CentOS 7 RPM installs Elasticsearch 7.14.1 and common plug-ins
Installing JDK 1.8
Install jdk:
- Open the official website to download: https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html
- Download the Linux x64 RPM Package: jdk-8u301-linux-x64.rpm
- Input password, 2696671285@qq.com /Oracle123 (if it fails, you can search the Internet for a jdk account)
- rpm installation jdk:
$ rpm -ivh jdk-8u301-linux-x64.rpm $ java -version
Configure environment variables: edit / etc/profile and enter environment variable configuration
export JAVA_HOME=/usr/local/java/jdk8
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
Download Elasticsearch
Visit the official website: https://www.elastic.co/cn/downloads/elasticsearch , view the latest version
$ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.14.1-x86_64.rpm # Note that you cannot install according to the official -- install, otherwise you need to create your own users # Because es cannot be started with root $ sudo rpm -ivh elasticsearch-7.14.1-x86_64.rpm warning: elasticsearch-7.14.1-x86_64.rpm: Header V4 RSA/SHA512 Signature, key ID d88e42b4: NOKEY Preparing... ################################# [100%] Creating elasticsearch group... OK Creating elasticsearch user... OK Updating / installing... 1:elasticsearch-0:7.14.1-1 ################################# [100%] ### NOT starting on installation, please execute the following statements to configure elasticsearch service to start automatically using systemd sudo systemctl daemon-reload sudo systemctl enable elasticsearch.service ### You can start elasticsearch service by executing sudo systemctl start elasticsearch.service Created elasticsearch keystore in /etc/elasticsearch/elasticsearch.keystore
How PS uninstalls rpm package:
$ rpm -qa |grep elasticsearch $ rpm -e elasticsearch-7.14.1-1.x86_64
- Edit the configuration file for elasticsearch
$ vim /etc/elasticsearch/elasticsearch.yml cluster.name: my-application node.name: node-1 path.data: /var/lib/elasticsearch # The data directory needs to be given permission, otherwise an error will be reported path.logs: /var/log/elasticsearch # Permission is required to store the directory, otherwise an error is reported network.host: 0.0.0.0 # Access address cluster.initial_master_nodes: ["node-1"]
- Modify file owner
// The latter two paths are the paths in the above configuration file $ chown elasticsearch:elasticsearch -R /var/lib/elasticsearch $ chown elasticsearch:elasticsearch -R /var/log/elasticsearch
- Set startup
$ systemctl enable elasticsearch
- Start, stop, view status commands
$ systemctl start elasticsearch # start-up $ systemctl stop elasticsearch # stop it $ systemctl status elasticsearch # View status
- Verify (or enter directly in the browser)
$ curl http://127.0.0.1:9200
{
"name" : "node-1",
"cluster_name" : "my-application",
"cluster_uuid" : "z2gcYkX7RDi9ehkMD2cBhA",
"version" : {
"number" : "7.6.2",
"build_flavor" : "default",
"build_type" : "rpm",
"build_hash" : "ef48eb35cf30adf4db14086e8aabd07ef6fb113f",
"build_date" : "2020-03-26T06:34:37.794943Z",
"build_snapshot" : false,
"lucene_version" : "8.4.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
Install Kibana visualization platform
Kibana is an open source analysis and visualization platform designed to work with Elasticsearch.
You use Kibana to search, view, and interact with the data stored in the elastic search index.
You can easily perform advanced data analysis and visualize data in the form of various icons, tables and maps.
Kibana makes it easy to understand large amounts of data. Its simple, browser based interface enables you to quickly create and share dynamic dashboards and display the changes of Elasticsearch queries in real time.
Note: the Kibana version should be the same as the ES version.
