This article is reproduced from: https://mp.weixin.qq.com/s/K-wCUUztBxjGSlv2M5UA1Q
This paper is mainly used to record the comparison of three batch insertion methods, so as to facilitate the selection according to the actual situation in the follow-up work
The database uses SQL server, JDK version 1.8, and runs in the SpringBoot environment. Compare the three available methods
-
Execute a single insert statement repeatedly
-
xml splicing sql
-
Batch execution
Let's start with the conclusion: please insert a small amount of data repeatedly, which is convenient. If the quantity is large, please use batch processing. (consider about 20 pieces of data to be inserted. In my test and database environment, the time-consuming is 100 milliseconds, and convenience is the most important.)
xml is not used to splice sql at any time.
code
Splicing SQL xml
newId() is the function of SQL server to generate UUID, which is irrelevant to this article
<insert id="insertByBatch" parameterType="java.util.List">
INSERT INTO tb_item VALUES
<foreach collection="list" item="item" index="index" separator=",">
(newId(),#{item.uniqueCode},#{item.projectId},#{item.name},#{item.type},#{item.packageUnique},
#{item.isPackage},#{item.factoryId},#{item.projectName},#{item.spec},#{item.length},#{item.weight},
#{item.material},#{item.setupPosition},#{item.areaPosition},#{item.bottomHeight},#{item.topHeight},
#{item.serialNumber},#{item.createTime}</foreach>
</insert>
Mapper Interface Mapper yes mybatis plug-in unit tk.Mapper The interface has little to do with the content of this article
public interface ItemMapper extends Mapper<Item> {
int insertByBatch(List<Item> itemList);
}
Service class
@Service
public class ItemService {
@Autowired
private ItemMapper itemMapper;
@Autowired
private SqlSessionFactory sqlSessionFactory;
//Batch processing
@Transactional
public void add(List<Item> itemList) {
SqlSession session = sqlSessionFactory.openSession(ExecutorType.BATCH,false);
ItemMapper mapper = session.getMapper(ItemMapper.class);
for (int i = 0; i < itemList.size(); i++) {
mapper.insertSelective(itemList.get(i));
if(i%1000==999){//Commit every 1000 to prevent memory overflow
session.commit();
session.clearCache();
}
}
session.commit();
session.clearCache();
}
//Splicing sql
@Transactional
public void add1(List<Item> itemList) {
itemList.insertByBatch(itemMapper::insertSelective);
}
//Circular insertion
@Transactional
public void add2(List<Item> itemList) {
itemList.forEach(itemMapper::insertSelective);
}
}
Test class
@RunWith(SpringRunner.class)
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT, classes = ApplicationBoot.class)
public class ItemServiceTest {
@Autowired
ItemService itemService;
private List<Item> itemList = new ArrayList<>();
//Generate test List
@Before
public void createList(){
String json ="{\n" +
" \"areaPosition\": \"TEST\",\n" +
" \"bottomHeight\": 5,\n" +
" \"factoryId\": \"0\",\n" +
" \"length\": 233.233,\n" +
" \"material\": \"Q345B\",\n" +
" \"name\": \"TEST\",\n" +
" \"package\": false,\n" +
" \"packageUnique\": \"45f8a0ba0bf048839df85f32ebe5bb81\",\n" +
" \"projectId\": \"094b5eb5e0384bb1aaa822880a428b6d\",\n" +
" \"projectName\": \"project_TEST1\",\n" +
" \"serialNumber\": \"1/2\",\n" +
" \"setupPosition\": \"1B column\",\n" +
" \"spec\": \"200X200X200\",\n" +
" \"topHeight\": 10,\n" +
" \"type\": \"Steel\",\n" +
" \"uniqueCode\": \"12344312\",\n" +
" \"weight\": 100\n" +
" }";
Item test1 = JSON.parseObject(json,Item.class);
test1.setCreateTime(new Date());
for (int i = 0; i < 1000; i++) {//The test will modify this quantity
itemList.add(test1);
}
}
//Batch processing
@Test
@Transactional
public void tesInsert() {
itemService.add(itemList);
}
//Splice string
@Test
@Transactional
public void testInsert1(){
itemService.add1(itemList);
}
//Circular insertion
@Test
@Transactional
public void testInsert2(){
itemService.add2(itemList);
}
}
Test results:
10 and 25 data inserts have been tested for many times, and the volatility is large, but they are basically at the level of 100 milliseconds
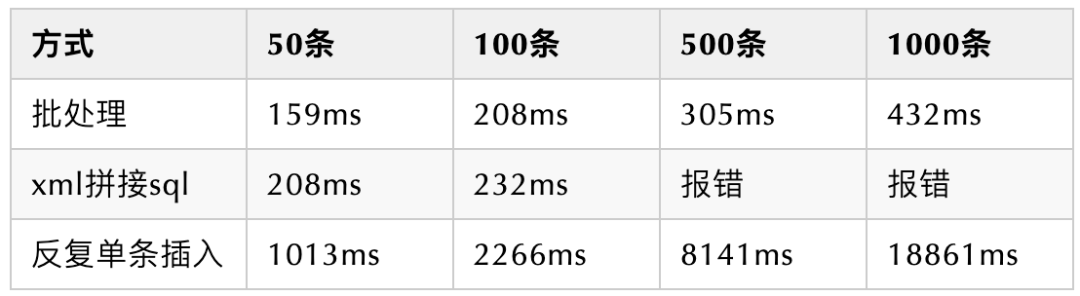
In the splicing sql method, errors are reported when 500 and 1000 sql statements are inserted (it seems that the sql statement is too long, which is related to the database type and is not tested by other databases): com.microsoft.sqlserver.jdbc.SQLServerException: the incoming tabular data stream (TDS) remote procedure call (RPC) protocol stream is incorrect. Too many parameters are provided in this RPC request, which should be 2100 at most
Can be found
-
The time complexity of loop insertion is O(n), and the constant C is very large
-
The time complexity of splicing SQL inserts (should be) O(logn), but the successful completion times are not many and uncertain
-
The time complexity of batch processing efficiency is O(logn), and the constant C is relatively small
conclusion
Although the efficiency of circular inserting a single piece of data is very low, the amount of code is very small. When using the tk.Mapper plug-in, only the code is required:
@Transactional
public void add1(List<Item> itemList) {
itemList.forEach(itemMapper::insertSelective);
}
Therefore, it must be used when the amount of data to be inserted is small.
xml splicing sql is the least recommended method. There are large sections of xml and sql statements to write when using, which is easy to make mistakes and low efficiency. More importantly, although the efficiency is OK, you hang up when you really need efficiency. What do you want?
Batch execution is recommended when there is a large amount of data insertion, and it is also convenient to use.