Exploratory analysis of data
Exploration of data characteristics
Data exploratory analysis needs to be seen from two aspects:
Field vs label
Field vs field
Data distribution analysis
It may be because the distribution of training set and verification set is different, such as the opposite trend of local and online score transformation.
A classifier can be constructed to distinguish the training set from the verification set. If the samples cannot be distinguished (AUC is close to 0.5), it indicates that the data distribution is consistent. Otherwise, it indicates that the distribution of the training set and the test set is not consistent.
Fundamentals of Feature Engineering -- feature types and treatment methods
Category characteristics
Deal with it at any time
High cardinality (multiple categories) leads to discrete data
It is difficult to fill in missing values
Divided into ordered and disordered
Processing process
Unique heat coding
Advantages: it is simple and can effectively encode category features
Disadvantages: it will lead to dimension explosion and sparse features
Tag code
Advantages: simple, no category dimension added
Disadvantages: it will change the order relationship of the original tags
labelEncoder is even better than single heat coding in the number model
Method: facetrize in pandas or label code on sklearn
Sequential coding
Code according to category size relationship
Advantages: it is simple and does not add category dimensions
Disadvantages: requires manual knowledge and
df[feature].map({mapped dictionary}) must cover all categories, but this method needs to cover all categories
Frequency coding
The number or frequency of occurrences is used as the code
Mean/Target code
Take the label probability given by the category as the code. At this time, the meaning of the last column is the average value of target under the country classification
Numerical feature processing method
