About Redis
Redis (Remote Dictionary Service) is an in memory database, also known as KV database and data structure database.
Redis is often used as data cache to cache hot data and reduce the pressure on the database.
View the complete Redis command: Redis command center.
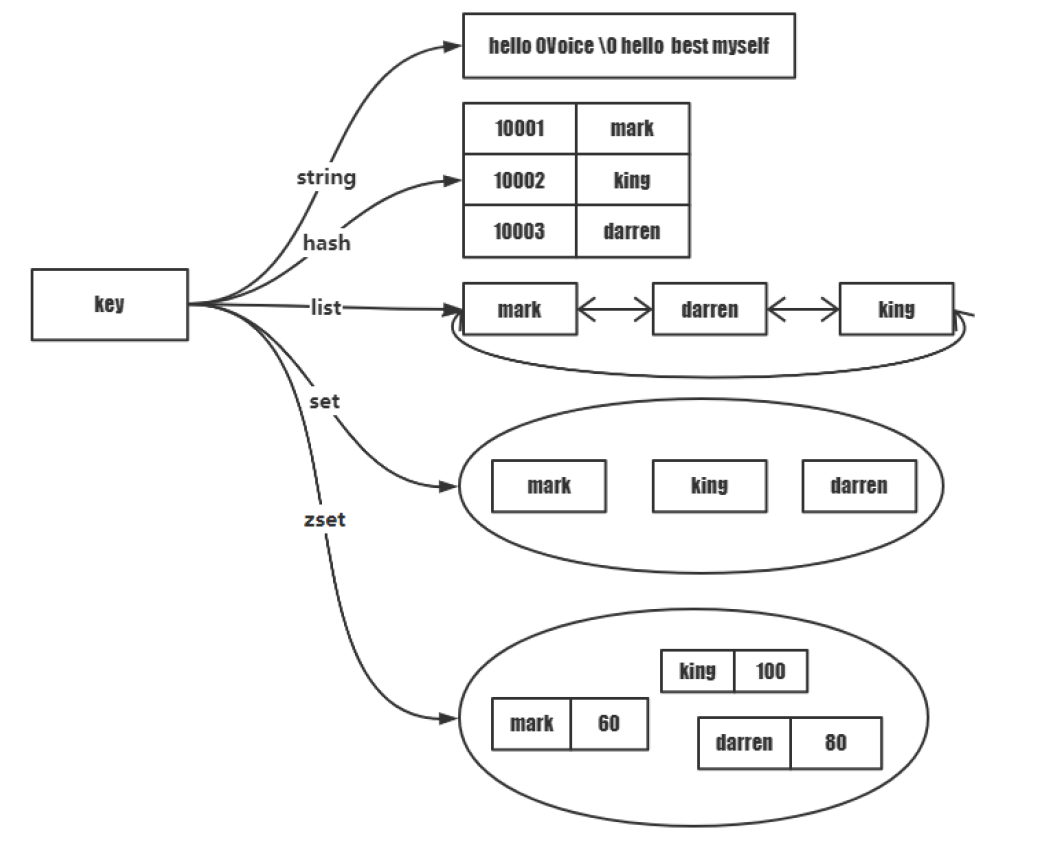
Key value basic data structure
Redis's external interface always obtains the data value through the key.
Redis provides five basic data structures to store key value: string, list, hash, set and zset.
