This article is about Learning Guide for Big Data Specialists from Zero (Full Upgrade) ClickHouse: Partial supplement.
Table Engine
4.1 Use of Table Engine
The table engine is a feature of ClickHouse. It can be said that the table engine determines how the underlying data is stored. These include:
_How and where data is stored, where it is written, and where it is read from
_Which queries are supported and how.
_Concurrent data access.
_Use of index if it exists.
_Whether multithreaded requests can be executed.
_Data copy parameters.
The table engine is used by explicitly defining the engine used by the table when it is created and the associated parameters used by the engine.
Special note: Engine names are case sensitive
4.2 TinyLog
Save as a column file on disk, does not support indexing, and has no concurrency control. Generally, small tables with a small amount of data are saved, which have limited effect on production environment. They can be used for normal practice tests.
For example:
create table t_tinylog ( id String, name String) engine=TinyLog;
4.3 Memory
Memory engine, where data is stored directly in memory in uncompressed original form and server restart data disappears. Read and write operations do not block each other and do not support indexing. Very high performance (over 10G/s) with simple queries.
It is typically used in very few places, except for testing, in scenarios where very high performance is required and the data volume is not too large (the upper limit is about 100 million rows).
4.4 MergeTree
The most powerful table engine in ClickHouse is the MergeTree engine and other engines in this series (*MergeTree), which supports indexing and partitioning and can rank innodb over Mysql. MergeTree also spawned many younger brothers and is a very distinctive engine.
_table building statement
create table t_order_mt( id UInt32, sku_id String, total_amount Decimal(16,2), create_time Datetime ) engine =MergeTree partition by toYYYYMMDD(create_time) primary key (id) order by (id,sku_id);
_Insert data
insert into t_order_mt values (101,'sku_001',1000.00,'2020-06-01 12:00:00') , (102,'sku_002',2000.00,'2020-06-01 11:00:00'), (102,'sku_004',2500.00,'2020-06-01 12:00:00'), (102,'sku_002',2000.00,'2020-06-01 13:00:00'), (102,'sku_002',12000.00,'2020-06-01 13:00:00'), (102,'sku_002',600.00,'2020-06-02 12:00:00');
MergeTree actually has a number of parameters (most of which are the defaults), but the three parameters are more important and involve many of the concepts about MergeTree.
4.4.1 partition by partition (optional)
Action
You should not be unfamiliar with hive s. The main purpose of partitioning is to reduce the scanning range and optimize the query speed
_If not filled in
Only one partition will be used.
_Partition directory
MergeTree is made up of column files + index files + table definition files, but if partitions are set they will be saved in different partition directories.
_Parallel
After partitioning, ClickHouse processes query statistics across partitions in parallel.
_Data write and partition merge
Any batch of data writes will result in a temporary partition that will not be included in any existing partition. At some point after writing (after about 10-15 minutes), ClickHouse will automatically perform a merge operation (wait or manually optimize) to merge the data from the temporary partition into the existing partition.
