In the first two sections, we got the city URL and city name. Today we will analyze the user information.
Climb the treasure net with go language for the first time
Climb the treasure net with go language

Crawler algorithm:
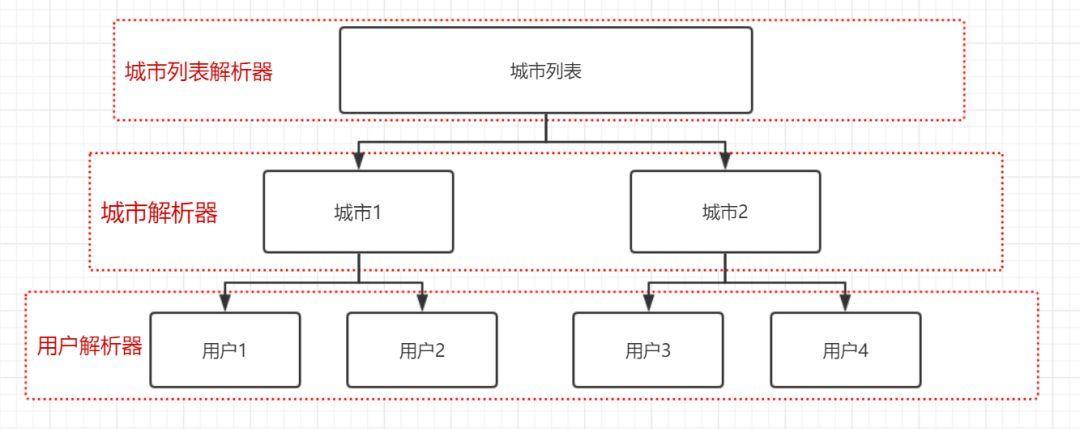
To extract the city list in the returned body, we need to use the city list parser;
All users in each city need to be parsed, and city parsers need to be used;
We also need to parse the personal information of each user, and we need to use a user parser.
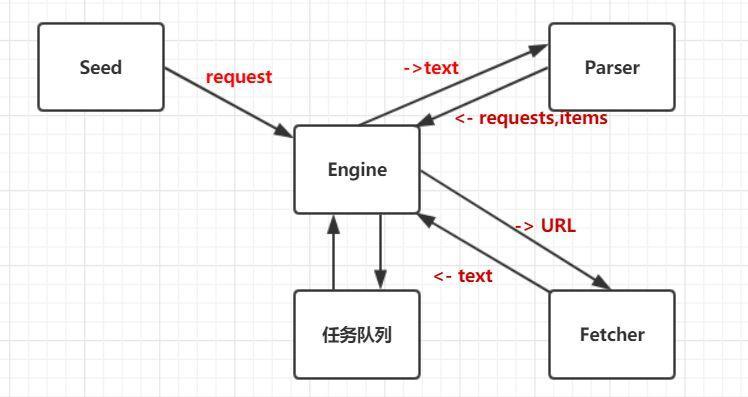
Overall architecture of crawler:
Seed sends the request to be crawled to the engine. The engine is responsible for sending the url in the request to the fetcher to crawl the data and return the information of utf-8. Then the engine sends the returned information to the Parser parser to parse the useful information and return more requests to be requested and useful information items. The task queue is used to store the requests to be requested. The engine drives each module to process the data until the task team Listed as empty.
Code implementation:
According to the above ideas, the citylist.go code of the city list parser is designed as follows:
package parser
import (
"crawler/engine"
"regexp"
"log"
)
const (
//How can I fall in love with you?</a>
cityReg = `<a href="(http://album.zhenai.com/u/[0-9]+)"[^>]*>([^<]+)</a>`
)
func ParseCity(contents []byte) engine.ParserResult {
compile := regexp.MustCompile(cityReg)
submatch := compile.FindAllSubmatch(contents, -1)
//Here, we need to generate a new request for each URL parsed.
result := engine.ParserResult{}
for _, m := range submatch {
name := string(m[2])
log.Printf("UserName:%s URL:%s\n", string(m[2]), string(m[1]))
//Add user information name to item
result.Items = append(result.Items, name)
result.Requests = append(result.Requests,
engine.Request{
//The URL corresponding to user information, which is used for subsequent user information crawling
Url : string(m[1]),
//This parse r is for users under the city.
