Project requirements:
- Because of the statistical analysis of mathematical modeling competition data, it is necessary to get the actual departure and landing time of all flights in an airport one day.
Code analysis:
- Take the airport as an example, the time to arrive at the airport is the same.
from pyquery import PyQuery as pq
# Open the "depart.txt" file to facilitate data storage
fout = open('E:/depart.txt', 'w', encoding='utf8')
# Here the url must write a link to the full https://flights.ctrip.com/actualtime/depart-bjs.p1/.
#There were 59 pages of data on that day.
for i in range(1,59):
cpage = 'https://flights.ctrip.com/actualtime/depart-bjs.p' + str(i) + '/'
# Get the page structure of the current link to d
d = pq(url=cpage)
for i in range(20): #Each page has 20 rows of data
datarow = d('.bg_0').eq(i).html() # Obtain the structure of line i from the. bg_0 attribute
ddata=pq(datarow)
#The time of arrival is the fourth column, and the replace() function is formatted for the file.
fout.write(ddata('td').eq(3).text().replace("\n"," ")) # Write file content
fout.write("\n")
# Close file
fout.close()
Test results: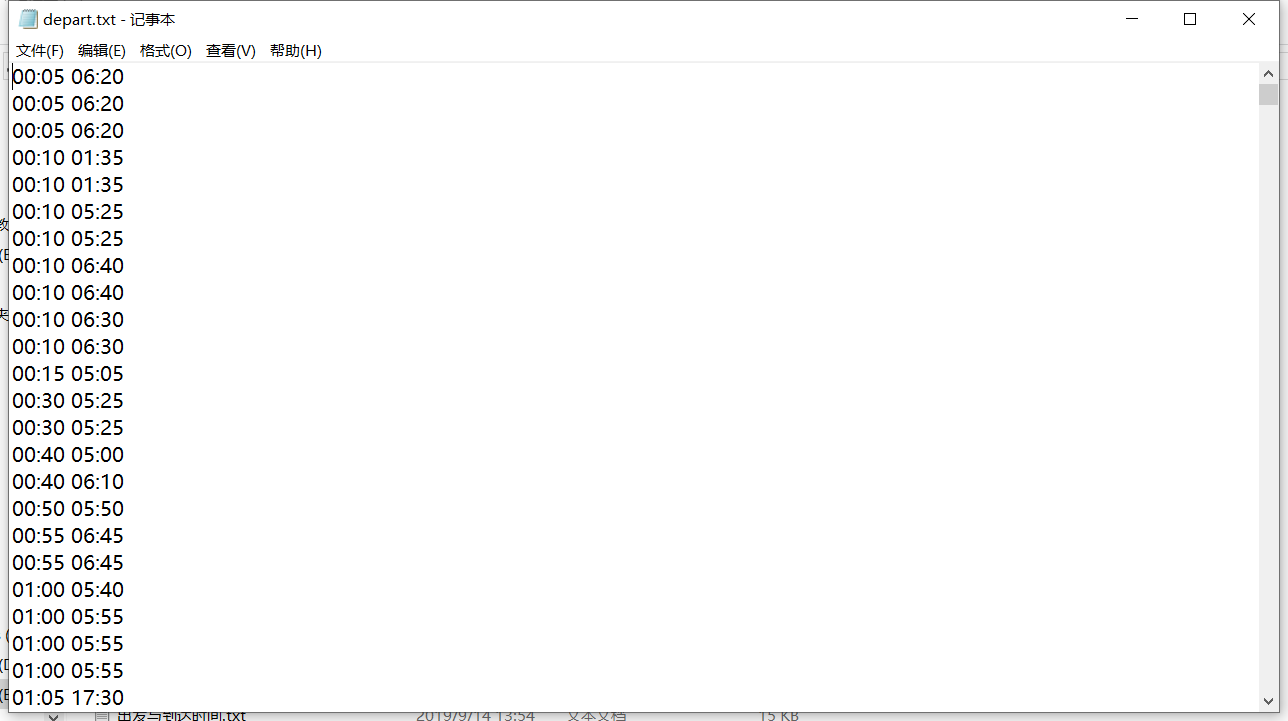
Knowledge expansion
Introduction to PyQuery Library
- PyQuery library is also a very powerful and flexible web page parsing library. PyQuery is a strict implementation of Python that imitates jQuery.
- Official documentation: https://pythonhosted.org/pyquery/index.html#
PyQuery library use
- Initialization (can load an HTML string, or an HTML file, or a url address)
from pyquery import PyQuery as pq
#String initialization
doc = pq("<html><title>hello</title></html>")
#URL initialization, where the URL must be fully written
doc = pq(url="http://www.baidu.com",encoding='utf-8')
#File initialization
d = pq(filename='path_to_html_file')
- html() and text() - Get the corresponding HTML block or text block
p = pq("<head><title>hello</title></head>")
p('head').html() # Return < title > Hello </title >
p('head').text() # Return to hello
- Get elements from HTML Tags
d = pq('<div><p>test 1</p><p>test 2</p></div>')
d('p') # Return [<p>, <p>]
print d('p') # Return < p > Test 1 </p > < p > test 2</p>
print d('p').html() # Return to test 1
#Note: When more than one element is retrieved, the html() and text() methods only return the corresponding content block of the first element.
- eq(index) - Get the specified element based on the given index number
#For example, if you want to get the content of the second p tag, you can:
print d('p').eq(1).html() # Return to test 2
- Get elements directly by class name and id name
d = pq("<div><p id='1'>test 1</p><p class='2'>test 2</p></div>")
d('#1').html() # Return to test 1
d('.2').html() # Return to test 2
- Getting and Modifying Attribute Values
#Get attribute values:
d = pq("<p id='my_id'><a href='http://hello.com'>hello</a></p>")
d('a').attr('href') # Return to http://hello.com
d('p').attr('id') # Return to my_id
#Modify attribute values:
d('a').attr('href', 'http://baidu.com')
- Returns all subsequent element blocks: nextAll(selector=None)
d = pq("<p id='1'>hello</p><p id='2'>world</p><img scr='' />")
d('p:first').nextAll() # Return[<p#2>, <img>]
d('p:last').nextAll() # Return [<img>]
- Get child and parent elements
# children(selector=None) -- Getting child elements
d = pq("<span><p id='1'>hello</p><p id='2'>world</p></span>")
d.children() # Return[<p#1>, <p#2>]
d.children('#2') # Return[<p#2>]
#parents(selector=None) - Get the parent element
d = pq("<span><p id='1'>hello</p><p id='2'>world</p></span>")
d('p').parents() # Return [<span>]
d('#1').parents('span') # Return [<span>]
d('#1').parents('p') # Return []