The overall content of the Android Handler mechanism series is as follows:
- Thread of Android Handler Mechanism 1
- ThreadLocal of Android Handler Mechanism 2
- SystemClock Class of Android Handler Mechanism 3
- Introduction to Looper and Handler of Android Handler Mechanism 4
- Message Profile and Message Object Pool of Android Handler Mechanism 5
- MessageQueue Introduction to Android Handler Mechanism 6
- Message Sending in Android Handler Mechanism 7
- Message extraction and other operations of Android Handler mechanism 8
- Preliminary Linux IO Multiplexing by Handler's Native of Android Handler Mechanism 9
- Implementation of Native by Native in Handdler of Android Handler Mechanism 10
- Summary of Handler Mechanism of Android Handler Mechanism 11
- Callable, Future and FutureTask of Android Handler Mechanism 12
- AsyncTask Source Parsing of Android Handler Mechanism 13
The main contents of this article are as follows:
- 1. Overview
- 2,Callable
- 3,Future
- 4,FutureTask
- 5, summary
I. overview
- Java can easily write multi-threaded applications from a released version and introduce asynchronous processing in its design. There are two ways to create threads, one is to inherit Thread directly, the other is to implement the Runnable interface. Thread class, Runnable interface and Java memory management model make multithreaded programming simple and direct. But you know that neither Thread nor Runnable interfaces allow you to declare checking exceptions, nor can you define return values back. It's a bit cumbersome to have no return value.
- Failure to declare throwing a checked exception is more cumbersome. The public void run() method contract means that you must catch and handle checked exceptions. Even if you carefully save exception information (when capturing an exception) for later inspection, there is no guarantee that all users of this class (Runnnable) will read the exception information. You can also modify the getter implemented by Runnable so that they can throw exceptions in task execution. But this method is not very safe and reliable besides tedious. You can't force users to call these methods. Programmers will probably call join() method and wait for the thread to finish.
- But don't worry now, the above problems are finally solved in 1.5. The introduction of Callable and Future interfaces and their support for thread pools gracefully solve these two problems.
Callable
(i) Runnable
When it comes to Callable, you can't ignore java.lang.Runnable, which is an interface. It only declares a run() method. Since the return value of the run() method is void, it can't return any results after the task is completed.
public interface Runnable { /** * When an object implementing interface <code>Runnable</code> is used * to create a thread, starting the thread causes the object's * <code>run</code> method to be called in that separately executing * thread. * <p> * The general contract of the method <code>run</code> is that it may * take any action whatsoever. * * @see java.lang.Thread#run() */ public abstract void run(); }
(ii) Callable
Callable is located under the java.util.concurrent package. It is also an interface, in which only one method is declared, but this method is called call().
/** * A task that returns a result and may throw an exception. * Implementors define a single method with no arguments called * {@code call}. * * <p>The {@code Callable} interface is similar to {@link * java.lang.Runnable}, in that both are designed for classes whose * instances are potentially executed by another thread. A * {@code Runnable}, however, does not return a result and cannot * throw a checked exception. * * <p>The {@link Executors} class contains utility methods to * convert from other common forms to {@code Callable} classes. * * @see Executor * @since 1.5 * @author Doug Lea * @param <V> the result type of method {@code call} */ @FunctionalInterface public interface Callable<V> { /** * Computes a result, or throws an exception if unable to do so. * * @return computed result * @throws Exception if unable to compute a result */ // V call() throws Exception; }
As you can see, in this generic interface, the type returned by the call() function is the type of V passed in.
(3) Class annotations for Callable
In order to better understand Callable, we should start with class annotations, which are translated as follows:
- Tasks that have execution results and can cause exceptions
Its implementation class needs to implement the call() method, which has no parameters. - Callable is somewhat similar to the Runnable interface because they are instances of executable code designed to be executed by threads. Because Runnable has no return value and cannot throw a checked exception.
- The Executors class contains methods that enable Callable to be converted to other common forms.
(4) The difference between Runnable and Callable:
- 1. Runnable is available in Java 1.1, while Callable is added after 1.5.
- 2. Callable specifies call(), Runnable specifies run()
- 3. Callable's task can return a value after execution, while Runnable's task can't return (because it's void)
- 4. The call() method can throw an exception, but the run() method can't.
- 5. Running Callable task can get a Future object, which represents the result of asynchronous calculation. It provides a method to check whether the calculation is completed or not, to wait for the completion of the calculation, and to retrieve the results of the calculation. Through the Future object, we can know the execution of the task, cancel the execution of the task, and obtain the execution results.
- 6. Join the thread pool to run. Runnable uses ExecutorService's execute() method and Callable uses submit() method.
Three, Future
(1) Future Class Explanation
Future is to cancel the execution result of a specific Runnable or Callable task, query whether it is completed, and obtain the result. If necessary, the result of execution can be obtained by get method, which will block the result of knowing the task return. The Future class is located under the java.util.concurrent package and is an interface:
public interface Future<V> { boolean cancel(boolean mayInterruptIfRunning); boolean isCancelled(); boolean isDone(); V get() throws InterruptedException, ExecutionException; V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException; }
Five methods are declared in the Future interface. The following are the roles of each method in turn:
- Boolean cancel (boolean mayInterruptIf Running): Method is used to cancel a task, return true if the cancel task succeeds, and false if the cancel task fails. The parameter mayInterruptIfRunning indicates whether it is allowed to cancel tasks that are being executed but not completed, and if set to true, it means that tasks in the execution process can be cancelled. If the task has been completed, whether the mayInterruptIfRunning is true or false, this method will definitely return false, that is, if the completed task is cancelled, false will be returned; if the task is executing, if the mayInterruptIfRunning is set to true, true will be returned; if the mayInterruptIfRunning is set to false, false will be returned; if the task has not been executed, whether the InterruptIfRunning is false or not. If Running is true or false, it must return true.
