Welcome back to: meet blue bridge, meet you, not negative code, not negative Qing!
catalogue
1, Introduction: depth first search (DFS)
Example 1. Scope and of binary search tree
4, Blue bridge conclusion: meet blue bridge meet you, not negative code, not negative Qing!
preface:
When it comes to depth first search (DFS), we can easily think of breadth first search (BFS). Together, they are called a search topic. Today, the author will make DFS clear, and the content of BFS will be explained in detail in the next chapter.
OK, no more nonsense, walk... Give you a little red flower first

1, Introduction: depth first search (DFS)
This content is very important. In order to facilitate your understanding, let's first cite a chestnut (from the book "algorithm notes" written by Hu fan and Zeng Lei).
For example, chestnuts:
Imagine that we are now in a huge maze from the first perspective. There is no God's perspective, no communication facilities, no miracles in hot-blooded animation, and there are only walls that grow the same around. So we can only find our own way out. If you lose your heart and walk around casually, you may be dizzy by the exactly same scenery around. At this time, you can only give up the so-called luck and take the following seemingly blind but actually effective method.
Take the current position as the starting point and walk along one road. When you encounter a fork, choose one of the forks. If there is a new turnout in the turnout, each turnout of the new turnout is still enumerated according to the above method. In this way, as long as there is an exit in the maze, this method can find it.
Iron juice may ask, if you choose a branch with no way out at the first fork, and this branch is deep, and there are new forks on the road many times, how can you return to the original fork when you find that this branch is a dead branch? In fact, the method is very simple. As long as you keep your right hand close to the wall on the right all the way forward, the above walking method will be executed automatically, and you will finally find the exit.
Look at the following figure:
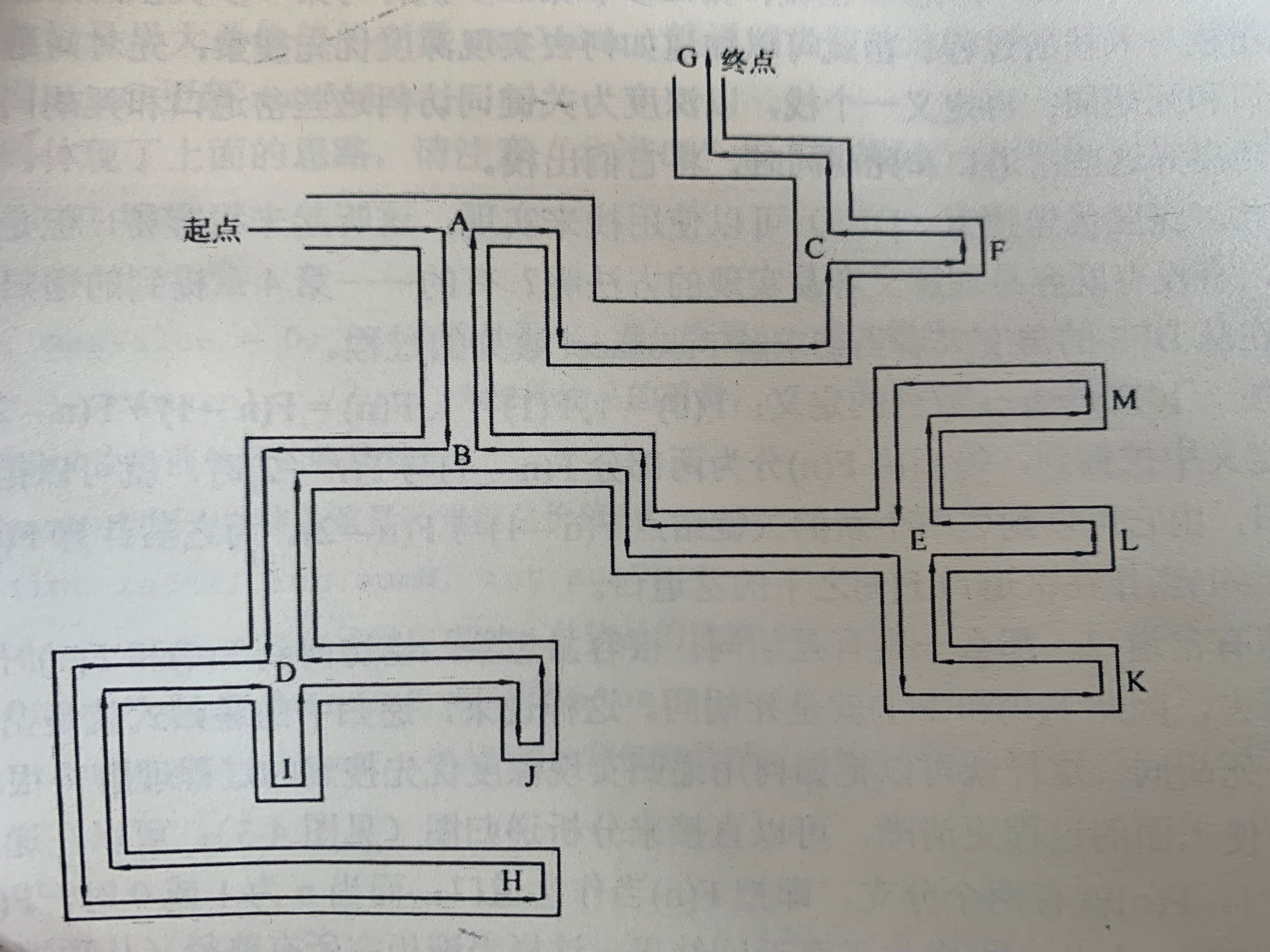
It can be seen from the figure that when you go forward from the starting point, you always choose one of the fork roads to go forward when you encounter a fork road (note that the fork road on the right side is always selected here). If you encounter a new fork road on the fork road, you still choose one of the fork roads of the new fork road to go forward until you encounter a dead alley, and then go back to the nearest fork road to choose another fork road. In other words, when you encounter a fork in the road, you always take "depth" as the key word to move forward, and you don't look back until you encounter a dead end. Therefore, this search method is called depth first search.