- Directly on the es official website, select: https://www.elastic.co/cn/kibana/
- Get the download link, https://www.elastic.co/cn/downloads/kibana
$ wget https://artifacts.elastic.co/downloads/kibana/kibana-7.14.1-x86_64.rpm $ rpm -ivh kibana-7.14.1-x86_64.rpm
- Modify kibana configuration
$ vim /etc/kibana/kibana.yml server.port: 5601 server.host: "0.0.0.0" elasticsearch.hosts: ["http://localhost:9200"] i18n.locale: "zh-CN"
- Power on
$ systemctl enable kibana
- start-up
$ systemctl start kibana $ systemctl stop kibana
Install head
Tip: head is just a front-end application. It can be deployed to different machines with es, but the js file needs to be changed. For simplicity, it is recommended to deploy together.
- Install node.js
$ wget https://nodejs.org/dist/v14.17.6/node-v14.17.6-linux-x64.tar.xz $ tar -xvf node-v14.17.6-linux-x64.tar.xz $ mkdir /usr/local/nodejs $ mv node-v14.17.6-linux-x64/* /usr/local/nodejs $ ln -s /usr/local/nodejs/bin/node /usr/bin # Establish node soft link $ ln -s /usr/local/nodejs/bin/npm /usr/bin # Establish npm soft link $ npm config set registry https://registry.npm.taobao.org # set the domestic Taobao image source $ yarn config set registry https://registry.npmjs.org --global $ node -v $ npm -v
- Install head
$ wget https://github.com/mobz/elasticsearch-head/archive/refs/tags/v5.0.0.tar.gz $ tar -zxvf v5.0.0.tar.gz $ mv elasticsearch-head-5.0.0 /usr/local $ cd /usr/local/elasticsearch-head-5.0.0 $ npm install # Get dependency
... because of the company's network security policy, the pull failed. Instead of trying to install it by yourself, I asked for the first machine for operation and maintenance.
Please visit: https://www.cnblogs.com/asker009/p/10045125.html
Install word splitter
Note: the plug-in download must be consistent with the Es version corresponding to its own version, and the Es needs to be restarted after installing the plug-in to take effect.
- Download and installation of IK word splitter
