hash table key to value. Setting the same field repeatedly will overwrite and return 0 |
| HMSET | Set multiple field value pairs to the hash table key at the same time. |
| HSETNX | Set the value of the hash table field only if the field field does not exist. |
| HEXISTS | Check whether the specified field exists in the hash table key. |
| HGET | Gets the value of the specified field stored in the hash table |
| HMGET | Gets the value of all the given fields |
| HGETALL | Get all fields and values in the hash table key |
| HKEYS | Get all fields in the hash table key |
| HLEN | Gets the number of fields in the hash table |
| HVALS | Gets all values in the hash table |
| HDEL | Delete one or more field fields in the hash table key |
| HINCRBY | Add the increment n to the integer value of the specified field in the hash table key and return the increment. The result is the same. It is only applicable to integer fields |
| HINCRBYFLOAT | Adds the increment n to the floating-point value of the specified field in the hash table key. |
127.0.0.1:6379> HSET mymap k1 v1 #Initialize a collection whose key is mymap (integer) 1 127.0.0.1:6379> HSET mymap k2 v2 (integer) 1 127.0.0.1:6379> HMSET mymap k3 v3 k4 v4 OK 127.0.0.1:6379> HEXISTS mymap k1 #Determine whether k1 exists in mymap (integer) 1 127.0.0.1:6379> HEXISTS mymap k5 (integer) 0 127.0.0.1:6379> HGETALL mymap #Return all key s and value s in mymap 1) "k1" 2) "v1" 3) "k2" 4) "v2" 5) "k3" 6) "v3" 7) "k4" 8) "v4" 127.0.0.1:6379> HGET mymap k1 "v1" 127.0.0.1:6379> HKEYS mymap #Return all key s in mymap 1) "k1" 2) "k2" 3) "k3" 4) "k4" 127.0.0.1:6379> HVALS mymap 1) "v1" 2) "v2" 3) "v3" 4) "v4" 127.0.0.1:6379> HDEL mymap k2 #Delete k2 in mymap (integer) 1 127.0.0.1:6379> HKEYS mymap 1) "k1" 2) "k3" 3) "k4" 127.0.0.1:6379> HSET mymap number 10 (integer) 1 127.0.0.1:6379> hget mymap number "10" 127.0.0.1:6379> HINCRBY mymap number 10 (integer) 20
The data changed by hash is user name and age, especially user information, which changes frequently! Hash is more suitable for object storage, and Sring is more suitable for string storage!
List
Redis list is a simple string list, sorted by insertion order. You can add an element to the head (left) or tail (right) of the list
A list can contain up to 232 - 1 elements (4294967295, more than 4 billion elements per list).
First of all, we can change the list into queue, stack, double ended queue, etc. through rule definition
As shown in the figure, List in Redis can be operated at both ends, so the commands are divided into LXXX and RLLL. Sometimes L also represents List, such as LLEN
| command | describe |
|---|---|
| LPUSH/RPUSH | PUSH values (one or more) from the left / right to the list. |
| LRANGE | Get the start and end elements of the list = = (the index is incremented from left to right)== |
| LPUSHX/RPUSHX | push values (one or more) into existing column names |
| LINSERT key BEFORE|AFTER pivot value | Inserts value before / after the specified list element |
| LLEN | View list length |
| LINDEX | Get list elements by index |
| LSET | Set values for elements by index |
| LPOP/RPOP | Remove value from leftmost / rightmost and return |
| RPOPLPUSH source destination | Pop up the last value at the end (right) of the list, return it, and then add it to the head of another list |
| LTRIM | Intercept the list within the specified range by subscript |
| LREM key count value | In the List, duplicate values are allowed. Count > 0: start the search from the head and delete the specified values. At most count is deleted. Count < 0: start the search from the tail... count = 0: delete all the specified values in the List. |
| BLPOP/BRPOP | Move out and get the first / last element of the list. If there are no elements in the list, the list will be blocked until the waiting timeout or pop-up elements are found. |
127.0.0.1:6379> rpush list a b c d e f #Initialize the list whose key is list (integer) 6 127.0.0.1:6379> LRANGE list 0 -1 #Return to list from left to right 1) "a" 2) "b" 3) "c" 4) "d" 5) "e" 6) "f" 127.0.0.1:6379> LPUSH list 1 #Insert 1 to the left (integer) 7 127.0.0.1:6379> LRANGE list 0 -1 1) "1" 2) "a" 3) "b" 4) "c" 5) "d" 6) "e" 7) "f" 127.0.0.1:6379> RPUSH list 2 #Insert 2 to the right (integer) 8 127.0.0.1:6379> LRANGE list 0 -1 #Return to list from left to right 1) "1" 2) "a" 3) "b" 4) "c" 5) "d" 6) "e" 7) "f" 8) "2" 127.0.0.1:6379> llen list (integer) 8 127.0.0.1:6379> LINDEX list 2 "b" 127.0.0.1:6379> LPUSH list1 1 #Initialize a list1 list (integer) 1 127.0.0.1:6379> RPOPLPUSH list list1 #Pop up a value from the right side of the list and insert it to the left side of the list "2" 127.0.0.1:6379> LRANGE list1 0 -1 1) "2" 2) "1" 127.0.0.1:6379> LPOP list1 "2" 127.0.0.1:6379> LPOP list1 "1" 127.0.0.1:6379> LTRIM list 1 8 OK 127.0.0.1:6379> LRANGE list 0 -1 1) "a" 2) "b" 3) "c" 4) "d" 5) "e" 6) "f"
Summary
- List is actually a linked list. Before node, after, left and right can insert values
- If the key does not exist, create a new linked list
- If the key exists, add content
- If all values are removed, the empty linked list also means that it does not exist
- Insert or change values on both sides for the highest efficiency! Modifying intermediate elements is relatively inefficient
Application:
Message queuing! Message queue (Lpush Rpop), stack (Lpush Rpop)
Set
Redis Set is an unordered Set of string type. Collection members are unique, which means that duplicate data cannot appear in the collection.