- boolean isCancelled(): Indicates whether the task has been cancelled successfully, and returns true if it has been cancelled before the task completes normally.
- isDone(): The method indicates whether the task has been completed or not, and returns true if the task has been completed.
- V get(): The method is used to get the execution result. This method will block and will not return until the task has been executed.
- V get(long timeout, TimeUnit unit): Used to get execution results, if the results have not been obtained within a specified time, return null directly.
To sum up, Future provides three functions:
- Judge whether the task is completed or not
- Able to interrupt tasks
- Capable of obtaining task execution results
(2) Future class annotations
- Future It can represent the result of asynchronous computation. Future Provide a method to check whether the calculation has been completed, and a method to retrieve the results. get()The method can obtain the result of calculation, which may cause blockage. If blockage occurs, it will block until the end of calculation. cancel()Method can cancel execution. There are also ways to determine whether a task has been completed or cancelled successfully. If the task has been completed, it can not be cancelled. If you want to use it Future And, hopefully, it's irrevocable and not concerned about the results of implementation, you can declare that Future The generic type of the underlying task, and the return value of the underlying task is null.
- Use example
class App { ExecutorService executor = ... ArchiveSearcher searcher = ... void showSearch(final String target) throws InterruptedException { Future<String> future = executor.submit(new Callable<String>() { public String call() { return searcher.search(target); } }); displayOtherThings(); // do other things while searching try { displayText(future.get()); // use future } catch (ExecutionException ex) { cleanup(); return; } } }
FutureTask is the specific implementation class of Future, and also implements Runnable. So FutureTask can be executed by Executor. For example, Executor's submit method can be replaced by the following
FutureTask<String> future = new FutureTask<>(new Callable<String>() { public String call() { return searcher.search(target); }}); executor.execute(future);
Memory consistency effect: If you want to call the Future.get() method on another thread, you should perform its own operations before calling the method.
(3) Boolean cancel (boolean mayInterrupt If Running) method annotation
Translated as follows:
An attempt to close an ongoing task fails if the task has been completed, or the task has been cancelled, or the task cannot be cancelled for some reason. When the task has not been executed, the call to this method will succeed, and the task will not be executed in the future. If the task has already started, mayInterruptIf Running decides whether the task should be interrupted. When this method is executed and returned, it calls the isDone() method and returns true all the time. If the isCancelled() method returns true after calling this method and then isCancelled() method, the isCancelled() method always returns true. The parameter mayInterruptIfRunning denotes whether the thread of the task can be interrupted, and true denotes that it can be interrupted. If the task cannot be cancelled, it returns false, and in most cases the task has been completed.
As mentioned above, Future is only an interface, so it can't be used directly to create objects. FutureTask is recommended in the comments, so let's take a look at FutureTask.
IV. FutureTask
FutureTask.java source address
Let's first look at FutureTask's implementation:
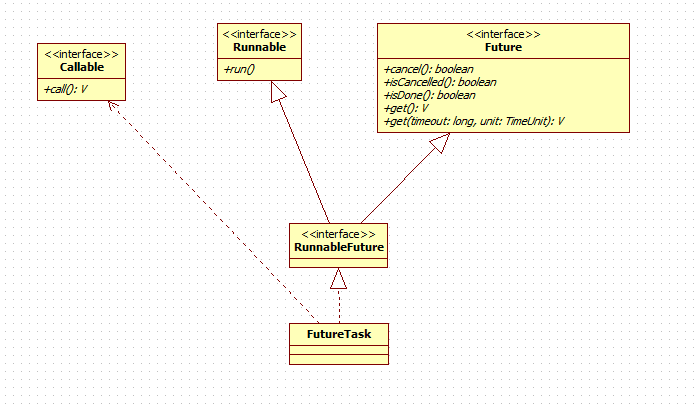
(1) Runnable Future
We know by code
public class FutureTask<V> implements RunnableFuture<V>
Explain that the FutureTask class implements the RunnableFuture interface. Let's take a look at the RunnableFuture interface.
RunnableFuture.java source address
/** * A {@link Future} that is {@link Runnable}. Successful execution of * the {@code run} method causes completion of the {@code Future} * and allows access to its results. * @see FutureTask * @see Executor * @since 1.6 * @author Doug Lea * @param <V> The result type returned by this Future's {@code get} method */ public interface RunnableFuture<V> extends Runnable, Future<V> { /** * Sets this Future to the result of its computation * unless it has been cancelled. */ void run(); }
I know from the code that Runnable Future inherits Runnable interface and Future interface, and FutureTask implements Runnable Future interface. So it can be executed by threads as Runnable, or it can be used as Future to get the return value of Callable.
(2) Class annotations of FutureTask
/**
* A cancellable asynchronous computation. This class provides a base
* implementation of {@link Future}, with methods to start and cancel
* a computation, query to see if the computation is complete, and
* retrieve the result of the computation. The result can only be
* retrieved when the computation has completed; the {@code get}
* methods will block if the computation has not yet completed. Once
* the computation has completed, the computation cannot be restarted
* or cancelled (unless the computation is invoked using
* {@link #runAndReset}).
*
* <p>A {@code FutureTask} can be used to wrap a {@link Callable} or
* {@link Runnable} object. Because {@code FutureTask} implements
* {@code Runnable}, a {@code FutureTask} can be submitted to an
* {@link Executor} for execution.
*
* <p>In addition to serving as a standalone class, this class provides
* {@code protected} functionality that may be useful when creating
* customized task classes.
*
* @since 1.5
* @author Doug Lea
* @param <V> The result type returned by this FutureTask's {@code get} methods
*/
In order to better understand the author's design, first look at class annotations, translated as follows:
- A cancelable asynchronous execution class, which is the basic implementation class of Future, provides some methods, such as opening and closing execution, querying whether the execution has been completed, and retrieving the results of calculation. This execution result can only be obtained when the execution is completed, and is blocked if it has not been completed. Unless the runAndReset() method is called, the boot or cancellation cannot be restarted once the calculation is completed.