Application scenario
- Cache hotspot data to reduce database pressure (hash)
- Record the number of friends' circle likes, comments and hits (hash)
- Record the list of circle of friends (sort), so as to quickly display the circle of friends (zset or list)
- Record the title, abstract, author and cover of the article for list page display (hash)
- Record the like user ID list and comment ID list of the circle of friends for display and de duplication count (zset)
- If the circle of friends talk ID is an integer ID, redis can be used to allocate the circle of friends talk ID (counter) (string)
- Record the friend relationship (set) through the intersection union difference set operation of the set
- In the game business, the record of each game is stored (list)
Internal storage structure of value and its selection
Redis converts the key into a hash value through the siphash function, and then uses the value as the index to find the corresponding key value node in the hashtable array. At this time, it does not directly get the value value value, because the internal value storage form is different for different data structures (or value is encoded in different forms) , you also need to retrieve the value value in the specific storage structure. The internal storage structure here includes a dictionary, a two-way linked list, a compressed list, a jump table, an integer array, a dynamic string, etc. the retrieval process is roughly as shown in the figure below, including two levels. The first level is to find the key value node through hashtable, and the second level is to find the key value node through hashtable Value found in storage structure of body:
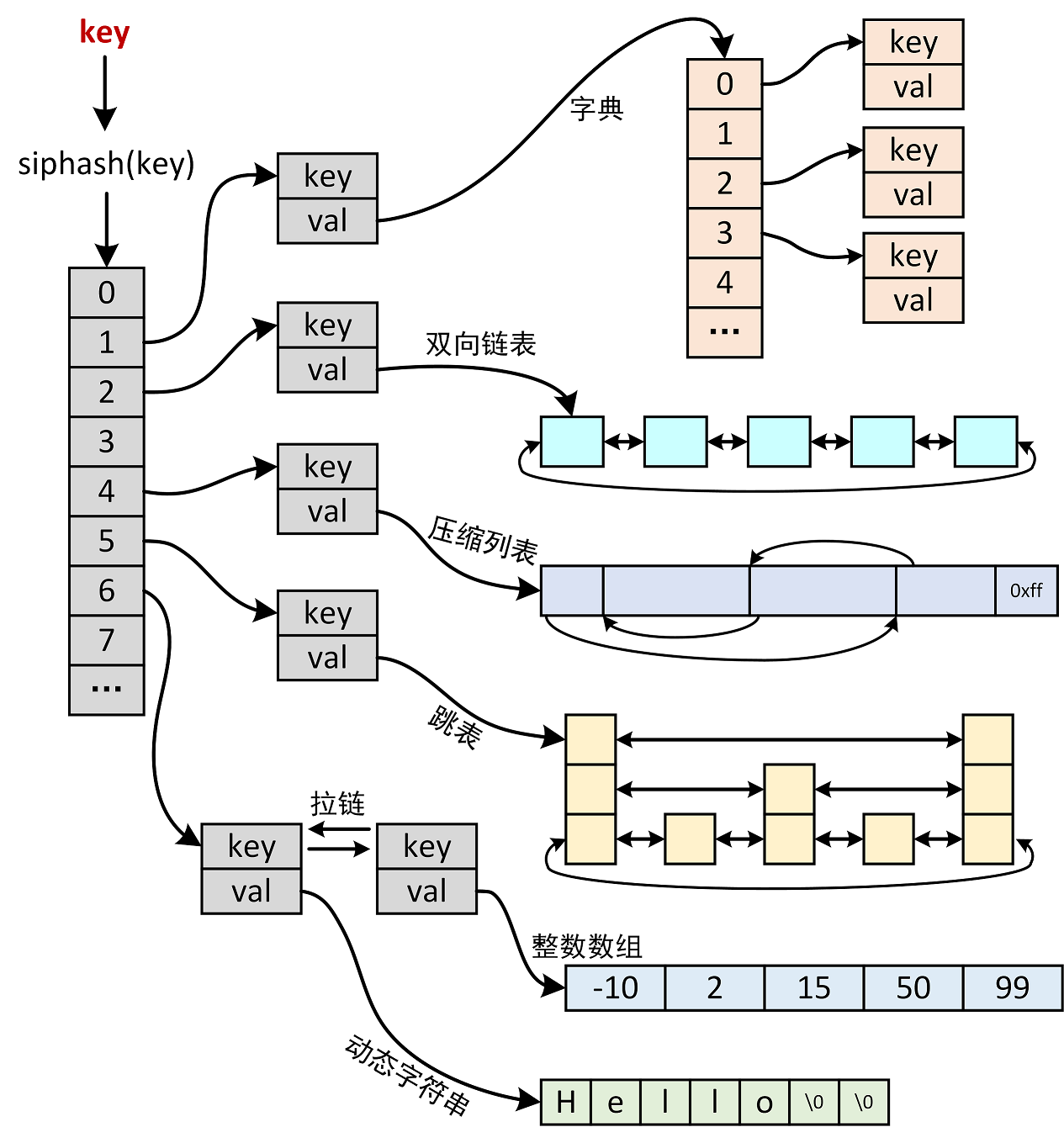
I personally understand that the advantage of this design is to unify the externally provided data operation interface into the form of key value, and then store data in different ways according to different data forms and data structures.