ParserFunc : func(bytes []byte) engine.ParserResult {
//Closure is used here; m[2] cannot be used here, otherwise all users in the for loop will share the same name
//Need to copy m [2] - Name: = string (m [2])
return ParseProfile(bytes, name)
},
})
}
return result
}city.go is as follows:
package parser
import (
"crawler/engine"
"regexp"
"log"
)
const (
//How can I fall in love with you?</a>
cityReg = `<a href="(http://album.zhenai.com/u/[0-9]+)"[^>]*>([^<]+)</a>`
)
func ParseCity(contents []byte) engine.ParserResult {
compile := regexp.MustCompile(cityReg)
submatch := compile.FindAllSubmatch(contents, -1)
//Here, we need to generate a new request for each URL parsed.
result := engine.ParserResult{}
for _, m := range submatch {
name := string(m[2])
log.Printf("UserName:%s URL:%s\n", string(m[2]), string(m[1]))
//Add user information name to item
result.Items = append(result.Items, name)
result.Requests = append(result.Requests,
engine.Request{
//The URL corresponding to user information, which is used for subsequent user information crawling
Url : string(m[1]),
//This parse r is for users under the city.
ParserFunc : func(bytes []byte) engine.ParserResult {
//Closure is used here; m[2] cannot be used here, otherwise all users in the for loop will share the same name
//Need to copy m [2] - Name: = string (m [2])
return ParseProfile(bytes, name)
},
})
}
return result
}User parser profile.go is as follows:
package parser
import (
"crawler/engine"
"crawler/model"
"regexp"
"strconv"
)
var (
// <td>< span class = "label" > age: < span > 25</td>
ageReg = regexp.MustCompile(`<td><span class="label">Age:</span>([\d]+)year</td>`)
// <td>< span class = "label" > height: < span > 182cm</td>
heightReg = regexp.MustCompile(`<td><span class="label">Height:</span>(.+)CM</td>`)
// <td>< span class = "label" > monthly income: < span > 5001-8000 yuan</td>
incomeReg = regexp.MustCompile(`<td><span class="label">Monthly income:</span>([0-9-]+)element</td>`)
//<td>< span class = "label" > marital status: < span > unmarried</td>
marriageReg = regexp.MustCompile(`<td><span class="label">Marital status:</span>(.+)</td>`)
//<td>< span class = "label" > education background: < span > Bachelor degree</td>
educationReg = regexp.MustCompile(`<td><span class="label">Education:</span>(.+)</td>`)
//<td>Working place: Bengbu, Anhui Province</td>
workLocationReg = regexp.MustCompile(`<td><span class="label">Workplace:</span>(.+)</td>`)
// <td>< span class = "label" > Occupation: < / span >--</td>
occupationReg = regexp.MustCompile(`<td><span class="label">Occupation: </span><span field="">(.+)</span></td>`)
// <td>Constellation: Sagittarius</td>
xinzuoReg = regexp.MustCompile(`<td><span class="label">Constellation:</span><span field="">(.+)</span></td>`)
//<td>< span class = "label" > native place: < span > Bengbu, Anhui</td>
hokouReg = regexp.MustCompile(`<td><span class="label">Nation:</span><span field="">(.+)</span></td>`)
// <td>< span class = "label" > housing conditions: < span > < span field = "" > -- < / span ></td>
houseReg = regexp.MustCompile(`<td><span class="label">Housing conditions:</span><span field="">(.+)</span></td>`)
// < TD width = "150" ></td>
genderReg = regexp.MustCompile(`<td width="150"><span class="grayL">Gender:</span>(.+)</td>`)
// <td>< span class = "label" > weight: < span > < span field = "" > 67kg < / span ></td>
weightReg = regexp.MustCompile(`<td><span class="label">Body weight:</span><span field="">(.+)KG</span></td>`)
//< H1 class = "ceiling name IB FL fs24 lh32 blue" > How can I fall in love with you</h1>
//nameReg = regexp.MustCompile(`<h1 class="ceiling-name ib fl fs24 lh32 blue">([^\d]+)</h1> `)
//<td>< span class = "label" > purchase or not: < span > < span field = "" > no purchase < / span ></td>