Numerical features are the most common continuous features, which are prone to outliers and outliers
Round
Form: scale and round the value to retain most of the information
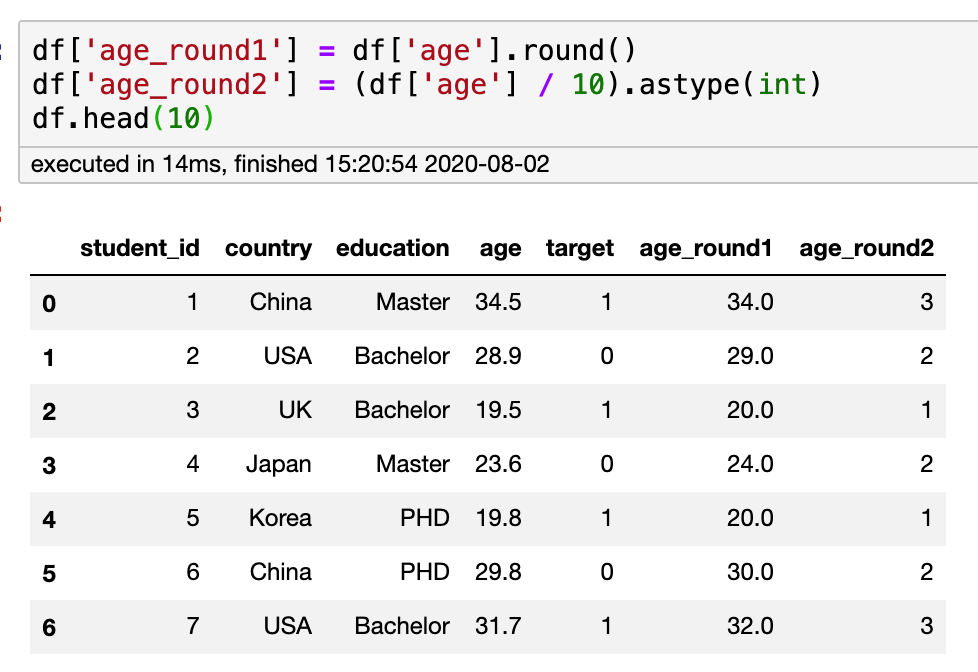
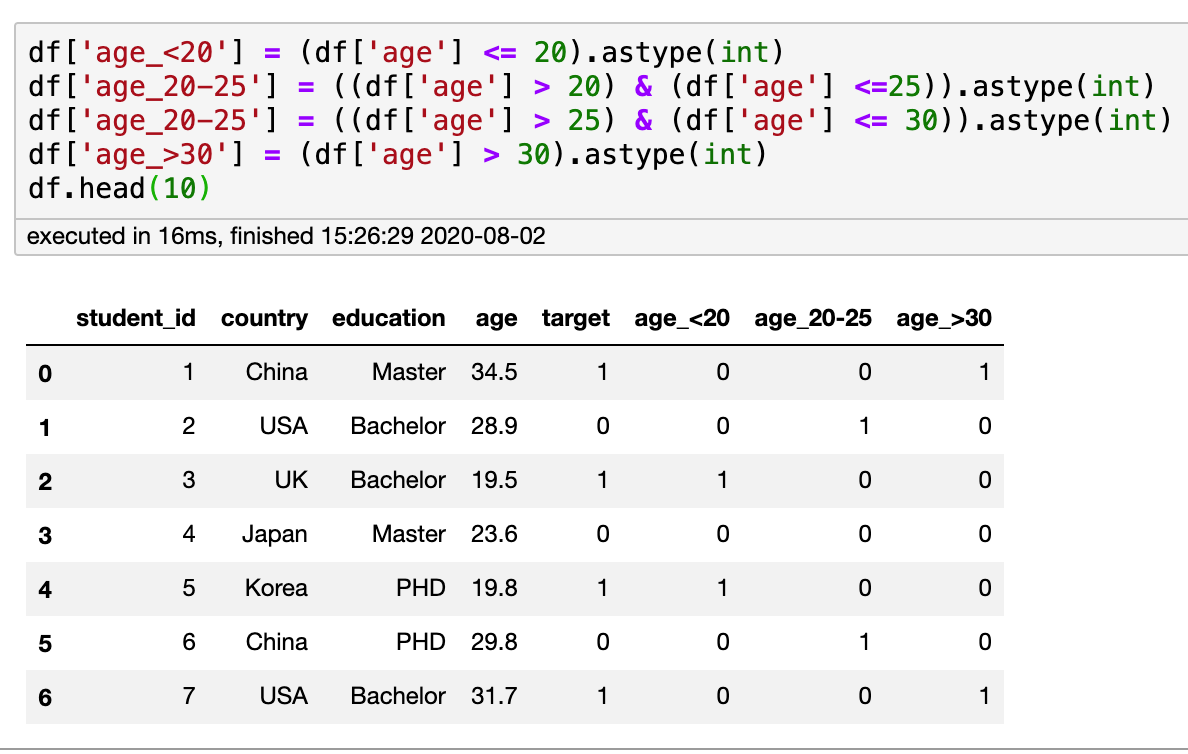
Binning boxed the values
Just like piecewise functions
Quick check of characteristic process code processing
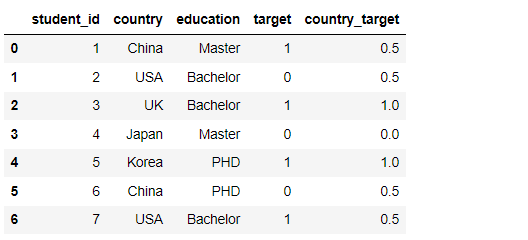
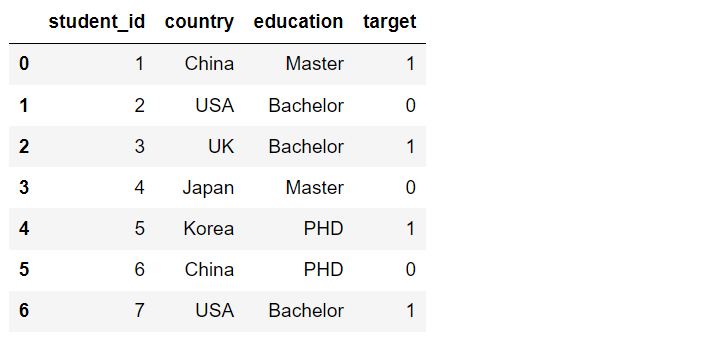
The experimental data set is constructed as follows:
df = pd.DataFrame({
'student_id': [1,2,3,4,5,6,7],
'country': ['China', 'USA', 'UK', 'Japan', 'Korea', 'China', 'USA'],
'education': ['Master', 'Bachelor', 'Bachelor', 'Master', 'PHD', 'PHD', 'Bachelor'],
'target': [1, 0, 1, 0, 1, 0, 1]
})
The feature coding method is given below as a code reference:
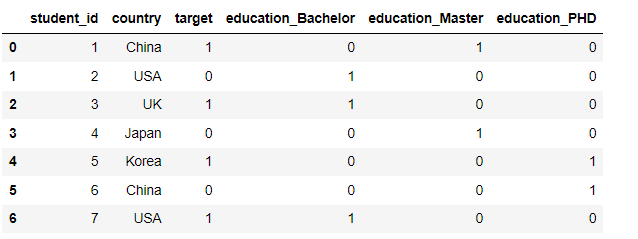
Onehot_code
First, we code education
pd.get_dummies(df, columns=['education'])
It is recommended to use the pandas library because the operation is simple
You can also use the OneHotEncoder method in sklearn, which is more complex
