objective
Click a link to a picture on a page of douban: Photographs of 5 cm/s/s/s/s/s/s/s/s/s/s/s/s/s/s/s/s/s/s/s/s/s/s/s/s/s/s/s/s/s/s/s/s/s/s/s/s/s/s/s
thinking
Overall idea: Get a page-by-page picture link for each page. For each page, get both the page address of the next page and the image link of this page.
An example: https://img3.doubanio.com/view/photo/photo/public/p2407668722.jpg . This is not the original link. Because there is no simulated login, it is not possible to view the link to the original map. However, after comparison and analysis, the original graph chain can be obtained by replacing the second "photo" string with "raw" in the small graph link. https://img3.doubanio.com/view/photo/raw/public/p2407668722.jpg.
Download with Thunderbolt. Save the links in xml.
Crawler idea: Send HTTP GET request and get html text. Parse html text to get the required links.
Analysis
Sort the pictures by time.

Click to enter the first picture: First page
View page elements
Next page: 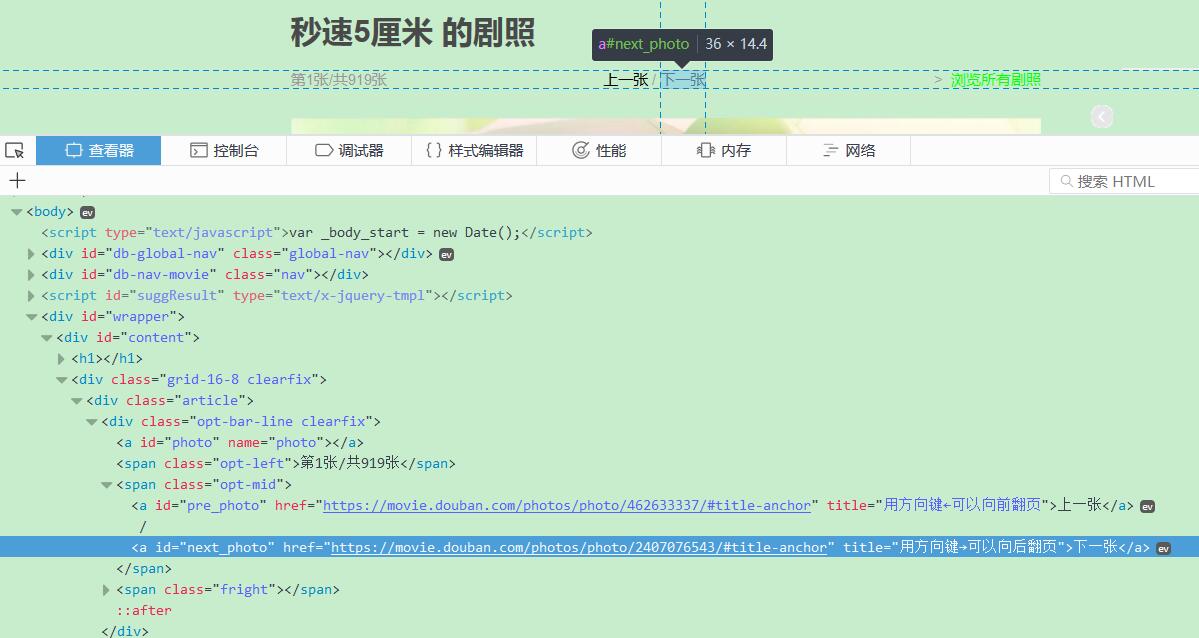
Picture links: 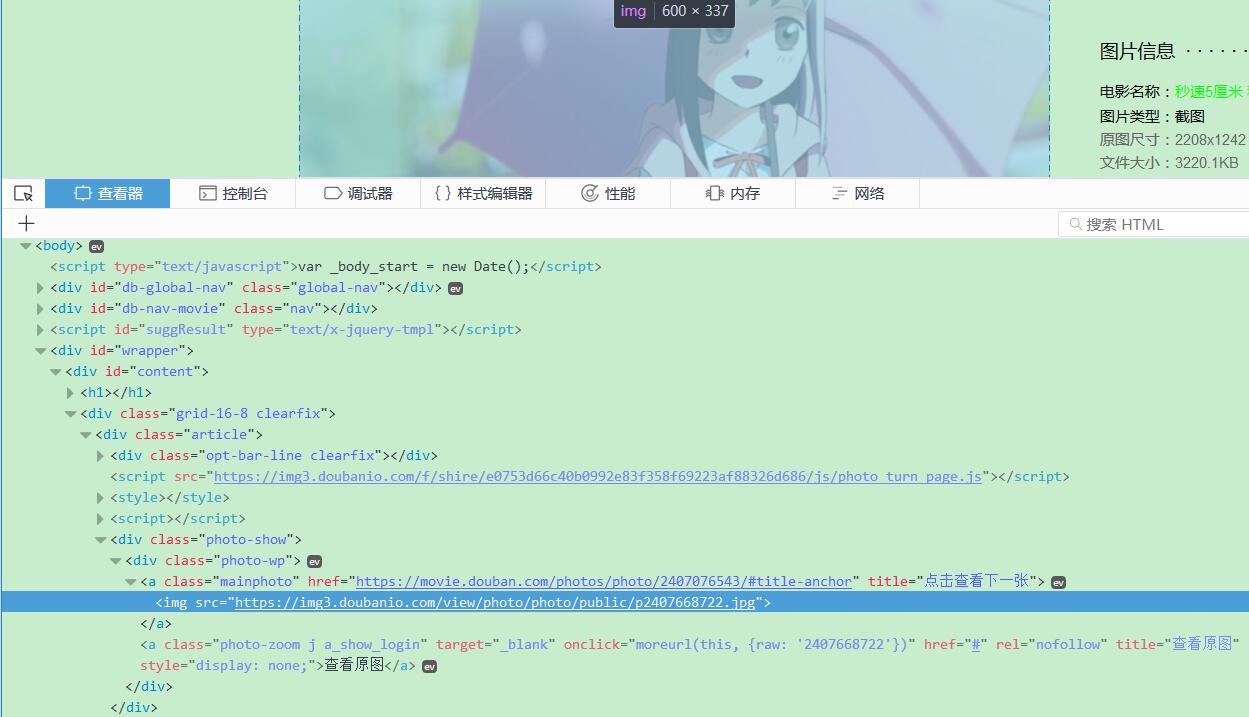
Code
Third-party jar packages required:
jsoup-1.8.1.jar
httpclient-4.5.2.jar
httpcore-4.4.4.jar
commons-logging-1.2.jar
Send HTTP GET request and get response message.
/**
* Send HTTP GET request to get the entity part of the response message
*
* @param url
* @param Referer
* @return
* @throws ClientProtocolException
* @throws IOException
*/
public static String getHtmlString(String url, String Referer) throws ClientProtocolException, IOException {
CloseableHttpClient httpClient = null;
CloseableHttpResponse htttpResponse = null;
String responseContent = null; /* Content returned */
/**
* HTTP Request header row field
*/
final String ACCEPT = "Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8";
final String ACCEPT_LANGUAGE = "Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8";
