Combiner concept

Combiner is known as the local Reduce, and Reduce's input is the final output of Combiner.
In MapReduce, when the data generated by map is too large, bandwidth becomes a bottleneck. How to compress the data transmitted to Reduce without affecting the final results? One way is to use Combiner, which is known as the local Reduce. Combiner is defined by reducer. In most cases, Combiner and reduce deal with the same logic, so the parameters of job.setCombinerClass() can be defined directly using the reduced defined. Of course, it can also be defined separately as a Combiner different from reduce, inheriting Reducer, which is basically defined in the same way as reduce.
combiner's value orientation:
As we all know, Hadoop framework uses Mapper to process data blocks into < key, value > key-value pairs, shuffle them among network nodes, and then use Reducer to process the calculated data and output the final results.
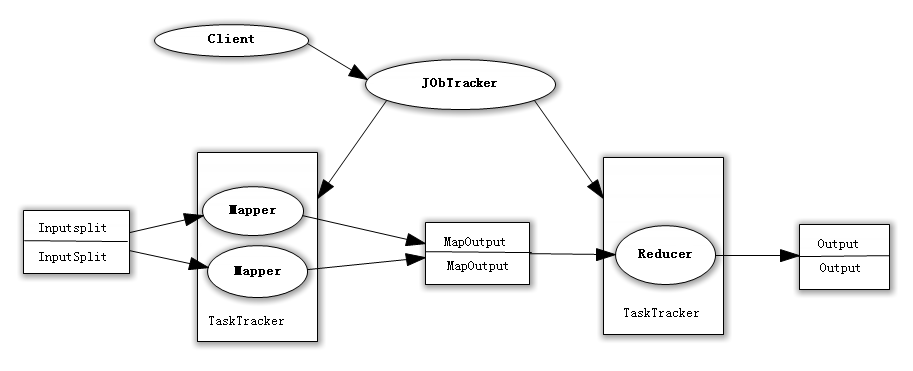
In the above process, we see at least two performance bottlenecks:
(1) If we have 1 billion data, Mapper generates 1 billion keys to transmit between networks, but if we only calculate the maximum value of data, it is obvious that Mapper only needs to output the maximum value it knows. To be exact, it is enough to know the maximum value of each data block (without pulling other data to Reducer). Reducing the base of calculation can not only reduce the network pressure, but also greatly improve the efficiency of the program.
Summary: Network bandwidth is seriously occupied to reduce program efficiency;
(2) Hypothesis use US Patent Data Set The definition of data skew is elaborated by one of the countries in Mapper. Such data is far from uniform or balanced distribution. Not only are the key pairs in Mapper and the key pairs in the intermediate stage (shuffle) equal, but most of the key pairs will eventually converge on a single Reducer, overwhelming the Reducer, thus greatly reducing the performance of program calculation.
Summary: Single node overloading reduces program performance;
Combiner's value is embodied vividly by these two problems.
Combiner details:
In MapReduce programming model, there is a very important component between MapReducer and MapReducer. It solves the above performance bottleneck problem, which is Combiner.
Be careful:
(1) Unlike mapper and reducer, combiner has no default implementation and needs explicit settings to work in conf.
(2) combiner is not applicable to all job s. combiner can only be set if the operation satisfies the binding law. combine operations are similar to opt (opt (1, 2, 3), opt (4, 5, 6). If opt is to sum and maximize, it can be used, but not if it is to median.
Each map may produce a large number of local outputs. Combiner's function is to merge the outputs of the map end first to reduce the data transmission between the map and reduce nodes, so as to improve the performance of network IO. It is one of the optimization methods of MapReduce. Its specific function is described below.