Collections in Redis are implemented through hash tables, so the complexity of adding, deleting and searching is O(1).
The largest number of members in the collection is 232 - 1 (4294967295, each collection can store more than 4 billion members).
| command | describe |
|---|---|
| SADD | Add one or more members to the collection unordered |
| SCARD | Gets the number of members of the collection |
| SMEMBERS | Returns all members of the collection |
| SISMEMBER | Query whether the member element is a member of the collection, and the result is unordered |
| SRANDMEMBER | Randomly return count members in the collection. The default value of count is 1 |
| SPOP | Randomly remove and return count members in the collection. The default value of count is 1 |
| SMOVE source destination member | Move the member of the source collection to the destination collection |
| SREM | Remove one or more members from the collection |
| SDIFF | Returns the difference set of all sets key1- key2 - |
| SDIFFSTORE destination key1[key2..] | Based on SDIFF, save the results to the set = = (overwrite) = =. Cannot save to other types of key s! |
| SINTER key1 [key2..] | Returns the intersection of all sets |
| SINTERSTORE destination key1[key2..] | On the basis of SINTER, the results are stored in the collection. cover |
| SUNION key1 [key2..] | Returns the union of all sets |
| SUNIONSTORE destination key1 [key2..] | On the basis of SUNION, store the results to and sheets. cover |
| SSCAN KEY [MATCH pattern] [COUNT count] | In a large amount of data environment, use this command to traverse the elements in the collection, traversing parts each time |
127.0.0.1:6379> sadd set a b c #Initialize the set with key set (integer) 3 127.0.0.1:6379> sadd set1 d e f #Initialize the set whose key is set1 (integer) 3 127.0.0.1:6379> SMEMBERS set #View all members of the specified collection 1) "b" 2) "c" 3) "a" 127.0.0.1:6379> SISMEMBER set b #Determine whether b exists in the set (integer) 1 127.0.0.1:6379> SISMEMBER set c (integer) 1 127.0.0.1:6379> SISMEMBER set e (integer) 0 127.0.0.1:6379> SRANDMEMBER set 2 #Random return of two members 1) "b" 2) "c" 127.0.0.1:6379> SRANDMEMBER set 2 1) "a" 2) "c" 127.0.0.1:6379> SADD set d (integer) 1 127.0.0.1:6379> SMOVE set set1 a #Move a in set to set1 (integer) 1 127.0.0.1:6379> SMEMBERS set 1) "b" 2) "c" 3) "d" 127.0.0.1:6379> SMEMBERS set1 1) "a" 2) "f" 3) "e" 4) "d" 127.0.0.1:6379> SREM set1 a #Delete the a element in set1 (integer) 1 127.0.0.1:6379> SMEMBERS set1 1) "f" 2) "e" 3) "d"
ZSet (sorted set)
The difference is that each element is associated with a score of type double. redis sorts the members of the collection from small to large through scores.
Same score: sort in dictionary order
Members of an ordered set are unique, but scores can be repeated.
| command | describe |
|---|---|
| ZADD key score member1 [score2 member2] | Add one or more members to an ordered collection, or update the scores of existing members |
| ZCARD key | Gets the number of members of an ordered collection |
| ZCOUNT key min max | Calculates the number of members of the specified interval score in the ordered set |
| ZINCRBY key n member | Adds the increment n to the score of the specified member in the ordered set |
| ZSCORE key member | Returns the score value of a member in an ordered set |
| ZRANK key member | Returns the index of the specified member in an ordered collection |
| ZRANGE key start end | Returns an ordered set through an index interval to synthesize members in a specified interval |
| ZRANGEBYLEX key min max | Returns the members of an ordered set through a dictionary interval |
| ZRANGEBYSCORE key min max | Return the members in the specified interval of the ordered set through scores = = - inf and + inf represent the minimum and maximum values respectively, and only open intervals () are supported== |
| ZLEXCOUNT key min max | Calculates the number of members in the specified dictionary interval in an ordered set |
| ZREM key member1 [member2..] | Remove one or more members from an ordered collection |
| ZREMRANGEBYLEX key min max | Removes all members of a given dictionary interval from an ordered set |
| ZREMRANGEBYRANK key start stop | Removes all members of a given ranking interval from an ordered set |
| ZREMRANGEBYSCORE key min max | Removes all members of a given score interval from an ordered set |
| ZREVRANGE key start end | Returns the members in the specified interval in the ordered set. Through the index, the score is from high to low |
| ZREVRANGEBYSCORRE key max min | Returns the members within the specified score range in the ordered set, and the scores are sorted from high to low |
| ZREVRANGEBYLEX key max min | Returns the members in the specified dictionary interval in the ordered set, in reverse dictionary order |
| ZREVRANK key member | Returns the ranking of the specified members in the ordered set, and the members of the ordered set are sorted by decreasing points (from large to small) |