From the example of this maze, we can also note that depth first search will go through all paths, and each time we reach a dead end represents the formation of a complete path. That is, depth first search is a search method that enumerates all complete paths to traverse all cases.
Summarize what depth first search is:
Start from the root node, search each branch as deep as possible, search the results of one branch, and then look at another branch. The image is: "one way to the end, don't hit the south wall, don't look back".
[knocking on the blackboard]: the above content may be a little windy, so it is suggested that iron juice should read it carefully for three times and understand it well. After all, this chapter belongs to the higher part, which may be a little difficult to understand, but after doing the title, you will find it is not difficult. If you don't believe it, look back. No, no, first make it almost up, and then look back
Q: what better way to achieve depth first search?
In fact, to be easy to understand and implement, depth first search must be recursive
I don't need to emphasize the importance of recursion here. Recursion is used in many places later, especially the binary tree in the data structure.
Let's review the recursion part of the previous article:
Review the definition of Fibonacci sequence: F (0) = 1, f (1) = 1, F(n) = F(n - 1) + F(n - 2) (n > = 2). It can be learned from this definition that whenever F(n) is divided into two parts F(n - 1) and F(n - 2), F(n) can be regarded as the fork of the maze, from which it can reach two new key nodes F(n - 1) and F(n - 2). When F(n - 1) is calculated later, F(n - 1) can be regarded as the turnout below the turnout F(n).
Since there is a fork in the road, there must be a dead end. It's easy to imagine that when accessing F(0) and F(1), you can't recurse down, so F(0) and F(1) are dead ends here. In this way, the recursion in recursion is a fork in the road, and the recursion boundary is a dead end. In this way, we can clearly understand how to use recursion to realize depth first search.
Therefore, depth first search can be well realized by using recursion. This statement does not mean that depth first search is recursive. It can only be said that depth first search is an implementation of recursion, because the idea of DFS can also be realized by using non recursion, but it will be more troublesome than recursion in general. However, when using recursion, the system will call something called system stack to store the state of each layer in recursion. Therefore, the essence of using recursion to realize DFS is actually stack.