- Callable or Runnable can pack FutureTask, which can be executed in Executor because FutureTask implements Runnable.
- In addition to being a separate class, FutureTask also provides some protected methods, which make it easy to customize task classes.
(3) Structure of FutureTask
The structure is as follows
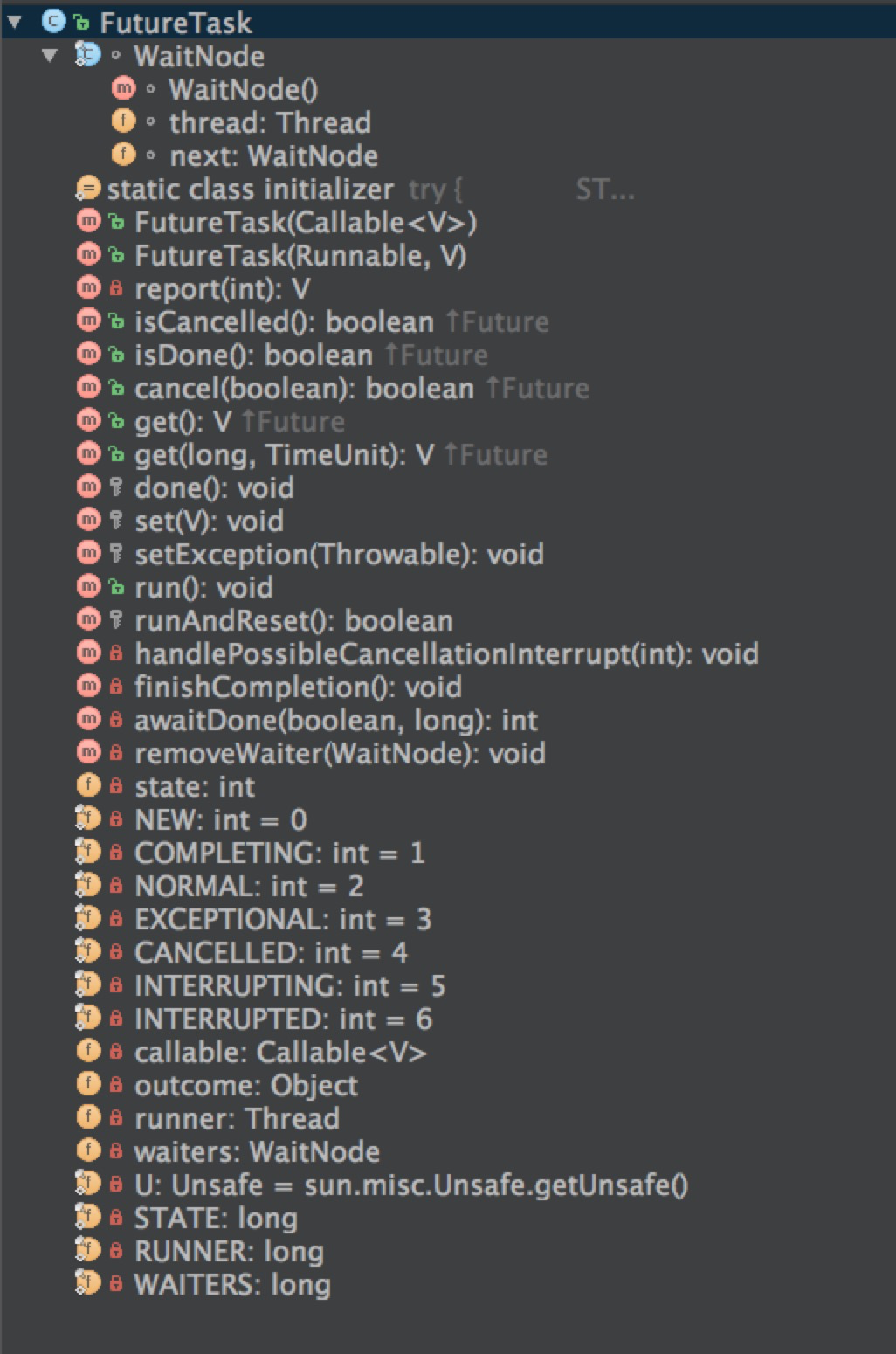
The relationship of succession is as follows:
(4) Static final class WaitNode
/** * Simple linked list nodes to record waiting threads in a Treiber * stack. See other classes such as Phaser and SynchronousQueue * for more detailed explanation. */ static final class WaitNode { volatile Thread thread; volatile WaitNode next; WaitNode() { thread = Thread.currentThread(); } }
First translate the notes.
A streamlined version of the linked list structure in which each node represents the thread waiting on the stack. For more details, please refer to other classes such as Phaser and SynchronousQueue.
The structure is as follows
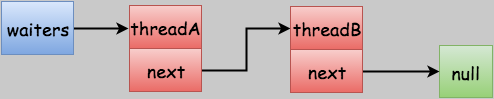
Let's look at constructors and member variables
- Thread: Represents a waiting thread
- Next: Represents the next node through which we can exit the list as a one-way list
- Constructor: In an argument-free constructor, threads are set to the current thread.
Conclusion:
WaitNode is a linked list structure that records threads waiting for the current FutureTask result.
