This paper crawls the data of qike.com only for learning, but also because I haven't written a blog for more than a month (because it's inconvenient to write the recent contents into a public blog).
The crawling technology in this article uses the beautiful soup library. For its specific usage, you can consult relevant materials on the Internet. At that time, I referred to the book "Python 3 web crawler development practice" (not advertising)
1 website introduction
The website crawled by this article is called Qike Solidot.
Qike Solidot : it is a science and technology information website under the top network. It mainly faces open source free software and readers who care about science and technology information, including many Chinese open source software developers, enthusiasts and preachers.
2 requirements introduction
Crawl the news information within 10 days from the home page of this website. The news information includes category, title and content.
For example:
# format # ===[category] title=== # content ======[Linux]CentOS Stream 9 Release====== CentOS The project released a new rolling update release CentOS Stream 9 ... ...
3 Introduction to import and warehousing
The role of these libraries is described here only in the context of this article.
requests: request and respond to the news information page information of Qike Solidot, that is, obtain the Html of the web page;
Beautiful soup: parse the Html information obtained from the requests library, split it and collect the information we need;
Time: because "collecting consultation information within 10 days" is included in the requirement, this library is used to divide and calculate the time and date (the current date and the previous date are realized by timestamp - the number of timestamps occupied in a day, and the date format YYMMdd is converted).
4. Specific coding and description
The content crawled this time is very friendly without the obstacles of anti crawling mechanism and asynchronous request response. Therefore, this article is no longer better than Html code. Without these obstacles, it is more suitable for practicing the use of various crawler request libraries and parsing libraries. Therefore, this website is a good crawler practice website, Of course, we'd better not maliciously brush other people's server traffic.
Another thing that must be explained is that one of the main technologies of this paper is the Beautiful Soup library. Beautiful Soup is a powerful parsing tool. We can no longer write some complex regular expressions. If we assume that soup is an object created by Beautiful Soup, we can obtain the information of the label node by using the method like the label name of soup, Then use the text attribute to obtain the text information in the tag, or use the soup. Tag name. attrs = {attribute name: 'attribute value'} with find_all function to obtain the corresponding matching tag nodes, etc. in short, this library is very convenient and powerful. Readers can collect relevant materials for learning by themselves. This article will not repeat its usage.
(1) First, define a crawler tool class MySpider for this crawler.
class MySpider(): # ...
(2) Define the necessary information for initialization. For crawlers, you can initialize the web page address and request header information (mainly set according to the anti crawling mechanism of the web page).
def __init__(self):
'''initialization'''
self.url = 'https://www.solidot.org/'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
(3) It is used to request and obtain the response information of the web page. Here, in order to facilitate subsequent processing, the response information is finally converted to the BeautifulSoup object in the BeautifulSoup library.
def loadPage(self, url):
'''Reusable page request method'''
response = requests.get(url, timeout = 10, headers =self.headers)
if response.status_code == 200:
return BeautifulSoup(response.content.decode('utf-8'), 'lxml')
else:
raise ValueError('status_code is:',response.status_code)
(4) Parse the beautiful soup object returned by the loadPage method, and parse the information we need from this object, that is, the title and content of the news. Here, because some news have categories and some news have no categories, we need to make a judgment. Here, I make the news without categories belong to the category of "no classification". Finally, we return a list object, In the list, the title and content appear alternately.
def getContent(self, soup):
'''According to the content of the web page, match the title and content at the same time'''
items = soup.find_all(attrs={'class':'block_m'})
result = []
for item in items:
title = '' # Category + title
content = '' # content
# print(item.find_all(attrs={'class':'ct_tittle'})[0].div)
# Section with title
divTag = item.find_all(attrs={'class':'ct_tittle'})[0].div
# print(divTag)
if(divTag.span != None):
title = '[' + divTag.span.a.text + ']' + divTag.find_all(name = 'a')[1].text
else:
title = '[[no classification]' + divTag.find_all(name = 'a')[0].text
# print(title)
# Section containing content
divTag2 = item.find_all(attrs={'class':'p_content'})[0].div
content = divTag2.text
result.append('======' + title.strip() + '======' + '\n')
result.append(content.strip() + '\n')
return result
(5) The result list returned after the execution of the previous function is persisted and stored in a txt file (of course, it can also be stored in excel or database in practical application. Here is just an example). The daily news consultation results are stored in a separate folder, and the date of the day needs to be named.
def saveContent(self, resultList, nowDate):
'''Data persistence is stored in local files'''
flag = 0
nowDate = str(nowDate)
fo = open('result-' + nowDate + '.txt', 'w', encoding='utf-8')
fo.write('Date:' + nowDate[0:4] + '-' + nowDate[4:6] + '-' + nowDate[6:8] + '\n')
for item in resultList:
fo.write(item)
flag += 1
if (flag % 2 == 0):
fo.write('\n')
(6) The main function is as follows. The iterative part of the following code does not need to be explained too much, that is, to collect data for 10 days in the corresponding requirements. For how to locate the current time and how to return the current time to 10 days ago and count the date of each day in these 10 days, I use the current timestamp to subtract the number of timestamps of one day, After that, the time stamp is converted into date form for processing, and Qike is relatively friendly. Articles at different times are directly divided in the url. In line with this idea, the following code is naturally obtained.