Main application scenarios of DFS:
- Binary tree search
- Graph search
OK, DFS was introduced briefly. Now we are going to serve hard dishes

2, Classic examples
Example 1. Scope and of binary search tree
Title Description
Given the root node of binary search tree Root, the return value is in the range [low, high] The sum of the values of all nodes between.
Note that the value of the root node is greater than that of the left subtree, and the value of the root node is less than that of the right subtree
Example 1:
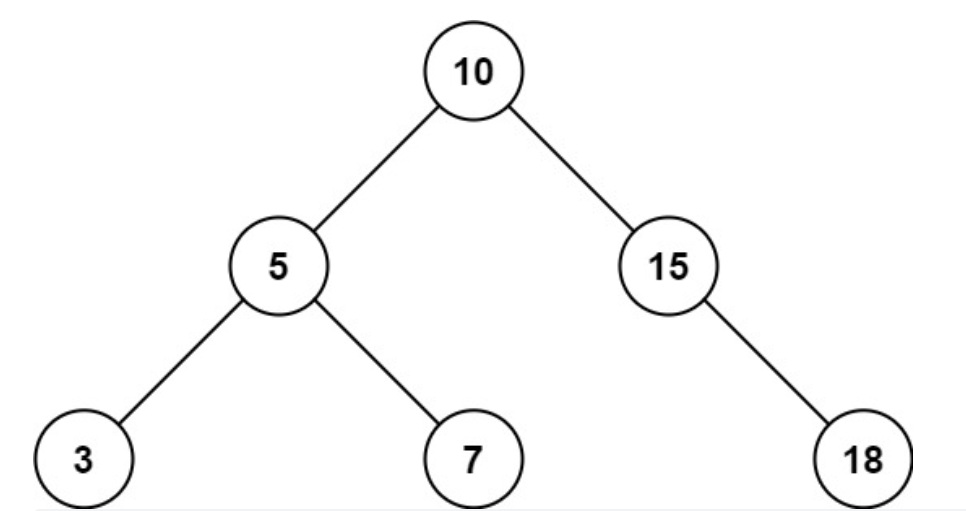
Input: root = [10,5,15,3,7,null,18], low = 7, high = 15 Output: 32
Example 2:
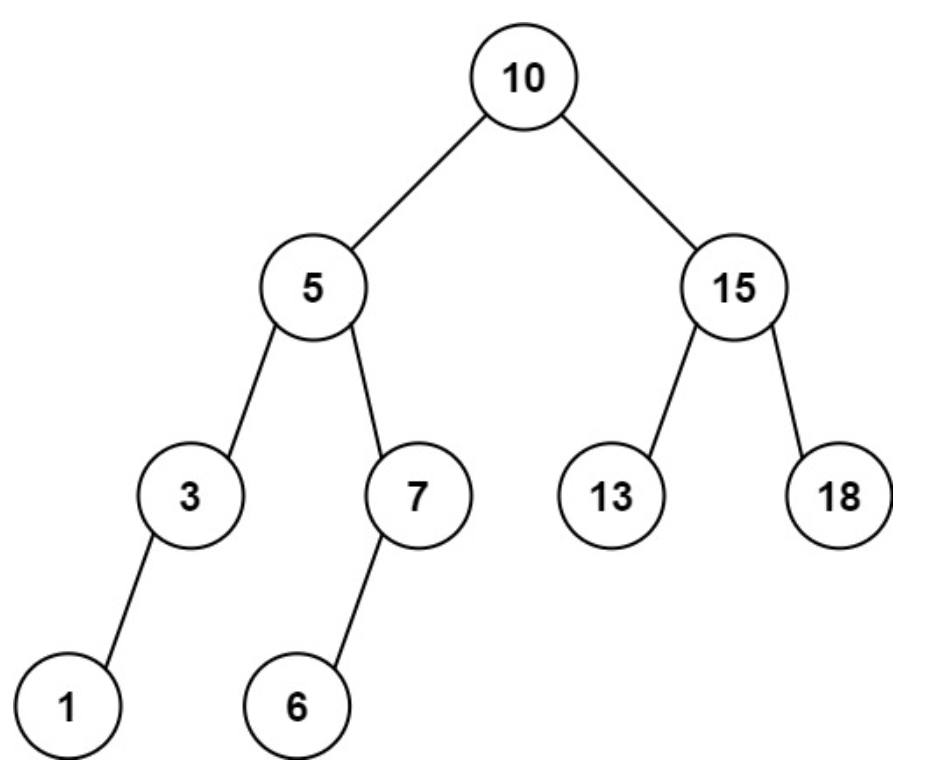
Input: root = [10,5,15,3,7,13,18,1,null,6], low = 6, high = 10 Output: 23
Problem solution
Calculate the range and in the order of depth first search. Note that the root node of the current subtree is root, which is discussed in the following four cases:
1. If the root node is empty, 0 is returned;
2. The value of the root node is greater than high. Since the values of all nodes on the right subtree of the binary search tree are greater than the value of the root node, that is, they are greater than high, there is no need to consider the right subtree and return the range and value of the left subtree;
3. The value of the root node is less than low. Since the values of all nodes on the left subtree of the binary search tree are less than the value of the root node, that is, they are less than low, there is no need to consider the left subtree and return the range and value of the right subtree;
4. If the value of the root node is within the range of [low,high], the sum of the value of the root node, the range and of the left subtree, and the range and of the right subtree shall be returned.
Code execution
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* struct TreeNode *left;
* struct TreeNode *right;
* };
*/
int rangeSumBST(struct TreeNode* root, int low, int high){
