Original online reading: https://usyiyi.github.io/nlp-py-2e-zh/2.html
1. Obtaining Text Corpus
1.1 Gutenberg Corpus
>>> for fileid in gutenberg.fileids():
>... num_words = len(gutenberg.words(fileid))
>... num_vocab = len(set(w.lower() for w in gutenberg.words(fileid)))
>... num_sents = len(gutenberg.sents(fileid))
>... num_chars = len(gutenberg.raw(fileid))
> Print ("average word length:", "round(num_chars/num_words)," "average sentence length:", "round(num_words/num_sents)," "average number of occurrences of each word:", "round (num_words/num_vocab)," "fileid")
...
Average Word Length: 5 Average Sentence Length: 25 Average Frequencies of Each Word: 26 austen-emma.txt
Average Word Length: 5 Average Sentence Length: 26 Average Frequencies of Each Word: 17 austen-persuasion.txt
Average Word Length: 5 Average Sentence Length: 28 Average Frequencies of Each Word: 22 austen-sense.txt
Average Word Length: 4 Average Sentence Length: 34 Average Frequencies of Each Word: 79 bible-kjv.txt
Average Word Length: 5 Average Sentence Length: 19 Average Frequencies of Each Word: 5 blake-poems.txt
Average Word Length: 4 Average Sentence Length: 19 Average Frequencies of Each Word: 14 bryant-stories.txt
Average Word Length: 4 Average Sentence Length: Average Frequency of 18 Words: 12 burgess-busterbrown.txt
Average Word Length: 4 Average Sentence Length: 20 Average Frequencies of Each Word: 13 carroll-alice.txt
Average Word Length: 5 Average Sentence Length: 20 Average Frequencies of Each Word: 12 chesterton-ball.txt
Average Word Length: 5 Average Sentence Length: 23 Average Frequencies of Each Word: 11 chesterton-brown.txt
Average Word Length: 5 Average Sentence Length: 18 Average Frequencies of Each Word: 11 chesterton-thursday.txt
Average Word Length: 4 Average Sentence Length: 21 Average Numbers of Words: 25 Edge worth-parents.txt
Average Word Length: 5 Average Sentence Length: 26 Average Frequencies of Each Word: 15 Meville-moby_dick.txt
Average Word Length: 5 Average Sentence Length: 52 Average Frequencies of Each Word: 11 milton-paradise.txt
Average Word Length: 4 Average Sentence Length: 12 Average Frequencies of Each Word: 9 shakespeare-caesar.txt
Average Word Length: 4 Average Sentence Length: 12 Average Frequencies of Each Word: 8 shakespeare-hamlet.txt
Average Word Length: 4 Average Sentence Length: 12 Average Frequencies of Each Word: 7 shakespeare-macbeth.txt
Average Word Length: 5 Average Sentence Length: 36 Average Frequencies of Each Word: 12 whitman-leaves.txt
>>>
This program displays three statistics for each text: the average word length, the average sentence length and the average number of occurrences of each word in this text (our vocabulary diversity score). See, the average word length seems to be a general attribute of English, because its value is always 4. (In fact, the average word length is 3 instead of 4, because the num_chars variable counts blank characters.) In contrast, the average sentence length and lexical diversity seem to be the author's personal characteristics.
