RBAC (Role-Based Access Control) means that users are associated with permissions through roles. In short, a user has several roles, and each role has several permissions. In this way, the authorization model of "user role permission" is constructed. In this model, the relationship between users and roles and between roles and permissions is generally many to many.
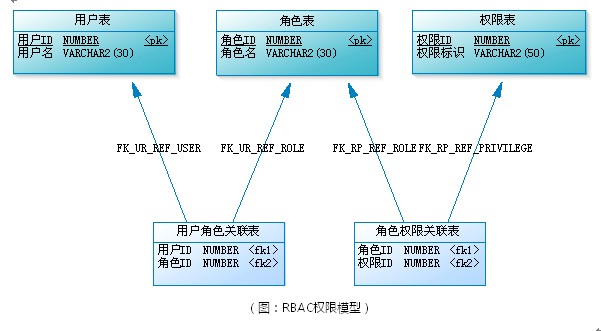
When the number of users is very large, it is very cumbersome to authorize (Grant roles) each user of the system one by one. At this time, users need to be grouped, and there are multiple users in each user group. In addition to authorizing users, you can also authorize user groups. In this way, all permissions owned by the user are the sum of the permissions owned by the user and the permissions owned by the user group in which the user belongs. (the following figure shows the association relationship among user group, user and role)
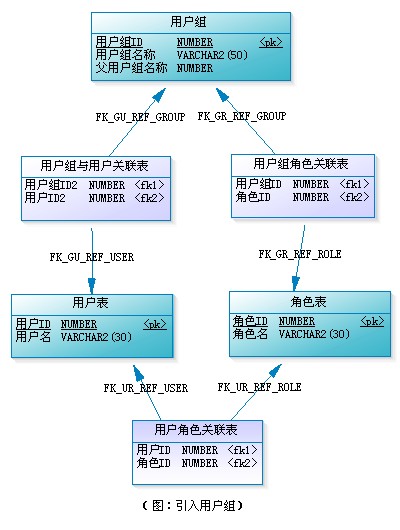
What are permissions represented in an application system? The operation of function modules, the deletion and modification of uploaded files, the access to menus, and even the visibility control of a button and a picture on the page can all belong to the scope of authority. In some permission designs, function operations are regarded as one category, while files, menus, page elements, etc. are regarded as another category, thus forming an authorization model of "user role permission resource". In data table modeling, function operations and resources can be managed uniformly, that is, they can be directly associated with the permission table, which may be more convenient and extensible. (see figure below)
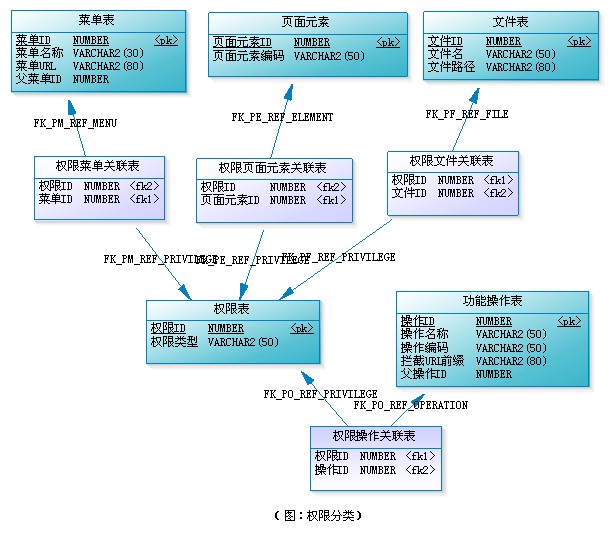
Please note that there is a column "permission type" in the permission table. We can distinguish which kind of permission according to its value, such as "MENU" indicates access permission to the MENU, "OPERATION" indicates OPERATION permission of the function module, "FILE" indicates modification permission of the FILE, "ELEMENT" indicates visibility control of page elements, etc.
This design has two advantages. First, it is not necessary to distinguish which are permission operations and which are resources (in fact, it is sometimes difficult to distinguish, such as menus, which are understood as resources or function module permissions?). Second, it is convenient to expand. When the system wants to control the permission of new things, I only need to create a new association table "permission XX association table" and determine the permission type string of this kind of permission.
Note that permission table and permission menu association table, permission menu association table and menu table are one-to-one relationships. (the same is true for file, page permission point, function operation, etc.). That is, each time you add a menu, you have to insert a record into each of the three tables at the same time. In this way, the permission table can be directly associated with the menu table without the permission menu association table. At this time, a column must be added in the permission table to save the ID of the menu. The permission table can distinguish which record under each type by "permission type" and this ID.
