[bloom filter] I
One of the solutions to cache penetration is the bloom filter
Cache penetration: refers to data that does not exist in the cache or database, but users constantly initiate requests, such as data with id "- 1" or other nonexistent data. At this time, the user is likely to be an attacker, and the attack will lead to excessive pressure on the database.
Bloom Filter
Bloom Filter was proposed by a young man named bloom in 1970.
It is actually a long binary vector and a series of random mapping functions. The binary stored data is either 0 or 1, and the default is 0.
It is mainly used to judge whether a data is in a set. 0 means nonexistence and 1 means existence.

Purpose of Bloom filter
-
Solve Redis cache penetration (this article focuses on)
-
When crawling, filter the crawler website. The website already exists in bloom and is not crawling.
-
Spam filtering determines whether each email address is in Bloom's blacklist. If it is, it will be judged as spam.
-
......
Principle of Bloom filter
Deposit process
When a data is added to this collection, it experiences the following baptism (there are disadvantages here, which will be described below):
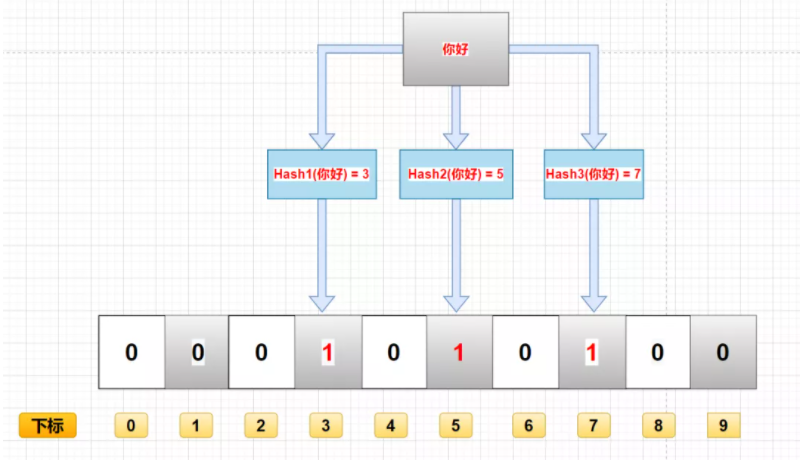
- Calculate the data through k hash functions and return K calculated hash values
- These k hash values are mapped to the corresponding K binary array subscripts
- Change the binary data corresponding to K subscripts to 1.
For example, if the first hash function returns x, the second and third hash functions return y and Z, then the binary corresponding to x, y and Z is changed to 1. As shown in the figure:
Query process
The main function of Bloom filter is to query a data. If it is not in this binary set, the query process is as follows:
-
The data is calculated through K hash functions, corresponding to the calculated K hash values
-
Find the corresponding binary array index through the hash value
-
Judgment: if the binary data corresponding to a subscript is 0, the data does not exist. If they are all 1, the data exists in the collection. (there are shortcomings here, which will be discussed below)
You can determine whether there is a binary data of 0 by multiplication.
Delete process
Generally, the data in the bloom filter cannot be deleted, which is one of the disadvantages, which will be analyzed below.
Advantages and disadvantages of Bloom filter
advantage
- Because binary data is stored, the space occupied is very small
- Its insertion and query speed is very fast, and the time complexity is O (K). You can think of the process of HashMap
- Confidentiality is very good, because it does not store any original data, only binary data
shortcoming
If you add data by calculating the hash value of the data, it is likely that two different data get the same hash value. Hash conflict.
For example, "hello" and "hello" in the figure, if they finally calculate that the hash value is the same, they will change the binary data of the same subscript to 1. At this time, you don't know whether the binary with subscript 2 represents "hello" or "hello".
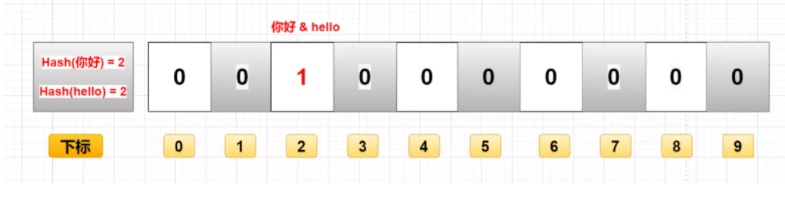
- Misjudgment: if the above figure does not save "hello" but only "hello", then when querying with "hello", it will be judged that "hello" exists in the set. Because the hash values of "hello" and "hello" are the same, the binary data found through the same hash value is also the same, which is 1.
- Deletion difficulty: because the hash values of "hello" and "hello" are the same, the corresponding array subscripts are the same. At this time, if you want to delete "hello", change the binary data in subscript 2 from 1 to 0. As a result, we deleted "hello" together. (0 means there is this data, 1 means there is no this data)
Realize bloom filter
There are many implementation methods, one of which is the implementation method provided by Guava.