final String CONNECTION = "Connection:keep-alive";
final String UPGRADE_INSECURE_REQUESTS = "Upgrade-Insecure-Requests:1";
final String USER_AGENT = "User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36";
httpClient = HttpClients.createDefault(); /* First create the HttpClient object */
HttpGet httpGet = new HttpGet(url); /* Create HTTP request object */
/* Forgery HTTP HEADER */
httpGet.setHeader(ACCEPT, url);
httpGet.setHeader(ACCEPT_LANGUAGE, url);
httpGet.setHeader(CONNECTION, url);
httpGet.setHeader(Referer, url); /* The address of the previous page, followed by the current request page. */
httpGet.setHeader(UPGRADE_INSECURE_REQUESTS,
url);/* Upgrade-Insecure-Requests First Behavior Specific to Google Browser */
httpGet.setHeader(USER_AGENT, url);
/*
* Set the timeout connection timeout time to 5000 milliseconds and set the timeout time to 1000 milliseconds for getting Connection from Connection Manager
* The timeout for requesting data is 6000 milliseconds
*/
RequestConfig requestConfig = RequestConfig.custom().setConnectTimeout(5000).setConnectionRequestTimeout(1000)
.setSocketTimeout(6000).build();
httpGet.setConfig(requestConfig);
try {
htttpResponse = httpClient.execute(httpGet); /* HTTP response */
} catch (ConnectTimeoutException e) {
System.out.println("request time out!");
return null;
}
/* Get the status code. If the status code is not 200, return null. */
if (htttpResponse.getStatusLine().getStatusCode() != 200) {
System.out.println(htttpResponse.getStatusLine());
responseContent = null; // If the HTTP GET request is unsuccessful, the return content is null
} else {
HttpEntity httpEntity = htttpResponse.getEntity(); /* Get the entity part of the HTTP response message */
responseContent = EntityUtils.toString(httpEntity, "UTF-8");
// If the HTTP GET request succeeds, the return content is the entity part of the response message.
