summary
In the previous chapter, we have introduced various levels and some details of the Broker's file system. In this chapter, we will continue to understand some details of the three files CommitLog, IndexFile and ConsumerQueue in the logical storage layer. Finally, we will compare the persistence structure and design rationality of RocketMQ and Kafka.
CommitLog
Now, let's start with a few pointers of CommitLog
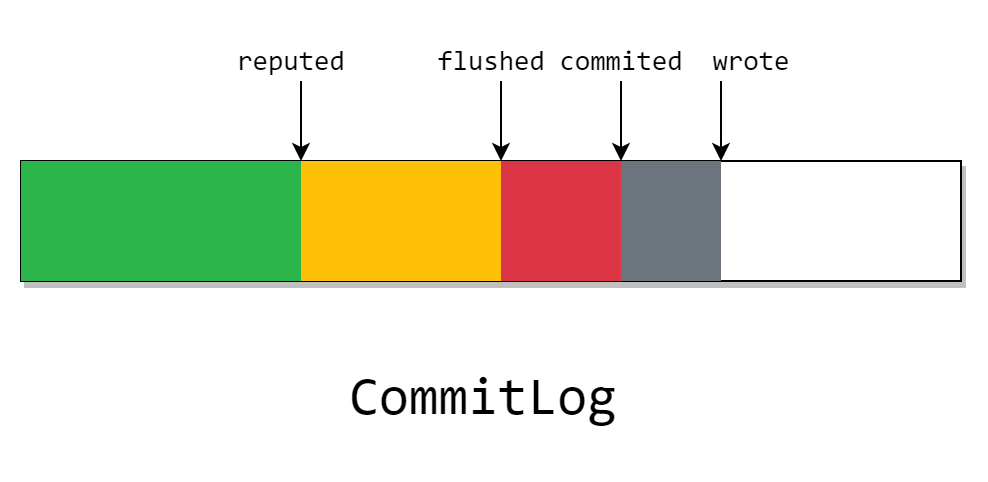
In the previous chapter< RocketMQ source code details | Broker Chapter II: file system >In, we have learned about the cache and disk brushing strategies of CommitLog. Now let's briefly comb them.
As described above, when CommitLog starts the transientStorePool, there will be a writeBuffer, which is an allocated piece of out of heap memory, that is, the gray part on the figure. The write pointer we see in the figure above points to the position where the writeBuffer has been written but there is no commit.
This gray part only exists in the Java process, that is, if the program crashes, it will be lost. And if the transientStorePool selection is turned off, the pointer will not exist.
Then, when we regularly brush writeBuffer into FileChannel, it becomes a red block in the figure. The committed pointer indicates that all previous messages have been flushed into the page cache.
This part of the message is stored in the page cache, and the page cache is a piece of memory in the operating system kernel, so the program will not be lost when it crashes, but it will still be lost after downtime.
However, CommitLog will perform disk flushing asynchronously or synchronously according to the specific disk flushing strategy, that is, the data before the flushed pointer has been completely stored in the disk.
And this piece of data will not be lost unless the media is destroyed.
After waiting for all CommitLogDispatcher processing to complete, the repeated pointer will advance. What this dispatch does is two things we didn't find when submitting messages: building IndexFile and ConsumerQueue.
It should be noted that in the figure, although the pointer is drawn as repeated, it is behind the flushed pointer. But in fact, the reputed pointer can be synchronized with the write pointer as soon as possible,
CommitLogDispatcher implementation classes include:
- CommitLogDispatcherBuildConsumeQueue
- CommitLogDispatcherBuildIndex
- CommitLogDispatcherCalcBitMap
These classes are described later
As we know from the previous chapter, the file structure of CommitLog is as follows:

Its length is fixed to 1G by default, and the file name is offset at the beginning. The message is of variable length. When a new message cannot be written at the end, a new file will be opened. And write the total length and magic number of the current file in the old file.
IndexFile
RocketMQ establishes an IndexFile to provide a method to query messages through a time range or Key value.
The file structure of IndexFile is as follows:

IndexFile can be divided into three parts
-
Header
The header records the start (minimum) time, end (maximum) time, start (minimum) offset, end (maximum) offset, and the number of slots and nodes
-
Slot Table
The slot of table records the pointer to the tail node in the current slot
-
Index Linked List
The index information of all nodes is recorded
It can be seen from the structure that IndexFile is a standard hash index. If you know the hash index, you can immediately guess the operation mechanism of IndexFile according to the above.
