catalogue
Part I: Transformation operator
mapPartitions() executes Map in partition units
mapPartitionsWithIndex() with partition number
glom() partition conversion array
reparation() repartition (execute Shuffle)
union() Union, subtract() difference, intersection()
partitionBy() repartition by k
reduceByKey() aggregates by k v
Note: regular expression filter string method
aggregateByKey() performs intra partition and inter partition logic according to k
foldByKey() partition aggregateByKey() with the same logic between kernel partitions
combineByKey() operation within and between partitions after structure conversion
mapValues() operates on v only
join() associates multiple v's corresponding to the same k
Expansion: left external connection, right external connection and all external connection
cogroup() is similar to full join, but aggregates k in the same RDD
collect() returns a dataset as an array
count() returns the number of elements in the RDD
first() returns the first element in the RDD
take(n) returns an array of the first n RDD elements
takeOrdered(n) returns an array of the first n elements after RDD sorting
countByKey() counts the number of keys of each type
Foreach () & foreachpartition traverses every element in the RDD
preface
In Spark Core, RDD (Resilient Distributed Dataset) supports two operations:
1,transformation
Create a new RDD from a known RDD. For example, a map is a transformation.
2,action
After the calculation on the dataset is completed, a value is returned to the driver. For example, reduce is an action.
be careful:
This article only briefly describes the Transformation operator and Action operator in order to understand how to use their corresponding operators; It is not intended to deeply understand the execution process and logical thought of each operator.
In Spark, almost all transformation operations are lazy, that is, transformation operations do not immediately calculate their results, but remember the operation. Only when the result is obtained through an action and returned to the driver, these conversion operations begin to calculate. This design can make Spark run more efficiently.
By default, each time you run an action on an RDD, each previous transformed RDD will be recalculated. However, we can persist an RDD in memory or on disk through the persist (or cache) method to speed up access.
According to different data types in RDD, there are two types of RDD as a whole:
- Value type
- Key value type (in fact, a two-dimensional tuple is stored)
Part I: Transformation operator
Value type
map() map
Requirements:
Create an RDD of 1 ~ 4 arrays, two partitions, and form all elements * 2 into a new RDD.
Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
mapTest(sc)
//4. Close the connection
sc.stop()
}
def mapTest(sc: SparkContext): Unit = {
// 3.1 create an RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 4,2)
// 3.2 call the map method and multiply each element by 2
val mapRdd: RDD[Int] = rdd.map(_ * 2)
// 3.3 print the data in the modified RDD
mapRdd.collect().foreach(println)
}
}The map() operation is shown in the figure:
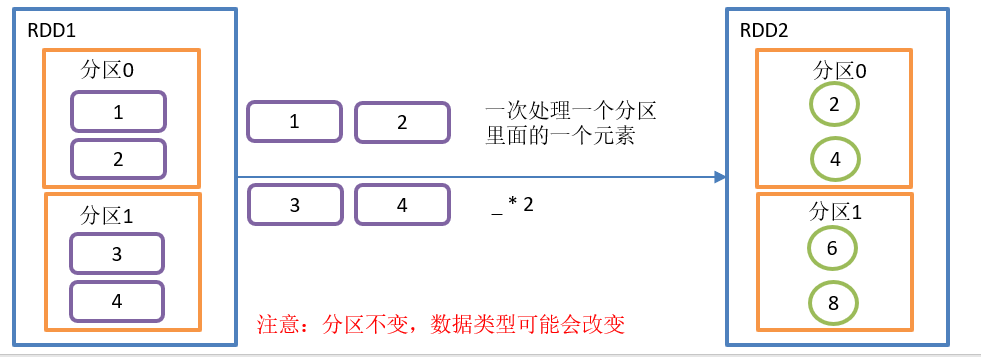
map() function structure
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
}
Function description
Parameter f is a function that can receive a parameter. When an RDD executes the map method, it will traverse each data item in the RDD and apply the F function in turn to generate a new RDD. That is, each element in the new RDD is obtained by applying the F function to each element in the original RDD in turn.
In this example, f is:_* two
Note: RDD. Map (* 2) is short for RDD. Map ((F: int) = > f * 2).
mapPartitions() executes Map in partition units
Requirements:
Create an RDD, 4 elements and 2 partitions, so that each element * 2 forms a new RDD
Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
mapPartitionsTest(sc)
//4. Close the connection
sc.stop()
}
/**
* Create an RDD, 4 elements and 2 partitions, so that each element * 2 forms a new RDD
* */
def mapPartitionsTest(sc: SparkContext): Unit ={
// 3.1 create the first RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 4,2)
// 3.2 requirements realization
val value: RDD[Int] = rdd.mapPartitions((data: Iterator[Int]) => data.map((x: Int) => x * 2))
// 3.3 printing
value.foreach(println)
}
}The mapPartitions() operation is shown in the figure below:

mapPartitions() function structure:
def mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U] = withScope {
val cleanedF = sc.clean(f)
new MapPartitionsRDD(
this,
(context: TaskContext, index: Int, iter: Iterator[T]) => cleanedF(iter),
preservesPartitioning)
}
Function introduction:
- The f function puts the data of each partition into the iterator for batch processing.
- Preservepartitioning: whether to keep the partition information of the upstream RDD. The default is false
- Map processes one element at a time, while mapPartitions processes partition data one at a time.
Note: the difference between map() and mapPartitions()
- map(): process one piece of data at a time.
- mapPartitions(): process the data of one partition at a time. After the data of this partition is processed, the data of this partition in the original RDD can be released, which may lead to OOM.
- Development guidance: when the memory space is large, it is recommended to use mapPartitions() to improve processing efficiency.
mapPartitionsWithIndex() with partition number
Requirements:
Create an RDD so that each element forms a tuple with the partition number to form a new RDD.
Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
mapPartitionsWithIndexTest(sc)
//4. Close the connection
sc.stop()
}
/**
* Create an RDD so that each element forms a tuple with the partition number to form a new RDD
* */
def mapPartitionsWithIndexTest(sc: SparkContext): Unit ={
// 3.1 create the first RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 4,2)
// 3.2 requirements realization
val value: RDD[(Int, Int)] = rdd.mapPartitionsWithIndex((index: Int, item: Iterator[Int]) => {
item.map((f: Int) => (index,f))
})
// 3.3 printing
value.foreach(println)
}
}mapPartitionsWithIndex() operation is shown in the figure:

mapPartitionsWithIndex() function structure:
def mapPartitionsWithIndex[U: ClassTag](
f: (Int, Iterator[T]) => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U] = withScope {
val cleanedF = sc.clean(f)
new MapPartitionsRDD(
this,
(context: TaskContext, index: Int, iter: Iterator[T]) => cleanedF(index, iter),
preservesPartitioning)
}
Function introduction:
- f: (Int, iterator [t]) = > Int in iterator [u] indicates the partition number
- Similar to mapPartitions, an integer parameter more than mapPartitions indicates the partition number
flatMap() flatten
Requirements:
Create a collection. What is stored in the collection is still a subset. Take out all the data in the subset and put it into a large collection.
Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
flatMapTest(sc)
//4. Close the connection
sc.stop()
}
/**
* Create a collection. What is stored in the collection is still a subset. Take out all the data in the subset and put it into a large collection
* */
def flatMapTest(sc: SparkContext): Unit ={
// 3.1 create the first RDD
val rdd: RDD[List[Int]] = sc.makeRDD(Array(List(1,2),List(3,4),List(5,6),List(7)),2)
// 3.2 requirements realization
val value: RDD[Int] = rdd.flatMap((list: List[Int]) => list)
// 3.3 printing
value.foreach(println)
}
}flatMap operation is shown in the figure:

Extension: the partition number can be obtained through the task context.
rdd.foreach((f: List[Int]) => {
// Get partitionID from task context
println(TaskContext.getPartitionId() + "---"+ f.mkString(","))
})
flatMap() function structure:
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.flatMap(cleanF))
}
Function introduction:
- Similar to the map operation, each element in the RDD is successively converted into a new element through the application f function and encapsulated in the RDD.
- Difference: in the flatMap operation, the return value of the f function is a collection, and each element in the collection will be split and put into a new RDD. And the new RDD inherits the number of partitions in the original RDD.
glom() partition conversion array
Requirements:
Create an RDD with 2 partitions, put the data of each partition into an array, and calculate the maximum value of each partition.
Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
glomTest(sc)
//4. Close the connection
sc.stop()
}
/**
* Create an RDD with 2 partitions, put the data of each partition into an array, and find the maximum value of each partition
* */
def glomTest(sc: SparkContext): Unit ={
// 3.1 create the first RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 4,2)
// 3.2 requirements realization
val value: RDD[Int] = rdd.glom().mapPartitions((x: Iterator[Array[Int]]) => x.map((f: Array[Int]) => f.max))
// 3.3 printing
value.foreach((f: Int) => {
println(TaskContext.getPartitionId() + ":" + f)
})
}
}glom() operation is shown in the figure:
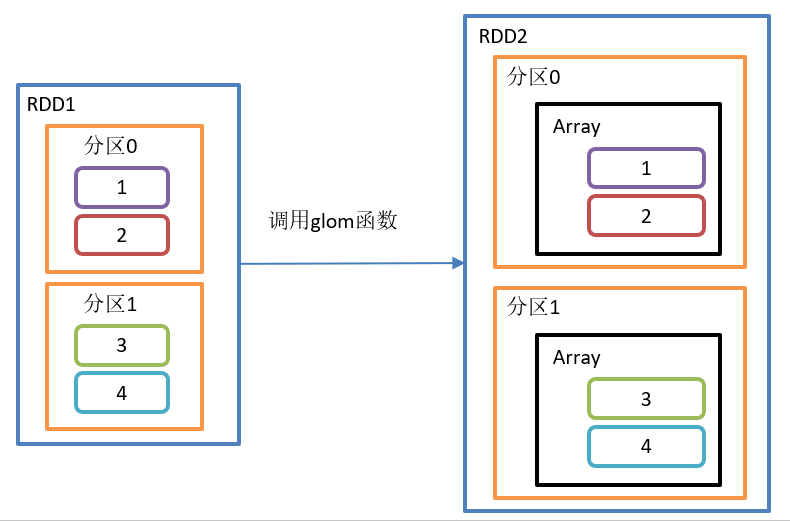
glom() function structure:
def glom(): RDD[Array[T]] = withScope {
new MapPartitionsRDD[Array[T], T](this, (context, pid, iter) => Iterator(iter.toArray))
}
Function introduction:
This operation turns each partition in the RDD into an array and places it in the new RDD. The element types in the array are consistent with those in the original partition.
groupBy() group
Requirements:
Create an RDD, grouped by element modulus with a value of 2.
Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
groupByTest(sc)
//4. Close the connection
sc.stop()
}
/**
* Create an RDD, grouped by element modulus with a value of 2
* */
def groupByTest(sc: SparkContext): Unit ={
// 3.1 create the first RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 10,3)
// 3.2 requirements realization
val value: RDD[(Int, Iterable[Int])] = rdd.groupBy(_ % 2)
// 3.3 printing
value.foreach(println)
}
}
The groupBy() operation is shown in the figure:
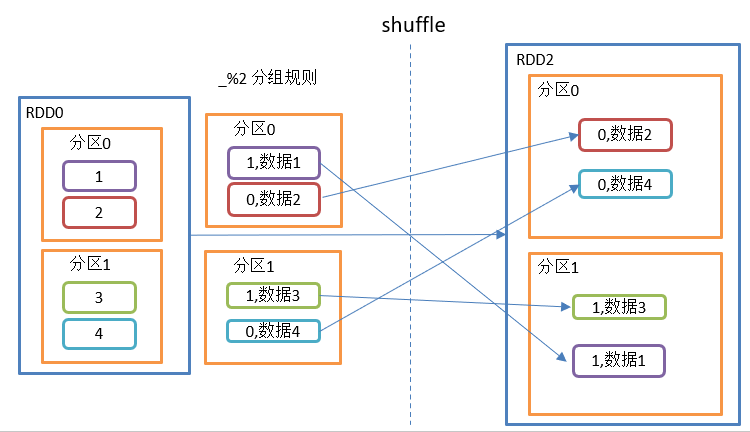
groupBy() function structure:
def groupBy[K](f: T => K)(implicit kt: ClassTag[K]): RDD[(K, Iterable[T])] = withScope {
groupBy[K](f, defaultPartitioner(this))
}
Function introduction:
Grouping: grouping according to the return value of the incoming function. Put the value corresponding to the same key into an iterator.
remarks:
1. There will be a shuffle process for groupBy
2. shuffle: the process of disrupting and reorganizing different partition data
3. shuffle will fall.
Extension: complex wordcount
Requirements:
There are the following data, ("Hello Scala", 2), ("Hello Spark", 3), ("Hello World", 2),("I Love You",5),("I Miss You",2),("Best wish",9). The number represents the number of occurrences. Find the number of occurrences of each word.
Code implementation:
def worldCountTest(sc: SparkContext): Unit ={
val rdd: RDD[(String, Int)] = sc.makeRDD(Array(("Hello Scala", 2), ("Hello Spark", 3), ("Hello World", 2), ("I Love You", 5), ("I Miss You", 2), ("Best wish", 9)))
// Method 1: suitable for scala
/*val value: String = rdd.map {
// pattern matching
case (str, count) => {
// scala For string operation, ("Hello Scala" + "") * 2 = Hello Scala Hello Scala
(str + " ") * count
}
}
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_+_)
.collect()
.mkString(",")
*/
// Mode 2: more general
val value: String = rdd.flatMap {
case (str, i) => {
str.split(" ").map((word: String) => (word, i))
}
}.reduceByKey(_ + _)
.collect()
.mkString(",")
println(value)
}Filter
Requirements:
Create an RDD of 1 to 10 and filter out even numbers.
Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
filterTest(sc)
//4. Close the connection
sc.stop()
}
/**
* Filter even
* */
def filterTest(sc: SparkContext): Unit = {
// 3.1 create the first RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 10, 3)
// 3.2 requirements realization
val value: RDD[Int] = rdd.filter(_ % 2 == 0)
// 3.3 printing
value.foreach(println)
}
}The operation process of filter() is as follows:
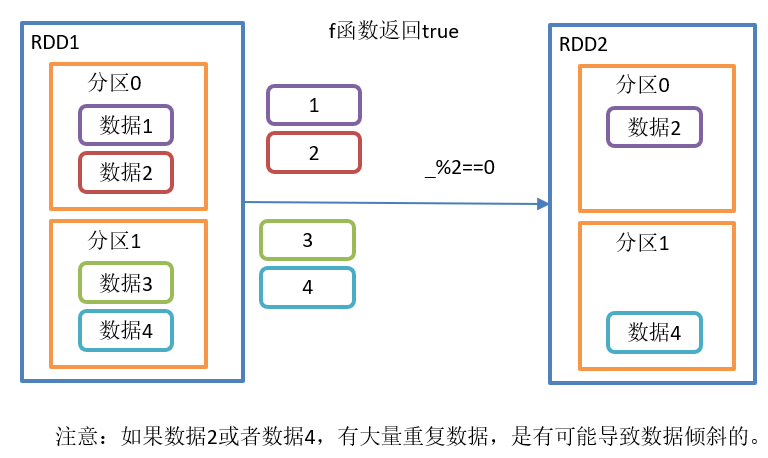
filter() function structure:
def filter(f: T => Boolean): RDD[T] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[T, T](
this,
(context, pid, iter) => iter.filter(cleanF),
preservesPartitioning = true)
}
Function introduction:
- Receives a function with a Boolean return value as an argument.
- When an RDD calls the filter method, the f function will be applied to each element in the RDD. If the return value type is true, the element will be added to the new RDD.
sample()
Requirements:
Create an RDD (1-10) from which to select samples to put back and not to put back.
Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
sampleTest(sc)
//4. Close the connection
sc.stop()
}
/**
* Random sampling
* */
def sampleTest(sc: SparkContext): Unit ={
// 3.1 create the first RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 20, 3)
// 3.2 requirements realization
val value: String = rdd.sample(true,0.3,3).collect().mkString(",")
val value2: String = rdd.sample(false,0.3,3).collect().mkString(",")
// 3.3 printing
println("Do not put back the sampling results:" + value2)
println("Put back the sampling results:" + value)
}
}The sample() operation is shown in the figure:

sample() function structure:
def sample(
withReplacement: Boolean,
fraction: Double,
seed: Long = Utils.random.nextLong): RDD[T] = {
......
}
Function introduction:
- Sampling from large amounts of data
- withReplacement: Boolean: whether to put the extracted data back
- fraction: Double:
- When withReplacement=false: the probability of selecting each element; The value must be [0,1]; The bottom layer uses Poisson distribution.
- When withReplacement=true: select the expected number of times for each element; The value must be greater than or equal to 0, and the bottom layer uses Bernoulli sampling.
- seed: Long: Specifies the random number generator seed
remarks:
1. The random sampling of the function is pseudo-random, because the incoming random seeds are the same, and the calculation results are of course the same.
distinct() de duplication
Requirements:
De duplication of the following data: 3,2,9,1,2,1,5,2,9,6,1
Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
distinctTest(sc)
//4. Close the connection
sc.stop()
}
/**
* Data De duplication
* */
def distinctTest(sc: SparkContext): Unit = {
// 3.1 create the first RDD
val rdd: RDD[Int] = sc.makeRDD(List(3,2,9,1,2,1,5,2,9,6,1))
// 3.2 requirements realization
val value: RDD[Int] = rdd.distinct()
// 3.3 printing
value.foreach(println)
}
}The distinct() operation is shown in the figure:
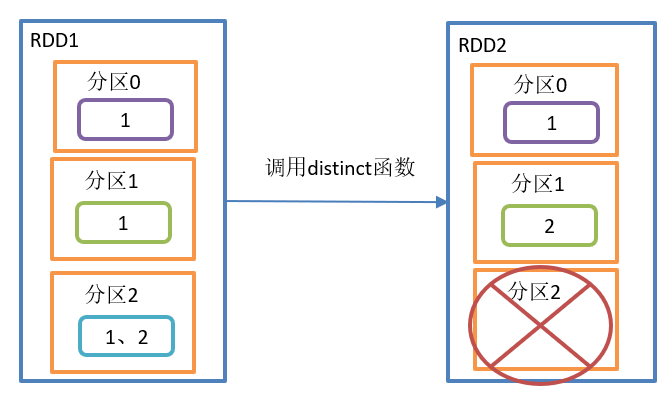
distinct() function structure:
def distinct(): RDD[T] = withScope {
distinct(partitions.length)
}
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
}
Function introduction:
De duplicate the internal elements and put the de duplicated elements into the new RDD.
remarks:
1. distinct() is easier to remove duplicates in a distributed way than in a HashSet set. OOM
2. By default, distinct will generate the same number of partitions as the original RDD partitions. Of course, you can also specify the number of partitions.
coalesce() repartition
Requirements:
1. Merge the RDDS of four partitions into the RDDS of two partitions
2. Merge the RDDS of three partitions into the RDDS of two partitions
Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
coalesceTest(sc)
//4. Close the connection
sc.stop()
}
/**
* coalesce Repartition
* */
def coalesceTest(sc: SparkContext): Unit = {
// 3.1 create the first RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 4,4)
val rdd2: RDD[Int] = sc.makeRDD(1 to 4,3)
// 3.2 requirements realization
val value1: Array[(Int, Int)] = rdd.coalesce(2).map((TaskContext.getPartitionId(),_)).collect()
val value2: Array[(Int, Int)] = rdd2.coalesce(2).map((TaskContext.getPartitionId(),_)).collect()
// 3.3 printing
println("value1:" + value1.mkString(","))
println("value2:" + value2.mkString(","))
}
}coalesce() operation is shown in the figure:
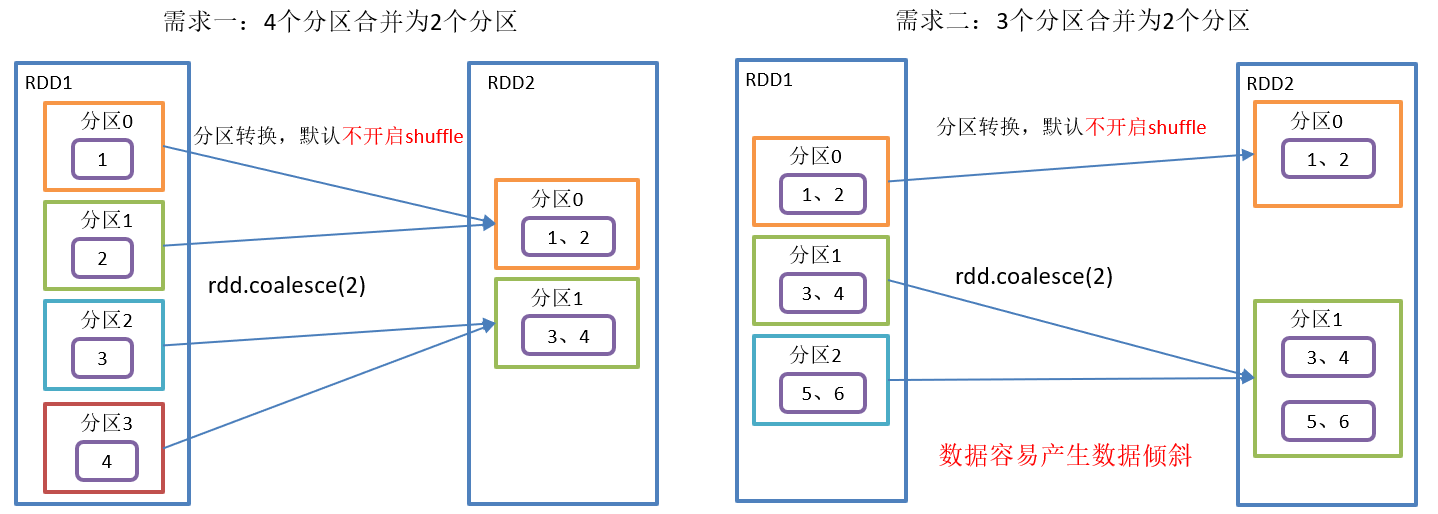
coalesce() function structure:
def coalesce(numPartitions: Int, shuffle: Boolean = false,
partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
(implicit ord: Ordering[T] = null)
: RDD[T] = withScope {
......