Here, the complete design diagram of the extended model of RBAC permission model is as follows:
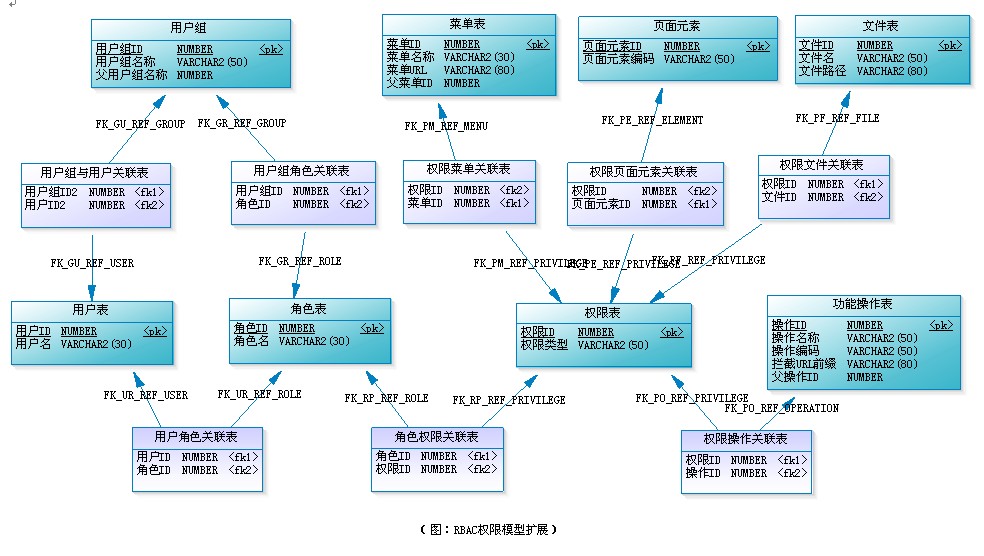
With the increasing size of the system, in order to facilitate management, role groups can be introduced to classify and manage roles. Unlike user groups, role groups do not participate in authorization. For example, in the permission management module of a power grid system, the role is hung under the Regional Bureau, and the regional bureau can be regarded as a role group here, which does not participate in permission allocation. In addition, in order to facilitate the management and search of the above main tables, a tree structure can be adopted, such as menu tree, function tree, etc. of course, these do not need to participate in permission allocation.
The above is extended from the basic RBAC model, and the specific design shall be adjusted according to the needs of the project business.
Is it necessary to design user groups:
Some people think that when designing user groups, you also need to add user groups and add permissions for user groups, which is the same as adding permissions directly to a single user. However, when you need to give permissions to existing users, if you previously used the design model of user groups, you can directly give permissions to user groups, There is no need to grant permissions to each user. Moreover, using user groups is also a structure that reflects the hierarchical relationship of users, so I think it is necessary to use user groups
Roles and permissions are logically tree structures. Adding, deleting, modifying and querying role permissions involves operations on tree data structures. Taking deleting a role as an example, this paper discusses several tree structure operation methods used in the actual development process:
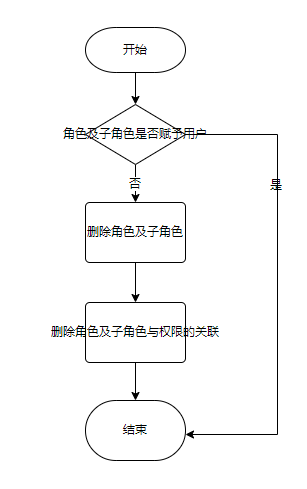
As shown in the figure, deleting a role requires the following steps:
1: Query the role and its sub role list to obtain the role and its sub role id list;
2: Query the user role mapping table according to the role id list found in the first step to determine whether the role and its sub roles are assigned to the user
If yes, it cannot be deleted. Otherwise, proceed to the next step;
3: Delete the role and its child roles;
4: Delete the corresponding data in the role permission table according to the role Id list queried in step 1.