Finally, the unique heat characteristic obtained is written into df
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder()
labels = []
for i in range(len(df['country'].unique())):
label = 'country_'+str(i)
labels.append(label)
df[labels] = ohe.fit_transform(df[['country']]).toarray()
LabelEncoder
For type coding, you can use the LabelEncoder library
from sklearn.preprocessing import LabelEncoder le = LabelEncoder() df['country_LabelEncoder'] = le.fit_transform(df['country']) df.head(10)
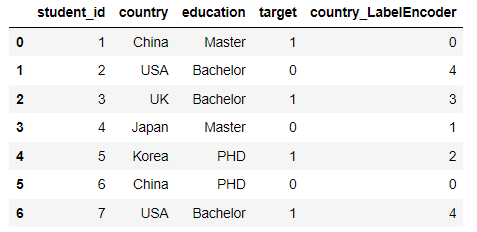
You can also use the methods that come with pandas
df['country_LabelEncoder'] = pd.factorize(df['country'])[0] df.head(10)
Among them, the pd.factorize method yields such a result

[0] is the code number and [1] is the type corresponding to the code
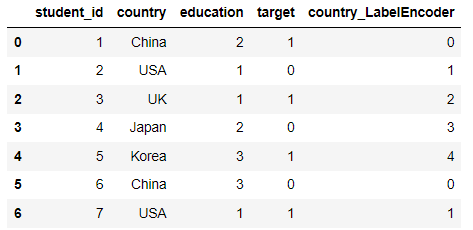
Ordinal Encoding
Here, the serial number must correspond to all existing ratings, otherwise an error will be reported