Next, enter the source code part
CommitLogDispatcher
ReputMessageService is a service started under the DefaultMessageStore class, that is, the storage component layer. The service executes deReput every second
private void doReput() {
if (this.reputFromOffset < DefaultMessageStore.this.commitLog.getMinOffset()) {
// The replay queue falls too far behind, causing the unreplayed commitLog to expire
log.warn("The reputFromOffset={} is smaller than minPyOffset={}, this usually indicate that the dispatch behind too much and the commitlog has expired.",
this.reputFromOffset, DefaultMessageStore.this.commitLog.getMinOffset());
this.reputFromOffset = DefaultMessageStore.this.commitLog.getMinOffset();
}
for (boolean doNext = true; this.isCommitLogAvailable() && doNext; ) {
/*
* When the system restarts, it will decide whether to start processing from scratch according to duplicationEnable
* Messages are still processed only for new messages. When it is on, you also need to set CommitLog.confirmOffset
* The message can be processed from the beginning, because by default, CommitLog.confirmOffset is set after the system is started
* And ReputMessageService.reputFromOffset are equal
*/
if (DefaultMessageStore.this.getMessageStoreConfig().isDuplicationEnable()
&& this.reputFromOffset >= DefaultMessageStore.this.getConfirmOffset()) {
break;
}
// Slice the ByteBuffer with the current reputed pointer as the starting point, and the length is to the current write pointer
SelectMappedBufferResult result = DefaultMessageStore.this.commitLog.getData(reputFromOffset);
if (result != null) {
try {
this.reputFromOffset = result.getStartOffset();
for (int readSize = 0; readSize < result.getSize() && doNext; ) {
// Build request for distribution
DispatchRequest dispatchRequest =
DefaultMessageStore.this.commitLog.checkMessageAndReturnSize(result.getByteBuffer(), false, false);
int size = dispatchRequest.getBufferSize() == -1 ? dispatchRequest.getMsgSize() : dispatchRequest.getBufferSize();
if (dispatchRequest.isSuccess()) {
if (size > 0) {
// Distribute requests to all processors
DefaultMessageStore.this.doDispatch(dispatchRequest);
// Processing of long polling
if (BrokerRole.SLAVE != DefaultMessageStore.this.getMessageStoreConfig().getBrokerRole()
&& DefaultMessageStore.this.brokerConfig.isLongPollingEnable()
&& DefaultMessageStore.this.messageArrivingListener != null) {
DefaultMessageStore.this.messageArrivingListener.arriving(dispatchRequest.getTopic(),
dispatchRequest.getQueueId(), dispatchRequest.getConsumeQueueOffset() + 1,
dispatchRequest.getTagsCode(), dispatchRequest.getStoreTimestamp(),
dispatchRequest.getBitMap(), dispatchRequest.getPropertiesMap());
}
// When finished, the offset of the playback pointer can be pushed forward
this.reputFromOffset += size;
readSize += size;
// Update measurement information
if (DefaultMessageStore.this.getMessageStoreConfig().getBrokerRole() == BrokerRole.SLAVE) {
DefaultMessageStore.this.storeStatsService
.getSinglePutMessageTopicTimesTotal(dispatchRequest.getTopic()).incrementAndGet();
DefaultMessageStore.this.storeStatsService
.getSinglePutMessageTopicSizeTotal(dispatchRequest.getTopic()).addAndGet(dispatchRequest.getMsgSize());
}
} else if (size == 0) {
// The current file has been read. Skip to the next file
this.reputFromOffset = DefaultMessageStore.this.commitLog.rollNextFile(this.reputFromOffset);
readSize = result.getSize();
}
} else if (!dispatchRequest.isSuccess()) {
/* pass */
}
}
} finally {
result.release();
}
} else {
doNext = false;
}
}
}
After the distribution data is built, it is handed over to each CommitLogDispatcher for processing. In Index, the buildIndex method of IndexService is called.