1.2 Network and Chat Text
1.3 Brown Corpus
>>> from nltk.corpus import brown >>> news_text = brown.words(categories='news') >>> fdist = nltk.FreqDist(w.lower() for w in news_text) >>> for k in fdist: ... if k[:2] == "wh": ... print(k + ":",fdist[k], end = " ") ... which: 245 when: 169 who: 268 whether: 18 where: 59 what: 95 while: 55 why: 14 whipped: 2 white: 57 whom: 8 whereby: 3 whole: 11 wherever: 1 whose: 22 wholesale: 1 wheel: 4 whatever: 2 whipple: 1 whitey: 1 whiz: 2 whitfield: 1 whip: 2 whirling: 1 wheeled: 2 whee: 1 wheeler: 2 whisking: 1 wheels: 1 whitney: 1 whopping: 1 wholly-owned: 1 whims: 1 whelan: 1 white-clad: 1 wheat: 1 whites: 2 whiplash: 1 whichever: 1 what's: 1 wholly: 1 >>>
Brownian Corpus looks at the frequency distribution under the conditions of the emergence of news and humor corpus every day of the week:
>>> cfd = nltk.ConditionalFreqDist((genre, word) for genre in brown.categories() for word in brown.words(categories = genre)) >>> genres = ["news", "humor"] # Fill in the categories we want to show >>> day = ["Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday"] # Fill in the words we want to count >>> cfd.tabulate(conditions = genres, samples = day) Monday Tuesday Wednesday Thursday Friday Saturday Sunday news 54 43 22 20 41 33 51 humor 1 0 0 0 0 3 0 >>> cfd.plot(conditions = genres, samples = day)

1.4 Reuters Corpus
1.5 Inaugural Address Corpus
>>> cfd = nltk.ConditionalFreqDist( ... (target, fileid[:4]) ... for fileid in inaugural.fileids() ... for w in inaugural.words(fileid) ... for target in ['america', 'citizen'] ... if w.lower().startswith(target)) [1] >>> cfd.plot()
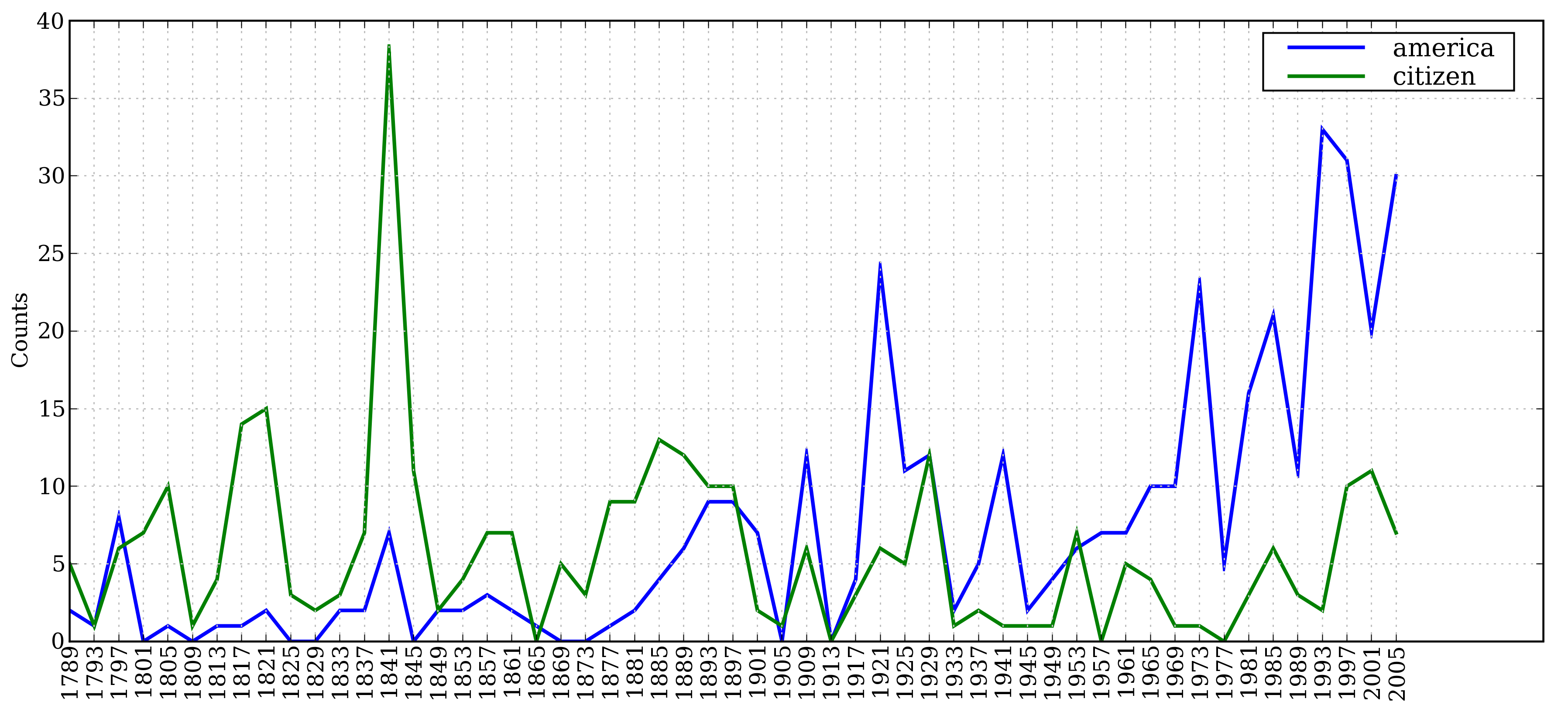 Conditional Frequency Distribution Map: Count all words in the Inaugural Address Corpus that begin with america or citizen.