| ZINTERSTORE destination numkeys key1 [key2 ..] | Calculate the intersection of one or more given ordered sets and store the result set in the new ordered set key. numkeys: represents the number of sets involved in the operation, and add the score as the score of the result |
| ZUNIONSTORE destination numkeys key1 [key2..] | Calculates the intersection of a given one or more ordered sets and stores the result set in a new ordered set key |
| ZSCAN key cursor [MATCH pattern\] [COUNT count] | Iterate the elements in the ordered set (including element members and element scores) |
-------------------ZADD--ZCARD--ZCOUNT--------------
127.0.0.1:6379> ZADD myzset 1 m1 2 m2 3 m3 # Add the member m1 score=1 and the member m2 score=2 to the ordered set myzset
(integer) 2
127.0.0.1:6379> ZCARD myzset # Gets the number of members of an ordered collection
(integer) 2
127.0.0.1:6379> ZCOUNT myzset 0 1 # Get the number of members whose score is in the [0,1] interval
(integer) 1
127.0.0.1:6379> ZCOUNT myzset 0 2
(integer) 2
----------------ZINCRBY--ZSCORE--------------------------
127.0.0.1:6379> ZINCRBY myzset 5 m2 # Add the score of member m2 + 5
"7"
127.0.0.1:6379> ZSCORE myzset m1 # Get the score of member m1
"1"
127.0.0.1:6379> ZSCORE myzset m2
"7"
--------------ZRANK--ZRANGE-----------------------------------
127.0.0.1:6379> ZRANK myzset m1 # Get the index of member m1. The index is sorted by score, and the index values with the same score are increased in dictionary order
(integer) 0
127.0.0.1:6379> ZRANK myzset m2
(integer) 2
127.0.0.1:6379> ZRANGE myzset 0 1 # Get members with index 0 ~ 1
1) "m1"
2) "m3"
127.0.0.1:6379> ZRANGE myzset 0 -1 # Get all members
1) "m1"
2) "m3"
3) "m2"
#Testset = > {ABC, add, amaze, apple, back, Java, redis} scores are all 0
------------------ZRANGEBYLEX---------------------------------
127.0.0.1:6379> ZRANGEBYLEX testset - + # Return all members
1) "abc"
2) "add"
3) "amaze"
4) "apple"
5) "back"
6) "java"
7) "redis"
127.0.0.1:6379> ZRANGEBYLEX testset - + LIMIT 0 3 # Display 0,1,2 records of query results by index in pages
1) "abc"
2) "add"
3) "amaze"
127.0.0.1:6379> ZRANGEBYLEX testset - + LIMIT 3 3 # Display 3, 4 and 5 records
1) "apple"
2) "back"
3) "java"
127.0.0.1:6379> ZRANGEBYLEX testset (- [apple # Show members in (-, apple] interval
1) "abc"
2) "add"
3) "amaze"
4) "apple"
127.0.0.1:6379> ZRANGEBYLEX testset [apple [java # Displays the members of the [apple,java] dictionary section
1) "apple"
2) "back"
3) "java"
-----------------------ZRANGEBYSCORE---------------------
127.0.0.1:6379> ZRANGEBYSCORE myzset 1 10 # Returns members whose score is between [1,10]
1) "m1"
2) "m3"
3) "m2"
127.0.0.1:6379> ZRANGEBYSCORE myzset 1 5
1) "m1"
2) "m3"
--------------------ZLEXCOUNT-----------------------------
127.0.0.1:6379> ZLEXCOUNT testset - +
(integer) 7
127.0.0.1:6379> ZLEXCOUNT testset [apple [java
(integer) 3
------------------ZREM--ZREMRANGEBYLEX--ZREMRANGBYRANK--ZREMRANGEBYSCORE--------------------------------
127.0.0.1:6379> ZREM testset abc # Remove member abc
(integer) 1
127.0.0.1:6379> ZREMRANGEBYLEX testset [apple [java # Remove all members in the dictionary interval [apple,java]
(integer) 3
127.0.0.1:6379> ZREMRANGEBYRANK testset 0 1 # Remove all members ranking 0 ~ 1
(integer) 2
127.0.0.1:6379> ZREMRANGEBYSCORE myzset 0 3 # Remove member with score at [0,3]
(integer) 2
# Testset = > {ABC, add, apple, amaze, back, Java, redis} scores are all 0
# myzset=> {(m1,1),(m2,2),(m3,3),(m4,4),(m7,7),(m9,9)}
----------------ZREVRANGE--ZREVRANGEBYSCORE--ZREVRANGEBYLEX-----------
127.0.0.1:6379> ZREVRANGE myzset 0 3 # Sort by score, and then return 0 ~ 3 of the results by index
1) "m9"
2) "m7"
3) "m4"
4) "m3"
127.0.0.1:6379> ZREVRANGE myzset 2 4 # Returns 2 ~ 4 of the index of the sorting result
1) "m4"
2) "m3"
3) "m2"
127.0.0.1:6379> ZREVRANGEBYSCORE myzset 6 2 # Returns the members in the collection whose scores are between [2,6] in descending order of score
1) "m4"
2) "m3"
3) "m2"
127.0.0.1:6379> ZREVRANGEBYLEX testset [java (add # Returns the members of the (add,java] dictionary interval in the collection in reverse dictionary order
1) "java"
2) "back"
3) "apple"
4) "amaze"
-------------------------ZREVRANK------------------------------
127.0.0.1:6379> ZREVRANK myzset m7 # Returns the member m7 index in descending order of score
(integer) 1
127.0.0.1:6379> ZREVRANK myzset m2
(integer) 4
# Mathscore = > {(XM, 90), (XH, 95), (XG, 87)} math scores of Xiao Ming, Xiao Hong and Xiao Gang
# Enscore = > {(XM, 70), (XH, 93), (XG, 90)} English scores of Xiao Ming, Xiao Hong and Xiao Gang
-------------------ZINTERSTORE--ZUNIONSTORE-----------------------------------
127.0.0.1:6379> ZINTERSTORE sumscore 2 mathscore enscore # Merge mathcore and enscore, and store the results in sumcore
(integer) 3
127.0.0.1:6379> ZRANGE sumscore 0 -1 withscores # The merged score is the sum of all scores in the previous set
1) "xm"
2) "160"
3) "xg"
4) "177"
5) "xh"
6) "188"
127.0.0.1:6379> ZUNIONSTORE lowestscore 2 mathscore enscore AGGREGATE MIN # Take the minimum member score of two sets as the result
(integer) 3
127.0.0.1:6379> ZRANGE lowestscore 0 -1 withscores
1) "xm"
2) "70"
3) "xg"
4) "87"
5) "xh"
6) "93"
Application case:
- set sort to store the sorting of class grade table and salary table!