We are mainly concerned with various operations of hash index, so let's look at the put method first
IndexFile#putKey
First, get the slot number of the Key in the Slot Table
int keyHash = indexKeyHashMethod(key); // Get hash slot number int slotPos = keyHash % this.hashSlotNum; // Get the physical offset of the slot int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize;
Then get the address of the Header node of the target slot and the difference between the current time and the beginTime in the Header
// Gets the head node of the bucket
int slotValue = this.mappedByteBuffer.getInt(absSlotPos);
if (slotValue <= invalidIndex || slotValue > this.indexHeader.getIndexCount()) {
slotValue = invalidIndex;
}
long timeDiff = storeTimestamp - this.indexHeader.getBeginTimestamp();
timeDiff = timeDiff / 1000;
if (this.indexHeader.getBeginTimestamp() <= 0) {
timeDiff = 0;
} else if (timeDiff > Integer.MAX_VALUE) {
timeDiff = Integer.MAX_VALUE;
} else if (timeDiff < 0) {
timeDiff = 0;
}
Add a node on an empty bucket in the Index Linked List
// Add inode this.mappedByteBuffer.putInt(absIndexPos, keyHash); this.mappedByteBuffer.putLong(absIndexPos + 4, phyOffset); this.mappedByteBuffer.putInt(absIndexPos + 4 + 8, (int) timeDiff); this.mappedByteBuffer.putInt(absIndexPos + 4 + 8 + 4, slotValue);
You can see that the offset value from the start time is stored on the timestamp, which is a good way to save space. Then store the address of the original head node
Last update meta information
this.mappedByteBuffer.putInt(absSlotPos, this.indexHeader.getIndexCount());
if (this.indexHeader.getIndexCount() <= 1) {
this.indexHeader.setBeginPhyOffset(phyOffset);
this.indexHeader.setBeginTimestamp(storeTimestamp);
}
if (invalidIndex == slotValue) {
this.indexHeader.incHashSlotCount();
}
this.indexHeader.incIndexCount();
this.indexHeader.setEndPhyOffset(phyOffset);
this.indexHeader.setEndTimestamp(storeTimestamp);
After knowing the principle of put, it's no problem to get
IndexFile#selectPhyOffset
First, get the position of the head node of the Key in the Slot Table
int keyHash = indexKeyHashMethod(key); int slotPos = keyHash % this.hashSlotNum; int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize;
Then traverse the linked list in the Index Linked List until the tail node
if (phyOffsets.size() >= maxNum) {
break;
}
int absIndexPos =
IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize
+ nextIndexToRead * indexSize;
int keyHashRead = this.mappedByteBuffer.getInt(absIndexPos);
long phyOffsetRead = this.mappedByteBuffer.getLong(absIndexPos + 4);
long timeDiff = (long) this.mappedByteBuffer.getInt(absIndexPos + 4 + 8);
int prevIndexRead = this.mappedByteBuffer.getInt(absIndexPos + 4 + 8 + 4);
However, different from the general Hash table, because the time is orderly, the traversal will not continue when it is found before the start time of the target node.
And since the same key will not be overwritten, all CommitLog offsets that are the same as the hash of the key will be returned.
long timeRead = this.indexHeader.getBeginTimestamp() + timeDiff;
boolean timeMatched = (timeRead >= begin) && (timeRead <= end);
if (keyHash == keyHashRead && timeMatched) {
phyOffsets.add(phyOffsetRead);
}
if (prevIndexRead <= invalidIndex
|| prevIndexRead > this.indexHeader.getIndexCount()
|| prevIndexRead == nextIndexToRead || timeRead < begin) {
break;
}
nextIndexToRead = prevIndexRead;
As for how to find multiple indexfiles, the method is also very simple. You only need to judge whether access is required according to the timestamp in the Header.
ConsumerQueue

The file structure of ConsumerQueue is relatively simple, which is composed of 30W structures in the figure above.
Messages distributed through the commitlogdispatcher buildconsumequeue will be appended to the MappedFile file directly after finding the corresponding Queue.
The search process is also relatively simple. The search here is divided into search by message logical offset and search by timestamp.
For the search by message logical offset, random reading can be performed by calculating the subscript.