optimize table xxxx final;
_For example
Perform the above insert operation again
insert into t_order_mt values (101,'sku_001',1000.00,'2020-06-01 12:00:00') , (102,'sku_002',2000.00,'2020-06-01 11:00:00'), (102,'sku_004',2500.00,'2020-06-01 12:00:00'), (102,'sku_002',2000.00,'2020-06-01 13:00:00'), (102,'sku_002',12000.00,'2020-06-01 13:00:00'), (102,'sku_002',600.00,'2020-06-02 12:00:00');
Viewing data is not included in any partitions
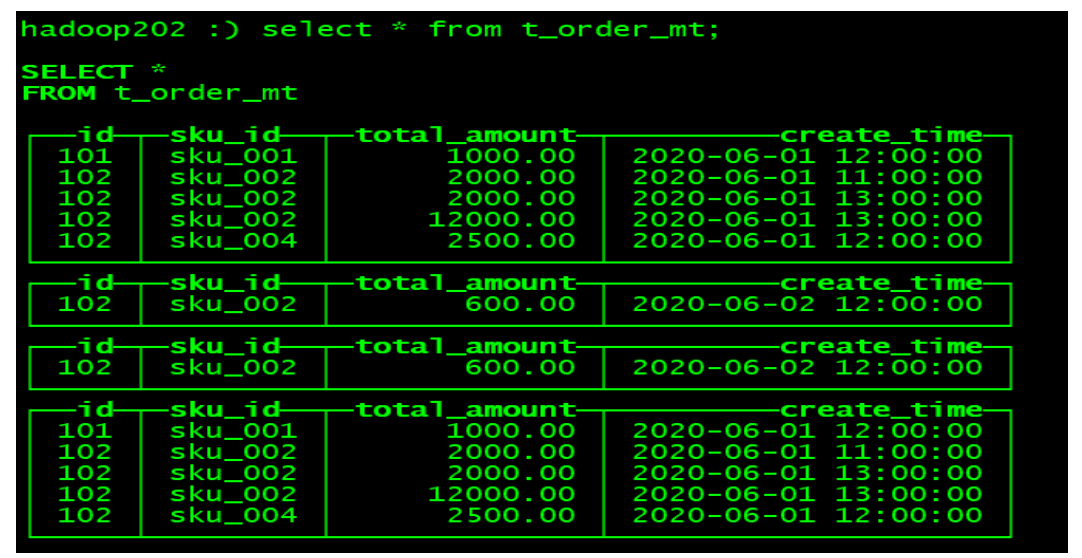
After manual optimization
hadoop202 :) optimize table t_order_mt final;
Query again
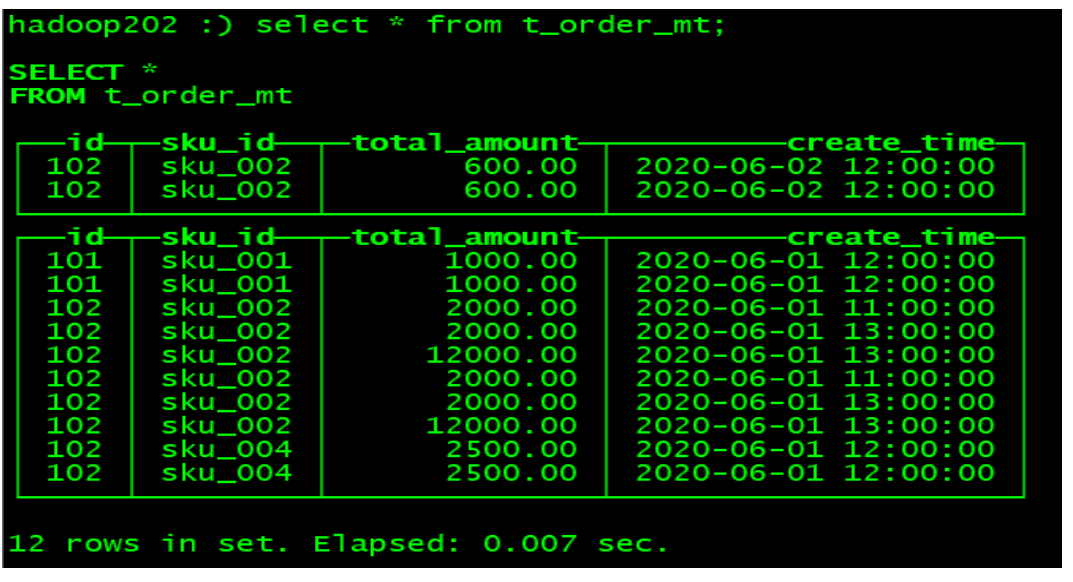


4.4.2 primary key primary key (optional)
Primary keys in ClickHouse, unlike other databases, provide only a first-level index of the data, but are not unique constraints. This means that data with the same primary key can exist.
The primary key is set mainly based on where condition in the query statement.
By doing some form of binary lookup on the primary key according to the conditions, the corresponding index granularity can be located, avoiding full table scanning.
Index granularity: Direct translation refers to index granularity, which refers to the interval between data corresponding to two adjacent indexes in a sparse index. MergeTree in ClickHouse defaults to 8192. It is not recommended to modify this value unless the column has a large number of duplicate values, such as tens of thousands of rows in a partition.
