One definition
If most of the k most similar samples in the feature space belong to a certain category, then the sample also belongs to this category.
1.1 distance formula
The distance between two samples can be calculated by the following formula, also called Euclidean distance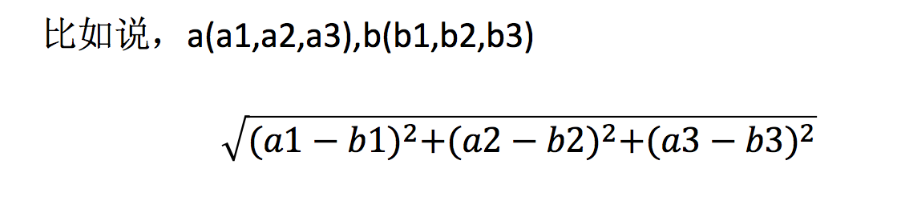
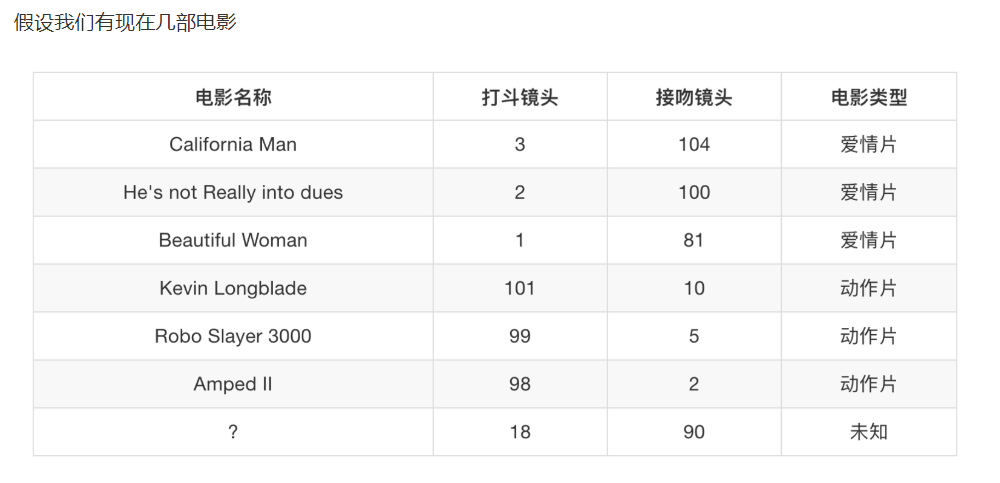
II. Analysis of film types
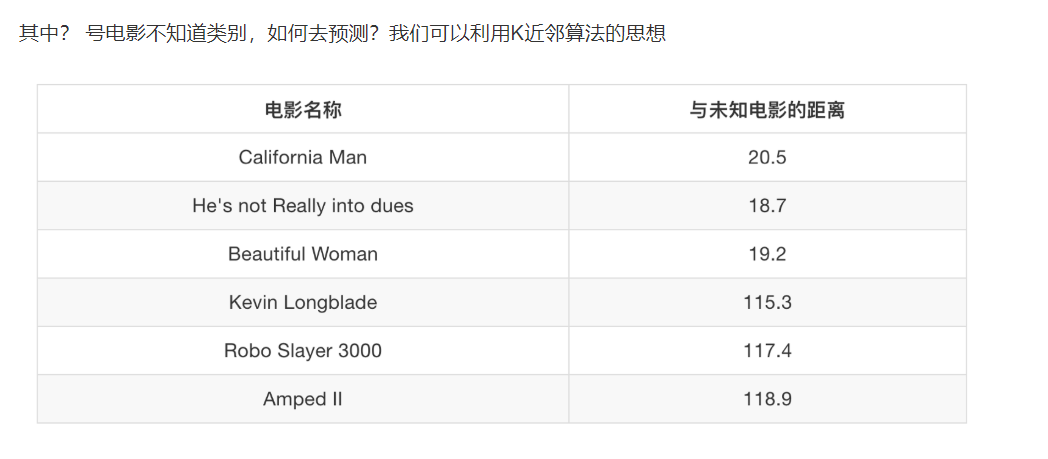
Three K-nearest neighbor algorithm API
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
- n_neighbors: int, optional (default = 5), k_neighbors query the number of neighbors used by default
- Algorithm: {'auto', 'ball tree', 'KD tree', 'brute'}, optional algorithm for calculating nearest neighbor: 'ball tree' will use BallTree, 'KD tree' will use KDTree. 'auto' will attempt to determine the most appropriate algorithm based on the value passed to the fit method. (different implementation methods affect efficiency)
Four cases: predicted sign in location
Data connection:
Link: https://pan.baidu.com/s/1O6rqUrD-QTeXYFJuElQFiw
Extraction code: w9d7

Data introduction:
train.csv,test.csv Row? ID: the ID of the registered event xy: coordinates Accuracy: positioning accuracy Time: time stamp place_id: the ID of the business, which is what you predict
4.1 data analysis
- Do some basic processing for the data (some of the processing done here may not achieve good results, we are just trying, some features can be processed according to some feature selection methods)
1. Narrow dataset DataFrame.query()
2. Process date data pd.to "datetime pd.datetimeindex
3. Add split date data
4. Delete the useless date data DataFrame.drop
5. Delete users with less than n check-in locations
place_count = data.groupby('place_id').count()
tf = place_count[place_count.row_id > 3].reset_index()
data = data[data['place_id'].isin(tf.place_id)]
-
Split data set
-
Standardized treatment
-
k-nearest neighbor prediction
4.2 procedure
from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier from sklearn.preprocessing import StandardScaler import pandas as pd """ k-Next to predicted user sign in location """ # 1. Read data data = pd.read_csv("./facebook-v-predicting-check-ins/train.csv") print(data.head(10)) #Processing data # 1. Reduce the size of the data, such as the location of the pladc ﹣ ID, which is different from each other, but there may be only one or two people in some locations, # Query data exposure