if __name__ == '__main__':
spider = MySpider()
# Get current timestamp
nowTickets = int(time.time())
for _ in range(10):
#Convert to other date formats, such as: '% Y -% m -% d% H:% m:% s'
timeArray = time.localtime(nowTickets)
timeFormat = time.strftime('%Y-%m-%d %H:%M:%S', timeArray)
nowDate = timeFormat[0:4] + timeFormat[5:7] + timeFormat[8:10]
nowDate = eval(nowDate)
soup = None
if (_ == 0):
soup = spider.loadPage(spider.url)
else:
soup = spider.loadPage(spider.url + '?issue=' + str(nowDate))
resultList = spider.getContent(soup)
spider.saveContent(resultList, nowDate)
nowTickets -= 86400
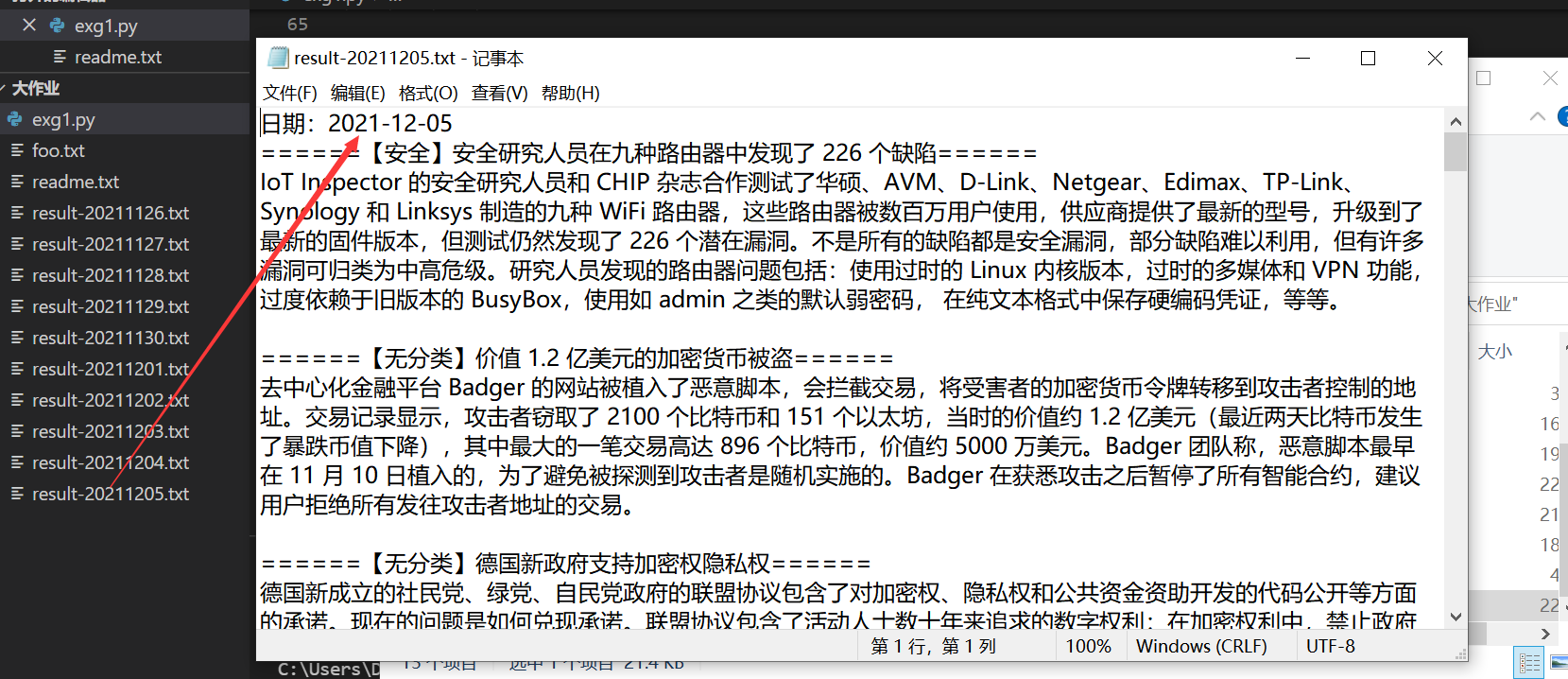
5 final results
Got 10 newly generated txt files, each file holds the news information of the day, and the crawling is successful.