According to the previous section Build a High Availability mongodb Cluster (3) - Deep Copy Set Two problems remain unsolved after the construction:
- Every data above the node is a full copy of the database. Will the pressure from the node be too high?
- Can the data expand automatically when the pressure is too high to support the machine?
In the early stage of the system, when the amount of data is small, it will not cause too many problems, but as the amount of data continues to increase, sooner or later there will be a machine hardware bottleneck problem. And mongodb's main focus is massive data architecture. He can't solve the problem of massive data. No way! This is how "fragmentation" solves this problem.
How do traditional databases read and write massive data? In fact, a sentence can be summarized: divide and rule. As you can see from the picture above, the following schematic diagram is presented by taobao Yue Xuqiang in infoq:
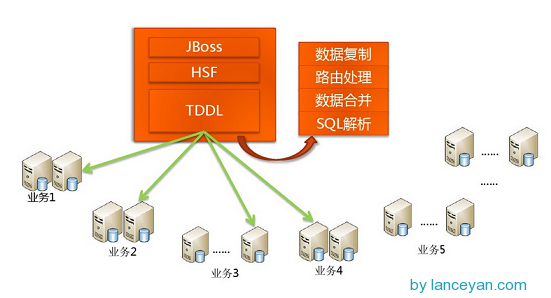
There is a TDDL in the figure above, which is a data access layer component of taobao. Its main functions are SQL parsing and routing processing. According to the function of the application request, the SQL that is currently accessed is parsed to determine which business database, which table accesses the query and returns the data results. Specific figures are as follows:
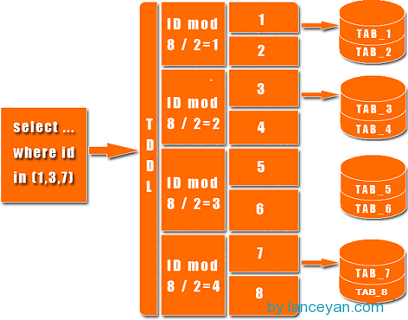
With so many traditional database architectures, how can Nosql do this? To achieve automatic expansion of mysql, a data access layer is added to extend it by program, and the addition, deletion and backup of database need to be controlled by program. Once there are more nodes in the database, it is very difficult to maintain it. But mongodb can do all this through his own internal mechanism! Suddenly petrified, so Niu X! Let's see what mechanism mongodb implements routing and fragmentation:
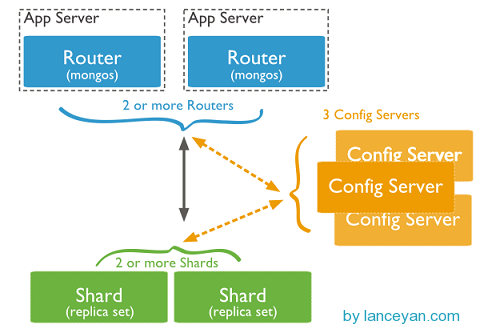
From the figure, you can see four components: mongos, config server, shard, replica set.
Mongos, the entrance of database cluster requests, all requests are coordinated through mongos, and there is no need to add a routing selector in the application. mongos itself is a request distribution center, which is responsible for forwarding the corresponding data requests to the corresponding shard server. In production environments, there are usually multiple mongos as the entry point for requests, preventing one of them from hanging all mongodb requests from being unable to operate.
Configuration server, as its name implies, stores the configuration of all database meta-information (routing, fragmentation). Mongos itself does not physically store fragmented servers and data routing information, but only caches in memory, while configuration servers actually store these data. The configuration information is loaded from config server when mongos is restarted for the first time or turned off. If the configuration server information changes later, all mongos will be notified to update their status, so that mongos can continue to route accurately. In production environments, there are usually multiple config servers to configure servers, because it stores metadata for fragmented routing, which can not be lost! Even if one of them is suspended, the mongodb cluster will not be suspended as long as there is stock.
shard, this is the legendary fragment. The above mentioned machine has a ceiling even if it is powerful. Just like the army fighting, a person can't compete with a division of the other side if he drank a blood bottle. As the saying goes, Zhuge Liang is the top of three smelly cobblers, and then the strength of the team is highlighted. The same is true on the internet. A common machine can't do many machines to do it, as shown below.