- Ordinary message, 1. Important message, 2. Judgment with weight
- Leaderboard application implementation, taking the Top N test
3, Business
A single Redis command guarantees atomicity, while Redis transactions do not guarantee atomicity.
1. How to use transactions
-
Open transaction (multi)
-
Order to join the team
-
Execute transaction (exec)
The commands after the transaction is started will not be executed immediately, but will be executed together after exec input
127.0.0.1:6379> keys * (empty list or set) 127.0.0.1:6379> MULTI #open OK 127.0.0.1:6379> set name thenie #Order to join the team QUEUED 127.0.0.1:6379> set age 18 QUEUED 127.0.0.1:6379> get name QUEUED 127.0.0.1:6379> get name QUEUED 127.0.0.1:6379> get age QUEUED 127.0.0.1:6379> EXEC #End -- execute 1) OK 2) OK 3) "thenie" 4) "thenie" 5) "18"
In redis, batch processing is more appropriate than transaction.
If you don't want to execute the transaction in the middle of starting the transaction, enter DISCARD to give up.
2. What happens to command errors in transactions
Code syntax error (compile time exception) all commands are not executed
127.0.0.1:6379> KEYS * (empty list or set) 127.0.0.1:6379> MULTI #open OK 127.0.0.1:6379> set name thenie QUEUED 127.0.0.1:6379> set age 18 QUEUED 127.0.0.1:6379> setset name er #Wrong command (error) ERR unknown command `setset`, with args beginning with: `name`, `er`, 127.0.0.1:6379> get name QUEUED 127.0.0.1:6379> EXEC #No execution after completion (error) EXECABORT Transaction discarded because of previous errors.
Code logic error (runtime exception) * * other commands can be executed normally * * > >, so transaction atomicity is not guaranteed
127.0.0.1:6379> KEYS * (empty list or set) 127.0.0.1:6379> MULTI OK 127.0.0.1:6379> set name thenie QUEUED 127.0.0.1:6379> set age 18 QUEUED 127.0.0.1:6379> INCR name #Logical error, the latest string is self incremented QUEUED 127.0.0.1:6379> INCR age QUEUED 127.0.0.1:6379> EXEC 1) OK 2) OK 3) (error) ERR value is not an integer or out of range #The third command was wrong, but all other commands were executed 4) (integer) 19
4, Spring boot integrates reids
You can read my blog Spring boot integrates reids
5, Persistence - RDB
The data in redis is cached in memory, and the data in memory is lost immediately after power failure, which requires us to write the data in memory to the hard disk after a specified time interval
This process is called persistence, and RDB (Redis Databases) is one of them.
What is RDB
After the specified time interval, write the dataset snapshot in memory to the database; During recovery, directly read the snapshot file for data recovery;
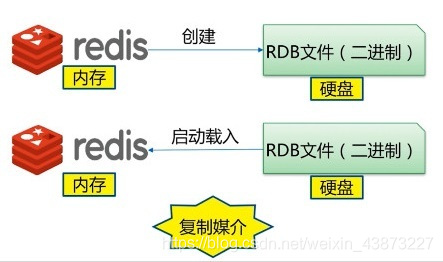
By default, Redis saves the database snapshot in a binary file named dump.rdb. The file name can be customized in the configuration file.