(5) Status of FutureTask
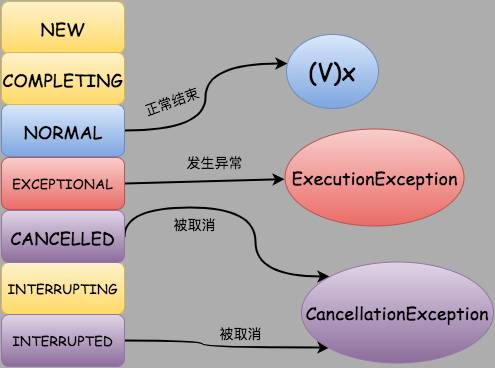
FutureTask has seven states, coded as follows:
/* * Revision notes: This differs from previous versions of this * class that relied on AbstractQueuedSynchronizer, mainly to * avoid surprising users about retaining interrupt status during * cancellation races. Sync control in the current design relies * on a "state" field updated via CAS to track completion, along * with a simple Treiber stack to hold waiting threads. * * Style note: As usual, we bypass overhead of using * AtomicXFieldUpdaters and instead directly use Unsafe intrinsics. */ /** * The run state of this task, initially NEW. The run state * transitions to a terminal state only in methods set, * setException, and cancel. During completion, state may take on * transient values of COMPLETING (while outcome is being set) or * INTERRUPTING (only while interrupting the runner to satisfy a * cancel(true)). Transitions from these intermediate to final * states use cheaper ordered/lazy writes because values are unique * and cannot be further modified. * * Possible state transitions: * NEW -> COMPLETING -> NORMAL * NEW -> COMPLETING -> EXCEPTIONAL * NEW -> CANCELLED * NEW -> INTERRUPTING -> INTERRUPTED */ private volatile int state; private static final int NEW = 0; private static final int COMPLETING = 1; private static final int NORMAL = 2; private static final int EXCEPTIONAL = 3; private static final int CANCELLED = 4; private static final int INTERRUPTING = 5; private static final int INTERRUPTED = 6;
The old rule first translates the annotations. We can see that there are two parts of the annotations. We translate them in turn as follows:
- Notes in the first half:
Revision Note: Unlike previous versions of Abstract Queued Synchronizer, the main reason is to avoid surprising users retaining interruptions in canceling competition for relocation. In the current design, synchronization control is achieved through the update field of CAS - "state". And these waiting threads are saved through a Treiber stack. Style Notes: As usual, we use insecure intrinsic functions directly and ignore the overhead of using Atomic XField Updaters.
Simply put, FutureTask uses state to represent task status, and state changes are guaranteed atomicity by CAS operations.
- Notes for the second half:
The running state of this task is initially NEW state. After calling the set() method or the setException() method or cancel() method, the running state becomes the state of the terminal. During runtime, if the state changes to COMPLETING after calculating the result, and if cancel(true) is called to interrupt the operation safely, the state changes to INTERRUPTING. Since the value is unique and cannot be further modified, the transition from intermediate state to final state is orderly. - Possible state change process
- NEW -> COMPLETING -> NORMAL
- NEW -> COMPLETING -> EXCEPTIONAL
- NEW -> CANCELLED
- NEW -> INTERRUPTING -> INTERRUPTED
I don't feel very good about the translation. Explain it in vernacular.
When the FutureTask object is initialized, the state is set to NEW in the constructor, and then the state changes are determined according to the specific implementation.
- Task execution is normal and not finished. state is COMPLETING, which means the task is about to be completed. Next, it will be set to NORMAL or EXCEPTIONAL soon. This depends on whether the call() method in Runnable is called to throw an exception or NORMAL if there is no exception. The throwing exception is EXCEPTIONAL.
- Cancellation of tasks after submission or before completion may become CANCELLED or INTERRUPTED. When cancel(boolean) is called, state becomes CANCELLED if a false is passed in to indicate that the thread is uninterrupted, and if true is passed in, state first becomes CANCELLED.
INTERRUPTING, when the interruption is completed, becomes INTERRUPTED.
To sum up, the state change process of FutureTask is as follows:
- Task normal execution and return: NEW - > COMPLETING - > NORMAL
- Exceptions in task execution: NEW - > COMPLETING - > EXCEPTIONAL
- Task execution is cancelled without interrupting threads: NEW - > CANCELLED
- Task execution is cancelled and threads are interrupted: NEW - > INTERRUPTING - > INTERRUPTED
So let's simply explain a few states.
- NEW: Task initialization status
- COMPLETING: The task is in its completion state (the task has been completed, but the result has not been assigned to the outcome)
- NORMAL: Task completion (results have been assigned to results)
- EXCEPTIONAL: Task execution exception
- CANCELLED: Mission cancelled
- INTERRUPTING: Tasks are interrupted
- INTERRUPTED: Tasks interrupted
(6) Member variables of FutureTask
/** The underlying callable; nulled out after running */ private Callable<V> callable; /** The result to return or exception to throw from get() */ private Object outcome; // non-volatile, protected by state reads/writes /** The thread running the callable; CASed during run() */ private volatile Thread runner; /** Treiber stack of waiting threads */ private volatile WaitNode waiters;
- callable: Task specific executor, specific things to do
- outcome: the execution result of a task, the return value of the get() method
- runner: Thread of Task Execution
- waiters: Waiting threads for task results (a chain list)
(7) The Constructive Function of FutureTask
FutureTask has two constructors
They are FutureTask (Callable < V > Callable) and FutureTask(Runnable runnable, V result), so let's analyze them in turn.
1. Constructor FutureTask (Callable < V > Callable)
/** * Creates a {@code FutureTask} that will, upon running, execute the * given {@code Callable}. * * @param callable the callable task * @throws NullPointerException if the callable is null */ public FutureTask(Callable<V> callable) { if (callable == null) throw new NullPointerException(); this.callable = callable; this.state = NEW; // ensure visibility of callable }
The old rule first translates the notes:
Create a FutureTask and run the incoming Callable when it executes in the future.
Looking at the code, we know:
- 1. Through the code, we know that if the incoming Callable is empty and throws an exception directly, it means that the incoming Callable cannot be empty at the time of construction.
- 2. Set the current state to NEW.
So to sum up, construct a FutureTask by passing in Callable.