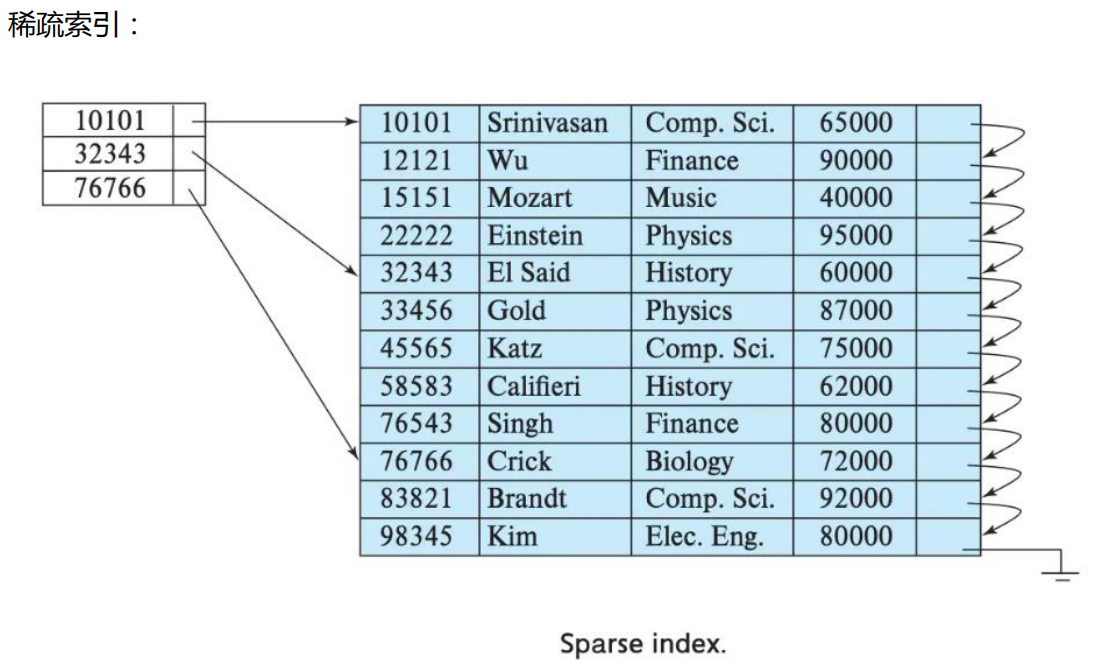
The advantage of sparse indexing is that you can locate more data with less indexed data at the expense of only locating the first row at the index granularity and then performing a little scanning.
4.4.3 order by (required)
order by sets in which field order the data within a partition is stored in order.
Order by is the only required item in MergeTree, even more important than primary key, because when the user does not set a primary key, many of the processes are handled according to the field of order by (for example, the redundancy and the
Summary).
Requirements: The primary key must be a prefix field for the order by field.
For example, if the order by field is (id,sku_id), then the primary key must be either ID or (id,sku_id)
4.4.4 Secondary Index
The current functionality of the secondary index on ClickHouse's official Web site is labeled experimental.
(1) Additional settings are required before using secondary indexes
Whether experimental secondary indexes are allowed
set allow_experimental_data_skipping_indices=1;
(2) Create test tables
create table t_order_mt2( id UInt32, sku_id String, total_amount Decimal(16,2), create_time Datetime, INDEX a total_amount TYPE minmax GRANULARITY 5 ) engine =MergeTree partition by toYYYYMMDD(create_time) primary key (id) order by (id, sku_id);
GRANULARITY N is the granularity that sets the granularity of a secondary index to a primary index.
