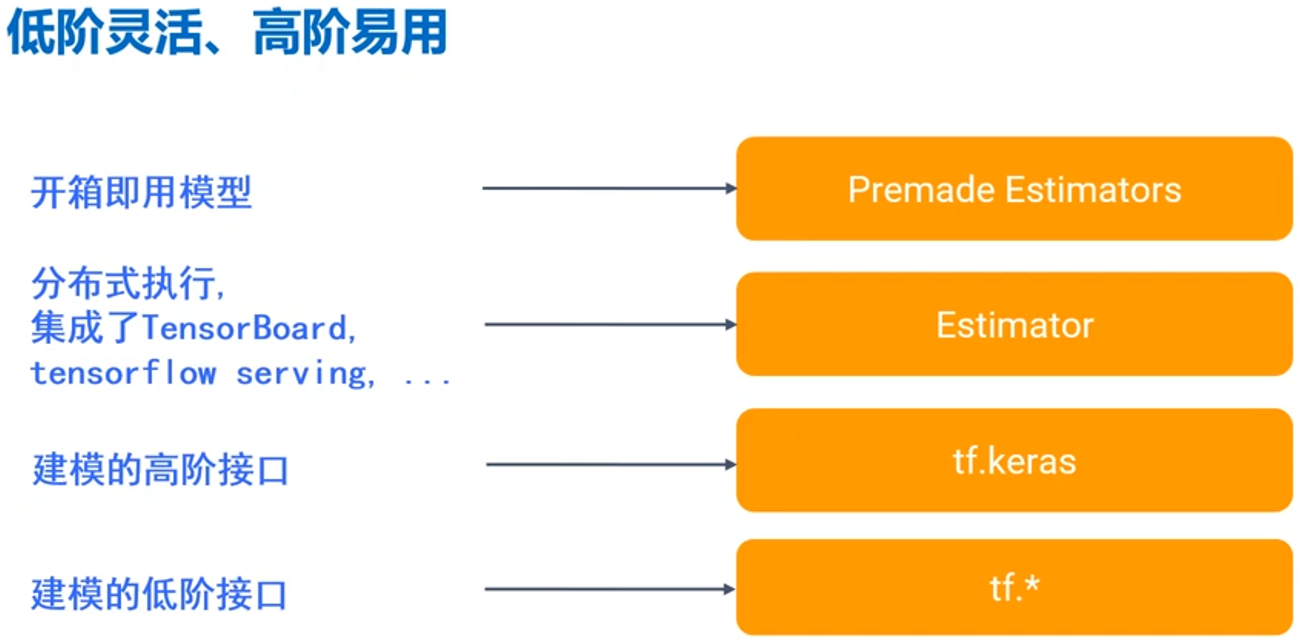
Keras is a higher-level Tensorflow interface application. The Tensorflow framework no longer needs to introduce the third-party keras package, and can directly apply the keras higher-order interface. The threshold of building neural network is reduced, which is more conducive to the use of neural network by researchers. On top of this, there are more integrated applications and models. Their relationship can be basically represented by the following figure. The lower the development threshold, the higher the development threshold, the more flexible the application, and the more friendly the higher level. Which level of API can be used according to the actual situation of developers
 The model building process of Keras.
The model building process of Keras.
1. Serialized modeling model = tf.keras.models.Sequential()
2. Add model.add(tf.keras.layers.Dense( )
3, Model setting is the measurement model.compile (...) that defines optimizer, loss function and monitoring