How to trigger
-
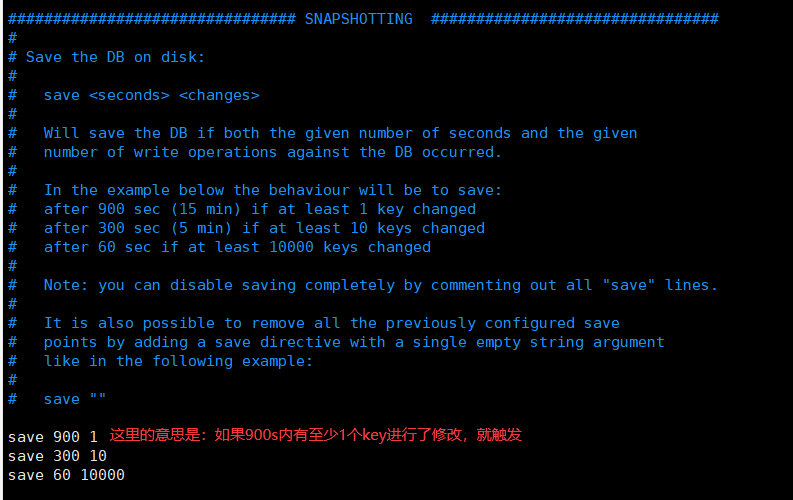
Trigger persistence rule
The persistence rules are configured in a configuration file named redis.conf:
-
Flush command
Persistence is also triggered by default when this command is executed.
After restarting the redis database, restore the data.
-
save
Using the save command will immediately persist the data in the current memory, but it will block, that is, it will not accept other operations;
Since the save command is a synchronization command, it will occupy the main process of Redis. If Redis data is very large, the execution speed of the save command will be very slow, blocking the requests of all clients.
-
bgsave
bgsave is performed asynchronously. redis can also continue to respond to client requests during persistence;
That is, fork() a child process to persist, while the main process continues to work.
working principle
During RDB, the main thread of redis will not perform io operations, and the main thread will fork a sub thread to complete the operation;
- Redis calls forks. Have both parent and child processes.
- The child process writes the data set to a temporary RDB file.
- When the child process finishes writing the new RDB file, Redis replaces the original RDB file with the new RDB file and deletes the old RDB file.
This way of working enables Redis to benefit from the copy on write mechanism (because the child process is used for write operations, and the parent process can still receive requests from the client.)
Advantages and disadvantages
advantage:
- Suitable for large-scale data recovery
- The requirements for data integrity are not high
Disadvantages:
- Operations need to be performed at a certain interval. If redis goes down unexpectedly, the last modified data will not be available.
- The fork process will occupy a certain content space.
6, Persistence - AOF
What is AOF
Record all our commands, history, and execute all the files again when recovering
Each write operation is recorded in the form of a log. All instructions executed by redis are recorded (read operations are not recorded). Only files are allowed to be added, but files cannot be overwritten. At the beginning of redis startup, the file will be read to rebuild the data. In other words, if redis restarts, the write instructions will be executed from front to back according to the contents of the log file to complete the data recovery.
How to open
It is not enabled by default. We need to configure it manually and restart redis to take effect!
If you want to use AOF, you need to modify the configuration file redis.conf:

appendonly no yes indicates that AOF is enabled
There is a problem with the transfer file
If the aof file is misplaced, redis cannot be started at this time. I need to modify the aof file
Redis provides us with a tool redis check AOF -- fix, which will eliminate the faulty commands in this file
Advantages and disadvantages
advantage
- Each modification will be synchronized, and the integrity of the file will be better
- If you do not synchronize every second, you may lose data for one second
- Never synchronized, most efficient
shortcoming
- Compared with data files, aof is much larger than rdb, and the repair speed is slower than rdb!
- Aof also runs slower than rdb, so the default configuration of redis is rdb persistence
7, redis master-slave replication
concept
In the redis Master-Slave architecture, the Master node is responsible for processing write requests, while the Slave node only processes read requests. For scenarios where there are few write requests and many read requests, such as the e-commerce details page, the concurrency can be greatly improved through this read-write separation operation. By increasing the number of redis Slave nodes, the QPS of redis can reach 10W +.
When the Master node writes data, it will be synchronized to the Slave node. The simple version architecture diagram is as follows:
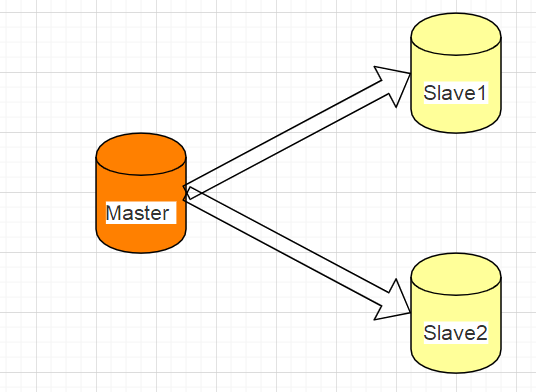
Simulate one master and two slaves (redis) on a server
-
Set and configure three redis service processes
There are three profiles:

#Modify the configuration files of the three redis respectively --------------Master( redis.conf)------------- #Port number port 6379 #pid file name pidfile /var/run/redis_6379.pid #Log file name logfile "6379.log" #rdb file name dbfilename dump.rdb --------------From( slave1.conf)------------- port 6380 pidfile /var/run/redis_6380.pid logfile "6380.log" dbfilename dump6380.rdb --------------From( slave2.conf)------------- port 6381 pidfile /var/run/redis_6381.pid logfile "6381.log" dbfilename dump6381.rdb
Service started successfully:
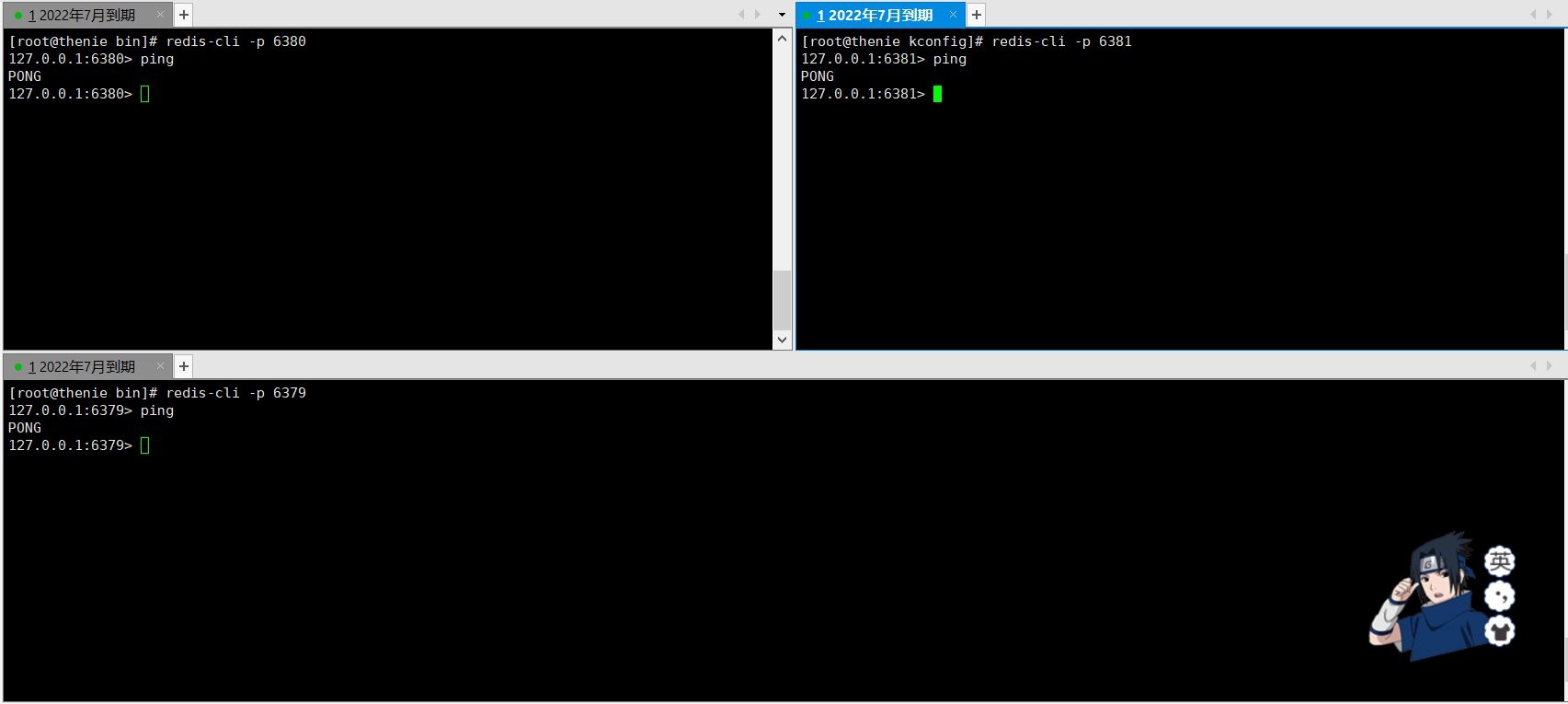
-
Establish contact
By default, each redis is a master node, so we only need to configure the slave
Use SLAVEOF host port to configure the host for the slave.
Configure successfully and use info replication to view master-slave status information:
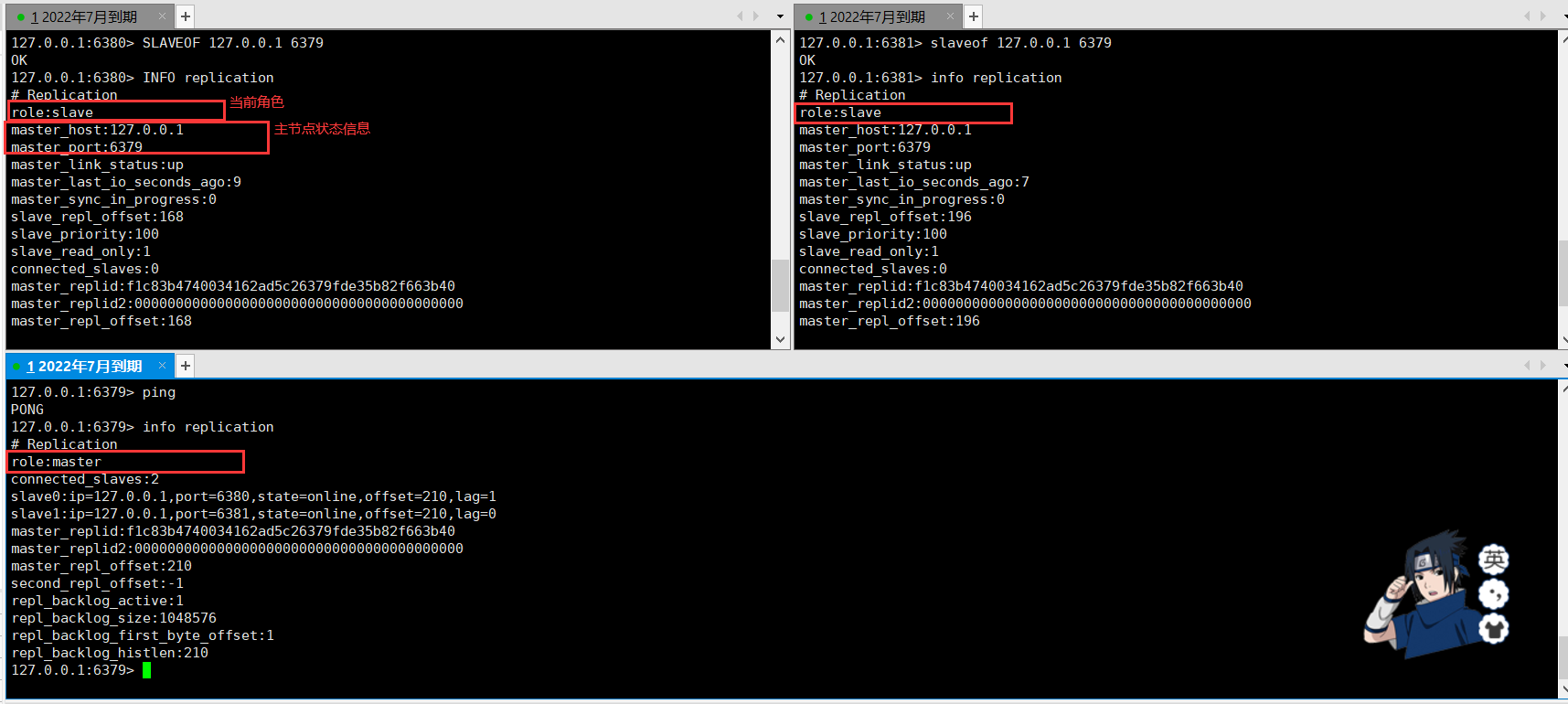
Use rules
-
The slave can only read, but the host can read, but it is mostly used for writing
-