(3) Insert data
insert into t_order_mt2 values (101,'sku_001',1000.00,'2020-06-01 12:00:00') , (102,'sku_002',2000.00,'2020-06-01 11:00:00'), (102,'sku_004',2500.00,'2020-06-01 12:00:00'), (102,'sku_002',2000.00,'2020-06-01 13:00:00'), (102,'sku_002',12000.00,'2020-06-01 13:00:00'), (102,'sku_002',600.00,'2020-06-02 12:00:00');
(4) Contrast effect
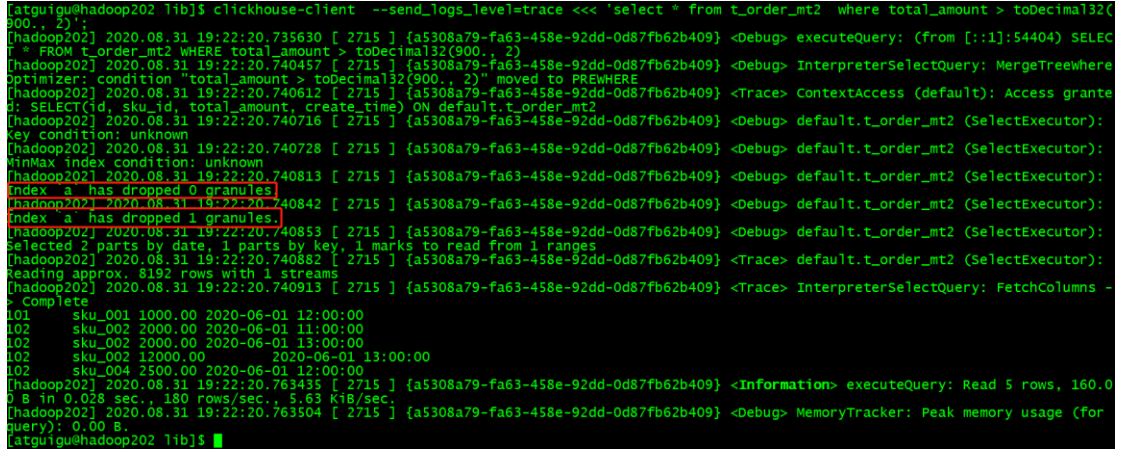
Then, by testing with the following statement, you can see that the secondary index can work for queries that are not primary key fields.
[atguigu@hadoop202 lib]$ clickhouse-client --send_logs_level=trace <<< 'select
* from t_order_mt2 where total_amount > toDecimal32(900., 2)';
4.4.5 Data TTL
TTL is Time To Live, and MergeTree provides the ability to manage the life cycle of a data or column.
(1) Column level TTL
_Create test tables
create table t_order_mt3( id UInt32, sku_id String, total_amount Decimal(16,2) TTL create_time+interval 10 SECOND, create_time Datetime ) engine =MergeTree partition by toYYYYMMDD(create_time) primary key (id) order by (id, sku_id);
_Insert data (note: change according to actual time)
insert into t_order_mt3 values (106,'sku_001',1000.00,'2020-06-12 22:52:30'), (107,'sku_002',2000.00,'2020-06-12 22:52:30'), (110,'sku_003',600.00,'2020-06-13 12:00:00');
_Manual merge, after the viewing effect expires, the specified field data is returned to 0
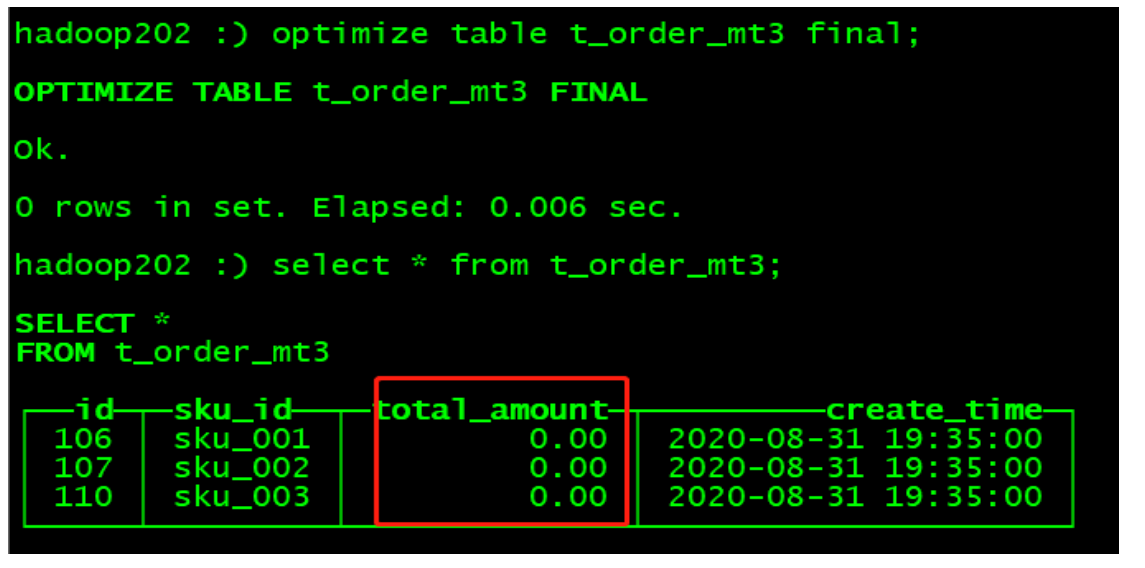
(2) Table level TTL
The following statement is that data will be lost 10 seconds after create_time
alter table t_order_mt3 MODIFY TTL create_time + INTERVAL 10 SECOND;
The field involved in the judgment must be of type Date or Datetime, and a partitioned date field is recommended.
