http://blog.csdn.net/runatworld/article/details/50774215
 Classification:
Classification:

Today, we talk about BP neural network. Neural network is based on BP neural network. machine learning It is widely used in many fields, such as function approximation, pattern recognition, classification, data compression and data processing.
Mining and other fields. Next, the principle and implementation of BP neural network are introduced.
Contents
1. Recognition of BP Neural Network
2. Selection of Implicit Layer
3. Forward Transfer Subprocesses
4. Reverse Transfer Subprocesses
5. Attentions of BP Neural Network
6. C++ Implementation of BP Neural Network
1. Recognition of BP Neural Network
Back Propagation neural network is divided into two processes
(1) Forward transmission sub-process of working signal
(2) Reverse transmission sub-process of error signal
In BP neural network, a single sample has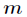 There are three inputs.
There are three inputs.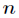 There are usually several hidden layers between the input layer and the output layer. Actual
There are usually several hidden layers between the input layer and the output layer. Actual
In 1989, Robert Hecht-Nielsen proved that a BP network with an implicit layer can be used for a continuous function in any closed interval.
This is the universal approximation theorem. So a three-layer BP network can accomplish arbitrary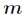 Dimension to
Dimension to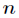 Dimensional mapping. That's the three layers.
Dimensional mapping. That's the three layers.
They are input layer (I), hidden layer (H), output layer (O). The following illustration
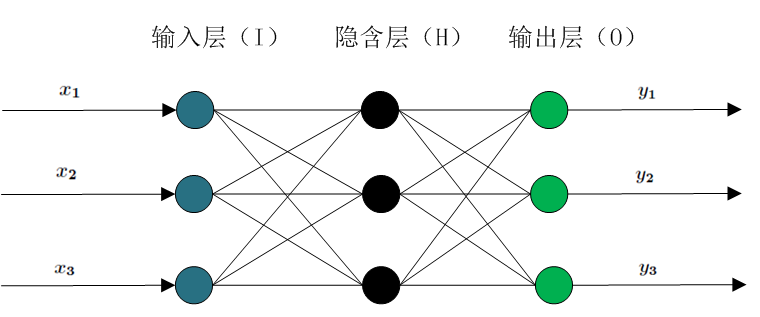
2. Selection of Implicit Layer
In BP neural network, the number of nodes in input layer and output layer is determined, while the number of nodes in hidden layer is uncertain, so how much should be set?
Is that right? In fact, the number of nodes in the hidden layer has an effect on the performance of the neural network. There is an empirical formula to determine the hidden layer.
The number of nodes is as follows
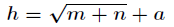
Among them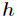 For the number of hidden layer nodes,
For the number of hidden layer nodes,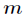 For the number of input layer nodes,
For the number of input layer nodes,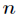 For the number of output layer nodes,
For the number of output layer nodes,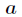 by
by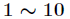 Adjustment constant between.
Adjustment constant between.
3. Forward Transfer Subprocesses
Nodes are now set up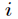 Node
Node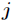 The weights between them are
The weights between them are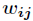 Node
Node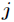 The threshold is
The threshold is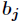 The output value of each node is
The output value of each node is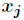 And the output of each node
And the output of each node
Value is based on the output value of all nodes in the upper layer, the weight value of the current node and all nodes in the upper layer, the threshold value of the current node and the activation function.
. The specific calculation method is as follows.
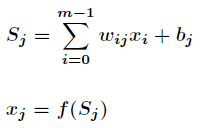
Among them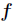 In order to activate function, S-type function or linear function are generally selected.
In order to activate function, S-type function or linear function are generally selected.
The forward transfer process is relatively simple and can be calculated according to the above formula. In BP neural network, the input layer node has no threshold.