The selection of value internal storage structure and the selection conditions are shown in the following table:
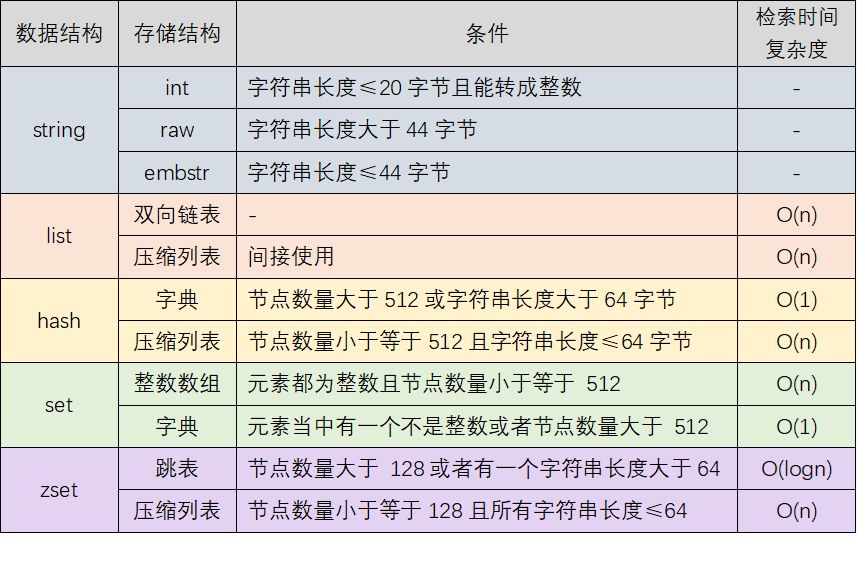
Note: redis string is a binary security string, which can store binary data such as pictures. Generally speaking, key and value are stored in the form of binary security string.
Basic data structure and its operation commands
1 string
Dynamic string is essentially a character array with a maximum length of 512M. It can be expanded. When the string length is less than 1M, it will be doubled each time; when it exceeds 1M, it will only be expanded by 1M each time.
1.1 storage structure
- If the string length is less than or equal to 20 and can be converted into an integer, int is used for storage;
- If the string length is less than or equal to 44, embstr is used for storage;
- If the string length is greater than 44, raw storage is used;
When the data length of redis's memory allocator is less than or equal to 64 bytes, it is considered as a small string, while when the data length is greater than 64 bytes, it is considered as a large string. Taking this as the boundary, redis will process the data differently. However, the boundary for different processing methods of string structure above is 44 bytes. This is related to the header structure of redis's internal description of string structure. These structures are different The 19 byte space is used. At the same time, the string needs to reserve a byte for \ 0, so it needs to occupy 20 bytes. The boundary of the corresponding region size string becomes 44 bytes.
1.2 basic command
Where key is the string as the key and val is the string of value value
SET key val # Set the value of the key GET key # Get value of key DEL key # Delete key Val key value pair SETNX key value # If the key does not exist, it is equivalent to the SET command. When the key exists, nothing is done INCR key # Perform an atomic plus one operation INCRBY key increment # Performs an atomic plus an integer operation DECR key # Perform atomic minus one DECRBY key decrement # Performs the atomic subtraction of an integer SETBIT key offset value # Set or clear the bit value of the value (string) of the key at offset. GETBIT key offset # Returns the bit value of the string corresponding to the key at offset BITCOUNT key # Count the number of bit s whose string is set to 1
Because the value of the set value is a string, the bit value obtained by entering a number and GETBIT follows its ASIC code, not the binary form of the number.
Regardless of the data type, all key s can be deleted with DEL.
1.3 application
a) Object storage:
> set student:1001 '{["name"]:"Mike",["sex"]:"male",["age"]:26}'
OK
> get student:1001
"{[\"name\"]:\"Mike\",[\"sex\"]:\"male\",[\"age\"]:26}"
> del student:1001
(integer) 1 # Delete succeeded
student:1001 is the name of the key, which is completely customized.
b) Accumulator (e.g. statistics of reading volume, visits, etc.):
> set reads 0 OK > incr reads # Accumulate 1 (integer) 1 > incrby reads 10 # Accumulate 10 (integer) 11
c) Distributed locks:
> setnx lock 1 # Get the lock (integer) 1 > setnx lock 1 # I didn't get the lock (integer) 0 > del lock # Release lock (integer) 1
d) Bit operation (such as statistics of monthly check-in times):
> setbit sign:202111 1 1 # 2021.11.1 sign in (integer) 0 > setbit sign:202111 2 1 # 2021.11.2 sign in (integer) 0 > bitcount sign:202111 # 2021.11 sign in times (integer) 2
2 list
Two way linked list, time complexity O(1) of head and tail data operation (deletion and increase); The time complexity of finding intermediate elements is
O(n).