2. Constructor FutureTask(Runnable runnable, V result)
/** * Creates a {@code FutureTask} that will, upon running, execute the * given {@code Runnable}, and arrange that {@code get} will return the * given result on successful completion. * * @param runnable the runnable task * @param result the result to return on successful completion. If * you don't need a particular result, consider using * constructions of the form: * {@code Future<?> f = new FutureTask<Void>(runnable, null)} * @throws NullPointerException if the runnable is null */ public FutureTask(Runnable runnable, V result) { this.callable = Executors.callable(runnable, result); this.state = NEW; // ensure visibility of callable }
The old rule first translates the notes:
Create a FutureTask and run the incoming Runnable when it is executed in the future, and return the result after successful completion to the incoming result.
Looking at the code, we know:
- 1. Callable returned by calling the callable(Runnable, T) method of Executors
- 2. Point the Callable returned above to the local variable callable
- 3. Set the current state to NEW.
So to conclude, construct a task by passing in Runnable
Incidentally, here's the internal implementation of Executors.callable(runnable, result) method
2.1,Executors.callable(Runnable, T)
/** * Returns a {@link Callable} object that, when * called, runs the given task and returns the given result. This * can be useful when applying methods requiring a * {@code Callable} to an otherwise resultless action. * @param task the task to run * @param result the result to return * @param <T> the type of the result * @return a callable object * @throws NullPointerException if task null */ public static <T> Callable<T> callable(Runnable task, T result) { if (task == null) throw new NullPointerException(); return new RunnableAdapter<T>(task, result); }
The inside of the method is very simple. It's a new Runnable Adapter and returns. Let's take a look at the Runnable Adapter adapter.
/** * A callable that runs given task and returns given result. */ private static final class RunnableAdapter<T> implements Callable<T> { private final Runnable task; private final T result; RunnableAdapter(Runnable task, T result) { this.task = task; this.result = result; } public T call() { task.run(); return result; } }
From the above code, we know that:
- Runnable Adapter is a static internal class of FutureTask and implements Callable, that is to say, Runnable Adapter is a subclass of Callable.
- The call method implementation code is to execute the run method of Runnable and return the result parameter passed in by the constructor.
This is actually a Runnable object disguised as a Callable object, which is an adapter object.
3. Summary of constructors
By analyzing the above two constructors, we know that whether we use the first constructor or the second constructor, the result is to initialize and assign the local variable callable, so FutureTask ultimately performs Callable-type tasks. Then set the state to NEW.
(8) Several Core Methods of FutureTask
FutureTask has several core approaches:
- public void run(): indicates the execution of a task
- public V get() and public V get(long timeout, TimeUnit unit): Indicate the result of the acquisition task
- Public Boolean cancel (boolean mayInterrupt If Running): denotes cancellation of tasks
Let's look at it in turn.
1. run() method
/** * Determine whether the state of the task is initialized? * Determine whether the thread object runner that executes the task is null or not, assign the current thread of execution to the runner attribute if it is empty * Instead of empty instructions, there should be threads ready to perform this task */ public void run() { if (state != NEW || !U.compareAndSwapObject(this, RUNNER, null, Thread.currentThread())) return; try { // When the task state is NEW and the callable is not empty, the task is executed // If you think it's cancel ed, callable will be emptied Callable<V> c = callable; if (c != null && state == NEW) { V result; // Variables of outcomes boolean ran; // Executed variables try { // Execute tasks and return results result = c.call(); ran = true; } catch (Throwable ex) { // Execution exception result = null; ran = false; setException(ex); } if (ran) //Set the results when the task is finished set(result); } } finally { // runner must be non-null until state is settled to // prevent concurrent calls to run() // Clear the execution thread of the task runner = null; // state must be re-read after nulling runner to prevent // leaked interrupts int s = state; if (s >= INTERRUPTING) //Judging the state of threads handlePossibleCancellationInterrupt(s); } }
From the above code and comments, we know that the flow inside the run method is as follows:
- Step 1: Check whether the current task is NEW and whether the runner is empty. This step is to prevent the task from being cancelled.
- Step 2: double-check task status and state
- Step 3: Execute business logic, that is, the c.call() method is executed
- Step 4: If the business logic is abnormal, call setException method to assign the exception object to result and update the value of state
- Step 5: If the business is normal, call the set method to assign the execution result to the result and update the state value.
1.1. Unsafe class
Java does not have direct access to the underlying operating system, but through local methods. Unsafe provides hardware-level atomic access, mainly providing the following functions:
- Allocate Released Memory
- Locate the memory location of a field
- Hang up a thread and restore, more through LockSupport access. park and unpark
- The CAS operation compares the memory value of an object at a certain location with the expected value.
The main method is compare AndSwap ()
1.1.1 UNSAFE. comparison AndSwapObject (this, runner Offset, null, Thread. current Thread ()) method
What does the line UNSAFE. compare AndSwapObject (this, RUNNER, null, Thread. current Thread ()) mean?
CompeAndSwapObject can modify the object by reflection according to the offset. The first parameter represents the object to be modified, the second represents the offset, the third parameter is used to compare the value corresponding to the offset, and the fourth parameter represents how to set the offset to the same value as the third parameter.
Translation into vernacular is:
If the RUNNER offset address of this object is null, set it to Thread. current Thread ().
The concept mentioned above is RUNNER. What is this RUNNER?
We found it in the source code
// Unsafe mechanics private static final sun.misc.Unsafe U = sun.misc.Unsafe.getUnsafe(); private static final long STATE; private static final long RUNNER; private static final long WAITERS; static { try { STATE = U.objectFieldOffset (FutureTask.class.getDeclaredField("state")); RUNNER = U.objectFieldOffset (FutureTask.class.getDeclaredField("runner")); WAITERS = U.objectFieldOffset (FutureTask.class.getDeclaredField("waiters")); } catch (ReflectiveOperationException e) { throw new Error(e); } // Reduce the risk of rare disastrous classloading in first call to // LockSupport.park: https://bugs.openjdk.java.net/browse/JDK-8074773 Class<?> ensureLoaded = LockSupport.class; }
It corresponds to the member variables of runner, that is, if the state is not NEW or runner is not null, the run method returns directly.