4. Reverse Transfer Subprocesses
Back-propagation of error signal is a complex sub-process in BP neural network, which is based on Widrow-Hoff learning rules. Assumed output layer
All results are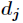 The error function is as follows
The error function is as follows
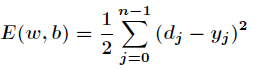
The main purpose of BP neural network is to revise weights and thresholds repeatedly so as to minimize the error function. Widrow-Hoff Learning Rules
By continuously adjusting the weights and thresholds of the network along the steepest descent direction of the sum of squares of relative errors, according to the gradient descent method, the weights vector
The correction is proportional to the gradient of E(w,b) at the current position, for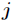 There are two output nodes.
There are two output nodes.
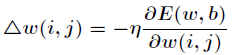
Suppose that the selected activation function is
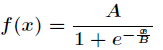
The derivative of activation function is obtained.
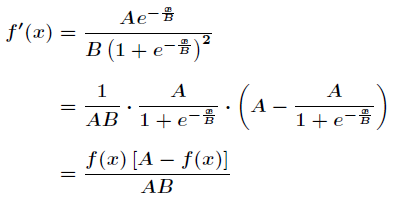
Next, we will focus on Yes
Yes
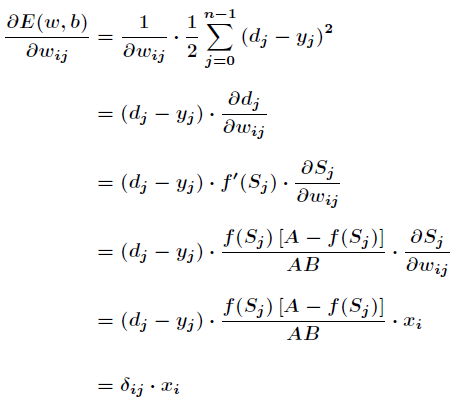
Among them are
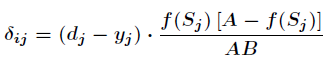
Similarly for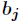 Yes
Yes
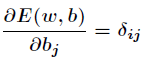
This is famous.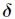 Learning rules reduce errors in the actual and expected output of the system by changing the connection weights between neurons.
Learning rules reduce errors in the actual and expected output of the system by changing the connection weights between neurons.
It is also called Widrow-Hoff learning rule or error-correcting learning rule.
The above is to calculate the adjustments of the weights between the hidden layer and the output layer, and the adjustments of the thresholds for the input layer, the hidden layer and the hidden layer.
Integer calculation is more complicated. hypothesis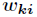 Is the weight between the k-th node of the input layer and the i-th node of the hidden layer, then there is
Is the weight between the k-th node of the input layer and the i-th node of the hidden layer, then there is
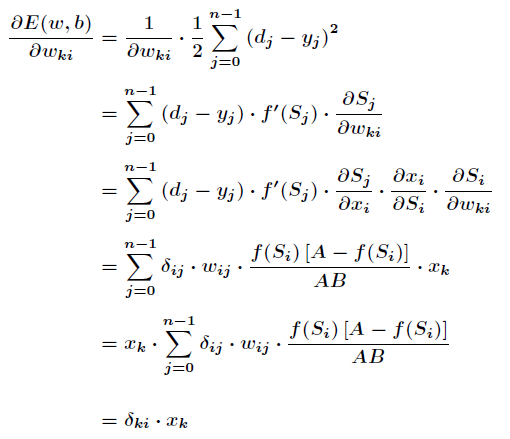
Among them are
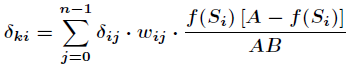
That's right.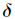 Learn rules more deeply.
Learn rules more deeply.
With the above formula, according to the gradient descent method, the weights and thresholds between the hidden layer and the output layer are adjusted as follows.
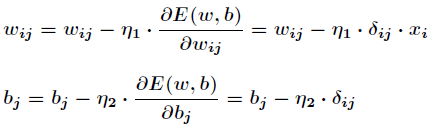
The weight and threshold adjustments between the input layer and the hidden layer are the same.