//Method 1: DFS
//Find recursive boundary (dead end)
if(root == NULL){
return 0;
}
//Fork
//If the value of the root node is greater than high, the value of the right subtree must not be satisfied. At this time, only the left subtree needs to be judged
if(root->val > high){
return rangeSumBST(root->left, low, high);
}
//If the value of the root node is less than low, the value of the left subtree must not be satisfied. At this time, only the right subtree needs to be judged
if(root->val < low){
return rangeSumBST(root->right, low, high);
}
//Otherwise, if the value of the root node is between low and high, the root node, left subtree and right subtree must be judged
return root->val + rangeSumBST(root->left, low, high) + rangeSumBST(root->right, low, high);
}Does it feel the same as recursion? After all, it uses the idea of recursion to solve the problem. Let's see how to solve the problem with pure recursion.
int rangeSumBST(struct TreeNode* root, int low, int high){
//Method 2: recursive method
//Find boundary
if(root == NULL){
return 0;
}
//Left subtree
int leftSum = rangeSumBST(root->left, low, high);
//Right subtree
int rightSum = rangeSumBST(root->right, low, high);
int result = leftSum + rightSum;
//Judge whether the root node meets
if(root->val >= low && root->val <= high){
result += root->val;
}
return result;
}OK, in fact, it feels good. It's not very difficult, and if you do more, you will find that recursion and divide and conquer are very interesting and wonderful.
Example 2. Number of islands
Title Description
Give you a chance ' A two-dimensional grid composed of 1 '(land) and 0' (water). Please calculate the number of islands in the grid.
Islands are always surrounded by water, and each island can only be formed by adjacent land connections in the horizontal and / or vertical direction.
In addition, you can assume that all four sides of the mesh are surrounded by water.