So we know
- private static final long STATE: Represents the member variable state
- private static final long RUNNER: Represents the member variable runner
- rivate static final long WAITERS: Represents the member variable waiters
In this run method, setException(Throwable) and set(V) methods are invoked, so let's look at them in detail.
1.2. SetException (Throwable) Method
/** * Causes this future to report an {@link ExecutionException} * with the given throwable as its cause, unless this future has * already been set or has been cancelled. * * <p>This method is invoked internally by the {@link #run} method * upon failure of the computation. * * @param t the cause of failure */ protected void setException(Throwable t) { // State state NEW - > COMPLETING if (U.compareAndSwapInt(this, STATE, NEW, COMPLETING)) { outcome = t; // // COMPLETING - > EXCEPTIONAL reaches stable state U.putOrderedInt(this, STATE, EXCEPTIONAL); // final state // Some closures finishCompletion(); } }
Simply translate the notes of the method:
- Unless the Future is set or cancelled, the exception will be reported to Execution Exception.
- If an exception occurs in the run() method, the method is called
So to sum up, when there are exceptions in the process of task execution, how to deal with exceptions
PS: This method is protected, so it can be rewritten.
1.3. set (V) method
The main method is to perform the assignment operation of the result.
/** * Sets the result of this future to the given value unless * this future has already been set or has been cancelled. * * <p>This method is invoked internally by the {@link #run} method * upon successful completion of the computation. * * @param v the value */ protected void set(V v) { // State state NEW - > COMPLETING if (U.compareAndSwapInt(this, STATE, NEW, COMPLETING)) { outcome = v; // COMPLETING - > NORMAL reaches stable state U.putOrderedInt(this, STATE, NORMAL); // final state // Some closures finishCompletion(); } }
From the above we know that the internal process of this method is as follows:
- First change the state of the task
- Second, assign the results
- Change the task status again
- Finally, the queue of waiting threads is processed (changing the thread blocking state to wake up, so that the waiting threads get the result)
PS: The putOrderedInt method of UNSAFE is used here, which is actually the method used inside the LazySet of atomic weight. Why use this method? First, LazySet is cheaper than Volatile-Write because it does not have an expensive Store/Load barrier. Second, subsequent threads will not see the state change from COMPLETING to NORMAL in time, but that doesn't matter, and NORMAL is the final state of state and will not change any more.
The finishCompletion() method is called in this method, so let's take a look at this method.
1.4. finishCompletion() Method
This method is:
At the completion of task execution (including cancellation, normal termination, abnormal occurrence), the thread queue is awaited while the task executor is emptied.
The code is as follows:
/** * Removes and signals all waiting threads, invokes done(), and * nulls out callable. */ private void finishCompletion() { // assert state > COMPLETING; // Traversing Waiting Nodes for (WaitNode q; (q = waiters) != null;) { if (U.compareAndSwapObject(this, WAITERS, q, null)) { for (;;) { Thread t = q.thread; if (t != null) { q.thread = null; // Wake up waiting threads LockSupport.unpark(t); } WaitNode next = q.next; if (next == null) break; q.next = null; // unlink to help gc q = next; } break; } } // Here you can customize what you want to do when the implementation task is completed (override the done() method in the subclass) done(); // Clear callable callable = null; // to reduce footprint }
As can be seen from the code and annotations, here is to traverse the WaitNode list, to each WaitNode corresponding thread in turn LockSupport.unpark(t) to end the blocking. When the WaitNode notification is complete, the do method is called. At present, this method is implemented empty, so if you want to execute some business logic after the task is completed, you can rewrite this method. So the main way to do this is to wake up the waiting threads. As you know, when the task ends normally or abnormally, finishCompletion() is called to wake up the waiting thread. Waiting for threads to wake up and get results.
·
1.4.1, Introduction to LockSupport
First of all, I will talk about LockSupport. Many novices are not very familiar with this thing. Let me talk about it briefly, but I will not elaborate on it here.
LockSupport is one of the foundations for building concurrent packages
Operating Object of \\\\\\\\\\\
LockSupport calls Unsafe's natvie code:
public native void unpark(Thread jthread); public native void park(boolean isAbsolute, long time);
These two function declarations clearly state the object of operation: the park function blocks the current Thread, while the unPark function wakes up another Thread.
Compared with wait/notify mechanism of Object class, park/unpark has two advantages:
- 1. Using threads as operating objects is more in line with the intuitive definition of blocking threads.
- 2. The operation is more precise and can wake up a thread accurately (notify wakes up a thread randomly, notify All wakes up all waiting threads), which increases flexibility.
#\\\\\\\\\\\\
In the above file, blocking and wake-up are used to compare with wait/notify. In fact, the core design principle of park/unpark is "license". Park is waiting for a license. Unpark provides a "license" for a thread. If a thread A calls park, thread A will block the park operation unless another thread unpark(A) gives A a license.
1.5. HandlePossibleCancellation Interrupt (int) method
/** * Ensures that any interrupt from a possible cancel(true) is only * delivered to a task while in run or runAndReset. */ private void handlePossibleCancellationInterrupt(int s) { // It is possible for our interrupter to stall before getting a // chance to interrupt us. Let's spin-wait patiently. // If the interrupt is currently in progress, wait for the interrupt to complete if (s == INTERRUPTING) while (state == INTERRUPTING) Thread.yield(); // wait out pending interrupt // assert state == INTERRUPTED; // We want to clear any interrupt we may have received from // cancel(true). However, it is permissible to use interrupts // as an independent mechanism for a task to communicate with // its caller, and there is no way to clear only the // cancellation interrupt. // // Thread.interrupted(); }
Let's start with the notes:
Perform the calculation without setting the result, and then reset the future to the initialization state. If the execution encounters an exception or the task is cancelled, the operation is no longer performed. The purpose of this design is to perform multiple tasks.