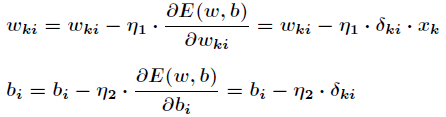
So far, the principle of BP neural network is basically finished.
5. Attentions of BP Neural Network
BP neural network is generally used to classify or approximate problems. If used for classification, the activation function usually chooses Sigmoid function or hard limit function.
Number, if used for function approximation, the output layer node uses a linear function, i.e.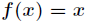 .
.
BP neural network can adopt incremental learning or batch learning when training data.
Incremental learning requires that the input mode should be random enough and sensitive to the noise of the input mode, that is, training for the input mode which changes dramatically.
The training effect is poor and suitable for on-line processing. Batch learning has no input mode order problem and good stability, but it is only suitable for offline processing.
Defects of standard BP neural network:
(1) It is easy to form local minima without obtaining global optimum.
There are many minimum values in BP neural network, so it is easy to fall into local minimum, which requires initial weights and thresholds.
The randomness of the initial weights and thresholds is good enough to be implemented randomly many times.
(2) The more training times, the lower learning efficiency and the slower convergence speed.
(3) The selection of hidden layer lacks theoretical guidance.
(4) There is a tendency to forget old samples when learning new samples during training.
BPalgorithm Improvement:
(1) Increasing momentum terms
The momentum term is introduced to accelerate the convergence of the algorithm, i.e. the following formula
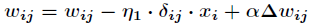
Momentum factor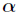 General selection
General selection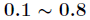 .
.
(2) Adaptive adjustment of learning rate
(3) introducing steepness factor
Normally, BP neural network normalizes the data before training, which maps the data into smaller intervals, such as [0,1] or [-1,1].
6. C++ Implementation of BP Neural Network
The C++ files of BP neural network are as follows

BP.h:
- #ifndef _BP_H_
- #define _BP_H_
- #include <vector>
- #define LAYER 3 // Three-Layer Neural Network
- #define NUM * 10 // Maximum number of nodes per layer
- #define A 30.0
- #define B. 10.0//A and B are parameters of S-type functions
- #define ITERS 1000 // Maximum number of training
- #define ETA_W 0.0035// Weight Adjustment Rate
- #define ETA_B 0.001//Threshold Adjustment Rate
- #define ERROR 0.002// Permissible Errors for a Single Sample
- #define ACCU 0.005// Permissible error per iteration
- #define Type double
- #define Vector std::vector
- struct Data
- {
- Vector<Type> x; //Input data
- Vector<Type> y; //output data
- };
- class BP{
- public:
- void GetData(const Vector<Data>);
- void Train();
- Vector<Type> ForeCast(const Vector<Type>);
- private:
- void InitNetWork(); //Initialize the network
- void GetNums(); //Get the number of input, output, and hidden layer nodes
- void ForwardTransfer(); //Forward Propagator Subprocess
- void ReverseTransfer(int); //Reverse Propagation Subprocess
- void CalcDelta(int); //Calculate the adjustments of w and b
- void UpdateNetWork(); //Update weights and thresholds
- Type GetError(int); //Calculating the Error of a Single Sample
- Type GetAccu(); //Calculating the Accuracy of All Samples
- Type Sigmoid(const Type); //Calculate the value of Sigmoid
- private:
- int in_num; //Number of input layer nodes
- int ou_num; //Number of Output Layer Nodes
- int hd_num; //Number of Hidden Layer Nodes
- Vector<Data> data; //Input and output data
- Type w[LAYER][NUM][NUM]; //Weights of BP Network
- Type b[LAYER][NUM]; //Threshold of BP Network Node
- Type x[LAYER][NUM]; //The output value of each neuron is transformed by S-type function, and the input layer is the original value.