The first step is to query the list of roles and their sub roles in the tree structure. This paper will introduce the following four ways to query the tree structure:
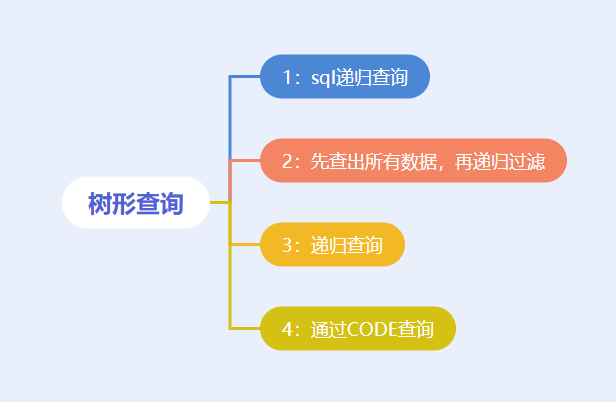
1: SQL recursive query:
For the convenience of subsequent description, the table name is uniformly agreed here: t_org, as defined below:
| field | type | explain |
|---|---|---|
| id | bigint(20) NOT NULL | Organization code |
| parent_id | bigint(20) | Parent organization code |
| desc | varchar(200) | remarks |
Query implementation scheme
The following test data are available in the table
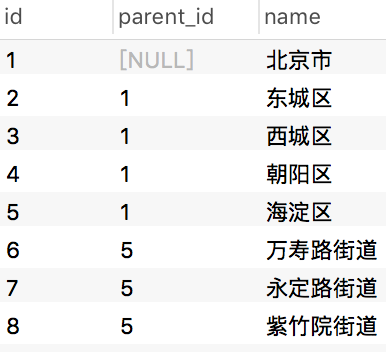
test data
When the number of organizational levels is determined
You can query and obtain results in the way of self association LEFT JOIN.
SELECT t1.id,t1.name,t2.id,t2.parent_id,t2.name,t3.id,t3.parent_id,t3.name FROM t_org t1 LEFT JOIN t_org t2 ON t1.id = t2.parent_id LEFT JOIN t_org t3 ON t2.id = t3.parent_id WHERE t1.id = '1';
The query results are as follows:;
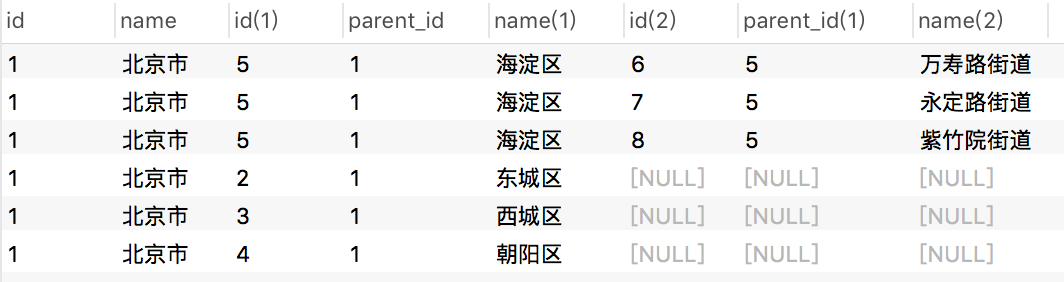
When the organization level is uncertain, the above method cannot be used for query
The query can be realized by user-defined functions
CREATE DEFINER=`root`@`localhost` FUNCTION `findChildren`(rootId INT) RETURNS VARCHAR(4000) CHARSET utf8
BEGIN
DECLARE sTemp VARCHAR(4000);
DECLARE sTempChd VARCHAR(4000);
SET sTemp = '$';
SET sTempChd = CAST(rootId as CHAR);
WHILE sTempChd is not null DO
SET sTemp = CONCAT(sTemp,',',sTempChd);
SELECT GROUP_CONCAT(id) INTO sTempChd FROM t_org
WHERE FIND_IN_SET(parent_id,sTempChd)>0;
END WHILE;
RETURN sTemp;
END;
Two MySQL functions are used in the above functions
GROUP_CONCAT(expr)
This function concatenates all non NULL strings from expr. If there is no non NULL string, it returns NULL. The syntax is as follows:
GROUP_CONCAT([DISTINCT] expr [,expr ...]
[ORDER BY {unsigned_integer | col_name | expr}
[ASC | DESC] [,col_name ...]]
[SEPARATOR str_val])
Note: Group_ The default maximum length of concat query results is 1024, which is the system variable GROUP_CONCAT_ max_ The default value of len can be set through [global | session] group_concat_max_len = val; Change the value.
FIND_IN_SET(str,strlist)
This function returns a value of 1 ~ N, indicating the position of str in strlist.
This function is used in conjunction with WHERE to filter the result set( Find the records contained in the str list result set)
Function usage
SELECT * FROM t_org WHERE FIND_IN_SET(id,findChildren(1)) > 0;
Scheme shortcomings
The length of the returned result is limited by the maximum length of VARCHAR, especially when the organization is large. Next, we can use stored procedures and temporary tables to solve this problem.
Stored procedure + temporary table
The scheme of using stored procedures combined with temporary tables requires the creation of two stored procedures. One is used to recursively query all nodes and write data into the temporary table, and the other is responsible for creating a temporary table and emptying the temporary table data to trigger the query call action.