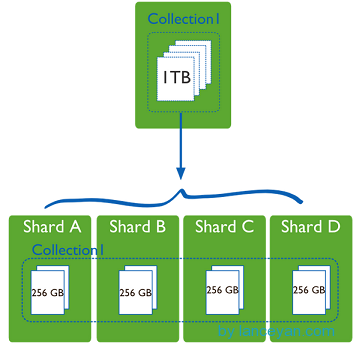
Collection 1, a data table of a machine, stores 1T of data. It's too stressful! After four machines were allocated, each machine was 256G, and the pressure on one machine was shared. Maybe someone asked if a machine hard disk could be enlarged a little. Why should it be allocated to four machines? Don't just think about storage space. The actual database running also has hard disk reading and writing, network IO, CPU and memory bottlenecks. As long as the fragmentation rules are set up in the mongodb cluster, the corresponding data operation requests can be automatically forwarded to the corresponding fragmentation machine through the mongos operation database. In the production environment, the slicing keys can be well set up, which affects how to distribute data evenly to multiple slicing machines. Do not appear that one machine has 1 T, other machines have not, so it is better not to slice!
Replica set, the last two sections have described in detail this East, how to come here to join the fun! In fact, if the replica set is not an incomplete architecture, assuming that one of the fragments will lose one quarter of the data, the high availability fragmentation architecture also needs to build replica set replica set replica set for each fragment to ensure the reliability of the fragmentation. The production environment is usually 2 copies + 1 arbitration.
Having said so much, let's take a look at how to build a highly available mongodb cluster:
Firstly, determine the number of components, three mongos, three config servers and three shard servers. Each shard has one copy and one arbitration, that is, 3*2 = 6. A total of 15 instances need to be deployed. These examples can be deployed either on a stand-alone machine or on a single machine. We have limited testing resources here. We only have three machines ready. On the same machine, as long as the ports are different, we can take a look at the physical deployment diagram.
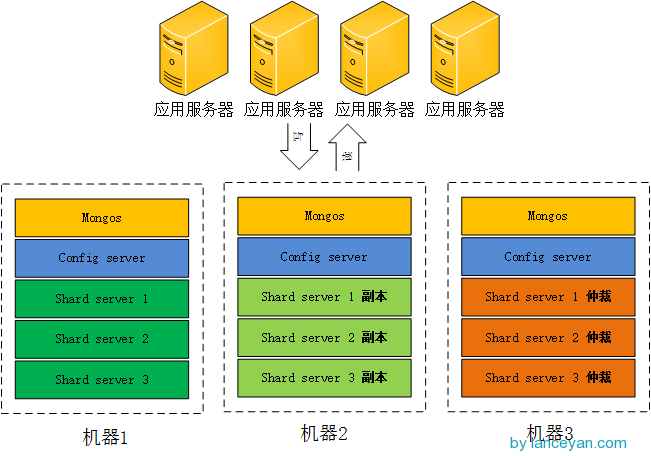
Architecture is set up, install software! ___________
- 1. Prepare the machine with IP set to 192.168.0.136, 192.168.0.137 and 192.168.0.138 respectively.
- 2. Establish mongodb fragmentation corresponding test folders on each machine.
#Store mongodb data files mkdir -p /data/mongodbtest #Enter the mongodb folder cd /data/mongodbtest
- 3. Download the installation package of mongodb
wget http://fastdl.mongodb.org/linux/mongodb-linux-x86_64-2.4.8.tgz #Unzip the downloaded compressed package tar xvzf mongodb-linux-x86_64-2.4.8.tgz
- 4. Set up five directories of mongos, config, shard1, shard2 and shard3 on each machine. Because mongos does not store data, it only needs to create a directory of log files.
#Establishment of mongos directory mkdir -p /data/mongodbtest/mongos/log #Establishment of config server data file storage directory mkdir -p /data/mongodbtest/config/data #Establish a directory for config server log files mkdir -p /data/mongodbtest/config/log #Establish a directory for config server log files mkdir -p /data/mongodbtest/mongos/log #Establishment of shard1 Data File Storage Directory mkdir -p /data/mongodbtest/shard1/data #Create shard1 log file storage directory mkdir -p /data/mongodbtest/shard1/log #Establishment of shard2 Data File Storage Directory mkdir -p /data/mongodbtest/shard2/data #Establishment of shard2 log file storage directory mkdir -p /data/mongodbtest/shard2/log #Establishment of shard3 Data File Storage Directory mkdir -p /data/mongodbtest/shard3/data #Create Shard 3 log file storage directory mkdir -p /data/mongodbtest/shard3/log
-
5. Planning the port numbers corresponding to the five components. Because a machine needs to deploy mongos, config server, shard1, shard2 and shard3 at the same time, it needs to be distinguished by ports. This port can be freely defined. In this paper, mongos is 2000, config server is 21000, shard1 is 2001, shard2 is 2002, and shard3 is 2003.
- 6. Start the configuration server on each server separately.
/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongod --configsvr --dbpath /data/mongodbtest/config/data --port 21000 --logpath /data/mongodbtest/config/log/config.log --fork
- 7. Start mongos server on each server.