(1) Combiner is the most basic way to realize the aggregation of local keys, sort the keys of map output, and iterate the value. As follows:
map: (K1, V1) → list(K2, V2)
combiner: (K2, list(V2)) → list(K2, V2)
reduce: (K2, list(V2)) → list(K3, V3)
(2) Combiner also has a local reduce function (which is essentially a reduce), such as Hadoop's wordcount example and the program to find the maximum value, combiner and reduce are exactly the same, as follows:
map: (K1, V1) → list(K2, V2)
combine: (K2, list(V2)) → list(K3, V3)
reduce: (K3, list(V3)) → list(K4, V4)
PS: Recall that if wordcount Not in Combiner Be a pioneer, with tens of millions of data Reduce The efficiency will be too low to imagine. Use combiner After that, finish first. map It will be aggregated locally, for Reduce Computing the first data aggregation, improve the efficiency of calculation. In this way, for hadoop Self contained wordcount For example, value It's a superimposed number, so map It can be done as soon as it's over. reduce Of value Overlay, not wait for all map End and proceed reduce Of value Superposition.
MapReduce with Combiner
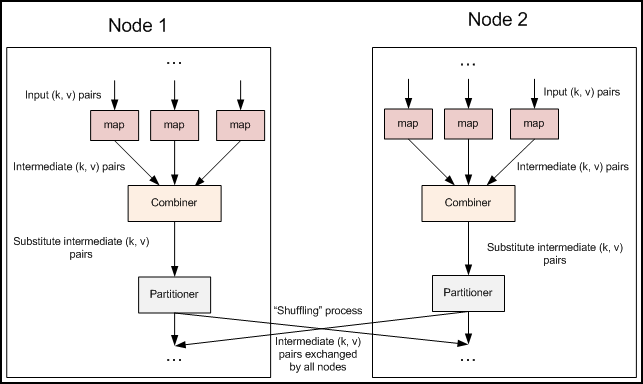
The code in the previous article omitted a step to optimize the bandwidth used by MapReduce jobs, Combiner, which runs before Reducer after Mapper. Combiner is optional, and if the process is suitable for your job, the Combiner instance runs on each node running the map task. Combiner receives the output of the Mapper instance on a particular node as input, and then the output of Combiner is sent to Reducer instead of sending the output of Mapper. Combiner is a "mini reduce" process that only processes data generated by a single machine.
Lift a small chestnut
We grabbed last year's highest quarterly temperature data:
The first mapper data (2017, [34, 25])
The second mapper data (2017, [33, 32])
If you do not consider using Combiner's computational process, Reducer is as follows:
(2017, [34, 25, 33, 32])// / Get the maximum by sorting
If you consider Combiner's computing process, Reducer gets the data set after compaction and processing.
(2017,[34])
(2017,[33])
The results of these two methods are identical. The greatest advantage of using Combiner is to save the data transmitted by the network, which is very helpful to improve the overall computing efficiency. Of course, the good way is to rely on the problem of counterpart. If combiner is used in the wrong place, it may be counterproductive. eg: Find the average value of a set of data. (The counterexamples are not listed. If necessary, you can send a private message or leave a message.)
Use MyReducer as Combiner
In the WordCount code in the previous article, you can add the Combiner method by adding the following simple code:
// Setting up Map Protocol Combiner
job.setCombinerClass(MyReducer.class);Customized Combiner
In order to understand the working principle of Combiner more clearly, we customize a Combiners class, no longer use MyReduce as a Combiners class, the specific code below one by one.