df['education'] = df['education'].map(
{'Bachelor': 1,
'Master': 2,
'PHD': 3})
df.head(10)
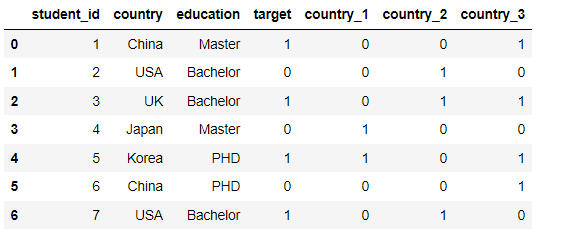
Binary coding
import category_encoders as ce encoder = ce.BinaryEncoder(cols= ['country']) pd.concat([df, encoder.fit_transform(df['country']).iloc[:, 1:]], axis=1)
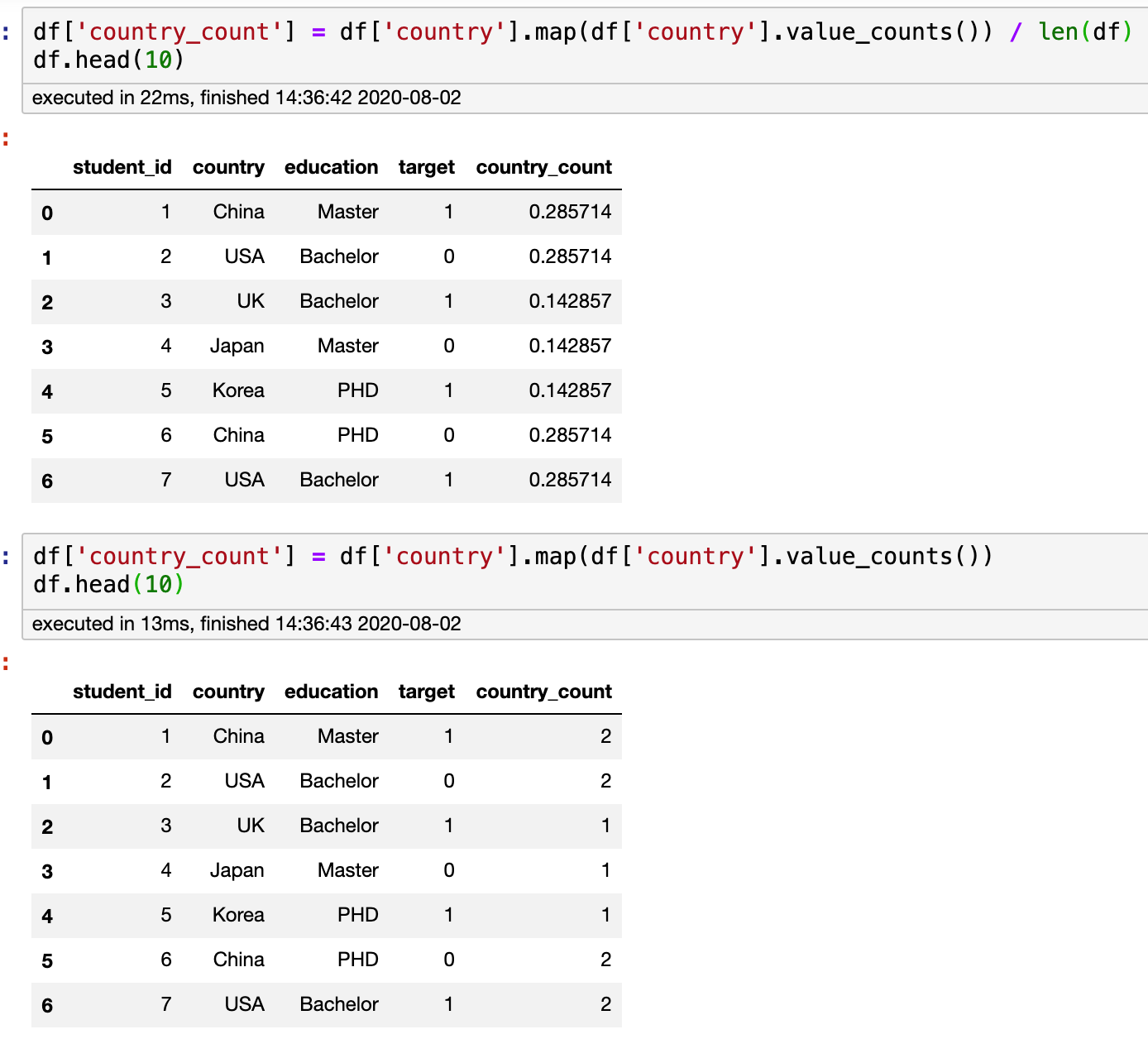
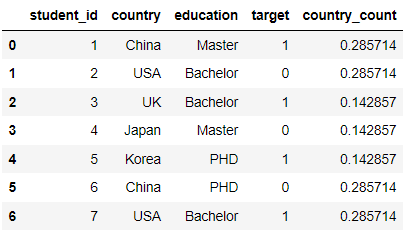
Frequency Encoding,Count Encoding
Note the use of the. map function here
Here, the frequency of the label is encoded as a feature
df['country_count'] = df['country'].map(df['country'].value_counts()) / len(df) df.head(10)
df['country_count'] = df['country'].map(df['country'].value_counts()) df.head(10)
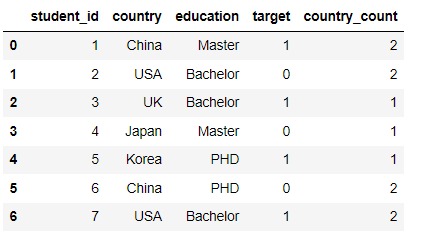
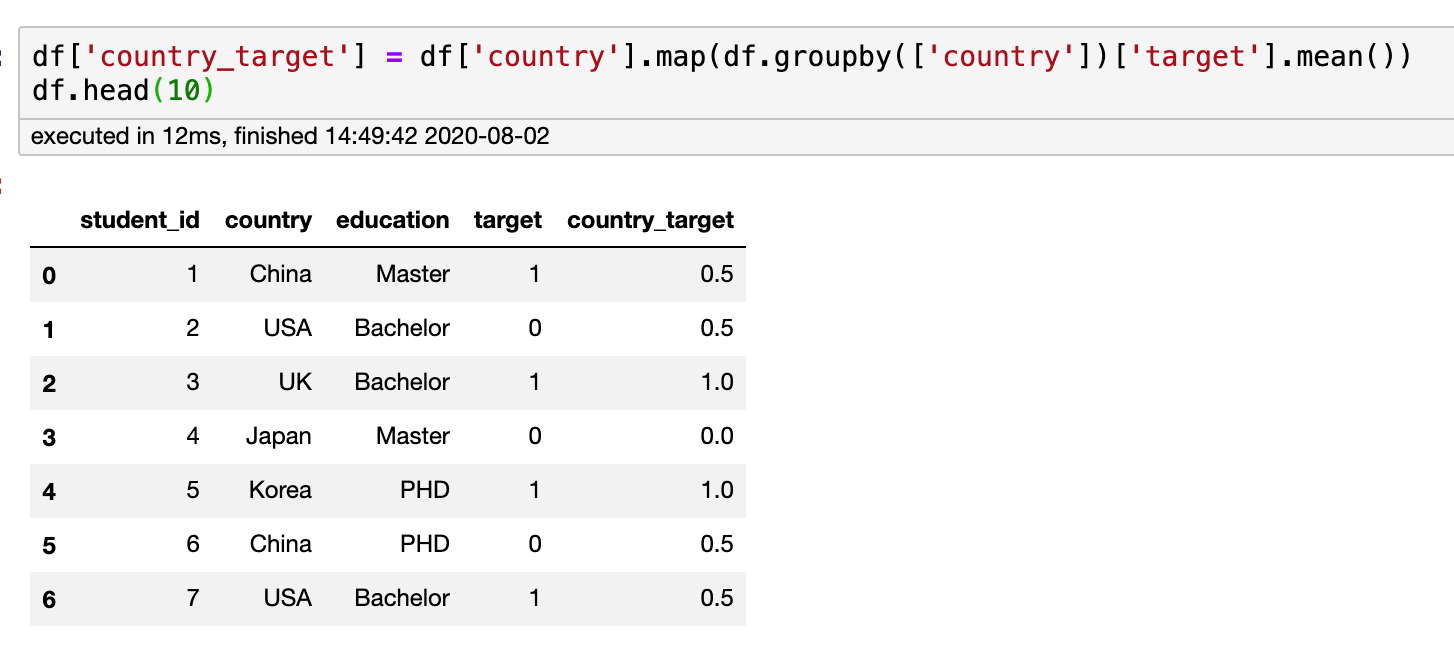
Mean/Target Encoding
Here, the average value of the tag is used as the encoding (note that this method will disclose the tag information)
df['country_target'] = df['country'].map(df.groupby(['country'])['target'].mean()) df.head(10)