Finding by timestamp is an interesting part. It uses dichotomy to speed up the search:
public long getOffsetInQueueByTime(final long timestamp) {
// Get the MappedFile just before this through the timestamp
MappedFile mappedFile = this.mappedFileQueue.getMappedFileByTime(timestamp);
if (mappedFile != null) {
long offset = 0;
// The lower order is the minimum of the message queue minimum offset and the file minimum offset
int low = minLogicOffset > mappedFile.getFileFromOffset() ? (int) (minLogicOffset - mappedFile.getFileFromOffset()) : 0;
int high = 0;
int midOffset = -1, targetOffset = -1, leftOffset = -1, rightOffset = -1;
long leftIndexValue = -1L, rightIndexValue = -1L;
long minPhysicOffset = this.defaultMessageStore.getMinPhyOffset();
SelectMappedBufferResult sbr = mappedFile.selectMappedBuffer(0);
if (null != sbr) {
ByteBuffer byteBuffer = sbr.getByteBuffer();
high = byteBuffer.limit() - CQ_STORE_UNIT_SIZE;
try {
while (high >= low) {
// ? Strange writing, divide by CQ first_ STORE_ UNIT_ Size multiplied by CQ_STORE_UNIT_SIZE
midOffset = (low + high) / (2 * CQ_STORE_UNIT_SIZE) * CQ_STORE_UNIT_SIZE;
byteBuffer.position(midOffset);
// Gets the offset of the found bucket in the CommitLog
long phyOffset = byteBuffer.getLong();
// Gets the size of the message
int size = byteBuffer.getInt();
if (phyOffset < minPhysicOffset) {
low = midOffset + CQ_STORE_UNIT_SIZE;
leftOffset = midOffset;
continue;
}
long storeTime =
this.defaultMessageStore.getCommitLog().pickupStoreTimestamp(phyOffset, size);
// Binary search based on persistence time
if (storeTime < 0) {
return 0;
} else if (storeTime == timestamp) {
targetOffset = midOffset;
break;
} else if (storeTime > timestamp) {
high = midOffset - CQ_STORE_UNIT_SIZE;
rightOffset = midOffset;
rightIndexValue = storeTime;
} else {
low = midOffset + CQ_STORE_UNIT_SIZE;
leftOffset = midOffset;
leftIndexValue = storeTime;
}
}
if (targetOffset != -1) {
offset = targetOffset;
} else {
if (leftIndexValue == -1) {
offset = rightOffset;
} else if (rightIndexValue == -1) {
offset = leftOffset;
} else {
offset =
Math.abs(timestamp - leftIndexValue) >
Math.abs(timestamp - rightIndexValue) ? rightOffset : leftOffset;
}
}
return (mappedFile.getFileFromOffset() + offset) / CQ_STORE_UNIT_SIZE;
} finally {
sbr.release();
}
}
}
return 0;
}
However, we found that when messages need to be consumed, it is not enough to rely only on the ComsumerQueue, because the consumption progress of each consumer group is not recorded in this structure.
This is because the Broker maintains the consumption progress in a Map in memory, and will regularly convert the Map into json format and persist it to disk.
Comparison between Kafka and RocketMQ
Finally, compare the persistence methods of Kafka and RocketMQ.
In Kafka, the file types mainly include:
-
log file
Message storage file
-
index file
Location index. Find the physical offset in the log file through the logical offset
-
timeindex file
Timestamp index. The physical offset in the log file can be found through the timestamp
From the index, both Kafka and RocketMQ can find messages according to location and timestamp.
However, in terms of storage method, Kafka manages the partition of each Topic physically through different files, while RocketMQ logically divides the Topic and Queue, and the write location is a separate file.
Intuitively, Kafka's scheme is physically divided, and RocketMQ also needs to maintain the Consumer file, and both are written in sequence. There is no doubt that the former can reduce additional maintenance work.
But in fact, the underlying design method of RocketMQ is better than Kafka. The following is the measurement of TPS in the case of multiple topics
| product | Number of topics | Number of concurrent sender | Sender RT | Sender TPS | Consumer TPS |
|---|---|---|---|---|---|
| RocketMQ | 64 | 800 | 8 | 9w | 8.6w |
| 128 | 800 | 9 | 7.8w | 7.7w | |
| 256 | 800 | 10 | 7.5w | 7.5w | |
| Kafka | 64 | 800 | 5 | 13.6w | 13.6w |
| 128 | 256 | 23 | 8500 | 8500 | |
| 256 | 256 | 133 | 2215 | 2352 |
Data from Alibaba middleware team blog: Kafka vs RocketMQ - impact of Topic number on stand-alone performance
It can be seen that Kafka can beat RocketMQ when there are few topics, but once the topics increase, Kafka's TPS will drop precipitously.
The reason is that the sequential writes in Kafka's memory are converted into actual random writes under multiple topics and multiple queues.
As we all know, both RocketMQ and Kafka use Page Cache to speed up file access. At the same time, if they are consumed immediately after production, messages are sent to the network card buffer in Page Cache (this is called zero copy). However, the memory is limited and the size of the Page Cache is limited, but too many pages in the memory will trigger "swap out".
When there are many topics and partitions, there will be more open file handles and more files mapped to memory by mmap. Therefore, when writing, the pages of multiple files will be "swapped in" and "swapped out" in turn. Of course, it is not faster than writing directly to memory in sequence.
For reading, both of them need to change the required pages into memory, so they are random reading, with little difference.