Available time periods:
- SECOND
- MINUTE
- HOUR
- DAY
- WEEK
- MONTH
- QUARTER
- YEAR
4.5 ReplacingMergeTree
ReplacingMergeTree is a variant of MergeTree, which stores features that fully inherit MergeTree, but only add one extra weight-removal function. Although MergeTree can set a primary key, primary key does not actually have a unique constraint function. If you want to process duplicate data, you can use this ReplacingMergeTree.
_Time to Remove
Data de-emphasis will only occur during merging. Merging occurs in the background at an unknown time, so you cannot plan ahead. Some data may not have been processed yet.
_weight removal range
If a table has been partitioned, de-weighting will only occur within the partition, not across partitions. ReplacingMergeTree has limited capabilities and is suitable for cleaning up duplicate data in the background to save space, but it does not guarantee that no duplicate data will appear.
_Case Demonstration
◼ Create Table
create table t_order_rmt( id UInt32, sku_id String, total_amount Decimal(16,2) , create_time Datetime ) engine =ReplacingMergeTree(create_time) partition by toYYYYMMDD(create_time) primary key (id) order by (id, sku_id);
ReplacingMergeTree() fills in the parameter as the version field, with duplicate data retaining the maximum version field value.
If you do not fill in the version field, the last item is retained by default in the insertion order.
◼ Insert data into a table