Example 1:
Input: grid = [ ["1","1","1","1","0"], ["1","1","0","1","0"], ["1","1","0","0","0"], ["0","0","0","0","0"] ] Output: 1
Example 2:
Input: grid = [ ["1","1","0","0","0"], ["1","1","0","0","0"], ["0","0","1","0","0"], ["0","0","0","1","1"] ] Output: 3
Problem solution
In order to find the number of islands, we can scan the whole two-dimensional grid. If a location is 1, the depth first search starts with it as the starting node. In the process of depth first search, each searched 1 will be re marked as 0, that is, all the 1 around 1 (up, down, left and right) will be assimilated into 0
Code execution
int numIslands(char** grid, int gridSize, int* gridColSize){
//Consider special circumstances
if(grid == NULL || gridSize == 0){
return 0;
}
int row = gridSize;//Number of rows
int col = *gridColSize;//Number of columns
int count = 0;//For counting
for(int i = 0; i < row; i++){
for(int j = 0; j < col; j++){
if(grid[i][j] == '1'){
count++;
}
dfs(grid, i, j, row, col);
}
}
return count;
}
void dfs(char** grid, int x, int y, int row, int col){
//Find recursive boundary (dead end)
if(x < 0 || x >= row || y < 0 || y >= col || grid[x][y] == '0'){
return;
}
grid[x][y] = '0';
//Fork
dfs(grid, x - 1, y, row, col);
dfs(grid, x + 1, y, row, col);
dfs(grid, x, y - 1, row, col);
dfs(grid, x, y + 1, row, col);
}Example 3. Knapsack problem
Title Description
There are n items, each with a weight of w[i] and a value of c[i]. Now you need to select several items and put them into a backpack with a capacity of v, so that the sum of the prices of the items in the backpack can be maximized and the maximum value can be obtained on the premise that the weight of the items selected into the backpack does not exceed the capacity of v.
Example:
Input: item weight: 3 5 1 2 2 item value: 4 5 2 1 3 Output: 10
Problem solution
In this problem, we need to select several items from n items and put them into the backpack to maximize the sum of their values. In this way, there are two choices for each item: choose or not, and this is the so-called "fork in the road". When you complete the selection of n items, you will reach the "dead end". However, this topic needs to consider one more situation. The total number of items you select should not exceed v. therefore, once the total weight of the selected items exceeds V, you will reach the "dead end". Therefore, this topic needs to be considered more. Iron juice should be careful. See the code implementation for details.
Code execution
//Title: there are n items. The weight of each item is w[i] and the value is c[i] (because each item is different, I means change). Now you need to select several items and put them into one
//In a knapsack with a capacity of V, the value of the items in the knapsack can be reduced to zero on the premise that the weight of the items selected into the knapsack does not exceed v
//And maximum, find the maximum value (1 < = n < = 20)
#include<stdio.h>
int maxValue = 0;//Maximum value
//The following four groups of data can be set by yourself. Because you want to simplify the topic, it is directly given here in the form of global variables
int n = 5;//Number of items
int v = 8;//Backpack Capacity
int w[] = { 3,5,1,2,2 };//w[i] is the weight of each item
int c[] = { 4,5,2,1,3 };//c[i] is the value of each item
//Index is the index of the currently processed item (the index range of the item is 0~n - 1)
//sumW and sumC are the current total weight and current total value respectively
void DFS(int index, int sumW, int sumC)
{
//The selection of n items has been completed (recursive boundary -- dead end)
if (index == n)
{
return;
}
//Fork
DFS(index + 1, sumW, sumC);//Don't select the first item
//Only when the capacity v is not exceeded after the first item is added can the execution continue (note this restriction)
if (sumW + w[index] <= v)
{
//Note: if the total value of the first item is greater than the maximum value, remember to update the maximum value
if (sumC + c[index] > maxValue)
{
maxValue = sumC + c[index];//Update maximum value maxValue
}
DFS(index + 1, sumW + w[index], sumC + c[index]);//Select item
}
}
int main()
{
DFS(0, 0, 0);//It is the first item at the beginning, and the current total weight and total value are 0
printf("The maximum value of meeting the conditions is:%d\n", maxValue);
return 0;
}3, Thinking questions
Today's thinking problem is to ask Tiezhi to take a look at the previous content about recursion and find more classic recursion problems to practice. come on
4, Blue bridge conclusion: meet blue bridge meet you, not negative code, not negative Qing!
I hope the above can help the iron juice people. It's not worth my time to update this content. If I feel I've gained something, can I pay more attention to it for three times, so that this article can be seen by more iron juice people? Hey, please, I'll make persistent efforts. 886, I'll see you next time.