/data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongos --configdb 192.168.0.136:21000,192.168.0.137:21000,192.168.0.138:21000 --port 20000 --logpath /data/mongodbtest/mongos/log/mongos.log --fork
- 8. Configure the replica set of each fragment.
#In each machine, the shard1 server and the replica set shard1 are set up separately. /data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongod --shardsvr --replSet shard1 --port 22001 --dbpath /data/mongodbtest/shard1/data --logpath /data/mongodbtest/shard1/log/shard1.log --fork --nojournal --oplogSize 10
In order to quickly start and save the storage space of the test environment, the nojournal is added here to shut down the log information. In our test environment, we do not need to initialize such a large redo log. The oplog size is also set to reduce the size of the local file. The oplog is a capped collection of fixed length that exists in the "local" database to record the Replica Sets operation log. Note that the settings here are for testing!
#In each machine, shard2 server and replica set are set up separately. /data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongod --shardsvr --replSet shard2 --port 22002 --dbpath /data/mongodbtest/shard2/data --logpath /data/mongodbtest/shard2/log/shard2.log --fork --nojournal --oplogSize 10 #In each machine, the shard3 server and the replica set shard3 are set up separately. /data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongod --shardsvr --replSet shard3 --port 22003 --dbpath /data/mongodbtest/shard3/data --logpath /data/mongodbtest/shard3/log/shard3.log --fork --nojournal --oplogSize 10
Configure the replica set for each fragment, and learn more about the replica set by referring to previous articles in this series.
Arbitrary login to a machine, such as 192.168.0.136, connected to mongodb
#Setting up the first fragmented replica set /data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongo 127.0.0.1:22001 #Using admin database use admin #Define replica set configuration config = { _id:"shard1", members:[ {_id:0,host:"192.168.0.136:22001"}, {_id:1,host:"192.168.0.137:22001"}, {_id:2,host:"192.168.0.138:22001",arbiterOnly:true} ] } #Initialize replica set configuration rs.initiate(config); #Setting up the second fragmented replica set /data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongo 127.0.0.1:22002 #Using admin database use admin #Define replica set configuration config = { _id:"shard2", members:[ {_id:0,host:"192.168.0.136:22002"}, {_id:1,host:"192.168.0.137:22002"}, {_id:2,host:"192.168.0.138:22002",arbiterOnly:true} ] } #Initialize replica set configuration rs.initiate(config); #Setting up the third fragmented replica set /data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongo 127.0.0.1:22003 #Using admin database use admin #Define replica set configuration config = { _id:"shard3", members:[ {_id:0,host:"192.168.0.136:22003"}, {_id:1,host:"192.168.0.137:22003"}, {_id:2,host:"192.168.0.138:22003",arbiterOnly:true} ] } #Initialize replica set configuration rs.initiate(config);
- 9. Currently, mongodb configuration server and routing server are built, and each fragmentation server is built. However, the application connecting to mongos routing server can not use the fragmentation mechanism, and the fragmentation configuration needs to be set up in the program to make the fragmentation effective.
#Connect to mongos /data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongo 127.0.0.1:20000 #Using admin database user admin #Series Routing Server and Distribution Replica Set 1 db.runCommand( { addshard : "shard1/192.168.0.136:22001,192.168.0.137:22001,192.168.0.138:22001"});
If Shard is a single server, add it with commands such as db.runCommand ({addshard: "[:]"}), and if shard is a replica set, use db.runCommand ({addshard: {replicaSetName/[:port][, server rhostname2 [:port],... ]”} In this format.
#Series Routing Server and Distribution Copy Set 2 db.runCommand( { addshard : "shard2/192.168.0.136:22002,192.168.0.137:22002,192.168.0.138:22002"}); #Series Routing Server and Distribution Copy Set 3 db.runCommand( { addshard : "shard3/192.168.0.136:22003,192.168.0.137:22003,192.168.0.138:22003"}); #View the configuration of the sharding server db.runCommand( { listshards : 1 } );
Content output
{ "shards" : [ { "_id" : "shard1", "host" : "shard1/192.168.0.136:22001,192.168.0.137:22001" }, { "_id" : "shard2", "host" : "shard2/192.168.0.136:22002,192.168.0.137:22002" }, { "_id" : "shard3", "host" : "shard3/192.168.0.136:22003,192.168.0.137:22003" } ], "ok" : 1 }
Because 192.168.0.138 is the arbitration node for each fragmented replica set, the above results are not listed.
- 10. At present, configuration services, routing services, fragmentation services and replica set services have been connected in series, but our purpose is to insert data, data can be automatically fragmented, just a little bit, a little.... Connect to mongos, ready for the specified database, specified collection fragmentation to take effect.
