Chapter 2 RDD Programming
2.1 Programming Model
In Spark, RDDs are represented as objects that are converted through method calls on objects.After a series of transformations define the RDD, actions can be invoked to trigger RDD calculations, either by returning results to the application (count, collect, etc.) or by saving data to the storage system (saveAsTextFile, etc.).In Spark, RDD calculations (i.e., deferred calculations) are performed only when action is encountered, allowing multiple transformations to be piped at run time.
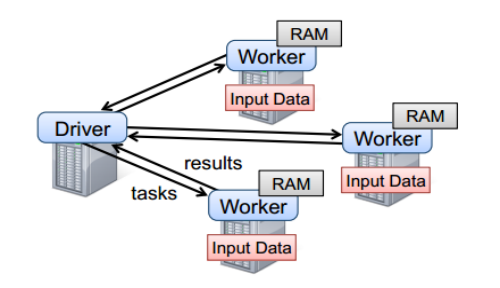
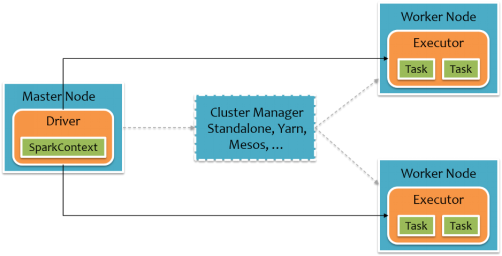
To use Spark, developers need to write a Driver program that is submitted to the cluster to schedule the worker to run, as shown in the following figure.Driver defines one or more RDDs and calls action s on the RDD, while Worker performs RDD partition calculation tasks.
2.2 RDD Creation
There are roughly three ways to create RDDs in Spark: from collections, from external storage, and from other RDDs.
Created from an existing Scala collection, the collection is parallelized.
val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
Create an RDD from a collection, Spark There are two main functions available: parallelize and makeRDD.Let's first look at the declarations of these two functions:
def parallelize[T: ClassTag]( seq: Seq[T], numSlices: Int = defaultParallelism): RDD[T] def makeRDD[T: ClassTag]( seq: Seq[T], numSlices: Int = defaultParallelism): RDD[T] def makeRDD[T: ClassTag](seq: Seq[(T, Seq[String])]): RDD[T]
We can see from the above that makeRDD has two implementations, and the parameters and parallelize received by the first makeRDD function are exactly the same.In fact, the first implementation of the makeRDD function relies on the implementation of the parallelize function to see how the makeRDD function is implemented in Spark:
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
parallelize(seq, numSlices)
}
We can see that this makeRDD function is exactly the same as the parallelize function.But let's look at the implementation of the second makeRDD function, which receives parameters of type Seq[(T, Seq[String]]], as described in the Spark documentation:
Distribute a local Scala collection to form an RDD, with one or more location preferences (hostnames of Spark nodes) for each object. Create a new partition for each collection item.
This function also provides location information for the data to see how we use it:
scala> val guigu1= sc.parallelize(List(1,2,3))
guigu1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[10] at parallelize at <console>:21
scala> val guigu2 = sc.makeRDD(List(1,2,3))
guigu2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[11] at makeRDD at <console>:21
scala> val seq = List((1, List("slave01")),| (2, List("slave02")))
seq: List[(Int, List[String])] = List((1,List(slave01)),
(2,List(slave02)))
scala> val guigu3 = sc.makeRDD(seq)
guigu3: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[12] at makeRDD at <console>:23
scala> guigu3.preferredLocations(guigu3.partitions(1))
res26: Seq[String] = List(slave02)
scala> guigu3.preferredLocations(guigu3.partitions(0))
res27: Seq[String] = List(slave01)
scala> guigu1.preferredLocations(guigu1.partitions(0))
res28: Seq[String] = List()
We can see that there are two implementations of the makeRDD function, the first one is actually exactly the same as parallelize, and the second one provides location information for the data, while the other is the same as the parallelize function, as follows:
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
assertNotStopped()
new ParallelCollectionRDD[T](this, seq, numSlices, Map[Int, Seq[String]]())
}
def makeRDD[T: ClassTag](seq: Seq[(T, Seq[String])]): RDD[T] = withScope {
assertNotStopped()
val indexToPrefs = seq.zipWithIndex.map(t => (t._2, t._1._2)).toMap
new ParallelCollectionRDD[T](this, seq.map(_._1), seq.size, indexToPrefs)
}
Both return ParallelCollectionRDD, and the implementation of this makeRDD cannot specify the number of partitions by itself, but is fixed to the size of the size of the seq parameter.
Created from datasets in external storage systems, including local file systems, and all Hadoop-supported datasets such as HDFS, Cassandra, HBase, and so on
scala> val atguigu = sc.textFile("hdfs://hadoop102:9000/RELEASE")
atguigu: org.apache.spark.rdd.RDD[String] = hdfs:// hadoop102:9000/RELEASE MapPartitionsRDD[4] at textFile at <console>:24