When the data of nodes in the table will not be compressed:
- The element length is less than 48 bytes and is not compressed;
- The length difference between elements before and after compression shall not exceed 8 bytes and shall not be compressed;
2.1 storage structure
- Two way linked list quicklist
- Compressed list ziplost
2.2 basic command
LPUSH key value [value ...] # Queue one or more elements from the left side of the queue LPOP key # Pop an element from the left side of the queue BLPOP key timeout # Pop up an element from the left side of the queue. If there is no element, it will be blocked; Timeout unit: s RPUSH key value [value ...] # Queue one or more elements from the right side of the queue RPOP key # Pop up an element from the right side of the queue, and return immediately if there is no element BRPOP key timeout # Pop up an element from the right side of the queue. If there is no element, it will be blocked; Timeout unit: s LRANGE key start end # Returns the element between start and end from the queue, left in the front and right in the back LREM key count value # Remove the element with the value of value from the list for the previous count times LTRIM key start end # Truncate the queue, leaving only the elements between start and end
2.3 Application
a) Implementation stack (first in, last out):
> lpush stack 'one' (integer) 1 > lpush stack 'two' (integer) 2 > lpop stack "two" > lpop stack "one"
b) Implementation queue (first in first out):
> lpush queue "one" (integer) 1 > lpush queue "two" (integer) 2 > rpop queue "one" > rpop queue "two"
c) Implement blocking queue:
> blpop queue 3 # Block for 3 seconds. If the timeout is set to 0, it will be permanently blocked until another client inserts the element (nil) (3.08s)
d) Asynchronous message queuing:
One client inserts the element and the other takes it out.
e) Get fixed window records (such as recent records):
> lpush news '{"topic":"holiday","view":20}'
> lpush news '{"topic":"nothing","view":10}'
> lpush news '{"topic":"a dog","view":100}'
> lpush news '{"topic":"shit","view":200}'
> lpush news '{"topic":"joker","view":122}'
> lpush news '{"topic":"batman","view":255}'
> ltrim news 0 4 # Truncate to the latest top 5 records
OK
> lrange news 0 -1 # -1 is the penultimate item, - 2 is the penultimate item, and so on
1) "{\"topic\":\"batman\",\"view\":255}"
2) "{\"topic\":\"joker\",\"view\":122}"
3) "{\"topic\":\"shit\",\"view\":200}"
4) "{\"topic\":\"a dog\",\"view\":100}"
5) "{\"topic\":\"nothing\",\"view\":10}"
The atomicity of commands needs to be guaranteed in actual projects, so lua scripts or pipeline commands are generally used.
3 hash
3.1 storage structure
- When the number of nodes is less than or equal to 512 and the string length is less than or equal to 64 bytes, the compressed list ziplost is adopted
- Dictionary dict is used when the number of nodes is greater than 512 or the length of string is greater than 64 bytes
Why not use compressed lists when there is a large amount of data? Because the compressed list needs compression processing and sequential retrieval, the performance becomes worse when the amount of data is large.
3.2 basic command
HSET key field value # Set the value corresponding to the field in the key corresponding hash HGET key field # Get the value corresponding to the field in the key hash HDEL key field # Delete the key value pair of the hash corresponding to the key. The key is field HMSET key field1 value1 field2 value2 ... fieldn valuen # Set multiple hash key value pairs HMGET key field1 field2 ... fieldn # Gets the value of multiple field s HINCRBY key field increment # Add an integer value to the value corresponding to the field in the key corresponding hash HLEN key # Get the number of key value pairs in the hash corresponding to the key HGETALL key # Returns all fields and values in the hash corresponding to the key. In the return value, the next value of each field name is its value, so the length of the return value is twice the size of the hash set
3.3 application
a) Storage object:
> hset user:1001 name Dave age 26 sex male # hset can also replace hmset (integer) 3 > hset user:1001 age 28 # Modify the age field of user:1001 (integer) 0 > hmget user:1001 name age sex 1) "Dave" 2) "28" 3) "male"
b) Implement a shopping cart:
You need to use hash to save each commodity object, but the hash is out of order. You also need a list to arrange the items in the order of purchase.
# key is the hash of User:1001:Cart to save the commodity object, field is the additional purchase commodity id, and value is the additional purchase quantity of the commodity; # The key is the list of User:1001:Items, and the product id is saved according to the order of purchase # key field value > hset User:1001:Cart itemId:20001 3 > lpush User:1001:Items itemId:20001 > hset User:1001:Cart itemId:20002 2 > lpush User:1001:Items itemId:20002 > hset User:1001:Cart itemId:20003 1 > lpush User:1001:Items itemId:20003 > hlen User:1001:Cart # Commodity category and quantity (integer) 3 # Modify the quantity of a product > hincrby User:1001:Cart itemId:20001 1 # Quantity plus 1 (integer) 4 > hincrby User:1001:Cart itemId:20001 -1 # Quantity minus 1 (integer) 3 # To delete a product, both hash and list should be operated > hdel User:1001:Cart itemId:20001 (integer) 1 > lrem User:1001:Items 1 itemId:20001 (integer) 1 # Get all items > lrange User:1001:Items 0 -1 1) "itemId:20003" 2) "itemId:20002" > hgetall User:1001:Cart 1) "itemId:20002" 2) "2" 3) "itemId:20003" 4) "1"
4 set
Collections are used to store unique fields and do not require ordering.