Looking at the code, we know that his main idea is that if other threads are terminating the task, the threads running the task temporarily give up CPU time until state= INTERRUPTED.
So its function is to uuuuuuuuuuuu
Ensure that the interruption generated by cancel(true) occurs during the run() or runAndReset() method process
2. get() and get(long, TimeUnit) methods
Tasks are executed by threads provided by the thread pool, and then the main thread blocks until the task thread wakes them up. Let's see what get() does.
2.1 get() method
The code is as follows:
/** * @throws CancellationException {@inheritDoc} */ public V get() throws InterruptedException, ExecutionException { int s = state; // A state less than COMPLETING indicates that the task is still executing and has not been cancelled. if (s <= COMPLETING) s = awaitDone(false, 0L); return report(s); }
We know by code
- First check the parameters
- It then determines whether it is executed properly and not cancelled, and if not, calls the awaitDone(boolean,long) method.
- Finally, call the report(int) method
There are two methods involved: awaitDone(boolean,long) method and report(int) method. Let's look at them in turn.
2.1.1 awaitDone (boolean, long) method
This method mainly waits for the task to finish, and stops if the task cancels or times out.
The code is as follows:
/** * Awaits completion or aborts on interrupt or timeout. * * @param timed true if use timed waits * @param nanos time to wait, if timed * @return state upon completion or at timeout */ private int awaitDone(boolean timed, long nanos) throws InterruptedException { // The code below is very delicate, to achieve these goals: // - call nanoTime exactly once for each call to park // - if nanos <= 0L, return promptly without allocation or nanoTime // - if nanos == Long.MIN_VALUE, don't underflow // - if nanos == Long.MAX_VALUE, and nanoTime is non-monotonic // and we suffer a spurious wakeup, we will do no worse than // to park-spin for a while // Starting time long startTime = 0L; // Special value 0L means not yet parked // Nodes currently waiting for threads WaitNode q = null; // Is the node in the waiting list? boolean queued = false; // Thread Blocking Waiting Through Dead Loop for (;;) { int s = state; if (s > COMPLETING) { // Tasks may have been completed or cancelled if (q != null) q.thread = null; return s; } else if (s == COMPLETING) // We may have already promised (via isDone) that we are done // so never return empty-handed or throw InterruptedException // Task threads may be blocked to give up cpu Thread.yield(); else if (Thread.interrupted()) { // Thread interrupts remove waiting threads and throw exceptions removeWaiter(q); throw new InterruptedException(); } else if (q == null) { // If the waiting node is empty, initialize the new node and associate the current thread if (timed && nanos <= 0L) // If you need to wait, and the waiting time is less than 0 to indicate immediate, return directly return s; // If you don't need to wait, or if you need to wait, but the waiting time is more than 0. q = new WaitNode(); } else if (!queued) // Wait for threads to join the queue, because queued=true if the queue succeeds queued = U.compareAndSwapObject(this, WAITERS, q.next = waiters, q); else if (timed) { //If there is a timeout setting final long parkNanos; if (startTime == 0L) { // first time startTime = System.nanoTime(); if (startTime == 0L) startTime = 1L; parkNanos = nanos; } else { long elapsed = System.nanoTime() - startTime; if (elapsed >= nanos) { // If it has timed out, the waiting node is removed removeWaiter(q); return state; } parkNanos = nanos - elapsed; } // nanoTime may be slow; recheck before parking if (state < COMPLETING) // The task is still in progress and hasn't been cancelled, so keep waiting. LockSupport.parkNanos(this, parkNanos); } else LockSupport.park(this); } }
Two participants:
- Time D sets the timeout time for true and false sets no timeout time
- nanos denotes the state of timeout
The logic in the for dead loop is as follows:
- The first step is to determine whether the task has been completed or cancelled. If it returns to the transition status value directly, if not, take the second step.
- The second step, if the state value is COMPLETING, indicates that the current set() method is blocked, so only the CPU resources of the current thread need to be released.
- The third step, if the thread has been interrupted, removes the thread and throws an exception
- The fourth step, if you can go to this step, the state value is only NEW, if the state value is NEW, and q==null, then this is the first time, so initialize a waiting node of the current thread.
- The fifth step, queued=false at this point, indicates that if you are not in the team, it is waiting to join the team.
- Step 6, you can go to this step and say queued=true, then judge whether time D is true, if true, then set the timeout time, and then see if startTime is 0, if 0, then it is the first time, because the default value of startTime is 0, if it is the first time, then set startTime=1. Make sure startTime==0 is the first time. If startTime!=0, it means that it is not the first time. If it is not the first time, elapsed time difference needs to be calculated. If elapsed is larger than nanos, then elapsed time-out is indicated. If it is smaller, there is no time-out, and there is time-difference, then wait for this time-difference blocking.
- Step 7, if timed is false, then there is no timeout setting.
So sum up:
WatDone is to add the current thread to the waiting queue (waitNode has the Thread variable of the current Thread), and then use LockSupport to block itself, wait for a timeout or be unblocked, to determine whether it has been completed (state >= COMPLETING), throw a timeout exception if it is not completed (COMPLETING), wait a little or return the result directly if it has been completed.
This method calls the removeWaiter(WaitNode) method, so let's first see how this removeWaiter(WaitNode) is implemented.