- Type d[LAYER][NUM]; //Record the value of delta in delta learning rules
- };
- #endif //_BP_H_
BP.cpp:
- #include <string.h>
- #include <stdio.h>
- #include <math.h>
- #include <assert.h>
- #include "BP.h"
- //Obtain all training sample data
- void BP::GetData(const Vector<Data> _data)
- {
- data = _data;
- }
- //Start training
- void BP::Train()
- {
- printf("Begin to train BP NetWork!\n");
- GetNums();
- InitNetWork();
- int num = data.size();
- for(int iter = 0; iter <= ITERS; iter++)
- {
- for(int cnt = 0; cnt < num; cnt++)
- {
- //Layer 1 input node assignment
- for(int i = 0; i < in_num; i++)
- x[0][i] = data.at(cnt).x[i];
- while(1)
- {
- ForwardTransfer();
- if(GetError(cnt) < ERROR) //If the error is small, jump out of the loop for a single sample
- break;
- ReverseTransfer(cnt);
- }
- }
- printf("This is the %d th trainning NetWork !\n", iter);
- Type accu = GetAccu();
- printf("All Samples Accuracy is %lf\n", accu);
- if(accu < ACCU) break;
- }
- printf("The BP NetWork train End!\n");
- }
- //Predict the output value according to the trained network
- Vector<Type> BP::ForeCast(const Vector<Type> data)
- {
- int n = data.size();
- assert(n == in_num);
- for(int i = 0; i < in_num; i++)
- x[0][i] = data[i];
- ForwardTransfer();
- Vector<Type> v;
- for(int i = 0; i < ou_num; i++)
- v.push_back(x[2][i]);
- return v;
- }
- //Get the number of network nodes
- void BP::GetNums()
- {
- in_num = data[0].x.size(); //Get the number of input layer nodes
- ou_num = data[0].y.size(); //Get the number of output layer nodes
- hd_num = (int)sqrt((in_num + ou_num) * 1.0) + 5; //Getting Number of Hidden Layer Nodes
- if(hd_num > NUM) hd_num = NUM; //The number of hidden layers should not exceed the maximum setting
- }
- //Initialize the network
- void BP::InitNetWork()
- {
- memset(w, 0, sizeof(w)); //Initialization weights and thresholds are 0, and random values can also be initialized.
- memset(b, 0, sizeof(b));
- }
- //Forward transmission sub-process of working signal
- void BP::ForwardTransfer()
- {
- //Calculating the Output Values of the Nodes in the Hidden Layer
- for(int j = 0; j < hd_num; j++)
- {
- Type t = 0;
- for(int i = 0; i < in_num; i++)
- t += w[1][i][j] * x[0][i];
- t += b[1][j];
- x[1][j] = Sigmoid(t);
- }
- //Calculate the output value of each node in the output layer
- for(int j = 0; j < ou_num; j++)
- {
- Type t = 0;
- for(int i = 0; i < hd_num; i++)
- t += w[2][i][j] * x[1][i];
- t += b[2][j];
- x[2][j] = Sigmoid(t);
- }
- }
- //Calculating the Error of a Single Sample
- Type BP::GetError(int cnt)
- {
- Type ans = 0;
- for(int i = 0; i < ou_num; i++)
- ans += 0.5 * (x[2][i] - data.at(cnt).y[i]) * (x[2][i] - data.at(cnt).y[i]);
- return ans;
- }
- //Error Signal Reverse Transfer Subprocess
- void BP::ReverseTransfer(int cnt)
- {
- CalcDelta(cnt);
- UpdateNetWork();
- }
- //Calculating the Accuracy of All Samples
- Type BP::GetAccu()
- {
- Type ans = 0;