4.1 storage structure
- If all elements are integers and the number of nodes is less than or equal to 512, the integer array intset is used for storage;
- If one of the elements is not an integer or the number of nodes is greater than 512, the dictionary dict is used for storage;
4.2 basic command
SADD key member [member ...] # Add one or more specified member elements to the set key SREM key member [member ...] # Removes the specified element from the key collection SISMEMBER key member # Returns whether the member member is a member of the stored collection key SCARD key # Calculate the number of collection elements SMEMBERS key # Returns all elements of the key collection SRANDMEMBER key [count] # Randomly return one or more elements in the key set without deleting them SPOP key [count] # Removes and returns one or more random elements from the collection stored in the key SDIFF key [key ...] # Returns the element of the difference between a set and a given set SINTER key [key ...] # Returns the intersection of members of all specified sets SUNION key [key ...] # Returns the of a given collection and all members of the collection
4.3 application
a) Realize the lucky draw:
> sadd luckyman 1001 1002 1003 1004 # Add user id participating in lottery (integer) 4 > smembers luckyman # List all user IDs participating in the raffle 1) "1001" 2) "1002" 3) "1003" 4) "1004" > srandmember luckyman 1 # Who is so lucky? 1) "1003"
b) Find common friends and recommend friends you might know:
> sadd User:1001:Friends 1002 1003 1004 1005 (integer) 4 > sadd User:1002:Friends 1001 1004 1005 1006 (integer) 4 > sinter User:1001:Friends User:1002:Friends # Seek intersection and get common friends 1) "1004" 2) "1005" # Recommend people you may know > sdiff User:1001:Friends User:1002:Friends # Find the difference set between 1001 and 1002, and 1003 can be recommended to 1002 1) "1002" 2) "1003"
5 zset
A sorted set that stores ordered unique fields.
5.1 storage structure
- If the number of nodes is greater than 128 or the length of a string is greater than 64, the skip list is used;
- If the number of nodes is less than or equal to 128 and the length of all strings is less than or equal to 64, ziplist is used for storage;
5.2 basic command
ZADD key [NX|XX] [CH] [INCR] score member [score member ...] # Add to the ordered set with key ZREM key member [member ...] # Delete the key value pair of member from the ordered set with key as key ZINCRBY key increment member # Add increment to the score value of the member of the ordered set key ZCARD key # Returns the number of ordered set elements of the key ZSCORE key member # Returns the score value of the member in the ordered set key ZRANK key member # Returns the ranking of member s in the ordered set key # The following command can pass the with scores option to return the score of the element with the element ZRANGE key start stop [WITHSCORES] # Returns the elements of the specified range in the ordered set key (sorted from the lowest to the highest score) ZREVRANGE key start stop [WITHSCORES] # Returns the members in the specified interval of the ordered set and the key type (sorted by decreasing score value) ZREMRANGEBYSCORE key min max # Remove all members in the ordered set key whose score value is between min and max (including those equal to min or max)
For detailed description of ZADD option parameters, please refer to zadd command.
5.3 application
a) Hot search ranking:
# Add 6 news items first, and the initial score is 50 > zadd hotnews:20211128 50 2021112801 50 2021112802 50 2021112803 50 2021112804 50 2021112805 50 2021112806 (integer) 6 # Start changing the heat of the news (score) > zincrby hotnews:20211128 1 2021112803 "51" > zincrby hotnews:20211128 1 2021112803 "52" > zincrby hotnews:20211128 1 2021112805 "51" > zincrby hotnews:20211128 5 2021112805 "56" > zincrby hotnews:20211128 10 2021112802 "60" # List top 2 news > zrevrange hotnews:20211128 0 2 WITHSCORES 1) "2021112802" 2) "60" 3) "2021112805" 4) "56" 5) "2021112803" 6) "52"
b) Delay queue:
The message is serialized into a string as the member of zset, and the expiration processing time of the message is taken as the score. Then, through lua and other scripting languages, multiple threads poll zset to obtain the latest expired message for processing.
c) Time window current limiting:
The system limits that a user's behavior can only occur N times in a specified time. Take "user id + behavior" as key and time as field and value. By removing the data outside the time window through ZREMRANGEBYSCORE, and then counting the number of behaviors in the time window with ZCARD, you can judge whether the behavior execution in the time window exceeds N times.