insert into t_order_rmt values (101,'sku_001',1000.00,'2020-06-01 12:00:00') , (102,'sku_002',2000.00,'2020-06-01 11:00:00'), (102,'sku_004',2500.00,'2020-06-01 12:00:00'), (102,'sku_002',2000.00,'2020-06-01 13:00:00'), (102,'sku_002',12000.00,'2020-06-01 13:00:00'), (102,'sku_002',600.00,'2020-06-02 12:00:00');
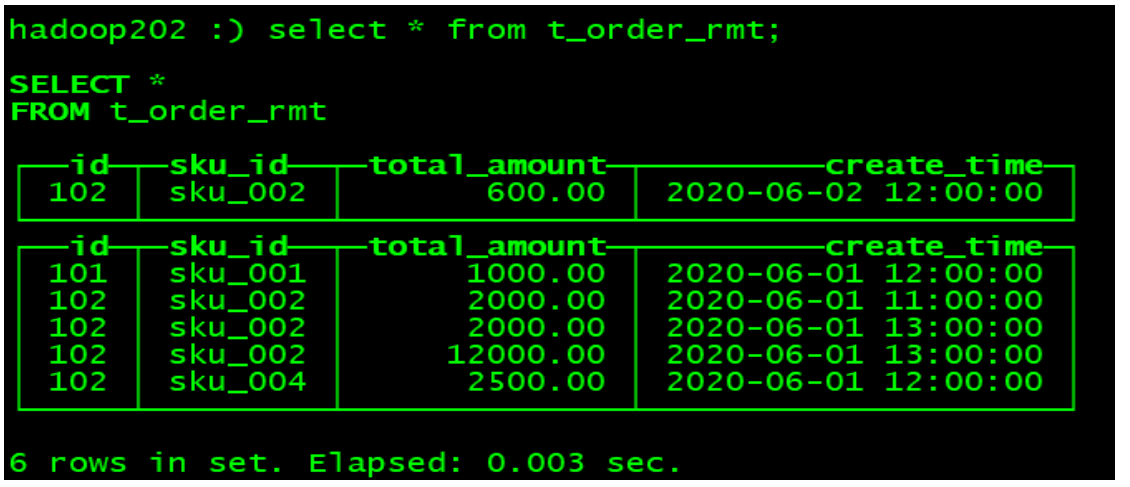
◼ Execute the first query
hadoop202 :) select * from t_order_rmt;
◼ Manual Merge
OPTIMIZE TABLE t_order_rmt FINAL;
◼ Execute the query again
hadoop202 :) select * from t_order_rmt;
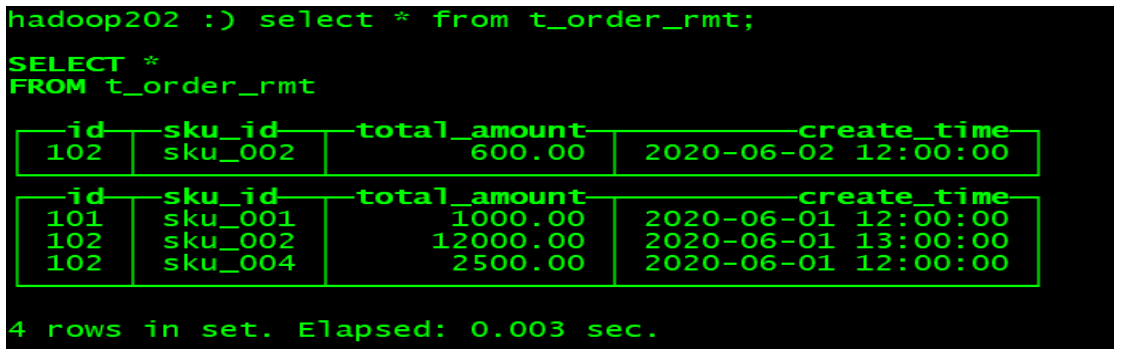
_Draw conclusions through testing
◼ The order by field is actually used as the unique key
◼ Removing weights cannot cross partitions
◼ Only merged partitions will be deduplicated
◼ Identify duplicate data retention, maximum version field value
◼ Keep the last pen in insertion order if the version fields are the same
4.6 SummingMergeTree
For scenarios where aggregation results are summarized in dimensions without query detail, the cost of either storage space or temporary aggregation while querying is greater if you only use a generic MageTree.
ClickHouse provides an engine SummingMergeTree that can "pre-aggregate" for this scenario
_Case Demonstration
◼ Create Table
create table t_order_smt( id UInt32, sku_id String, total_amount Decimal(16,2) , create_time Datetime ) engine =SummingMergeTree(total_amount) partition by toYYYYMMDD(create_time) primary key (id) order by (id,sku_id );
◼ insert data
insert into t_order_smt values (101,'sku_001',1000.00,'2020-06-01 12:00:00'), (102,'sku_002',2000.00,'2020-06-01 11:00:00'), (102,'sku_004',2500.00,'2020-06-01 12:00:00'), (102,'sku_002',2000.00,'2020-06-01 13:00:00'), (102,'sku_002',12000.00,'2020-06-01 13:00:00'), (102,'sku_002',600.00,'2020-06-02 12:00:00');