When the host is powered off and down, the role of the slave will not change by default. The cluster only loses the write operation. After the host is restored, the slave will be connected and restored to its original state.
-
After the slave is powered off and down, if the slave is not configured using the configuration file, the data of the previous host cannot be obtained as the host after restart. If the slave is reconfigured at this time, all the data of the host can be obtained. Here is a synchronization principle.
-
As mentioned in Article 2, by default, new hosts will not appear after host failure. There are two ways to generate new hosts:
- The slave manually executes the command slave of no one. After execution, the slave becomes a host independently
- Use sentinel mode (automatic election)
-
8, Sentinel mode
When the primary server is down, it is obviously unrealistic to manually switch the primary server. Sentinel mode is more often used.
summary
Sentinel mode is a special mode. Firstly, Redis provides sentinel commands. Sentinel is an independent process. As a process, it will run independently. The principle is that the sentinel sends a command and waits for the response of the Redis server, so as to monitor multiple running Redis instances.
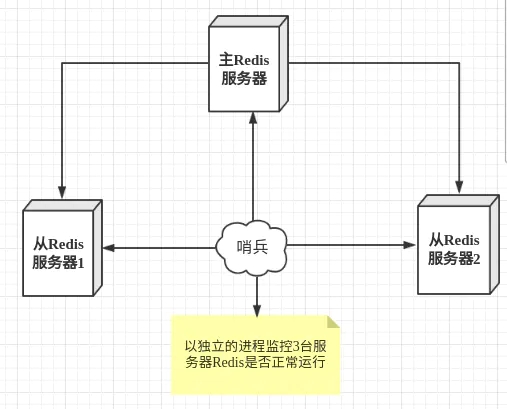
The role of the sentry here:
- Send commands to monitor redis and return it to running status (including master server and slave server)
- When the sentinel detects that the master is down, it will automatically switch one slave to the master, and then notify other slave servers through publish subscribe mode to modify the configuration file and let them switch hosts.
However, there may be problems when a sentinel process monitors the Redis server. Therefore, we can use multiple sentinels for monitoring. Each sentinel will also be monitored, which forms a multi sentinel mode.
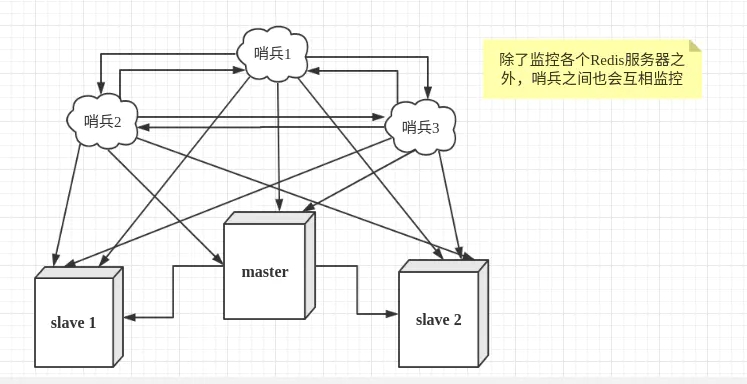
failover process
Assuming that the main server goes down, sentry 1 detects this result first, and the system will not fail immediately. Sentry 1 subjectively thinks that the main server is unavailable, which becomes a subjective offline phenomenon. When the following sentinels also detect that the primary server is unavailable and the number reaches a certain value, a vote will be held between sentinels. The voting result is initiated by a sentinel for failover. After the switch is successful, each sentinel will switch its monitored slave server to the host through the publish and subscribe mode. This process is called objective offline. In this way, everything is transparent to the client.