data = data.query("x > 1.0 & x < 1.25 & y > 2.5 & y < 2.75") # 2. Processing time - time stamp date 1990-01-01 10:25:10 timevalue = pd.to_datetime(data['time'], unit='s') # Convert time format to dictionary format timevalue = pd.DatetimeIndex(timevalue) # Other features of construction feature adding time data['day'] = timevalue.day data['hour'] = timevalue.hour data['weekday'] = timevalue.weekday # Delete the time stamp feature: 1 in pd, 0 in ske data = data.drop(['time'], axis=1) # Delete less than n target locations place_count = data.groupby('place_id').count() tf = place_count[place_count.row_id > 3].reset_index() data = data[data['place_id'].isin(tf.place_id)] # 3. Remove the eigenvalue and target value from the data y = data['place_id'] x = data.drop(['place_id'], axis=1) # 4. Data segmentation x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25) # 5. Standardization characteristic Engineering std = StandardScaler() #Standardize the eigenvalues of test set and training set x_train = std.fit_transform(x_train) x_test = std.fit_transform(x_test) # 2. Algorithm flow # K value: the value of the algorithm's input parameter is uncertain theoretically: k = root number (number of samples) # K value: parameter tuning method will be used later to test out the best parameters in turn [1,3,5,10,20100200] knn = KNeighborsClassifier(n_neighbors=5) # Accurate rate of score estimation by predict of fit input data knn.fit(x_train, y_train) # Predict the test data set to get the accuracy rate y_predict = knn.predict(x_test) print("The predicted target check-in location is:",y_predict) # Get prediction accuracy print("Prediction accuracy:", knn.score(x_test, y_test))
4.3 result analysis
Accuracy: one of the evaluation of classification algorithm
- 1. What is the value of k? What's the impact?
Small value of k: easily affected by abnormal points
Large k value: the problem of sample equilibrium
- 2. Performance issues?
High time complexity in distance calculation
5, K-neighbor summary
- Advantage:
Simple, easy to understand, easy to implement, no training required - Disadvantages:
Lazy algorithm, large amount of calculation and large memory cost when classifying test samples
K value must be specified. If K value is not selected properly, classification accuracy cannot be guaranteed - Usage scenario: small data scenario, thousands to tens of thousands of samples, specific scenario and specific business to test