carReg = regexp.MustCompile(`<td><span class="label">Purchase or not:</span><span field="">(.+)</span></td>`)
)
func ParseProfile(contents []byte, name string) engine.ParserResult {
profile := model.Profile{}
age, err := strconv.Atoi(extractString(contents, ageReg))
if err != nil {
profile.Age = 0
}else {
profile.Age = age
}
height, err := strconv.Atoi(extractString(contents, heightReg))
if err != nil {
profile.Height = 0
}else {
profile.Height = height
}
weight, err := strconv.Atoi(extractString(contents, weightReg))
if err != nil {
profile.Weight = 0
}else {
profile.Weight = weight
}
profile.Income = extractString(contents, incomeReg)
profile.Car = extractString(contents, carReg)
profile.Education = extractString(contents, educationReg)
profile.Gender = extractString(contents, genderReg)
profile.Hokou = extractString(contents, hokouReg)
profile.Income = extractString(contents, incomeReg)
profile.Marriage = extractString(contents, marriageReg)
profile.Name = name
profile.Occupation = extractString(contents, occupationReg)
profile.WorkLocation = extractString(contents, workLocationReg)
profile.Xinzuo = extractString(contents, xinzuoReg)
result := engine.ParserResult{
Items: []interface{}{profile},
}
return result
}
//get value by reg from contents
func extractString(contents []byte, re *regexp.Regexp) string {
m := re.FindSubmatch(contents)
if len(m) > 0 {
return string(m[1])
} else {
return ""
}
}The engine code is as follows:
package engine
import (
"crawler/fetcher"
"log"
)
func Run(seeds ...Request){
//Keep a queue here
var requestsQueue []Request
requestsQueue = append(requestsQueue, seeds...)
for len(requestsQueue) > 0 {
//Take the first one.
r := requestsQueue[0]
//Keep only unprocessed request s
requestsQueue = requestsQueue[1:]
log.Printf("fetching url:%s\n", r.Url)
//Crawling data
body, err := fetcher.Fetch(r.Url)
if err != nil {
log.Printf("fetch url: %s; err: %v\n", r.Url, err)
//An error occurred and continue to crawl the next url
continue
}
//Analyze the result of crawling
result := r.ParserFunc(body)
//Continue to add the request in the crawl result to the request queue
requestsQueue = append(requestsQueue, result.Requests...)
//Print the item in each result, that is, print the city name, the person name under the city...
for _, item := range result.Items {
log.Printf("get item is %v\n", item)
}
}
}The Fetcher is used to initiate http get requests. Here's a point to note: Treasure web may have anti crawler restrictions, so you can send a request directly in the http.Get(url) mode, and 403 will be reported for denial of access. Therefore, you need to simulate the browser mode:
client := &http.Client{}
req, err := http.NewRequest("GET", url, nil)
if err != nil {
log.Fatalln("NewRequest is err ", err)
return nil, fmt.Errorf("NewRequest is err %v\n", err)
}
req.Header.Set("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36")
//Return request get return result
resp, err := client.Do(req)The final catcher code is as follows:
package fetcher
import (
"bufio"
"fmt"
"golang.org/x/net/html/charset"
"golang.org/x/text/encoding"
"golang.org/x/text/encoding/unicode"
"golang.org/x/text/transform"
"io/ioutil"
"log"
"net/http"
)
/**
Crawling network resource function
*/
func Fetch(url string) ([]byte, error) {
client := &http.Client{}
req, err := http.NewRequest("GET", url, nil)
if err != nil {
log.Fatalln("NewRequest is err ", err)
return nil, fmt.Errorf("NewRequest is err %v\n", err)
}
req.Header.Set("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36")
//Return request get return result
resp, err := client.Do(req)
//Use http.Get(url) to get information directly. 403 may be returned when crawling. Access is forbidden.