#Specify testdb fragmentation to take effect db.runCommand( { enablesharding :"testdb"}); #Specify the collection and key to be fragmented in the database db.runCommand( { shardcollection : "testdb.table1",key : {id: 1} } )
We need to slice the table1 table of testdb, and automatically slice it to shard1, shard2 and shard3 according to id. This is because not all mongodb databases and tables need to be sliced!
- 11. Test the results of fragmentation configuration.
#Connect to mongos server /data/mongodbtest/mongodb-linux-x86_64-2.4.8/bin/mongo 127.0.0.1:20000 #Using testdb use testdb; #Insert test data for (var i = 1; i <= 100000; i++) db.table1.save({id:i,"test1":"testval1"}); #View the fragmentation as follows, some irrelevant information is omitted db.table1.stats();
{ "sharded" : true, "ns" : "testdb.table1", "count" : 100000, "numExtents" : 13, "size" : 5600000, "storageSize" : 22372352, "totalIndexSize" : 6213760, "indexSizes" : { "_id_" : 3335808, "id_1" : 2877952 }, "avgObjSize" : 56, "nindexes" : 2, "nchunks" : 3, "shards" : { "shard1" : { "ns" : "testdb.table1", "count" : 42183, "size" : 0, ... "ok" : 1 }, "shard2" : { "ns" : "testdb.table1", "count" : 38937, "size" : 2180472, ... "ok" : 1 }, "shard3" : { "ns" : "testdb.table1", "count" :18880, "size" : 3419528, ... "ok" : 1 } }, "ok" : 1 }
We can see that the data is divided into three segments, the number of each segment is shard1 "count": 42183, shard2 "count": 38937, shard3 "count": 18880. It's already done! Not too much seems to be not very uniform, so this section is still very exquisite, follow-up in-depth discussion.
- 12. The java program calls the fragmented cluster, because we configure three mongos as the entries. It doesn't matter which one of the entries is suspended. Using the cluster client program is as follows:
public class TestMongoDBShards { public static void main(String[] args) { try { List<ServerAddress> addresses = new ArrayList<ServerAddress>(); ServerAddress address1 = new ServerAddress("192.168.0.136" , 20000); ServerAddress address2 = new ServerAddress("192.168.0.137" , 20000); ServerAddress address3 = new ServerAddress("192.168.0.138" , 20000); addresses.add(address1); addresses.add(address2); addresses.add(address3); MongoClient client = new MongoClient(addresses); DB db = client.getDB( "testdb" ); DBCollection coll = db.getCollection( "table1" ); BasicDBObject object = new BasicDBObject(); object.append( "id" , 1); DBObject dbObject = coll.findOne(object); System. out .println(dbObject); } catch (Exception e) { e.printStackTrace(); } } }
The whole fragmented cluster has been built. Think about whether our architecture is good enough? In fact, there are still many areas to be optimized, such as we put all arbitration nodes in one machine, the other two machines bear all the read and write operations, but 192.168.0.138 as arbitration is quite idle. Let the machine 3 192.168.0.138 share more responsibilities! The architecture can be adjusted so that the load distribution of the machine can be more balanced. Each machine can be used as the master node, the replica node and the arbitration node, so that the pressure will be balanced a lot, as shown in the figure:
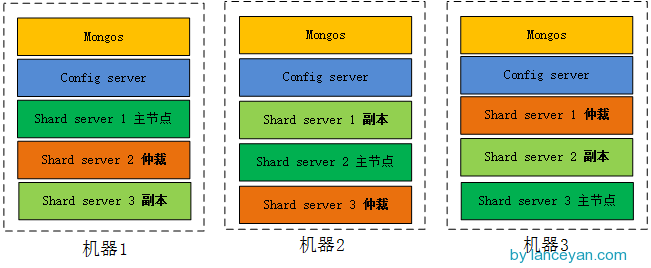
Of course, the data of production environment is far larger than the current test data. In the case of large-scale data application, we can not deploy all nodes like this. The hardware bottleneck is hard injury, and can only expand the machine. There are many mechanisms that need to be adjusted to make good use of mongodb, but we can quickly achieve high availability and scalability through this east, so it is also a very good Nosql component.
Look at the mongodb java driver client MongoClient(addresses), which can be passed into multiple mongos as the entrance to the mongodb cluster, and can achieve automatic failover, but how about load balancing? Open the source code to see:

Its mechanism is to select the fastest ping machine as the entry point for all requests, and if the machine hangs up, the next machine will be used. So... Surely not! In case of double eleven, all requests are sent centrally to this machine, which is likely to hang up. Once it hangs up, it will transfer requests to the off-stage machine according to its mechanism, but the total amount of pressure has not been reduced ah! __________ The next one may still crash, so there are loopholes in this architecture! But this article is too long, follow-up solution.
Reference resources: http://docs.mongodb.org/manual/core/sharding-introduction/