Conditional Frequency Distribution Map: Count all words in the Inaugural Address Corpus that begin with america or citizen.
1.6 Tagged Text Corpus
1.8 Text Corpus Structure
Common structure of text corpus: the simplest corpus is a collection of isolated texts with no special organization; some corpuses are organized according to classifications such as style (Brown corpus); some classifications overlap, such as topic categories (Reuters corpus); and others can express changes in language usage over time (inaugural speeches). Stock Library).
1.9 Load your own corpus
>>> from nltk.corpus import PlaintextCorpusReader >>> corpus_root = '/usr/share/dict' >>> wordlists = PlaintextCorpusReader(corpus_root, '.*') >>> wordlists.fileids() ['README', 'connectives', 'propernames', 'web2', 'web2a', 'words'] >>> wordlists.words('connectives') ['the', 'of', 'and', 'to', 'a', 'in', 'that', 'is', ...]
2 Conditional Frequency Distribution
2.1 Conditions and Events
Each pair takes the form of: (condition, event). If we deal with the whole Brownian corpus according to style, there will be 15 conditions (one condition per style) and 1,161,192 events (one event per word).
>>> text = ['The', 'Fulton', 'County', 'Grand', 'Jury', 'said', ...] >>> pairs = [('news', 'The'), ('news', 'Fulton'), ('news', 'County'), ...]
2.2 Counting Vocabulary by Style
>>> genre_word = [(genre, word) ... for genre in ['news', 'romance'] ... for word in brown.words(categories=genre)] >>> len(genre_word) 170576 >>> genre_word[:4] [('news', 'The'), ('news', 'Fulton'), ('news', 'County'), ('news', 'Grand')] # [_start-genre] >>> genre_word[-4:] [('romance', 'afraid'), ('romance', 'not'), ('romance', "''"), ('romance', '.')] # [_end-genre]
>>> cfd = nltk.ConditionalFreqDist(genre_word) >>> cfd [1] <ConditionalFreqDist with 2 conditions> >>> cfd.conditions() ['news', 'romance'] # [_conditions-cfd]
>>> print(cfd['news']) <FreqDist with 14394 samples and 100554 outcomes> >>> print(cfd['romance']) <FreqDist with 8452 samples and 70022 outcomes> >>> cfd['romance'].most_common(20) [(',', 3899), ('.', 3736), ('the', 2758), ('and', 1776), ('to', 1502), ('a', 1335), ('of', 1186), ('``', 1045), ("''", 1044), ('was', 993), ('I', 951), ('in', 875), ('he', 702), ('had', 692), ('?', 690), ('her', 651), ('that', 583), ('it', 573), ('his', 559), ('she', 496)] >>> cfd['romance']['could'] 193
2.3 Drawing distribution maps and tables
See: 1.3 Brown Corpus
2.4 Use double conjunctions to generate random text
Using bigrams to make the generating model:
>>> def generate_model(cfdist, word, num = 15): ... for i in range(num): ... print (word,end = " ") ... word = cfdist[word].max() ... >>> text = nltk.corpus.genesis.words("english-kjv.txt") >>> bigrams = nltk.bigrams(text) >>> cfd = nltk.ConditionalFreqDist(bigrams) >>> cfd <ConditionalFreqDist with 2789 conditions> >>> list(cfd) [('they', 'embalmed'), ('embalmed', 'him'), ('him', ','), (',', 'and'), ('and', 'he'), ('he', 'was'), ('was', 'put'), ('put', 'in'), ('in', 'a'), ('a', 'coffin'), ('coffin', 'in'), ('in', 'Egypt'), ('Egypt', '.')] >>> cfd["so"] FreqDist({'that': 8, '.': 7, ',': 4, 'the': 3, 'I': 2, 'doing': 2, 'much': 2, ':': 2, 'did': 1, 'Noah': 1, ...}) >>> cfd["living"] FreqDist({'creature': 7, 'thing': 4, 'substance': 2, 'soul': 1, '.': 1, ',': 1}) >>> generate_model(cfd, "so") so that he said , and the land of the land of the land of >>> generate_model(cfd, "living") living creature that he said , and the land of the land of the land >>>
4 Vocabulary Resources
4.1 Vocabulary List Corpus
The lexical corpus is a / usr/share/dict/words file in Unix, which is used by some spell checkers. We can use it to find unusual or misspelled words in text corpus.