The introduction of IK word segmentation is not much. In a word, IK word segmentation is a Chinese word segmentation device which is widely used and has good word segmentation effect. For ES development, nine out of ten Chinese word segmentation uses IK word segmentation. Download address: https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.6.1/elasticsearch-analysis-ik-7.6.1.zip
$ wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.14.1/elasticsearch-analysis-ik-7.14.1.zip
- Download and installation of pinyin word splitter
You can enter Pinyin in the search boxes of Taobao and jd.com to find the desired results. This is Pinyin word segmentation. Pinyin word segmentation analyzes Chinese into pinyin format. You can find the desired results through the data analyzed by pinyin word segmentation. Download address: https://github.com/medcl/elasticsearch-analysis-pinyin/releases/download/v7.6.1/elasticsearch-analysis-pinyin-7.6.1.zip
$ wget https://github.com/medcl/elasticsearch-analysis-pinyin/releases/download/v7.14.1/elasticsearch-analysis-pinyin-7.14.1.zip
- Installation: after downloading, directly put it into the plugins directory of elasticsearch directory and unzip it
$ cd /usr/share/elasticsearch/plugins/ $ mkdir ik && cd ik $ mv /tmp/elasticsearch-analysis-ik-7.6.1.zip . $ unzip elasticsearch-analysis-ik-7.6.1.zip $ mkdir pinyin && cd pinyin $ mv /tmp/elasticsearch-analysis-pinyin-7.14.1.zip . $ unzip elasticsearch-analysis-pinyin-7.14.1.zip $ chown elasticsearch:elasticsearch -R /usr/share/elasticsearch/plugins # Don't forget $ systemctl restart elasticsearch # Restart es
Test the IK word splitter with Kibana, no problem
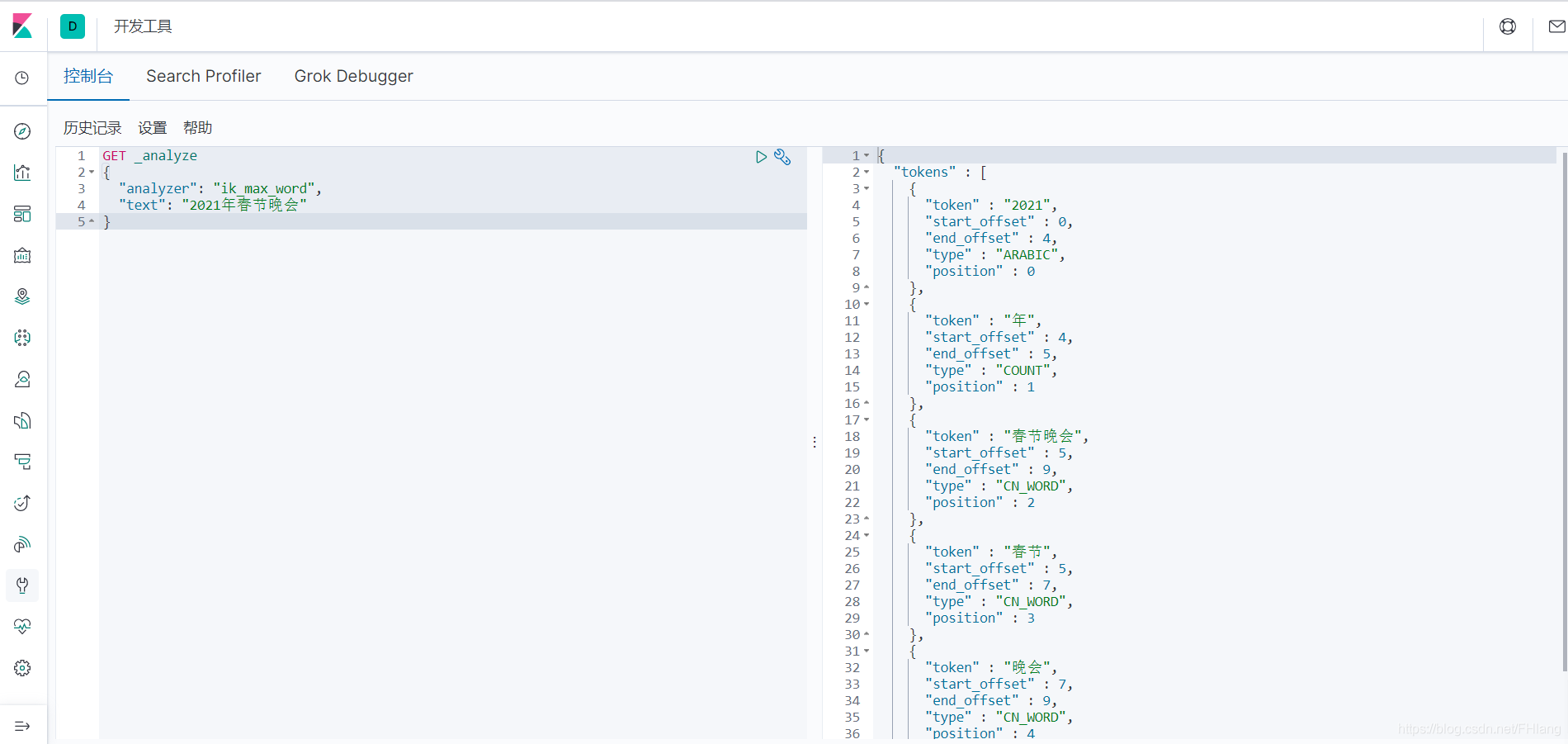
use
Please read:
reference resources:
- [elasticsearch] install elasticsearch 7.6.2 and kibana 7.6.2 under CentOS 7 (rpm mode)
- Introduction to Elasticsearch (I): CentOS 7.6 installation ES 7.6.1
- Introduction to Elasticsearch (II): Elasticsearch 7.6.1 installing word splitter and Kibana
- Introduction to Elasticsearch (III): Elasticsearch 7.6.1 installation of head and node.js
- CentOS7 NodeJS installation detailed tutorial (with installation steps)
- Elasticsearch plug-ins head and kibana