4. Train u history = model. Fit ( )
5. Evaluate? Results = model. Evaluate (...)
6. Use the model to predict Gu result = model. Predict ( )
7. Restore model. Load? Weights ( )
Take titanic personnel data as an example, and use keras to build neural network code for reference
#Data preparation ##Download passenger data import urllib.request import os data_url = "http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3.xls" data_file_path = "data/titanic3.xls" if not os.path.isfile(data_file_path): result = urllib.request.urlretrieve(data_url,data_file_path) print("downloaded:",result) else: print(data_file_path," data file already exists.") #Read data import numpy import pandas as pd df_data = pd.read_excel(data_file_path) #Filter data fields selected_cols = ['survived','name','pclass','sex','age','sibsp','parch','fare','embarked'] selected_df_data = df_data[selected_cols] from sklearn import preprocessing #Define data preprocessing functions def prepare_data(df_data): df = df_data.drop(['name'],axis = 1) age_mean = df['age'].mean() df['age']=df['age'].fillna(age_mean) fare_mean = df['fare'].mean() df['fare']=df['fare'].fillna(fare_mean) df['sex']=df['sex'].map({'female':0,'male':1}).astype(int) df['embarked'] = df['embarked'].fillna('S') df['embarked'] = df['embarked'].map({'C':0,'Q':1,'S':2}).astype(int) ndarray_data = df.values features = ndarray_data[:,1:] label = ndarray_data[:,0] minmax_scale = preprocessing.MinMaxScaler(feature_range=(0,1)) norm_features = minmax_scale.fit_transform(features) return norm_features,label #shuffle scrambles data to prepare for subsequent data shuffled_df_data = selected_df_data.sample(frac=1) #Preprocessing data x_data,y_data = prepare_data(shuffled_df_data) #Divided into training set test set train_size = int(len(x_data)*0.8) x_train = x_data[:train_size] y_train = y_data[:train_size] x_test = x_data[train_size:] y_test = y_data[train_size:] #Keras modeling import tensorflow as tf #Modeling with Keras serialization model = tf.keras.models.Sequential() #Add layer 1,64Neurons, input data dimension is7,KERNEL_INITIALIZERIt refers to the way of weight initialization model.add(tf.keras.layers.Dense(units = 64, input_dim = 7, use_bias = True, kernel_initializer ='uniform', bias_initializer ='zero', activation = 'relu')) #Add sigmoid layer, the input dimension of the second layer can not be specified, which is equal to the dimension of the first layer by default model.add(tf.keras.layers.Dense(units=32,activation='sigmoid')) #Specify output layer,Output layer units It's equal to the category that needs to be classified model.add(tf.keras.layers.Dense(units=1,activation='sigmoid')) #Show model parameters model.summary() #Using keras to set up the model,It's about defining optimizers, loss functions, and metrics for monitoring model.compile(optimizer = tf.keras.optimizers.Adam(0.003), loss='binary_crossentropy', metrics = ['accuracy']) #sigmoid is used as the activation function, and binary crossentropy is used as the general loss function #softmax is used as the activation function, and the general loss function is classified cross entropy #For specific settings, please refer to the relevantAPIDocuments like #https://www.tensorflow.org/versions/r1.10/api_docs/python/tf/keras/Model #In the training model of keras, the return value of fit is the data of dictionary type train_history = model.fit(x=x_train, y=y_train, validation_split = 0.2, #The training set data is divided into two parts,20%Use as validation set epochs =100, batch_size = 40, verbose=2 #Display parameters 0/1/2 0No indication;1Display progress bar;2Show most details ) #Define the visual function of training process import matplotlib.pyplot as plt def visu_train_history(train_history,train_metrics,validation_metric): plt.plot(train_history.history[train_metrics]) plt.plot(train_history.history[validation_metric]) plt.title('Train_History') plt.ylabel('train_metrics') plt.xlabel('epoch') plt.legend(['train','validatio'],loc='upper left') plt.show() #Display accuracy visu_train_history(train_history,'acc','val_acc') #Display loss function visu_train_history(train_history,'loss','val_loss') #Evaluation model evaluate_results = model.evaluate(x=x_test, y = y_test) #model.metrics_names Label that holds the return value of the result #Application of keras model #Making data #Jack:3First class, male, fare5,Age23 #Rose: first class, women, ticket price100,Age20 Jack_info=[0,'Jack',3,'male',23,1,0,5.0,'S'] Rose_info = [1,'Rose',1,'female',20,1,0,100.0,'S'] #Create new passenger information #columns=selected_cols The column representing passenger information is the feature column selected previously new_passager_pd = pd.DataFrame([Jack_info,Rose_info],columns=selected_cols) #Add new passenger information to the old DataFrame all_passager_pd = selected_df_data.append(new_passager_pd) #Data preprocessing is performed here x_features,y_label = prepare_data(all_passager_pd) #Using the model to calculate the survival rate of passengers surv_probability = model.predict(x_features) #Check the survival probability of the last two passengers print(surv_probability[-2:])