}
Function introduction:
- Reduce the number of partitions to improve the execution efficiency of small data sets after filtering large data sets.
- shuffle is false by default. This operation will convert the original RDD with a large number of partitions to the target RDD with a small number of partitions.
- shuffle:
- true: shuffle. At this time, the number of target partitions can be greater than or less than the number of original partitions. That is, the original partition can be reduced and expanded.
- false: do not shuffle. At this time, the number of target partitions can only be less than the number of original partitions; When greater than, the number of partitions does not take effect. That is, you can only reduce or equal to the original partition.
remarks:
1. shuffle principle: break up the data and then reassemble it.

2. Readers can refer to the specific shuffle process“ Thoroughly understand spark's shuffle process".
reparation() repartition (execute Shuffle)
Requirements:
Create an RDD with 4 partitions and repartition it
Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
repartitionTest(sc)
//4. Close the connection
sc.stop()
}
/**
* repartition Repartition
* */
def repartitionTest(sc: SparkContext): Unit = {
// 3.1 create the first RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 10,4)
// 3.2 requirements realization
val value1: Array[(Int, Int)] = rdd.repartition(2).map((TaskContext.getPartitionId(),_)).collect()
val value2: Array[(Int, Int)] = rdd.repartition(5).map((TaskContext.getPartitionId(),_)).collect()
// 3.3 printing
println("value1:" + value1.mkString(","))
println("value2:" + value2.mkString(","))
}
}The replacement () operation is shown in the figure:
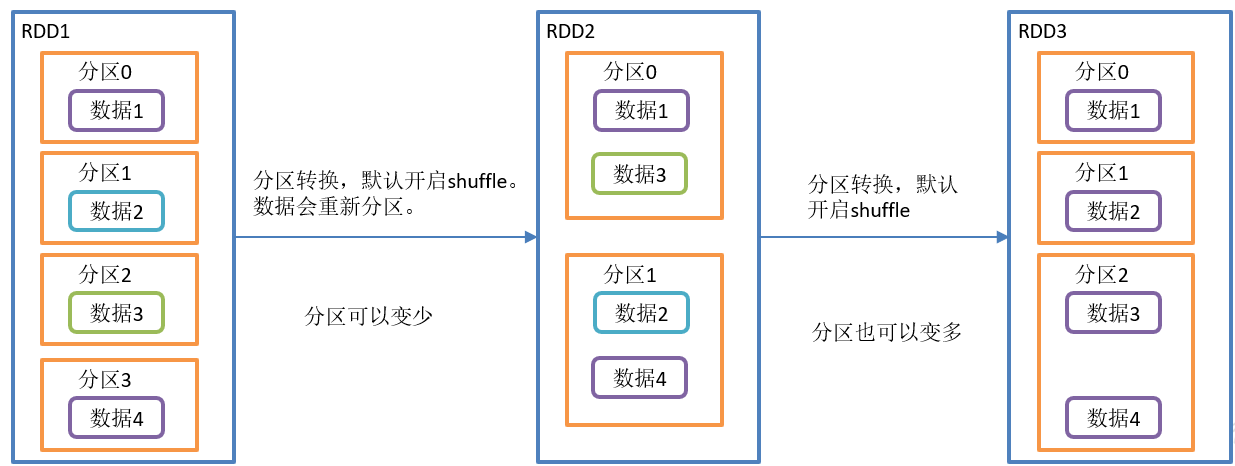
reparation() function structure:
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}
Function introduction:
- This operation is actually a coalesce operation, and the default value of the parameter shuffle is true.
- Whether you convert an RDD with a large number of partitions to an RDD with a small number of partitions, or convert an RDD with a small number of partitions to an RDD with a large number of partitions, the repartition operation can be completed, because it will go through the shuffle process anyway.
Note: the difference between coalesce and reparation
- When the coalesce is repartitioned, you can choose whether to perform the shuffle process. Determined by the parameter shuffle: Boolean = false/true.
- repartition is actually called coalesce to shuffle.
- If you are reducing partitions, try to avoid shuffle and use coalesce.
- In most cases, reduce the use of coalesce in partitions and increase the use of representation in partitions.
sortBy() sort
Requirements:
Create an RDD and sort according to different rules.
- Sort in ascending order of number size
- Sort in descending order of number size
- Sort by modulus in descending order of the remainder of 5
- For binary, the first element is in ascending order. If the first element is the same, the second element is in descending order
Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
sortByTest(sc)
//4. Close the connection
sc.stop()
}
/**
* sortBy sort
* */
def sortByTest(sc: SparkContext): Unit = {
// 3.1 create the first RDD
val rdd: RDD[Int] = sc.makeRDD(List(3,16,5,8,2,10,9,1,7,6))
// 3.2 requirements realization
// Ascending order
val value1: String = rdd.sortBy((num: Int) => num).collect().mkString(",")
// Descending order
val value2: String = rdd.sortBy((num: Int) => num,false).collect().mkString(",")
// Sort by% 5
val value3: String = rdd.sortBy((num: Int) => num % 5,false).collect().mkString(",")
// The first element is in ascending order. If the first element is the same, the second element is in descending order
val value4: String = rdd2.sortBy((x: (Int, Int)) => (x._1,-x._2)).collect().mkString(",")
// 3.3 printing
println("value1:" + value1)
println("value2:" + value2)
println("value3:" + value3)
println("value4:" + value4)
}
}sortBy() operation is shown in the figure:
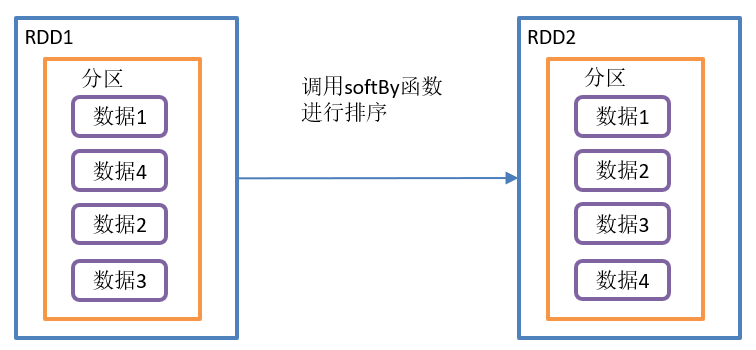
sortBy() function structure:
def sortBy[K](
f: (T) => K,
ascending: Boolean = true,
numPartitions: Int = this.partitions.length)
(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T] = withScope {
this.keyBy[K](f)
.sortByKey(ascending, numPartitions)
.values
}
Function introduction:
- This operation is used to sort data.
- Before sorting, the data can be processed through the f function, and then sorted according to the processing results of the f function. The default is positive order.
- By default, the number of partitions of the newly generated RDD after sorting is the same as that of the original RDD.
- You can adjust the number of target partitions through the numPartitions parameter.
pipe() call script
Requirements:
Write a script and use the pipeline to act on the RDD.
Code implementation:
# Write a script and increase the execution permission
[root@node001 spark]$ vim pipe.sh
#!/bin/sh
echo "Start"
while read LINE; do
echo ">>>"${LINE}
done
[root@node001 spark]$ chmod 777 pipe.sh
# Create an RDD with only one partition
scala> val rdd = sc.makeRDD (List("hi","Hello","how","are","you"),1)
# Apply the script to the RDD and print it
scala> rdd.pipe("/opt/module/spark/pipe.sh").collect()
res18: Array[String] = Array(Start, >>>hi, >>>Hello, >>>how, >>>are, >>>you)
#Create an RDD with two partitions
scala> val rdd = sc.makeRDD(List("hi","Hello","how","are","you"),2)
# Apply the script to the RDD and print it
scala> rdd.pipe("/opt/module/spark/pipe.sh").collect()
res19: Array[String] = Array(Start, >>>hi, >>>Hello, Start, >>>how, >>>are, >>>you)The pipe() operation is shown in the figure:

pipe() function structure:
def pipe(command: String): RDD[String] = withScope {
// Similar to Runtime.exec(), if we are given a single string, split it into words
// using a standard StringTokenizer (i.e. by spaces)
pipe(PipedRDD.tokenize(command))
}
Function introduction:
- The pipeline calls the shell script once for each partition and returns the output RDD
-
The script should be placed where the worker node can access it
-
Each partition executes the script once, but each element is a line in standard input
Double Value type interaction
The common operators of double Value interaction are union, intersection and difference sets in mathematics.