map method for overwriting Mapper class
public static class MyMapper extends
Mapper<LongWritable, Text, Text, LongWritable> {
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws java.io.IOException, InterruptedException {
String line = value.toString();
String[] spilted = line.split("\\s");
for (String word : spilted) {
context.write(new Text(word), new LongWritable(1L));
// Output key-value pair information of Mapper for display effect
System.out.println("Mapper output<" + word + "," + 1 + ">");
}
};
}Rewrite Reducer class reduce method, add MyCombiner class and override reduce method
public static class MyCombiner extends
Reducer<Text, LongWritable, Text, LongWritable> {
protected void reduce(
Text key,
java.lang.Iterable<LongWritable> values,
org.apache.hadoop.mapreduce.Reducer<Text, LongWritable, Text, LongWritable>.Context context)
throws java.io.IOException, InterruptedException {
// Display times indicate how many times Combiner executes and how many groupings k2 has
System.out.println("Combiner Input grouping<" + key.toString() + ",N(N>=1)>");
long count = 0L;
for (LongWritable value : values) {
count += value.get();
// Display times represent the number of key logarithms of K2 and V2 input
System.out.println("Combiner Input key-value pairs<" + key.toString() + ","
+ value.get() + ">");
}
context.write(key, new LongWritable(count));
// Display times represent the number of keys logarithms of K2 and V2 output
System.out.println("Combiner Output key-value pairs<" + key.toString() + "," + count
+ ">");
};
}Add MyCombiner class and override reduce method
public static class MyCombiner extends
Reducer<Text, LongWritable, Text, LongWritable> {
protected void reduce(
Text key,
java.lang.Iterable<LongWritable> values,
org.apache.hadoop.mapreduce.Reducer<Text, LongWritable, Text, LongWritable>.Context context)
throws java.io.IOException, InterruptedException {
// Display times indicate how many times the protocol function has been called and how many groupings k2 has
System.out.println("Combiner Input grouping<" + key.toString() + ",N(N>=1)>");
long count = 0L;
for (LongWritable value : values) {
count += value.get();
// Display times represent the number of key logarithms of K2 and V2 input
System.out.println("Combiner Input key-value pairs<" + key.toString() + ","
+ value.get() + ">");
}
context.write(key, new LongWritable(count));
// Display times represent the number of key pairs of K2 and V2 output
System.out.println("Combiner Output key-value pairs<" + key.toString() + "," + count
+ ">");
};
}
// Setting Map Specification Combiner Class (Function)
job.setCombinerClass(MyCombiner.class);
Print information on debugging console
(1) Mapper Period
Mapper output<hello,1> Mapper output<edison,1> Mapper output<hello,1> Mapper output<kevin,1>
(2) Combiner Period
Combiner Input grouping<edison,N(N>=1)> Combiner Input key-value pairs<edison,1> Combiner Output key-value pairs<edison,1> Combiner Input grouping<hello,N(N>=1)> Combiner Input key-value pairs<hello,1> Combiner Input key-value pairs<hello,1> Combiner Output key-value pairs<hello,2> Combiner Input grouping<kevin,N(N>=1)> Combiner Input key-value pairs<kevin,1> Combiner Output key-value pairs<kevin,1>
As can be seen here, a local Reeduce operation is performed in Combiner, which simplifies the merging pressure of remote Reduce nodes.
(3) Reducer Period
Reducer Input grouping<edison,N(N>=1)> Reducer Input key-value pairs<edison,1> Reducer Input grouping<hello,N(N>=1)> Reducer Input key-value pairs<hello,2> Reducer Input grouping<kevin,N(N>=1)> Reducer Input key-value pairs<kevin,1>
It can be seen here that the merge calculation of hello is completed only once.
Then, if we look again at the console output without adding Combiner:
(1)Mapper
Mapper output<hello,1> Mapper output<edison,1> Mapper output<hello,1> Mapper output<kevin,1>
(2)Reducer
Reducer Input grouping<edison,N(N>=1)> Reducer Input key-value pairs<edison,1> Reducer Input grouping<hello,N(N>=1)> Reducer Input key-value pairs<hello,1> Reducer Input key-value pairs<hello,1> Reducer Input grouping<kevin,N(N>=1)> Reducer Input key-value pairs<kevin,1>
It can be seen that when Combiner is not used, hello is unified merged by Reducer nodes, that is, why there are two hello input keys right here.
Summary: From the output information of the console, we can see that combine only specifies two identical hello, thus the input to reduce becomes < hello, 2>. In the actual Hadoop cluster operation, we use multiple hosts to carry out MapReduce. If we join the protocol operation, each host will make a protocol for the local data before reducing, and then reduce through the cluster. This will greatly save the time of reducing, thus speeding up the processing speed of MapReduce.
Reference: https://blog.csdn.net/deguotiantang/article/details/58586972