◼ Execute the first query
hadoop202 :) select * from t_order_smt;
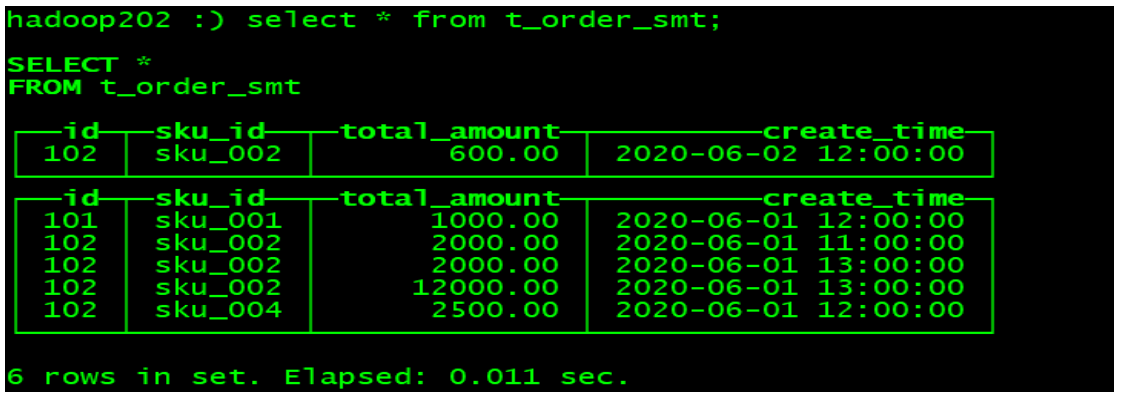
◼ Manual Merge
OPTIMIZE TABLE t_order_smt FINAL;
◼ Execute the query again
hadoop202 :) select * from t_order_smt;
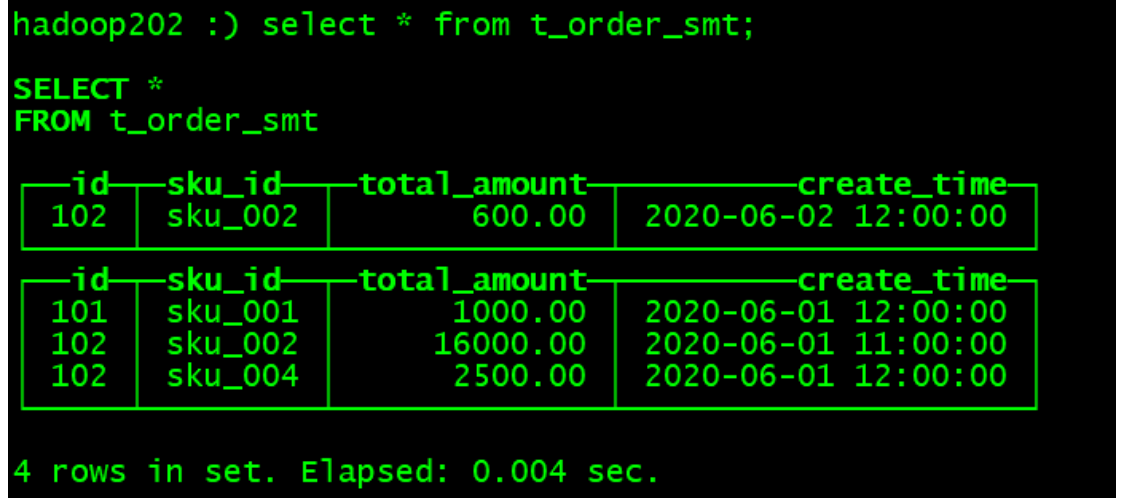
From the results, the following conclusions can be drawn
◼ Use the column specified in SummingMergeTree() as the summary data column
◼ You can fill in multiple columns that must have numeric columns. If you don't, use all non-dimensional columns and fields that are numeric columns as summary data columns
◼ order by column as dimension column
◼ Other columns keep the first row in insertion order
◼ Data that is not in one partition will not be aggregated
_Development Recommendations
When designing aggregation tables, unique key values, pipelining numbers can be removed, and all fields are dimensions, measures, or timestamps.
Question
Can the following SQL be executed directly to get summary values
select total_amount from XXX where province_name='' and create_date='xxx'
No, it may contain some temporary details that haven't been aggregated yet
If you want to get summary values, you still need to aggregate using sum, which will improve efficiency, but the ClickHouse itself is a column storage and the efficiency improvements are limited and not particularly noticeable.
select sum(total_amount) from province_name='' and create_date='xxx'