union() Union, subtract() difference, intersection()
Requirements:
Create two RDD S, union, intersection and difference
Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
aggTest(sc)
//4. Close the connection
sc.stop()
}
/**
* Union, intersection and difference sets
* */
def aggTest(sc: SparkContext): Unit ={
// 3.1 create the first RDD
val rdd1: RDD[Int] = sc.makeRDD (1 to 6)
val rdd2: RDD[Int] = sc.makeRDD (4 to 10)
// 3.2 requirements realization
// Union
val value1: Array[Int] = rdd1.union(rdd2).collect()
// Difference set
val value2: Array[Int] = rdd1.subtract(rdd2).collect()
// intersection
val value3: Array[Int] = rdd1.intersection(rdd2).collect()
// 3.3 printing
println("Union:" + value1.mkString(","))
println("Difference set:" + value2.mkString(","))
println("Intersection:" + value3.mkString(","))
}
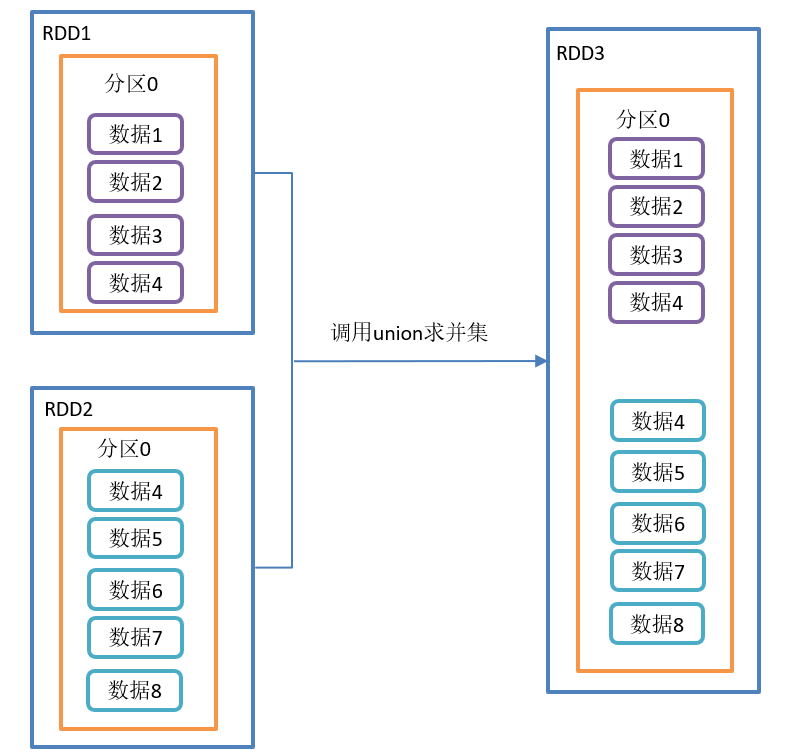
}union() union operation is shown in the figure:
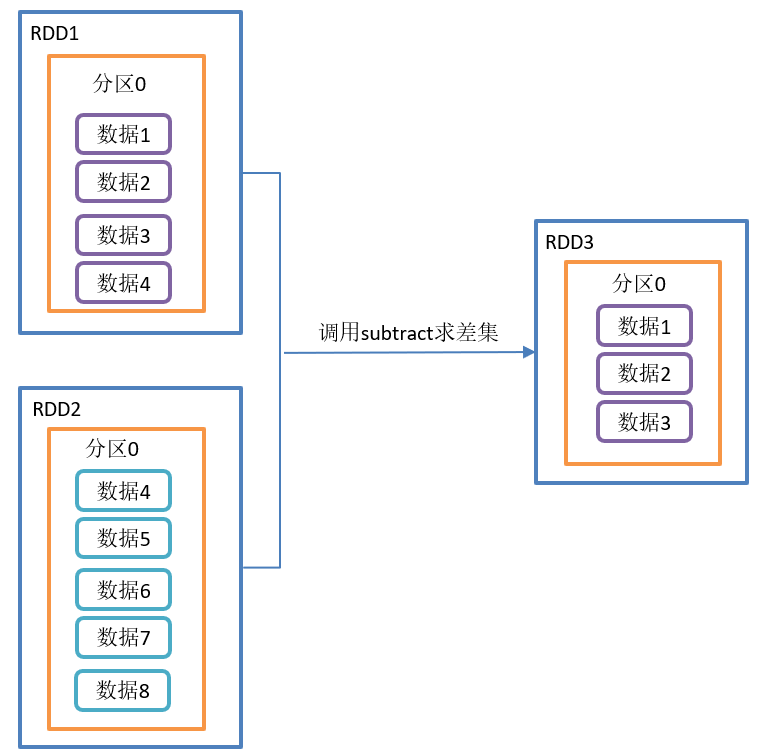
The subtract() difference set operation is shown in the figure:
The intersection operation of intersection() is shown in the figure:

union() function structure:
def union(other: RDD[T]): RDD[T] = withScope {
sc.union(this, other)
}
Structure of the subtract() function:
def subtract(other: RDD[T]): RDD[T] = withScope {
subtract(other, partitioner.getOrElse(new HashPartitioner(partitions.length)))
}
Structure of intersection() function:
def intersection(other: RDD[T]): RDD[T] = withScope {
this.map(v => (v, null)).cogroup(other.map(v => (v, null)))
.filter { case (_, (leftGroup, rightGroup)) => leftGroup.nonEmpty && rightGroup.nonEmpty }
.keys
}
Function introduction:
- Union: a new RDD is returned after union of the source RDD and the parameter RDD
- Difference set: a function to calculate the difference. Remove the same elements in two RDDS, and different RDDS will be retained
-
Intersection: returns a new RDD after intersecting the source RDD and the parameter RDD
Zip (zipper)
Requirements:
Create two RDDS and combine them to form a (k,v)RDD
Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
zipTest(sc)
//4. Close the connection
sc.stop()
}
/**
* zip zipper
* */
def zipTest(sc: SparkContext): Unit ={
// 3.1 create the first RDD
val rdd1: RDD[Int] = sc.makeRDD (1 to 3,2)
val rdd2: RDD[String] = sc.makeRDD (List("a","b","c"),2)
// 3.2 requirements realization
val value: Array[(String, Int)] = rdd2.zip(rdd1).collect()
// 3.3 printing
println(value.mkString(","))
}
}The zip() operation is shown in the figure:
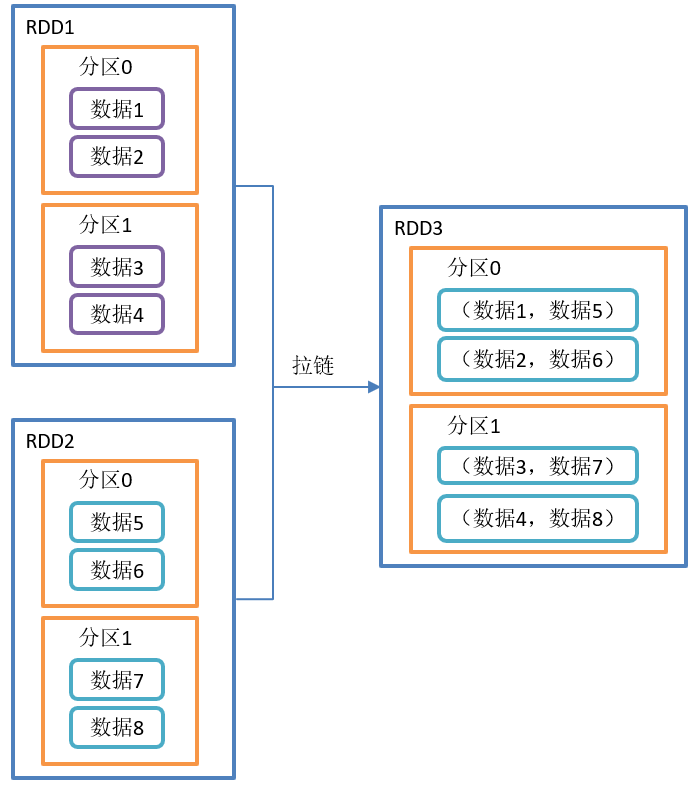
zip() function structure:
def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)] = withScope {
......
}
Function introduction:
- This operation can merge the elements in two RDDS in the form of Key Value pairs. Where, the Key in the Key Value pair is the element in the first RDD, and the Value is the element in the second RDD.
- Combine the two RDDS into an RDD in the form of Key/Value. By default, the number of partition s and elements of the two RDDS are the same, otherwise an exception will be thrown.
Key value type
partitionBy() repartition by k
Requirements:
Create an RDD with 5 partitions and repartition it.
Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
partitionByKeyTest(sc)
//4. Close the connection
sc.stop()
}
/**
* partitionByKey:Repartition according to key
* */
def partitionByKeyTest(sc: SparkContext): Unit ={
val tuples: List[(Int, String)] = List((1, "a"), (2, "b"), (3, "c"), (4, "d"), (1, "aa"), (1, "bb"), (3, "cc"), (4, "dd")
,(1,"aaa"),(2,"bbb"),(3,"ccc"),(4,"ddd"))
// 3.1 create the first RDD
val rdd: RDD[(Int, String)] = sc.makeRDD (tuples,5)
rdd.cache()
println("-------Before partition-------")
val value1: String = rdd.mapPartitionsWithIndex((index: Int, data: Iterator[(Int, String)]) => {
data.map((index,_))
}).collect().mkString("\t")
println(value1)
// 3.2 requirements realization
val value: RDD[(Int, String)] = rdd.partitionBy(new HashPartitioner(3))
// 3.3 printing
println("-------After partition-------")
val value2: String = value.mapPartitionsWithIndex((index: Int, data: Iterator[(Int, String)]) => {
data.map((index,_))
}).collect().mkString("\t")
println(value2)
}
}The partitionBy() operation is shown in the figure below:
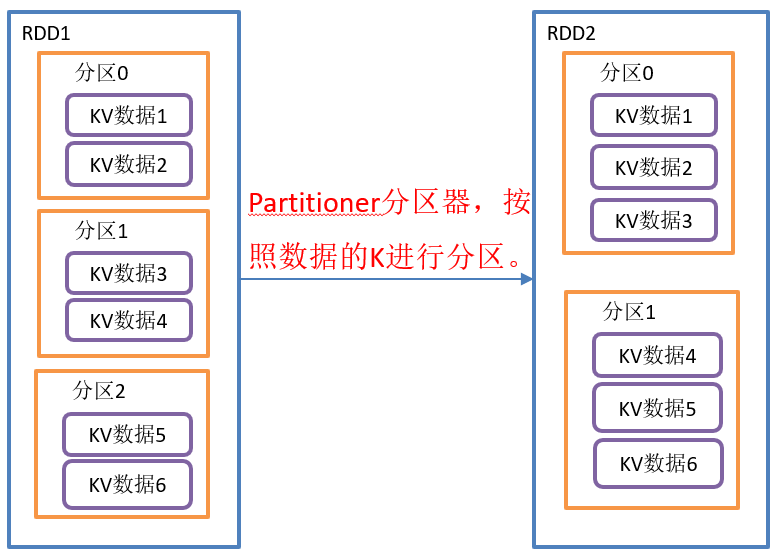
partitionBy() function structure:
def partitionBy(partitioner: Partitioner): RDD[(K, V)] = self.withScope {
if (keyClass.isArray && partitioner.isInstanceOf[HashPartitioner]) {
throw new SparkException("HashPartitioner cannot partition array keys.")
}
if (self.partitioner == Some(partitioner)) {
self
} else {
new ShuffledRDD[K, V, V](self, partitioner)
}
}
Function introduction:
- Re partition K in RDD[K,V] according to the specified Partitioner; A Shuffle process is generated.
- If the original partionRDD is consistent with the existing partionRDD, it will not be partitioned, otherwise it will be partitioned.
- The default partitioner is HashPartitioner.
remarks:
1. The principle of HashPartitioner is:
- The partition id value of the next RDD corresponding to the key value is obtained after the data is modeled according to the hashCode value of the key value in the RDD,
- Supports the case where the key value is null. When the key is null, it returns 0;
- The partitioning device is basically suitable for partitioning data of all RDD data types.
2. For the detailed principle of the divider, please refer to: [spark] - hashpartitioner & rangepartitioner differences
be careful:
1. Because the hashCode of the array in JAVA is based on the array object itself, not the array content, if the RDD key is an array type, the data key with consistent data content may not be allocated to the same RDD partition. (not measured)
2. In scala, if the key of RDD is Array type, the compilation fails. Exception in thread "main" org.apache.spark.SparkException: HashPartitioner cannot partition array keys.
At this time, it is best to customize the data partition, partition the array content, or convert the array content into a collection.