}
try {
httpClient.close();
htttpResponse.close();
} catch (Exception e) {
System.out.println(e);
}
return responseContent;
}Page parsing:
/**
* Get the page that contains the picture link directly
*
* @param htmlString
* @return String
*/
public static String getNextPage(String htmlString) {
String nextPageUrl = null;
Document htmlDocument = Jsoup.parse(htmlString); /* Parsing HTML documents */
Element spanElement = htmlDocument.select("span.opt-mid").first(); /* Get elements */
Element linkElement = spanElement.select("a").last();
if (linkElement == null) {
nextPageUrl = null; // If the link label does not exist, return null
} else {
nextPageUrl = linkElement.attr("href"); // If the link label exists, the url is returned
}
return nextPageUrl;
}
/**
* Get the picture links in each page
*
* @param htmlString
* @return String
* @throws IOException
*/
public static String getImageURL(String htmlString) throws IOException {
Document htmlDocument = Jsoup.parse(htmlString);
Element divElement = htmlDocument.select("div.photo-wp").first();
Element linkElement = divElement.getElementsByTag("img").first();
String imageUrl = linkElement.attr("src");
return imageUrl;
}Relevant approaches to XML operations:
/**
* Create an XML file
*
* @param filename
* File path
* @param rootname
* Name of root node
* @throws ParserConfigurationException
* @throws TransformerException
*/
public static void createXml(String filename, String rootname)
throws ParserConfigurationException, TransformerException {
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();/* Create Document Builder Factory */
DocumentBuilder documentBuilder = builderFactory.newDocumentBuilder();/* Create Document Builder */
Document xmlDocument = documentBuilder.newDocument();/* Create Document */
Element urlElement = xmlDocument.createElement(rootname); /* Create the root node */
xmlDocument.appendChild(urlElement);/* Add the root node to the Document */
TransformerFactory transformerFactory = TransformerFactory.newInstance(); /* Create TransformerFactory objects */
Transformer tf = transformerFactory.newTransformer(); /* Creating Transformer Objects */
tf.setOutputProperty(OutputKeys.INDENT, "yes"); /* Line Break When Setting Output Data */
tf.transform(new DOMSource(xmlDocument), new StreamResult(
filename));/* Transformer's transform() method is used to convert DOM tree into XML */
}
/**
* Add a new node to the specified node
*
* @param filePath
* File path
* @param fatherNode
* Parent Node Name
* @param newNode
* Add node name
* @param textContent
* Content of added nodes
* @throws ParserConfigurationException
* @throws SAXException
* @throws IOException
* @throws TransformerException
*/
public static void addNode(String filePath, String fatherNode, String newNode, String textContent)
throws ParserConfigurationException, SAXException, IOException, TransformerException {
Document xmlDocument = XmlOperateHelper.readXML(filePath);
Element itemElement = xmlDocument.createElement(newNode);
itemElement.setTextContent(textContent);
Node fNode = xmlDocument.getElementsByTagName(fatherNode).item(0);
fNode.appendChild(itemElement);
