The search results of many search engines will highlight the matching keywords to facilitate the rapid identification of users. Of course, Lucene.NET also provides the highlighting function.
1. Realization of highlight function
1.1. Install Lucene.NET.HighLight
The highlight function of Lucene.NET is implemented by Lucene.NET.HighLight package and installed by NuGet manager. It is recommended to keep the same version as Lucene.NET.
1.2. Modify query method
Highlighting is a icing on the cake function, so it is planned to set whether to highlight as a configurable item of search input items. At the same time, the realization of highlighting function is also reflected in specific query methods.
Change the search input item SingleSearchOption to:
public class SingleSearchOption:SearchOptionBase
{
/// <summary>
///Search keywords
/// </summary>
public string Keyword { get; set; }
/// <summary>
///Restricted search domain
/// </summary>
public List<string> Fields { get; set; }
/// <summary>
///Highlight
/// </summary>
public bool IsHightLight { get; set; }
public SingleSearchOption(string keyword,List<string> fields,int maxHits=100,bool isHightLight=false)
{
if (string.IsNullOrWhiteSpace(keyword))
{
throw new ArgumentException("Search keyword cannot be empty");
}
Keyword = keyword;
Fields = fields;
MaxHits = maxHits;
IsHightLight = isHightLight;
}
}
The query method SingleSearch is modified to:
public SingleSearchResult SingleSearch(SingleSearchOption option)
{
SingleSearchResult result = new SingleSearchResult();
Stopwatch watch=Stopwatch.StartNew();
using (Lucene.Net.Index.DirectoryReader reader = DirectoryReader.Open(Directory))
{
//Instantiate index retriever
IndexSearcher searcher = new IndexSearcher(reader);
var queryParser = new MultiFieldQueryParser(LuceneVersion.LUCENE_48, option.Fields.ToArray(), Analyzer);
Query query = queryParser.Parse(option.Keyword);
var matches = searcher.Search(query, option.MaxHits).ScoreDocs;
#region highlight
QueryScorer scorer = new QueryScorer(query);
Highlighter highlighter = new Highlighter(scorer);
#endregion
result.TotalHits = matches.Count();
foreach (var match in matches)
{
var doc = searcher.Doc(match.Doc);
SearchResultItem item = new SearchResultItem();
item.Score = match.Score;
item.EntityId = doc.GetField(CoreConstant.EntityId).GetStringValue();
item.EntityName = doc.GetField(CoreConstant.EntityType).GetStringValue();
String storedField = doc.Get(option.Fields[0]);
if (option.IsHightLight)//Highlight
{
TokenStream stream = TokenSources.GetAnyTokenStream(reader, match.Doc, option.Fields[0], doc, Analyzer);
IFragmenter fragmenter = new SimpleSpanFragmenter(scorer);
highlighter.TextFragmenter = fragmenter;
string fragment = highlighter.GetBestFragment(stream, storedField);
item.FieldValue = fragment;
}
else
{
item.FieldValue = storedField;
}
result.Items.Add(item);
}
}
watch.Stop();
result.Elapsed = watch.ElapsedMilliseconds;
return result;
}
1.3. Highlight test example
The simple highlight function is modified. Use the web API interface to test it
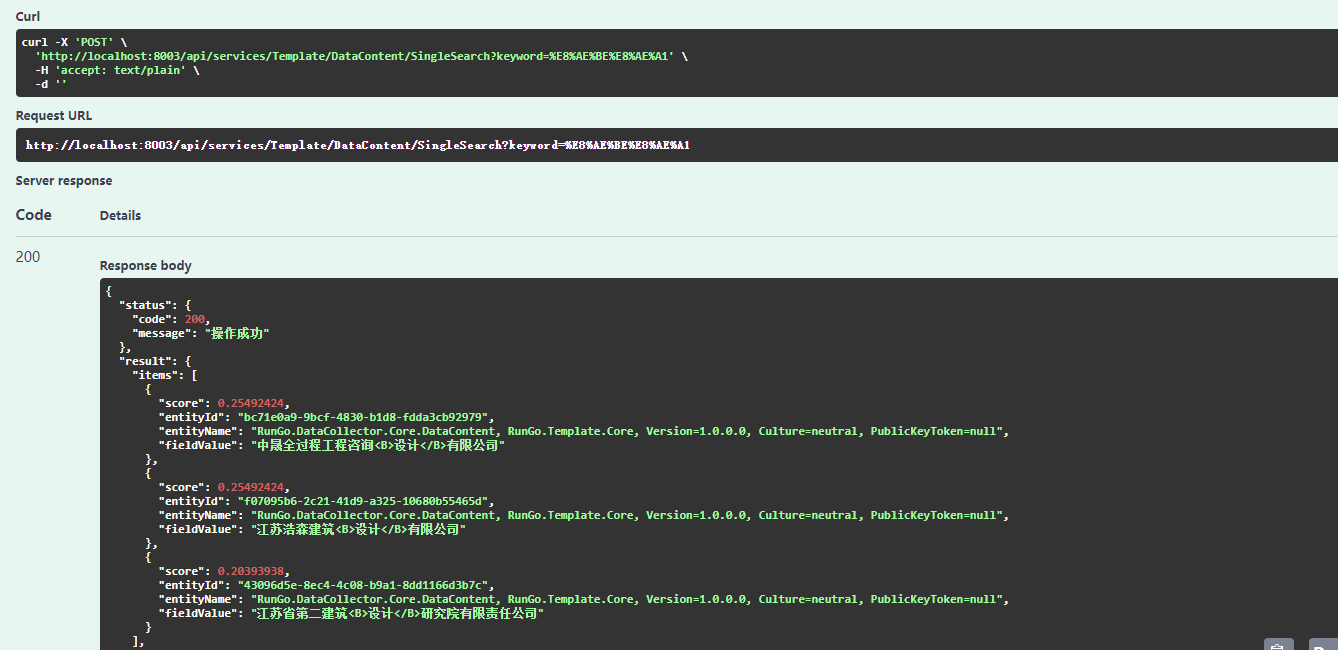
It can be seen from the returned results that the keyword "design" in the search results is labeled with "< / B / > < / / B / >".