Custom partition
class MyPartitioner(num: Int) extends Partitioner {
// Number of partitions set
override def numPartitions: Int = num
// Specific partition logic
override def getPartition(key: Any): Int = {
if (key.isInstanceOf[Int]) {
val keyInt: Int = key.asInstanceOf[Int]
if (keyInt % 2 == 0)
0
else
1
}else{
0
}
}
}
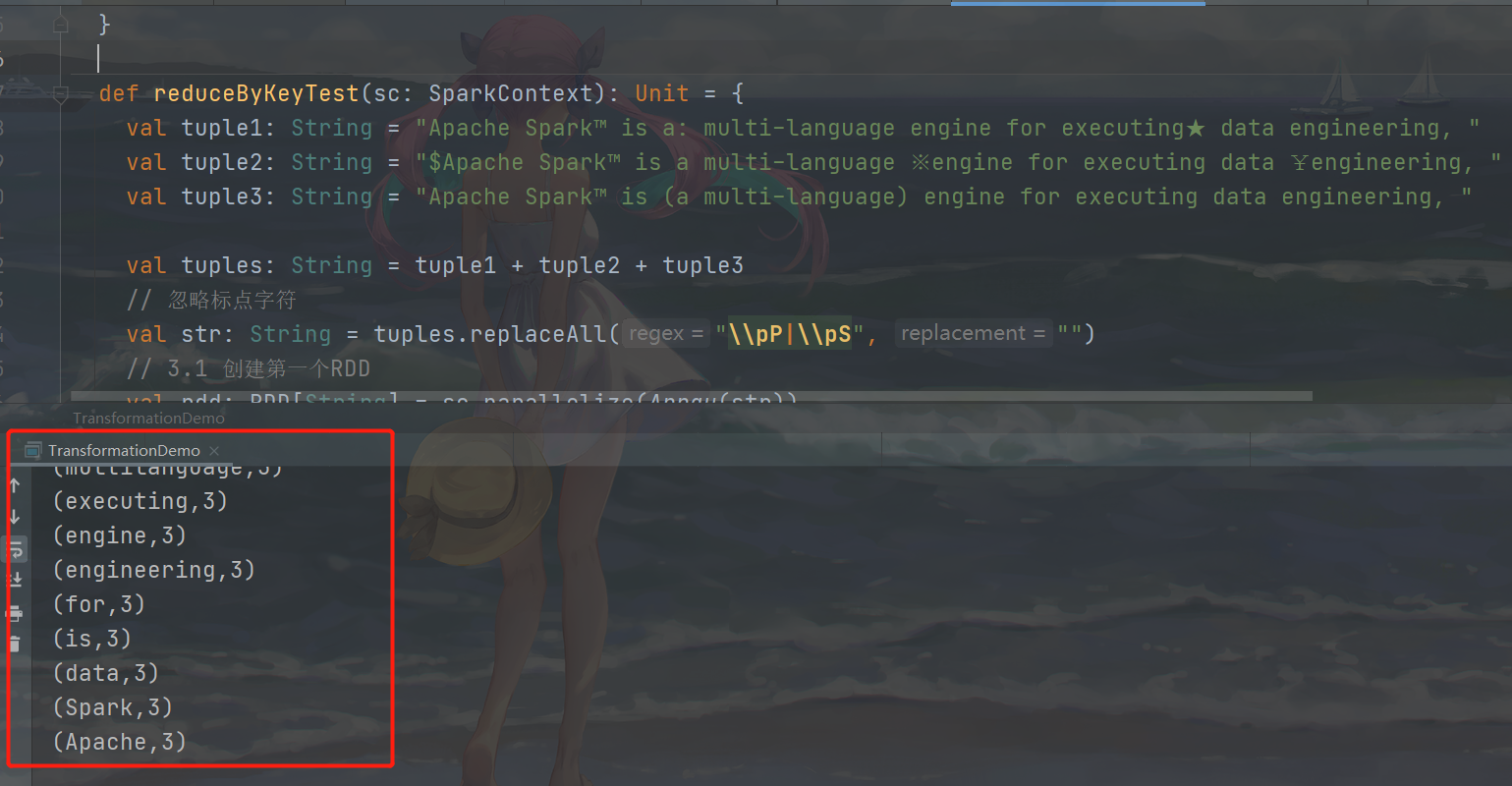
reduceByKey() aggregates by k v
Requirements:
Count the number of word occurrences (wordCount).
Code implementation:
In order to increase the difficulty, this experiment adds some Chinese and English characters to the string.
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
reduceByKeyTest(sc)
//4. Close the connection
sc.stop()
}
def reduceByKeyTest(sc: SparkContext): Unit = {
val tuple1: String = "Apache Spark™ is a: multi-language engine for executing★ data engineering, "
val tuple2: String = "$Apache Spark™ is a multi-language ※engine for executing data ¥engineering, "
val tuple3: String = "Apache Spark™ is (a multi-language) engine for executing data engineering, "
val tuples: String = tuple1 + tuple2 + tuple3
// Ignore punctuation characters
val str: String = tuples.replaceAll("\\pP|\\pS", "")
// 3.1 create the first RDD
val rdd: RDD[String] = sc.parallelize(Array(str))
// 3.2 requirements realization
val value2: String = rdd.flatMap(f => f.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.collect()
.mkString("\n")
// 3.3 printing
println(value2)
}
}
Operation results:
Note: regular expression filter string method
/pP: the lowercase P means property, represents Unicode property, and is used as the prefix of Unicode positive expression. The capital P represents one of the seven character attributes of the Unicode character set: the punctuation character.
The other six are:
50: L etters;
M: Marking symbols (generally not appear separately);
Z: Delimiters (such as spaces, line breaks, etc.);
S: Symbols (such as mathematical symbols, currency symbols, etc.);
N: Numbers (such as Arabic numerals, Roman numerals, etc.);
C: Other characters
The reduceByKey() operation is shown in the figure below:
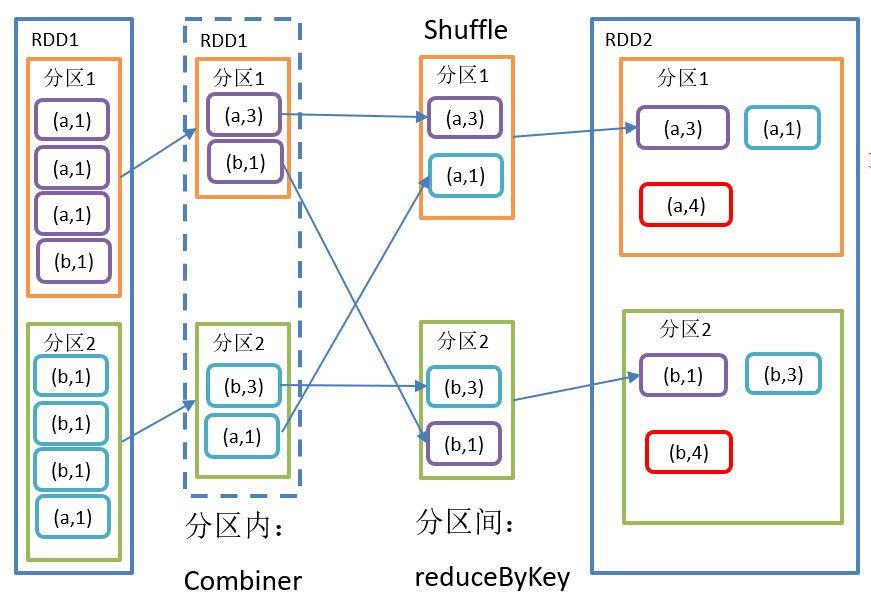
reduceByKey() function structure:
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)] = self.withScope {
combineByKeyWithClassTag[V]((v: V) => v, func, func, partitioner)
}
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)] = self.withScope {
reduceByKey(new HashPartitioner(numPartitions), func)
}
def reduceByKey(func: (V, V) => V): RDD[(K, V)] = self.withScope {
reduceByKey(defaultPartitioner(self), func)
}
Function introduction:
- This operation can aggregate the elements in RDD[K,V] to V according to the same K.
- There are many overload forms, and you can also set the number of partitions of the new RDD.
- The default partitioner is HashPartitioner
groupByKey() regroups by k
Requirements:
Find the average number of abc occurrences in the List(("a",1),("b",5),("a",5),("b",2),("a",1),("c",5),("b",5),("b",2)).
Function implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
groupByKeyTest(sc)
//4. Close the connection
sc.stop()
}
/**
* groupByKey():Group by key
* */
def groupByKeyTest(sc: SparkContext): Unit = {
// 3.1 create the first RDD
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("a",1),("c",15),("a",5),("b",2),("a",1),("c",9),("b",5),("b",2)), 2)
// 3.2 requirements realization
val value: Array[(String, String)] = rdd.groupByKey().map(f => {
val format: DecimalFormat = new DecimalFormat("#0.00")
val sum: Int = f._2.sum
val count: Int = f._2.size
val nums: Double = sum.toDouble / count
(f._1,format.format(nums))
}).collect()
// 3.3 printing
println(value.mkString("\n"))
}
}Note: DecimalFormat class.
This class mainly uses # and 0 placeholders to specify the length of numbers. 0 indicates that if the number of digits is insufficient, it is filled with 0, # indicating that the number is pulled to this position whenever possible.
For example: #. 00 means to keep two digits after the decimal point. It is uncertain before the decimal point. Any number of digits is OK.
00.00 represents two digits of the integer part, which is insufficient to be supplemented with 0; The decimal part has 2 digits, and if it is insufficient, it shall be supplemented with 0.
The groupByKey() operation is shown in the figure below:
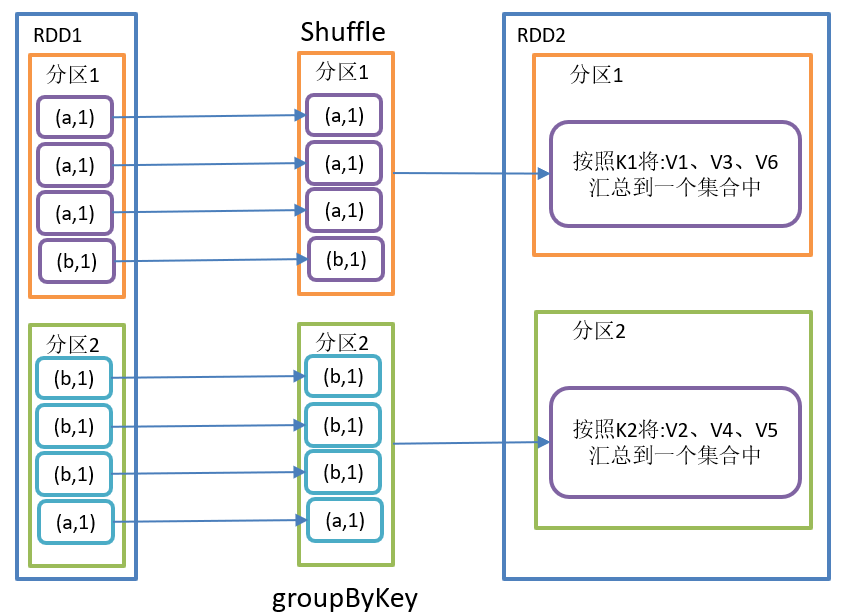
groupByKey() function structure:
def groupByKey(): RDD[(K, Iterable[V])] = self.withScope {
groupByKey(defaultPartitioner(self))
}
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])] = self.withScope {
}
def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])] = self.withScope {
groupByKey(new HashPartitioner(numPartitions))
}
Function introduction:
- groupByKey operates on each key, but only generates one seq without aggregation.
- This operation can specify the partitioner or the number of partitions (HashPartitioner is used by default)
remarks: Difference between reduceByKey and groupByKey
- reduceByKey: aggregate by key. There is a combine operation before shuffle. The returned result is RDD[k,v].
- groupByKey: group by key and shuffle directly.