TransformerFactory transformerFactory = TransformerFactory.newInstance();
Transformer transformer = transformerFactory.newTransformer();
transformer.setOutputProperty(OutputKeys.INDENT, "yes");
transformer.transform(new DOMSource(xmlDocument), new StreamResult(filePath));
}
/**
* Read the XML file
*
* @param filePath
* @return Document
* @throws ParserConfigurationException
* @throws SAXException
* @throws IOException
*/
public static Document readXML(String filePath) throws ParserConfigurationException, SAXException, IOException {
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();/* Create Document Builder Factory */
DocumentBuilder documentBuilder = builderFactory.newDocumentBuilder();/* Create Document Builder */
Document urlXml = documentBuilder.parse(filePath);
return urlXml;
}Testing:
public class MainTest {
public static void main(String[] args)
throws IOException, ParserConfigurationException, TransformerException, SAXException, InterruptedException {
long startTime = System.currentTimeMillis();
String baseUrl = "https://movie.douban.com/photos/photo/2407668722/";
String fistReferer = "https://movie.douban.com/photos/photo/2407668722/";
String filePath = "C:\\Users\\L\\Desktop\\links.xml";
String nextReferer = null;
String linkString = null;
int imageCount = 1;
final int loopTime = 918;
XmlOperateHelper.createXml(filePath, "url");
String htmlString = HttpClientHelper.getHtmlString(baseUrl, fistReferer);
// System.out.println(html);
linkString = JsoupHelper.getImageURL(htmlString);
linkString = linkString.replaceAll("photo", "raw");
linkString = linkString.replaceFirst("raw", "photo");
System.out.println(linkString);
XmlOperateHelper.addNode(filePath, "url", "item", linkString);
nextReferer = baseUrl;
baseUrl = JsoupHelper.getNextPage(htmlString);
for (int i = 1; i < loopTime; i++) {
htmlString = HttpClientHelper.getHtmlString(baseUrl, nextReferer);
linkString = JsoupHelper.getImageURL(htmlString);
linkString = linkString.replaceAll("photo", "raw");
linkString = linkString.replaceFirst("raw", "photo");
System.out.println(linkString);
XmlOperateHelper.addNode(filePath, "url", "item", linkString);
nextReferer = baseUrl;
baseUrl = JsoupHelper.getNextPage(htmlString);
imageCount++;
Thread.currentThread();
int x = (int) (Math.random() * 100) + 500;
Thread.sleep(x);
}
System.out.println(imageCount);
long endTime = System.currentTimeMillis();
System.out.println("Time consuming:" + (endTime - startTime) + " ms");
}
}Results:
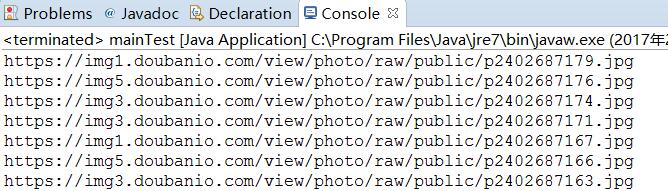
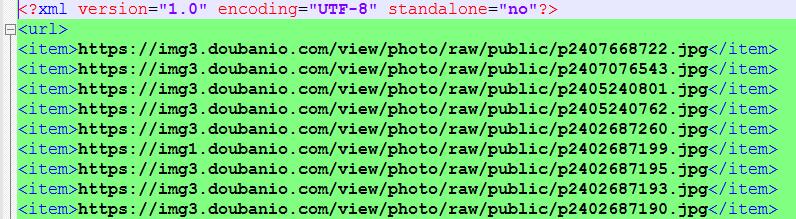
summary
It's just the simplest crawler. But there are still some problems in the process of writing. The first is the simulated landing problem. Because there is a validation code when landing. It's not settled yet. However, through analysis and comparison, the original map link can be obtained indirectly. The second is how to fake the crawler. If you climb too fast, the site will be banned from accessing, with serious direct IP blocking. So I camouflaged the crawler, first by camouflaging the request head, and secondly by reducing the crawling rate. Next, take a look at HTTP Authoritative Guide.