First, define the first stored procedure as follows:
CREATE DEFINER=`root`@`localhost` PROCEDURE `findOrgChildList`(IN orgId VARCHAR(20))
BEGIN
DECLARE v_org VARCHAR(20) DEFAULT '';
DECLARE done INTEGER DEFAULT 0;
-- Put query results into cursor
DECLARE C_org CURSOR FOR SELECT d.id
FROM t_org d
WHERE d.parent_id = orgId;
DECLARE CONTINUE HANDLER FOR NOT found SET done=1;
SET @@max_sp_recursion_depth = 10;
-- Incoming organization id Write temporary table
INSERT INTO tmp_org VALUES (orgId);
OPEN C_org;
FETCH C_org INTO v_org;
WHILE (done=0)
DO
-- Recursive call to find subordinate
CALL findOrgChildList(v_org);
FETCH C_org INTO v_org;
END WHILE;
CLOSE C_org;
END
As shown above, the logic is relatively simple. Next, define the second stored procedure as follows;
CREATE DEFINER=`root`@`localhost` PROCEDURE `findOrgList`(IN orgId VARCHAR(20))
BEGIN
DROP TEMPORARY TABLE IF EXISTS tmp_org;
-- Create temporary table
CREATE TEMPORARY TABLE tmp_org(org_id VARCHAR(20));
-- Empty temporary table data
DELETE FROM tmp_org;
-- Initiate call
CALL findOrgChildList(orgId);
-- Query results from temporary tables
SELECT org_id FROM tmp_org ORDER BY org_id;
END
Use as follows
CALL findOrgList(org_id);
So far, we can process infinite levels of tree structure data.
MyBatis call stored procedure
In MyBatis, we can call stored procedures in the following ways
<select id="selectOrgChildList" resultType="java.lang.String" statementType="CALLABLE">
<![CDATA[
CALL findOrgList(
#{orgId,mode=IN,jdbcType=VARCHAR},
]]>
</select>
The statementType needs to be specified as CALLABLE, which means that a stored procedure needs to be executed. The default value of statementType is PREPARED.
2: Find out all the data before recursion
public class RoleTreeServiceImpl extends ServiceImpl<RoleTreeMapper,RoleTree>implements RoleTreeService{
@Autowired
private RoleTreeMapper roleTreeMapper;
@Autowired
private UserRoleMapper userRoleMapper;
/**
* Get all categories
* @return
*/
@Override
public List<RoleTree> selectRoleTree() {
List<RoleTree>roleTreeList=roleTreeMapper.selectRoleTree();
List<UserRole>userRoleList=userRoleMapper.selectAll();
//Define a new List
List<RoleTree>treeList=new ArrayList<>();
//Find all primary classifications
for(RoleTree roleTree :roleTreeList){
//Parent of the first level menu_ role_ ID is 0
if(roleTree.getParent_role_id()==0){
treeList.add(roleTree);
}
}
//Set submenu for level 1 menu
for (RoleTree roleTree :treeList){
roleTree.setTrees(getchilde(roleTree.getId(),roleTreeList));
}
return treeList;
}
/**
* Recursive lookup submenu
* @param id Current menu id
* @param rootList List to find
*/
private List<RoleTree>getchilde(Integer id,List<RoleTree>rootList){
//Submenu of submenu
List<RoleTree>childList =new ArrayList<>();
for (RoleTree roleTree :rootList){
//Traverse all nodes and compare the parent menu id with the passed id
if(roleTree.getParent_role_id().equals(id)){
childList.add(roleTree);
}
}
//Loop the submenus of the submenu again
for(RoleTree roleTree :childList){
roleTree.setTrees(getchilde(roleTree.getId(),rootList));
}
//Exit recursion
if (childList.size()==0){
return null;
}
return childList;
}
}3: Recursive query database
private Long @Nullable [] getChildren2(@NotNull Role parentRole) {
var children = this.roleService.list(new QueryWrapper<Role>().eq("parent_id", parentRole.getId()));
if (children.size() > 0) {
children.forEach(role -> {
role.setAuthids(this.getChildren2(role));
});
return children.stream().map(Role::getId).toArray(Long[]::new);
}
return null;
}4: By designing ROLE_CODE implementation
Add role in database_ In the code field, the following rules are defined when adding roles. The code of the root node is A and the code of the child node is A_B. The child node is A_B_C. By analogy, when querying all child nodes of A node, the role of the child node is used_ Does the code value contain the role of the node_ Code value can find out all child nodes of the node.
summary
Method 1 is applicable to the tree structure with fixed node level. If you want to query the tree structure with fixed level, you need to customize the mysql function, which is relatively complex, and Oracle has a related implementation. The implementation of method 2 is relatively simple and widely used. Method 3 is suitable for the case of small amount of data. Method 4 solves this problem from the design, which is intuitive and simple, but additional roles are required when adding new nodes_ Code field, rules need to be defined.