- Development guidance:
- reduceByKey is preferred without affecting business logic.
- Summation does not affect business logic, and averaging affects business logic.
aggregateByKey() performs intra partition and inter partition logic according to k
demand
Create an RDD, take out the maximum value of the corresponding value of the same key in each partition in the RDD, and then add it.
Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
aggregateByKeyTest(sc)
//4. Close the connection
sc.stop()
}
/**
* Take out the maximum value of the corresponding value of the same key in each partition, and then add it
* */
def aggregateByKeyTest(sc: SparkContext): Unit = {
// 3.1 create the first RDD
val array: Array[(String, Int)] = Array(("a", 3), ("a", 2), ("c", 4), ("b", 3), ("c", 6), ("c", 8))
val rdd: RDD[(String, Int)] = sc.makeRDD(array, 2)
// 3.2 take out the maximum value of the corresponding value of the same key in each partition and add it
// val value: RDD[(String, Int)] = rdd.aggregateByKey(0)(math.max, _ + _)
// Do not use the math function
val value: RDD[(String, Int)] = rdd.aggregateByKey(0)((a: Int, b: Int) => {
if (a > b) a else b
}, _ + _)
// 3.3 printing results
value.foreach(println)
}The aggregateByKey() operation is shown in the figure:

Function structure:
def aggregateByKey[U: ClassTag](zeroValue: U, partitioner: Partitioner)(
seqOp: (U, V) => U,
combOp: (U, U) => U): RDD[(K, U)] = self.withScope {
*********
}
Function introduction:
(1) Zero value: an initial value for each key in each partition;
(2) seqOp (in partition): the function is used to iterate value step by step with the initial value in each partition;
(3) combOp (between partitions): the function is used to merge the results in each partition.
foldByKey() partition aggregateByKey() with the same logic between kernel partitions
Requirements:
Find a worldcount from the data in the above example.
Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
foldByKeyTest(sc)
//4. Close the connection
sc.stop()
}
def foldByKeyTest(sc: SparkContext): Unit = {
// 3.1 create the first RDD
val array: Array[(String, Int)] = Array(("a", 3), ("a", 2), ("c", 4), ("b", 3), ("c", 6), ("c", 8))
val rdd: RDD[(String, Int)] = sc.makeRDD(array)
// 3.2 worldcount
// val value: RDD[(String, Int)] = rdd.aggregateByKey(0)(_+_, _ + _)
val value: RDD[(String, Int)] = rdd.foldByKey(0)(_ + _)
// 3.3 printing
value.foreach(println)
}foldByKey() operation is shown in the figure:

foldByKey() function structure:
def foldByKey(
zeroValue: V,
partitioner: Partitioner)(func: (V, V) => V): RDD[(K, V)] = self.withScope {
........
}
Function introduction:
- The simplified operation of aggregateByKey is the same as seqop and combop. That is, the intra partition logic and inter partition logic are the same.
-
Parameter zeroValue: is an initialization value, which can be of any type
- Parameter func: it is a function, and the two input parameters are the same
combineByKey() operation within and between partitions after structure conversion
Requirements:
Create a pairRDD and calculate the average value of each key according to the key.
Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
combineKeyTest(sc)
//4. Close the connection
sc.stop()
}
def combineKeyTest(sc: SparkContext): Unit = {
// 3.1 create the first RDD
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98)))
// 3.2 requirement implementation: add the values corresponding to the same key, record the number of occurrences of the key, and put it into a binary
val value: Array[(String, String)] = rdd.combineByKey(
(_, 1),
(acc: (Int, Int), other: Int) => (acc._1 + other, acc._2 + 1), // Note: the type here must be added manually, otherwise it cannot be used
(acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2)
).map(f => {
val format: DecimalFormat = new DecimalFormat("#0.00")
(f._1, format.format(f._2._1 / f._2._2.toDouble))
}).collect()
// 3.3 printing
println(value.mkString("\n"))
}
}The combineByKey() operation is shown in the figure:
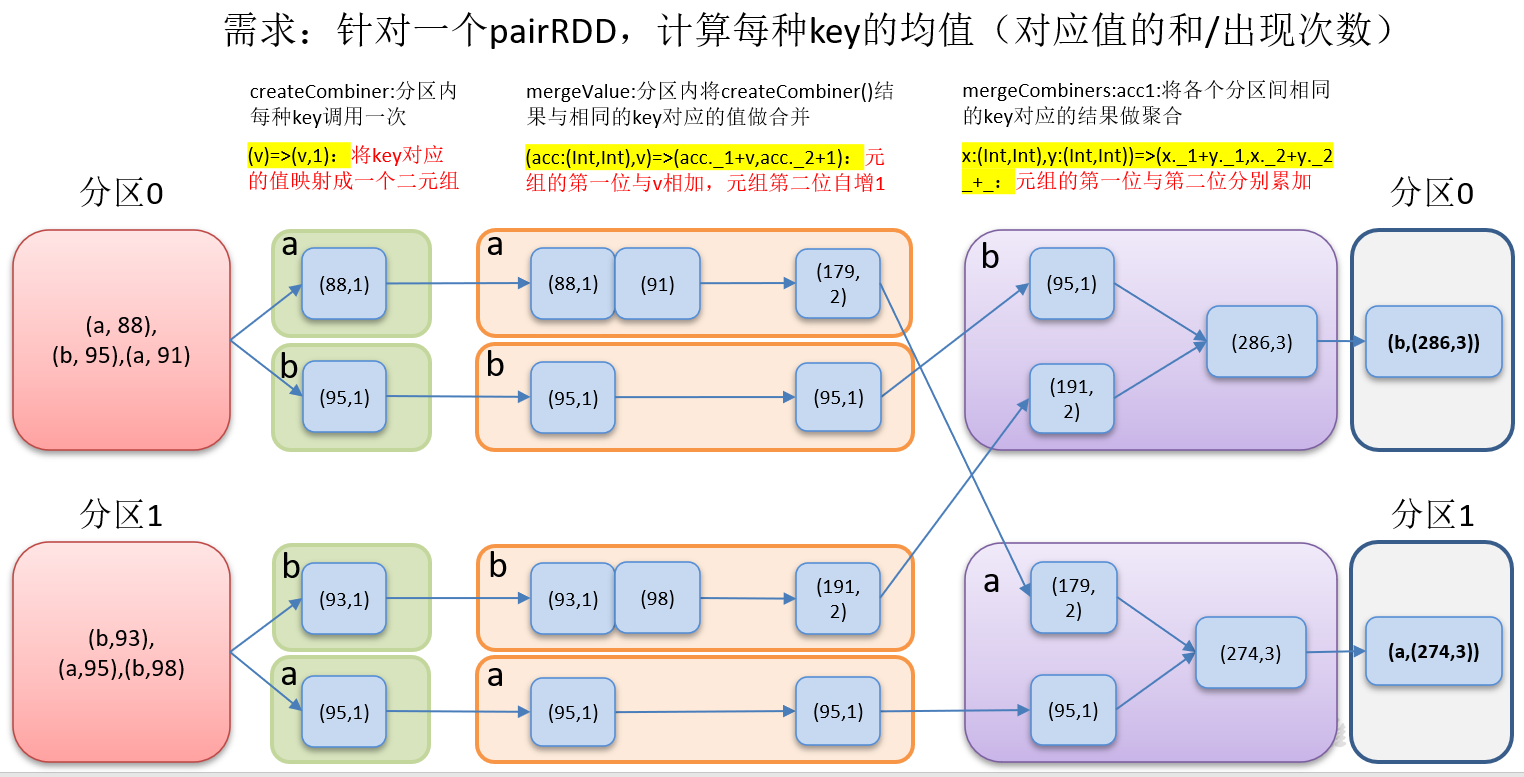
combineByKey() function functions:
def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C,
partitioner: Partitioner,
mapSideCombine: Boolean = true,
serializer: Serializer = null): RDD[(K, C)] = self.withScope {
combineByKeyWithClassTag(createCombiner, mergeValue, mergeCombiners,
partitioner, mapSideCombine, serializer)(null)
}
def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C,
numPartitions: Int): RDD[(K, C)] = self.withScope {
combineByKeyWithClassTag(createCombiner, mergeValue, mergeCombiners, numPartitions)(null)
}
Function introduction:
- Createcombiner: v = > the function to create a combination in the C group. The popular point is to initialize the read data. It takes the current value as a parameter, and can perform some conversion operations on the value to convert it into the data format we want
- Mergevalue: (C, V) = > C this function is mainly a merge function within a partition and acts inside each partition. Its function is mainly to merge V into the element C of the previous (createCombiner). Note that C here refers to the data format after the conversion of the previous function, and V here refers to the original data format (the previous function is before the conversion)
- Mergecombiners: (C, c) = > r this function is mainly used to merge multiple partitions. At this time, two C are merged into one C. for example, two C:(Int) are added to get an R:(Int)
remarks: The differences and relationships between reduceByKey, aggregateByKey, foldByKey and combineByKey on key aggregation
- The four underlying layers call combineByKeyWithClassTag
- reduceByKey has no initial value, and the logic within and between partitions is the same
- The first initial value of aggregateByKey is consistent with the processing rules in the partition, and the logic within and between partitions can be different
-
foldByKey has an initial value, and the logic within and between partitions is consistent
-
The initial value of combineByKey can change its structure, and the logic within and between partitions is different
sortByKey() sorts by k
Requirements:
Create a pairRDD and sort according to the positive and reverse order of key s
Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
sortByKeyTest(sc)
//4. Close the connection
sc.stop()
}
/**
* sortByKeyTest():When called on a (K,V) RDD, K must implement the Ordered interface and return a (K,V) RDD sorted by key
* */
def sortByKeyTest(sc: SparkContext): Unit = {
// 3.1 create the first RDD
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98)))
// 3.2 requirements realization
val value1: Array[(String, Int)] = rdd.sortByKey().collect()
val value2: Array[(String, Int)] = rdd.sortByKey(false).collect()
// 3.3 printing
println(value1.mkString("\n"))
println("--------------------------")
println(value2.mkString("\n"))
}
}sortByKey() operation is shown in the figure:
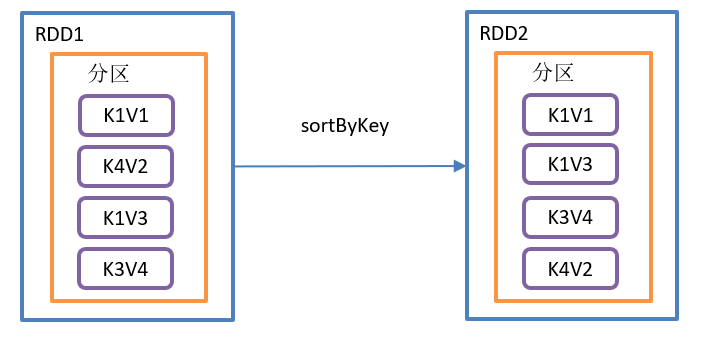
sortByKey() function structure:
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length)
: RDD[(K, V)] = self.withScope
{
val part = new RangePartitioner(numPartitions, self, ascending)
new ShuffledRDD[K, V, V](self, part)
.setKeyOrdering(if (ascending) ordering else ordering.reverse)
}
Function introduction:
- When called on a (K,V) RDD, K must implement the Ordered interface and return a (K,V) RDD sorted by key
- Default ascending order
mapValues() operates on v only
Requirements:
Create a pairRDD and convert the value data to uppercase.
Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
mapValuesTest(sc)
//4. Close the connection
sc.stop()
}
/**
* mapValuesTest():Operate on Values only
* */
def mapValuesTest(sc: SparkContext): Unit = {
// 3.1 create the first RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(List((1, "a"), (2, "b"), (3, "c"), (4, "d"), (1, "aa"), (1, "bb"), (3, "cc")))
// 3.2 requirements realization
val value: Array[(Int, String)] = rdd.mapValues(_.toUpperCase).collect()
// 3.3 printing
println(value.mkString("\n"))
}
}mapValues() operation is shown in the figure:

mapValues() function structure:
def mapValues[U](f: V => U): RDD[(K, U)] = self.withScope {
val cleanF = self.context.clean(f)
new MapPartitionsRDD[(K, U), (K, V)](self,
(context, pid, iter) => iter.map { case (k, v) => (k, cleanF(v)) },
preservesPartitioning = true)
}
Function introduction:
For types in the form of (K,V), only V is operated on
join() associates multiple v's corresponding to the same k
Requirements:
Create two pairrdds and aggregate the data with the same key into a tuple.
Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
joinTest(sc)
//4. Close the connection
sc.stop()
}
/**
* joinTest():Call on RDDS of types (K,V) and (K,W) to return the RDD of (K,(V,W)) of all element pairs corresponding to the same key
* */
def joinTest(sc: SparkContext): Unit = {
//3.1 create a second RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"), (2, "b"), (3, "c"),(0,"Fatal Frame")))
val rdd1: RDD[(Int, Int)] = sc.makeRDD(Array((1, 4), (2, 5), (4, 6)))
// 3.2 requirements realization
val value: Array[(Int, (String, Int))] = rdd.join(rdd1).collect()
// 3.3 printing
println(value.mkString("\n"))
}
}The join() operation is shown in the figure:
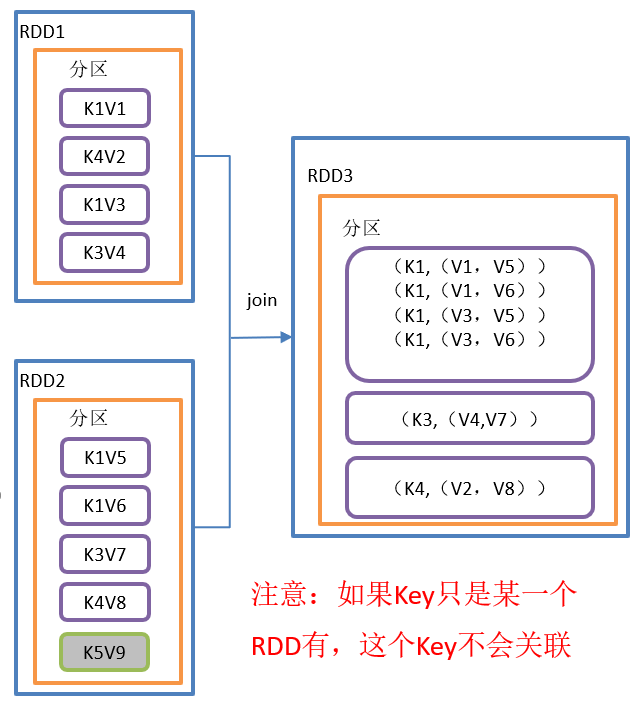
join() function structure:
def join[W](other: RDD[(K, W)], partitioner: Partitioner): RDD[(K, (V, W))] = self.withScope {
this.cogroup(other, partitioner).flatMapValues( pair =>
for (v <- pair._1.iterator; w <- pair._2.iterator) yield (v, w)
)
}
Function introduction:
Call on RDDS of types (K,V) and (K,W) to return the RDD of (K,(V,W)) of all element pairs corresponding to the same key
Expansion: left external connection, right external connection and all external connection
The return type is: (Int, (String, Option[Int]).
Option[A] (sealed trait) has two values:
1. Some[A] has a value of type A
2. None has no value
Generally through F_ 2._ 2. Getorelse ("default value") gets the value.
Left external connection (left connection): both on the left and not on the right. It is represented by None,
def leftOuterJoin[W](other: RDD[(K, W)], partitioner: Partitioner)
Right external connection (right connection): both on the right and not on the left. It is represented by None
def rightOuterJoin[W](other: RDD[(K, W)], partitioner: Partitioner)
All external connections (all connections): there are both left and right, but they are not related. It is represented by None,
def fullOuterJoin[W](other: RDD[(K, W)], partitioner: Partitioner)
cogroup() is similar to full join, but aggregates k in the same RDD
Requirements:
Create two pairrdds and aggregate the data with the same key into an iterator.
Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
cogroupTest(sc)
//4. Close the connection
sc.stop()
}
/**
* cogroupTest():Called on RDDS of types (K,V) and (K,W), returns an RDD of type (k, (iteratable < V >, iteratable < w >))
* */
def cogroupTest(sc: SparkContext): Unit = {
//3.1 create a second RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"), (3, "cC"), (2, "b"), (3, "c"),(0,"Fatal Frame"),(1, "aA")))
val rdd1: RDD[(Int, Int)] = sc.makeRDD(Array((1, 4), (2, 5), (2, 55),(4, 6),(1, 44)))
// 3.2 requirements realization
val value: Array[(Int, (Iterable[String], Iterable[Int]))] = rdd.cogroup(rdd1).collect()
// 3.3 printing
println(value.mkString("\n"))
}
}The operation of cogroup() is shown in the figure:
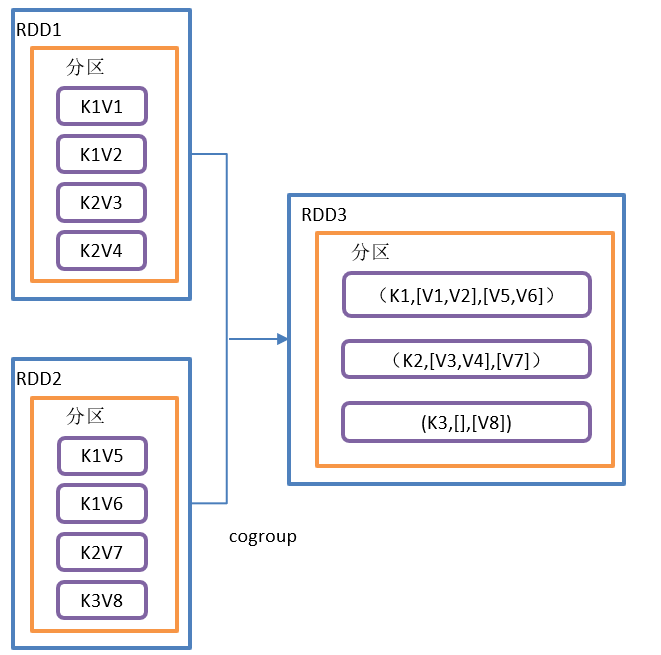
cogroup() function structure:
def cogroup[W](other: RDD[(K, W)]): RDD[(K, (Iterable[V], Iterable[W]))] = self.withScope {
cogroup(other, defaultPartitioner(self, other))
}
Function introduction:
Called on RDDS of types (K,V) and (K,W), returns an RDD of type (k, (iteratable < V >, iteratable < w >))
Part II: Action operator
The action operator triggers the execution of the whole job. Because the conversion operators are lazy loading and will not be executed immediately. Common action operators are as follows.
Note: for convenience, the test of action operator will also be implemented under the object TransformationDemo package. Do not create a new package.
reduce() aggregation
1) Function signature: def reduce (F: (T, t) = > t): t
2) Function Description: the f function aggregates all elements in RDD, first aggregates data in partitions, and then aggregates data between partitions.
3) Requirement Description: create an RDD and aggregate all elements to get the result
4) The code is as follows:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
reduceTest(sc)
//4. Close the connection
sc.stop()
}
/**
* Action operator:
* reduce:Aggregate all elements in RDD
* */
def reduceTest(sc: SparkContext): Unit = {
//3.1 create a second RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"), (3, "cC"), (2, "b"), (3, "c"),(0,"Fatal Frame"),(1, "aA")))
val rdd1: RDD[Int] = sc.makeRDD(1 to 10)
// 3.2 requirements realization
val value: (Int, String) = rdd.reduce((k1: (Int, String), k2: (Int, String)) => (k1._1 + k2._1,k1._2 + k2._2))
val value1: Int = rdd1.reduce(_+_)
// 3.3 printing
println(value)
println(value1)
}
}collect() returns a dataset as an array
1) Function signature: def collect(): Array[T]
2) Function Description: in the driver, all elements of the dataset are returned in the form of Array array.
Note: all data will be pulled to the Driver. When the amount of data is large, OOM will occur. Use with caution.
3) Requirement Description: create an RDD and collect the RDD content to the Driver side for printing
4) Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
collectTest(sc)
//4. Close the connection
sc.stop()
}
/**
* Action operator:
* collect:Collect data to the Driver end and return it in the form of array.
* */
def collectTest(sc: SparkContext): Unit = {
//3.1 create a second RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"), (3, "cC"), (2, "b"), (3, "c"),(0,"Fatal Frame"),(1, "aA")))
// 3.2 requirements realization
val value: Array[(Int, String)] = rdd.collect()
// 3.3 printing
value.foreach(println)
}
}count() returns the number of elements in the RDD
1) Function signature: def count(): Long
2) Function Description: returns the number of elements in RDD.
3) Requirement Description: create an RDD and count the number of RDDS.
4) Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
countTest(sc)
//4. Close the connection
sc.stop()
}
/**
* Action operator:
* count:Returns the number of RDD S
* */
def countTest(sc: SparkContext): Unit = {
//3.1 create a second RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"), (3, "cC"), (2, "b"), (3, "c"),(0,"Fatal Frame"),(1, "aA")))
// 3.2 requirements realization
val value: Long = rdd.count()
// 3.3 printing
println(value)
}
}first() returns the first element in the RDD
1) Function signature: def first(): T
2) Function Description: returns the first element in RDD.
3) Requirement Description: create an RDD and return the first element in the RDD.
4) Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
firstTest(sc)
//4. Close the connection
sc.stop()
}
/**
* Action operator:
* first:Return the first data in RDD
* */
def firstTest(sc: SparkContext): Unit = {
//3.1 create a second RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"), (3, "cC"), (2, "b"), (3, "c"),(0,"Fatal Frame"),(1, "aA")))
// 3.2 requirements realization
val value: (Int, String) = rdd.first()
// 3.3 printing
println(value)
}
}take(n) returns an array of the first n RDD elements
1) Function signature: def take(num: Int): Array[T]
2) Function Description: returns an array composed of the first n elements of RDD.
3) Requirement Description: returns the first three elements with the largest key value in RDD.
4) Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
takeTest(sc)
//4. Close the connection
sc.stop()
}
/**
* Action operator:
* take(n):Returns an array of the first n elements composed of RDD S.
* */
def takeTest(sc: SparkContext): Unit = {
//3.1 create a second RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"),(4, "4c"), (5, "5c"), (3, "cC"), (2, "b"), (6, "c"),(0,"Fatal Frame"),(7, "aA")))
// 3.2 requirements realization
val value: Array[(Int, String)] = rdd.sortByKey(false).take(3)
// 3.3 printing
println(value.mkString("\n"))
}
}takeOrdered(n) returns an array of the first n elements after RDD sorting
1) Function signature: def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T]
2) Function Description: returns an array composed of the first n elements sorted by the RDD. (default ascending order)
3) Requirement Description: create an RDD and get the first two elements after the RDD is sorted.
4) Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[*]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
takeTest(sc)
//4. Close the connection
sc.stop()
}
/**
* Action operator:
* takeOrdered(n):Returns an array of the first n elements sorted by the RDD
* */
def takeOrderedTest(sc: SparkContext): Unit = {
//3.1 create a second RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"),(4, "4c"), (5, "5c"), (3, "cC"), (2, "b"), (6, "c"),(0,"Fatal Frame"),(7, "aA")))
// 3.2 requirements realization
val value: Array[(Int, String)] = rdd.takeOrdered(5) // Ascending order
// Custom sorting (override compare method): descending
val value1: Array[(Int, String)] = rdd.takeOrdered(5)(new Ordering[(Int,String)](){
override def compare(x: (Int, String), y: (Int, String)): Int = y._1-x._1
})
// 3.3 printing
println(value.mkString("\n"))
println(value1.mkString("\n"))
}
}aggregate() case
1) Function signature: def aggregate [u: classtag] (zerovalue: U) (seqop: (U, t) = > u, combop: (U, U) = > U): u
2) Function Description: the aggregate function aggregates the elements in each partition through the logic and initial value in the partition, and then operates with the logic and zero value between partitions.
Note: 1. There is a difference between using the initial value again by the inter partition logic and aggregateByKey.
2. zeroValue is used once for intra partition aggregation and once for inter partition aggregation.
Operation flow diagram:

3) Requirement Description: create an RDD and add all elements to get the result.
4) Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[1]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
aggregateTest(sc)
//4. Close the connection
sc.stop()
}
/**
* Action operator:
* aggregateTest(n):aggregate The function aggregates the elements in each partition through the logic and initial value in the partition, and then operates with the logic and zero value between partitions
* */
def aggregateTest(sc: SparkContext): Unit = {
//3.1 create a second RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"),(2, "4c"), (3, "5c"), (4, "cC")),2)
// 3.2 requirements realization
val value: Int = rdd.aggregate(0)(
(a: Int, b: (Int, String)) => a + b._1,
(x: Int, y: Int) => x + y
)
val value3: Int = rdd.aggregate(10)(
(a: Int, b: (Int, String)) => a + b._1,
(x: Int, y: Int) => x + y
)
val value2: String = rdd.aggregate("x")(
(a: String, b: (Int, String)) => a + b._1,
(x: String, y: String) => x + y
)
// 3.3 printing
println(value)
println(value2)
println(value3)
}fold() case
1) Function signature: def fold (zerovalue: T) (OP: (T, t) = > t): t
2) Function Description: folding operation, simplified operation of aggregate. That is, the intra partition logic and inter partition logic are the same.
3) Requirement Description: create an RDD and add all elements to get the result.
4) Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[1]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
foldTest(sc)
//4. Close the connection
sc.stop()
}
/**
* Action operator:
* fold:Folding operation, simplified operation of aggregate. That is, the intra partition logic and inter partition logic are the same.
* */
def foldTest(sc: SparkContext): Unit = {
//3.1 create a second RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"),(2, "4c"), (3, "5c"), (4, "cC")),2)
// 3.2 requirements realization
val value: (Int, String) = rdd.fold((0," "))((z: (Int, String), x: (Int, String)) => (z._1 + x._1,x._2 + z._2))
// 3.3 printing
println(value)
}
}countByKey() counts the number of keys of each type
1) Function signature: def countByKey(): Map[K, Long]
2) Function Description: count the number of each key.
Note: it can be used to check whether the data is tilted.
3) Requirement Description: create a PairRDD and count the number of key s of each type.
4) Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[1]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
countByKeyTest(sc)
//4. Close the connection
sc.stop()
}
/**
* Action operator:
* countByKey:Count the number of key s of each type
* */
def countByKeyTest(sc: SparkContext): Unit = {
//3.1 create a second RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(List((1, "a"), (2, "b"), (3, "c"), (4, "d"), (1, "aa"), (1, "bb"), (3, "cc")))
// 3.2 requirements realization
val value: collection.Map[Int, Long] = rdd.countByKey()
// 3.3 printing
println(value)
}
}save correlation operator
1) saveAsTextFile(path) is saved as a Text file
(1) Function signature: def saveAsTextFile(path: String)
(2) Function Description: save the elements of the dataset to the HDFS file system or other supported file systems in the form of textfile. For each element, Spark will call the toString method to replace it with the text in the file.
2)saveAsSequenceFile(path) Save as Sequencefile file
(1) Function signature: def saveAsSequenceFile(path: String)
(2) Function Description: save the elements in the dataset to the specified directory in the format of Hadoop Sequencefile, which can enable HDFS or other file systems supported by Hadoop.
Note: only kv type RDD S have this operation, and single valued ones do not
3)saveAsObjectFile(path) Serialized objects are saved to a file
(1) Function signature: def saveAsObjectFile(path: String)
(2) Function Description: used to serialize elements in RDD into objects and store them in files.
Code demonstration:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[1]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
saveTest(sc)
//4. Close the connection
sc.stop()
}
/**
* Action operator:
* savexxx: Persist data locally (or HDFS)
* */
def saveTest(sc: SparkContext): Unit = {
//3.1 create RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(List((1, "a"), (2, "b"), (3, "c"), (4, "d"), (1, "aa"), (1, "bb"), (3, "cc")))
// 3.2 requirements realization
rdd.repartition(1).saveAsTextFile("file:///C:/tmp/output/txt/")
rdd.repartition(1).saveAsObjectFile("file:///C:/tmp/output/obj/")
rdd.repartition(1).saveAsSequenceFile("file:///C:/tmp/output/seq/")
}
}Foreach () & foreachpartition traverses every element in the RDD
1) Function signature: def foreach (F: T = > unit): Unit
2) Function Description: traverse each element in RDD and apply f function in turn.
Two forms of foreach operator operations are shown in the figure:

remarks:
1. When the collect operator is called, the data is printed at the Drive end; When the collect operator is not called, the data will not be returned to the Drive side, but directly printed on the Executor side.
2. Differences between foreach and foreachPartition:
foreach is to process data one by one;
Foreach partition is a partition that takes data from one partition. There is a lot of data information in one partition.
Therefore, in use, when we want to save the processing results to the database, we should use the foreachPartition method, which will be more efficient.
3) Requirement Description: create an RDD and print each element.
4) Code implementation:
object TransformationDemo {
def main(args: Array[String]): Unit = {
//1. Create SparkConf and set App name
val conf: SparkConf = new SparkConf().setMaster("local[1]")
.setAppName("TransformationDemo_test")
//2. Create SparkContext, which is the entry to submit Spark App
val sc: SparkContext = new SparkContext(conf)
//3. Specific business logic
foreachTest(sc)
//4. Close the connection
sc.stop()
}
/**
* Action operator:
* foreach And foreachPartition: traversing elements in RDD
* */
def foreachTest(sc: SparkContext): Unit = {
//3.1 create RDD
val rdd: RDD[Int] = sc.makeRDD(1 to 100,5)
// 3.2 requirements realization
rdd.foreach((f: Int) => println(TaskContext.getPartitionId() + "--" + f))
rdd.foreachPartition((f: Iterator[Int]) => println(TaskContext.getPartitionId() + "--" + f.mkString(",")))
}
}summary
So far, all the commonly used RDD operators have been summarized. Of course, there are many missing operators and methods that are not involved. Interested readers can study them by themselves.
The following is a summary of common interview questions about RDD operator:
- The difference between map and mapPartitions
map(): process one piece of data at a time.
mapPartitions(): process the data of one partition at a time. After the data of this partition is processed, the data of this partition in the original RDD can be released, which may lead to OOM.
Development guidance: when the memory space is large, it is recommended to use mapPartitions() to improve processing efficiency.
- The functions, differences and relations of coalesce and repartition operators
1) Relationship:
Both are used to change the number of partitions of RDD. The bottom layer of repartition calls the coalesce method: coalesce(numPartitions, shuffle = true)
2) Difference:
Shuffle will occur in repartition. coalesce will judge whether shuffle occurs according to the passed parameters.
Generally, repartition is used to increase the number of partitions of rdd, and coalesce is used to reduce the number of partitions.
Note:
1. The parameter filled in by coalesce is less than or equal to the partition quantity of RDD, and greater than will not work
2. Too small parameters in coalesce may lead to OOM. At this time, to ensure a small number of small files, you can use repetition.
- What should we pay attention to when using zip operator (that is, what situations can't be used)
In Spark, the number of elements and partitions of two RDD S must be the same, otherwise an exception will be thrown.
In fact, the essence is that the number of elements in each partition is the same
- The difference and relationship between aggregateByKey and aggregate.
The parameters and functions of aggregate and aggregateByKey are the same, except that there are more keys in aggregateByKey.
If the RDD is set to 2 partitions and 4 partitions respectively, then
- The output of aggregateByKey() is not affected because it processes the intra partition and inter partition logic according to K.
- It will affect the output result of aggregate. In the two partitions, the initial value is used 3 times in total; In the four partitions, the initial value was used five times.
- The difference between reduceByKey and groupByKey.
reduceByKey: aggregate by key. There is a combine operation before shuffle. The returned result is RDD[k,v].
groupByKey: group by key and shuffle directly. The return result is RDD [(k, iteratable [v]).
Development guidance: reduceByKey has better performance than groupByKey, and groupByKey will cause OOM. Recommended. However, attention should be paid to whether it will affect the business logic.
- The difference and relationship between reduceByKey and aggregateByKey.
reduceByKey can be considered as a simplified version of aggregateByKey.
aggregateByKey is divided into three parameters (zeroValue, seqOp and combOp). You can customize the initial value, intra partition and inter partition operations.
- The parameter function of combineByKey indicates the parameter call timing.
def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C): RDD[(K, C)]
(1) createCombiner: v = > the function to create a combination in the C group. It will traverse each key value pair in the partition. If this key is encountered for the first time, call the createCombiner function, pass in value, and get a value of type C. (if this key is not encountered for the first time, this method will not be called.)
(2) Mergevalue: (C, V) = > C this function is mainly a merge function within a partition and acts inside each partition. If you are not the first to encounter this key, call this function to merge.
(3) Mergecombines: (C, c) = > r this function is mainly used to merge multiple partitions. At this time, two C's are merged into one C. Merge the values of the same key across partitions.
Although the road is endless and faraway, I still want to pursue the truth in the world. --- Qu Yuan