//resp, err := http.Get(url)
if err != nil {
return nil, fmt.Errorf("Error: http Get, err is %v\n", err)
}
//Close response body
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
return nil, fmt.Errorf("Error: StatusCode is %d\n", resp.StatusCode)
}
//utf8Reader := transform.NewReader(resp.Body, simplifiedchinese.GBK.NewDecoder())
bodyReader := bufio.NewReader(resp.Body)
utf8Reader := transform.NewReader(bodyReader, determineEncoding(bodyReader).NewDecoder())
return ioutil.ReadAll(utf8Reader)
}
/**
Confirm coding format
*/
func determineEncoding(r *bufio.Reader) encoding.Encoding {
//The r here is read to make sure that resp.Body is readable.
body, err := r.Peek(1024)
//If an error is encountered while parsing the encoding type, UTF-8 is returned
if err != nil {
log.Printf("determineEncoding error is %v", err)
return unicode.UTF8
}
//It is simplified here without confirmation.
e, _, _ := charset.DetermineEncoding(body, "")
return e
}The main method is as follows:
package main
import (
"crawler/engine"
"crawler/zhenai/parser"
)
func main() {
request := engine.Request{
Url: "http://www.zhenai.com/zhenghun",
ParserFunc: parser.ParseCityList,
}
engine.Run(request)
}The user information finally crawled is as follows, including nickname, age, height, weight, salary, marital status, etc.
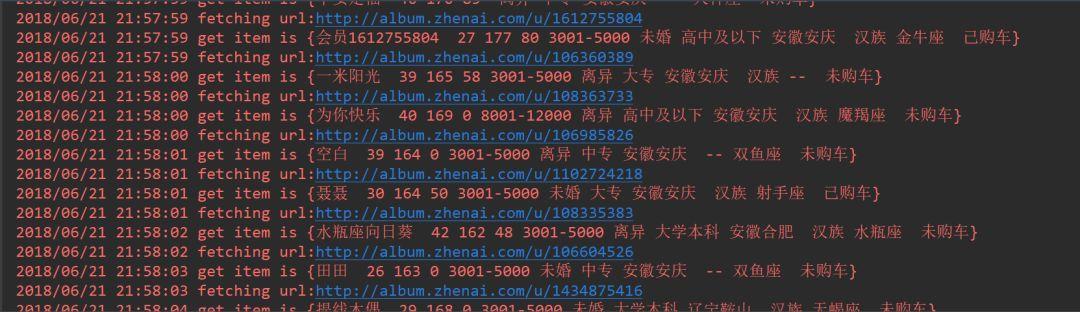
If you want a picture of which girl, you can click the url to check it, and then say hello to further development.
At this point, the single task version of the crawler is finished. Later, we will do performance analysis on the single task version of the crawler, and then upgrade to the multi task Concurrent Version, store the crawled information in elastic search, and query on the page.
This public account provides free csdn download service and massive it learning resources. If you are ready to enter the IT pit and aspire to become an excellent program ape, these resources are suitable for you, including but not limited to java, go, python, springcloud, elk, embedded, big data, interview materials, front-end and other resources. At the same time, we have set up a technology exchange group. There are many big guys who will share technology articles from time to time. If you want to learn and improve together, you can reply [2] in the background of the public account. Free invitation plus technology exchange groups will learn from each other and share programming it related resources from time to time.
Scan the code to pay attention to the wonderful content and push it to you at the first time

This public account provides free csdn download service and massive it learning resources. If you are ready to enter the IT pit and aspire to become an excellent program ape, these resources are suitable for you, including but not limited to java, go, python, springcloud, elk, embedded, big data, interview materials, front-end and other resources. At the same time, we have set up a technology exchange group. There are many big guys who will share technology articles from time to time. If you want to learn and improve together, you can reply [2] in the background of the public account. Free invitation plus technology exchange groups will learn from each other and share programming it related resources from time to time.
Scan the code to pay attention to the wonderful content and push it to you at the first time