- int num = data.size();
- for(int i = 0; i < num; i++)
- {
- int m = data.at(i).x.size();
- for(int j = 0; j < m; j++)
- x[0][j] = data.at(i).x[j];
- ForwardTransfer();
- int n = data.at(i).y.size();
- for(int j = 0; j < n; j++)
- ans += 0.5 * (x[2][j] - data.at(i).y[j]) * (x[2][j] - data.at(i).y[j]);
- }
- return ans / num;
- }
- //Calculate adjustment
- void BP::CalcDelta(int cnt)
- {
- //Calculating delta Value of Output Layer
- for(int i = 0; i < ou_num; i++)
- d[2][i] = (x[2][i] - data.at(cnt).y[i]) * x[2][i] * (A - x[2][i]) / (A * B);
- //Calculating delta Value of Implicit Layer
- for(int i = 0; i < hd_num; i++)
- {
- Type t = 0;
- for(int j = 0; j < ou_num; j++)
- t += w[2][i][j] * d[2][j];
- d[1][i] = t * x[1][i] * (A - x[1][i]) / (A * B);
- }
- }
- //Adjust BP network according to the calculated adjustment amount
- void BP::UpdateNetWork()
- {
- //Weight and Threshold Adjustment Between Implicit Layer and Output Layer
- for(int i = 0; i < hd_num; i++)
- {
- for(int j = 0; j < ou_num; j++)
- w[2][i][j] -= ETA_W * d[2][j] * x[1][i];
- }
- for(int i = 0; i < ou_num; i++)
- b[2][i] -= ETA_B * d[2][i];
- //Weight and Threshold Adjustment Between Input Layer and Implicit Layer
- for(int i = 0; i < in_num; i++)
- {
- for(int j = 0; j < hd_num; j++)
- w[1][i][j] -= ETA_W * d[1][j] * x[0][i];
- }
- for(int i = 0; i < hd_num; i++)
- b[1][i] -= ETA_B * d[1][i];
- }
- //Calculating the value of Sigmoid function
- Type BP::Sigmoid(const Type x)
- {
- return A / (1 + exp(-x / B));
- }
Test.cpp:
- #include <iostream>
- #include <string.h>
- #include <stdio.h>
- #include "BP.h"
- using namespace std;
- double sample[41][4]=
- {
- {0,0,0,0},
- {5,1,4,19.020},
- {5,3,3,14.150},
- {5,5,2,14.360},
- {5,3,3,14.150},
- {5,3,2,15.390},
- {5,3,2,15.390},
- {5,5,1,19.680},
- {5,1,2,21.060},
- {5,3,3,14.150},
- {5,5,4,12.680},
- {5,5,2,14.360},
- {5,1,3,19.610},
- {5,3,4,13.650},
- {5,5,5,12.430},
- {5,1,4,19.020},
- {5,1,4,19.020},
- {5,3,5,13.390},
- {5,5,4,12.680},
- {5,1,3,19.610},
- {5,3,2,15.390},
- {1,3,1,11.110},
- {1,5,2,6.521},
- {1,1,3,10.190},
- {1,3,4,6.043},
- {1,5,5,5.242},
- {1,5,3,5.724},
- {1,1,4,9.766},
- {1,3,5,5.870},
- {1,5,4,5.406},
- {1,1,3,10.190},
- {1,1,5,9.545},
- {1,3,4,6.043},
- {1,5,3,5.724},
- {1,1,2,11.250},
- {1,3,1,11.110},
- {1,3,3,6.380},
- {1,5,2,6.521},
- {1,1,1,16.000},
- {1,3,2,7.219},
- {1,5,3,5.724}
- };
- int main()
- {
- Vector<Data> data;
- for(int i = 0; i < 41; i++)
- {
- Data t;
- for(int j = 0; j < 3; j++)
- t.x.push_back(sample[i][j]);
- t.y.push_back(sample[i][3]);
- data.push_back(t);
- }
- BP *bp = new BP();
- bp->GetData(data);
- bp->Train();
- while(1)
- {
- Vector<Type> in;
- for(int i = 0; i < 3; i++)
- {
- Type v;
- scanf("%lf", &v);
- in.push_back(v);
- }
- Vector<Type> ou;
- ou = bp->ForeCast(in);
- printf("%lf\n", ou[0]);
- }
- return 0;
- }
Makefile:
- Test : BP.h BP.cpp Test.cpp
- g++ BP.cpp Test.cpp -o Test
- clean:
- rm Test