2. Highlight function principle
In the above example, the simplest highlight effect of Lucene.NET is used. Its principle is not complex. Understanding its principle can also help us achieve more and richer effects. In short, it is to re process the query results, find the location of matching keywords, and add styles to rewrite the query results. The general process is as follows.
2.1.QueryScorer instantiation
QueryScorer scorer = new QueryScorer(query);
QueryScorer implements the Lucene.Net.Search.Highlight.IScorer interface to score text fragments according to the number of unique Query words found. The parameters of its constructor are the current Query example Query. In addition, the optional options are the IndexReader instance and the name of the Field to be highlighted.
public QueryScorer(Query query) => this.Init(query, (string) null, (IndexReader) null, true);
public QueryScorer(Query query, string field) => this.Init(query, field, (IndexReader) null, true);
public QueryScorer(Query query, IndexReader reader, string field) => this.Init(query, field, reader, true);
public QueryScorer(Query query, IndexReader reader, string field, string defaultField)
{
this.defaultField = defaultField.Intern();
this.Init(query, field, reader, true);
}
public QueryScorer(Query query, string field, string defaultField)
{
this.defaultField = defaultField.Intern();
this.Init(query, field, (IndexReader) null, true);
}
2.2.HighLighter instantiation
Highlighter highlighter = new Highlighter(scorer);
The HighLighter class can be seen from its name to highlight the corresponding item in the marked text.
public Highlighter(IScorer fragmentScorer)
: this((IFormatter) new SimpleHTMLFormatter(), fragmentScorer)
{
}
public Highlighter(IFormatter formatter, IScorer fragmentScorer)
: this(formatter, (IEncoder) new DefaultEncoder(), fragmentScorer)
{
}
public Highlighter(IFormatter formatter, IEncoder encoder, IScorer fragmentScorer)
{
this._formatter = formatter;
this._encoder = encoder;
this._fragmentScorer = fragmentScorer;
}
2.3. Get TokenStream
TokenStream can be said to be the core here. Through the previous Lucene.NET workflow, we know that the text will be divided into TokenStream, which records the location of each Token. Through TokenStream, you can quickly find the word segmentation that needs to add highlight effect.
TokenStream stream = TokenSources.GetAnyTokenStream(reader, match.Doc, option.Fields[0], doc, Analyzer);
Get the Token Stream corresponding to the current IndexReader, matching Document and Analyzer from the Token collection.
public static TokenStream GetAnyTokenStream(
IndexReader reader,
int docId,
string field,
Document doc,
Analyzer analyzer)
{
TokenStream tokenStream = (TokenStream) null;
Terms terms = reader.GetTermVectors(docId)?.GetTerms(field);
if (terms != null)
tokenStream = TokenSources.GetTokenStream(terms);
return tokenStream ?? TokenSources.GetTokenStream(doc, field, analyzer);
}
2.4. Setting Fragment
IFragmenter fragmenter = new SimpleSpanFragmenter(scorer); highlighter.TextFragmenter = fragmenter;
Instantiate a class that implements the IFragmenter interface to split text into fragments of different sizes instead of a single word.
/// <param name="queryScorer"><see cref="T:Lucene.Net.Search.Highlight.QueryScorer" /> that was used to score hits</param>
public SimpleSpanFragmenter(QueryScorer queryScorer)
: this(queryScorer, 100)
{
}
/// <param name="queryScorer"><see cref="T:Lucene.Net.Search.Highlight.QueryScorer" /> that was used to score hits</param>
/// <param name="fragmentSize">size in bytes of each fragment</param>
public SimpleSpanFragmenter(QueryScorer queryScorer, int fragmentSize)
{
this.fragmentSize = fragmentSize;
this.queryScorer = queryScorer;
}
2.5. Replace keyword style
String storedField = doc.Get(option.Fields[0]); string fragment = highlighter.GetBestFragment(stream, storedField);
The last step is to add the found keywords to the style.
public string[] GetBestFragments(TokenStream tokenStream, string text, int maxNumFragments)
{
maxNumFragments = Math.Max(1, maxNumFragments);
TextFragment[] bestTextFragments = this.GetBestTextFragments(tokenStream, text, true, maxNumFragments);
List<string> stringList = new List<string>();
for (int index = 0; index < bestTextFragments.Length; ++index)
{
if (bestTextFragments[index] != null && (double) bestTextFragments[index].Score > 0.0)
stringList.Add(bestTextFragments[index].ToString());
}
return stringList.ToArray();
}
Note: one thing to note in this process is that the Analyzer used - or further, the word breaker used - should be consistent. If you use different word splitters when creating indexes and queries, the keywords do not match the results. Needless to say, due to the difference of word segmentation results, the position of keywords will also be offset.