def unusual_words(text): text_vocab = set(w.lower() for w in text if w.isalpha()) english_vocab = set(w.lower() for w in nltk.corpus.words.words()) unusual = text_vocab - english_vocab return sorted(unusual) >>> unusual_words(nltk.corpus.gutenberg.words('austen-sense.txt')) ['abbeyland', 'abhorred', 'abilities', 'abounded', 'abridgement', 'abused', 'abuses', 'accents', 'accepting', 'accommodations', 'accompanied', 'accounted', 'accounts', 'accustomary', 'aches', 'acknowledging', 'acknowledgment', 'acknowledgments', ...] >>> unusual_words(nltk.corpus.nps_chat.words()) ['aaaaaaaaaaaaaaaaa', 'aaahhhh', 'abortions', 'abou', 'abourted', 'abs', 'ack', 'acros', 'actualy', 'adams', 'adds', 'adduser', 'adjusts', 'adoted', 'adreniline', 'ads', 'adults', 'afe', 'affairs', 'affari', 'affects', 'afk', 'agaibn', 'ages', ...]
Discontinued word corpus is high-frequency words such as the, to and also, which we sometimes want to filter from documents before further processing.
>>> from nltk.corpus import stopwords >>> stopwords.words('english') ['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', 'her', 'hers', 'herself', 'it', 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', 'should', 'now']
A spelling puzzle: In a grid of randomly selected letters, select the letters inside to form words; the puzzle is called "goal".
>>> puzzle_letters = nltk.FreqDist('egivrvonl') # Note that if the string'egivrvonl'is used here, the frequency of each letter is given. >>> obligatory = 'r' >>> wordlist = nltk.corpus.words.words() >>> [w for w in wordlist if len(w) >= 6 ... and obligatory in w ... and nltk.FreqDist(w) <= puzzle_letters] ['glover', 'gorlin', 'govern', 'grovel', 'ignore', 'involver', 'lienor', 'linger', 'longer', 'lovering', 'noiler', 'overling', 'region', 'renvoi', 'revolving', 'ringle', 'roving', 'violer', 'virole']
Name corpus, including 8000 names classified by sex. The names of men and women are stored in separate files. Let's find out the names that appear in both documents at the same time, that is, gender ambiguous names:
>>> names = nltk.corpus.names >>> names.fileids() ['female.txt', 'male.txt'] >>> male_names = names.words('male.txt') >>> female_names = names.words('female.txt') >>> [w for w in male_names if w in female_names] ['Abbey', 'Abbie', 'Abby', 'Addie', 'Adrian', 'Adrien', 'Ajay', 'Alex', 'Alexis', 'Alfie', 'Ali', 'Alix', 'Allie', 'Allyn', 'Andie', 'Andrea', 'Andy', 'Angel', 'Angie', 'Ariel', 'Ashley', 'Aubrey', 'Augustine', 'Austin', 'Averil', ...]