2.1.2 removeWaiter(WaitNode)
/** * Tries to unlink a timed-out or interrupted wait node to avoid * accumulating garbage. Internal nodes are simply unspliced * without CAS since it is harmless if they are traversed anyway * by releasers. To avoid effects of unsplicing from already * removed nodes, the list is retraversed in case of an apparent * race. This is slow when there are a lot of nodes, but we don't * expect lists to be long enough to outweigh higher-overhead * schemes. */ private void removeWaiter(WaitNode node) { if (node != null) { // Empty the node's thread field node.thread = null; /** * The following procedure removes the node from the waiting queue, based on thread as null * If there is competition in the process, try again */ retry: for (;;) { // restart on removeWaiter race for (WaitNode pred = null, q = waiters, s; q != null; q = s) { s = q.next; if (q.thread != null) pred = q; else if (pred != null) { pred.next = s; if (pred.thread == null) // check for race continue retry; } else if (!U.compareAndSwapObject(this, WAITERS, q, s)) continue retry; } break; } } }
First, let's look at the annotations for classes
In order to prevent accumulated memory garbage, it is necessary to cancel the timeout or interrupted waiting nodes. Internal nodes are simple because they don't have CAS, so they can be released harmlessly. In order to avoid the impact of deleted nodes, if there is competition, it is necessary to rearrange. So when there are many nodes, the speed will be very slow, so we don't recommend that the list is too long to reduce efficiency.
This method is mainly to remove thread nodes from the waiting queue.
2.1.2 report (int) method
/** * Returns result or throws exception for completed task. * * @param s completed state value */ @SuppressWarnings("unchecked") private V report(int s) throws ExecutionException { Object x = outcome; // If the task is completed normally, the result of the task execution is returned. if (s == NORMAL) return (V)x; // If the task is cancelled, an exception is thrown if (s >= CANCELLED) throw new CancellationException(); // Other states throw execution exceptions ExecutionException throw new ExecutionException((Throwable)x); }
If the task is in the three states of NEW, COMPLETING and INTERRUPTING, the report method can not be executed, so the three states are not converted.
2.2 get(long, TimeUnit) method
Wait for the result after calculating the time given for completion at most
/** * @throws CancellationException {@inheritDoc} */ public V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException { if (unit == null) throw new NullPointerException(); int s = state; if (s <= COMPLETING && (s = awaitDone(true, unit.toNanos(timeout))) <= COMPLETING) throw new TimeoutException(); return report(s); }
The source code of the parametric get method is very concise. First, the parameters are checked, then the timeout is judged according to the state state. If the timeout is abnormal, the report is called to get the final result.
When s <= COMPLETING, it indicates that the task is still executing and has not been cancelled. If it is true, go to the awaitDone method. The awaitDone method has been explained above, but it's just explained here.
3. cancel(boolean) method
Only tasks that have not yet been executed can be cancelled (tasks with NEW status)
public boolean cancel(boolean mayInterruptIfRunning) { // If the task state is not initialized, cancel the task //If the task has been executed and may be completed, but the state change has not yet been modified, that is, the set() method in the run() method has not yet been invoked. // Continue to determine whether the current state of the task is NEW, because at this point the thread executing the task may be processed again, and the task status may have changed. if (!(state == NEW && U.compareAndSwapInt(this, STATE, NEW, mayInterruptIfRunning ? INTERRUPTING : CANCELLED))) return false; // If the task state is still NEW, that is, the executing thread does not change the state of the task. // Let the execution thread interrupt (the execution thread may change the state of the task in this process) try { // in case call to interrupt throws exception if (mayInterruptIfRunning) { try { Thread t = runner; if (t != null) t.interrupt(); } finally { // final state // Set task status to interrupt U.putOrderedInt(this, STATE, INTERRUPTED); } } } finally { // Processing the results of task completion finishCompletion(); } return true; }
From the above code, we know that this cancellation does not necessarily work.
The above code logic is as follows:
- Step 1: If state is not equal to NEW, it means that the task is about to enter the final state, then state = NEW is false, leading if to set up and return false directly.
- Step 2: If mayInterruptIfRunning is true, indicating interrupt threads, set the state to INTERRUPTING, and then set it to INTERRUPTED after interruption. If mayInterruptIfRunning is false, indicating no interruption of threads, set state to CANCELLED
- Step 3: The state state state is NEW, and the task may or may not have started, so check with Unsafe and return to false if not.
- Step 4: Remove waiting threads
- Step 5: Wake up
Therefore, cancel() method changes the status of futureTask. If the incoming is false and the business logic has started to execute, the current task will not be terminated, but will continue to execute until the exception is known or the execution is completed. If true is passed in, the interrupt() method of the current thread is called and the interrupt flag bit is set to true.
In fact, there is no other way to terminate a thread task completely unless the thread stops its own task or exits the JVM. mayInterruptIfRunning=true, which terminates a task by expecting the current thread to respond to interrupts. When the task is cancelled, it is encapsulated as Cancellation Exception and thrown.
4. runAndReset() Method
Tasks can be performed multiple times
/** * Executes the computation without setting its result, and then * resets this future to initial state, failing to do so if the * computation encounters an exception or is cancelled. This is * designed for use with tasks that intrinsically execute more * than once. * * @return {@code true} if successfully run and reset */ protected boolean runAndReset() { if (state != NEW || !U.compareAndSwapObject(this, RUNNER, null, Thread.currentThread())) return false; boolean ran = false; int s = state; try { Callable<V> c = callable; if (c != null && s == NEW) { try { c.call(); // don't set result ran = true; } catch (Throwable ex) { setException(ex); } } } finally { // runner must be non-null until state is settled to // prevent concurrent calls to run() runner = null; // state must be re-read after nulling runner to prevent // leaked interrupts s = state; if (s >= INTERRUPTING) handlePossibleCancellationInterrupt(s); } return ran && s == NEW; }
Let's start with the notes:
Perform the calculation without setting the result, and then reset the future to the initialization state. If the execution encounters an exception or the task is cancelled, the operation is no longer performed. The purpose of this design is to perform multiple tasks.
We can compare runAndReset and run methods. In fact, they are not very different. There are two main differences.
- 1 run() method sets the result value, while runAndReset() removes the code
Let's look at the handlePossibleCancellation Interrupt (int) method
Five, summary
FutureTask is mostly a simple analysis, the rest of you can just look at it. Task state in FutureTask is represented by variable state, and task state is judged based on state. FutureTask's blocking is achieved by spinning + suspending threads.