9, Cache penetration and avalanche
Cache penetration
concept
By default, when a user requests data, it will first find it in the cache, and then find it in the database if it misses. However, if the access volume is too large and the cache misses, it will be transferred to the database, resulting in too much pressure, which may lead to database crash. In network security, some people maliciously use this means to attack, which is called flood attack.
Solution
Bloom filter
As the name suggests, bron raises a shield in front.
Hash all possible query parameters to quickly judge whether the data is available; Intercept verification is performed at the control layer. If there is no, it will be returned directly.
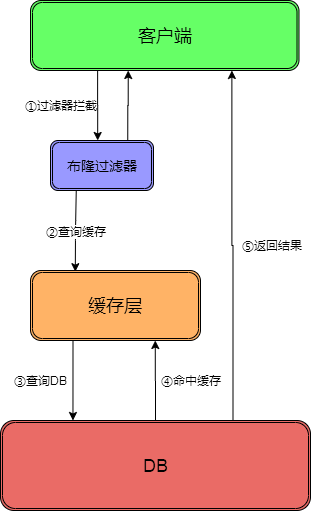
Cache empty objects
If a request is not found in the cache and database, an empty object is placed in the cache for subsequent processing.
There is a drawback to this: storing empty objects also requires space. A large number of empty objects will consume a certain space, and the storage efficiency is not high. The way to solve this problem is to set a shorter expiration time;
Even if the expiration time is set for a null value, there will still be inconsistency between the data of the cache layer and the storage layer for a period of time, which will have an impact on the business that needs to maintain consistency.
Buffer breakdown
concept
Compared with cache penetration, cache breakdown is more purposeful. When a key expires in the cache and multiple requests access the key at the same time, these requests will breakdown into the DB, resulting in a large number of transient DB requests and a sudden increase in pressure. This means that the cache is broken down. It is only because the cache of one key is unavailable, but other keys can still use the cache response.
For example, on the hot search ranking, a hot news is accessed in large numbers at the same time, which may lead to cache breakdown.
Solution
-
Set hotspot data never to expire
In this way, the hot data will not expire, but it will occupy more space. Once there are too many hot data, it will occupy more space. When the redis memory is full, it will also clean up some data.
-
Add mutex lock (distributed lock)
Before accessing the key, SETNX (set if not exists) is used to set another short-term key to lock the access of the current key. After the access is completed, the short-term key is deleted. Ensure that only one thread can access at the same time. In this way, the requirements for locks are very high.
Cache avalanche
concept
A large number of key s set the same expiration time, resulting in all caches failing at the same time, resulting in large instantaneous DB requests, sudden pressure increase and avalanche.
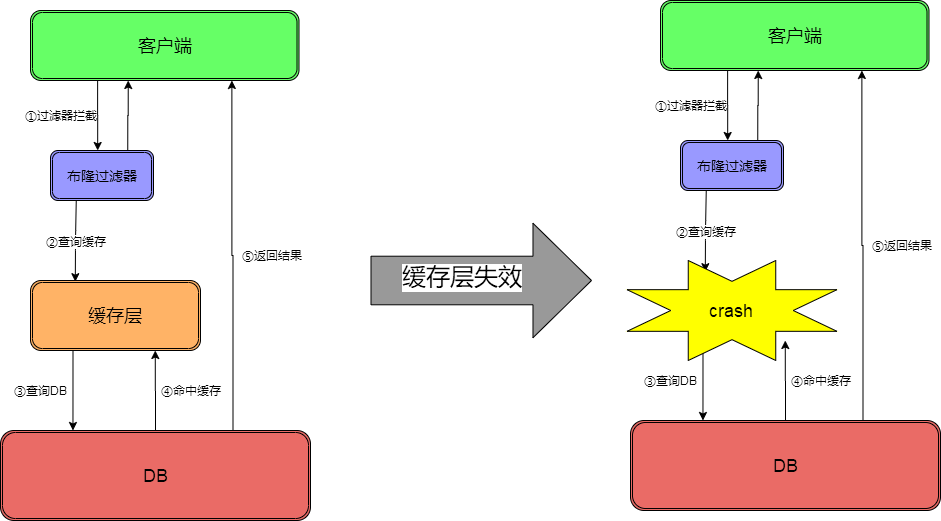
Solution
-
redis high availability
The meaning of this idea is that since redis may hang up, I will add several more redis. After one is hung up, others can continue to work. In fact, it is a cluster
-
Current limiting degradation
The idea of this solution is to control the number of threads reading and writing to the database cache by locking or queuing after the cache expires. For example, for a key, only one thread is allowed to query data and write cache, while other threads wait.
-
Data preheating
The meaning of data heating is that before the formal deployment, I first access the possible data in advance, so that some data that may be accessed in large quantities will be loaded into the cache. Before a large concurrent access is about to occur, manually trigger the loading of different cache key s and set different expiration times to make the time point of cache invalidation as uniform as possible.
If the expiration time is set for a null value, there will still be inconsistency between the data of the cache layer and the storage layer for a period of time, which will have an impact on the business that needs to maintain consistency.

If the article is helpful to you, please praise it and add a close~~