1, Introduction of Guava pom configuration
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>29.0-jre</version> </dependency>
2, Code implementation
Note: there is a misjudgment rate in the bloom filter, which can be set manually. The smaller the misjudgment rate, the larger the memory occupation and hash calculation time
package cn.lxiaol.www.bloomfilter;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class BloomFilterCase {
/**
* How much data is expected to be stored
*/
private static final int size = 1000000;
/**
* Expected misjudgment rate
*/
private static double fpp = 0.01;
/**
* Bloom filter
*/
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, fpp);
private static final int total = 1000000;
public static void main(String[] args) {
// Insert 1 million sample data
for (int i = 0; i < total; i++) {
bloomFilter.put(i);
}
//Use another 100000 to test the misjudgment rate
int count = 0;
for (int i = total; i < total+100000; i++) {
if(bloomFilter.mightContain(i)){
count++;
System.out.println(i+"Misjudged");
}
}
System.out.println("Total misjudgments:"+count);
System.out.println("fpp: " + 1.0 * count / 100000);
}
}
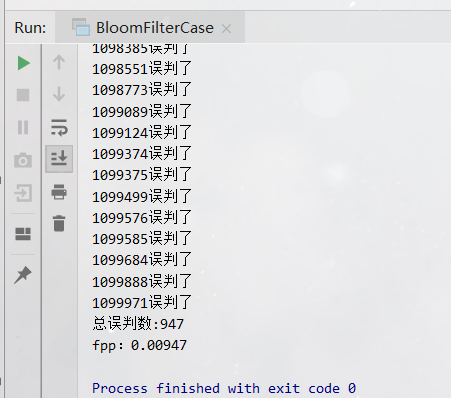 There are 947 misjudgments in 100000 data, which is about equal to the misjudgment rate set in our code: fpp = 0.01.
There are 947 misjudgments in 100000 data, which is about equal to the misjudgment rate set in our code: fpp = 0.01.
Deep analysis of code
@VisibleForTesting
static <T> BloomFilter<T> create(Funnel<? super T> funnel, long expectedInsertions,
double fpp, BloomFilter.Strategy strategy) {
Preconditions.checkNotNull(funnel);
Preconditions.checkArgument(expectedInsertions >= 0L, "Expected insertions (%s) must be >= 0", expectedInsertions);
Preconditions.checkArgument(fpp > 0.0D, "False positive probability (%s) must be > 0.0", fpp);
Preconditions.checkArgument(fpp < 1.0D, "False positive probability (%s) must be < 1.0", fpp);
Preconditions.checkNotNull(strategy);
if (expectedInsertions == 0L) {
expectedInsertions = 1L;
}
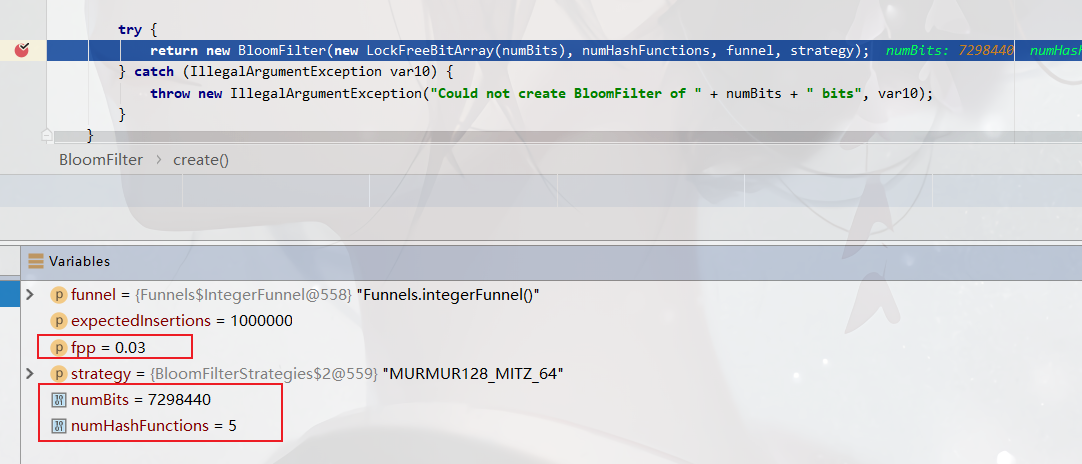
long numBits = optimalNumOfBits(expectedInsertions, fpp);
int numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits);
try {
return new BloomFilter(new LockFreeBitArray(numBits), numHashFunctions, funnel, strategy);
} catch (IllegalArgumentException var10) {
throw new IllegalArgumentException("Could not create BloomFilter of " + numBits + " bits", var10);
}
}
There are four parameters:
- funnel: data type (usually in Funnels tool class)
- Expected inserts: the number of values expected to be inserted
- fpp: misjudgment rate (the default value is 0.03)
- strategy: hash algorithm
Let's focus on fpp parameters
fpp misjudgment rate
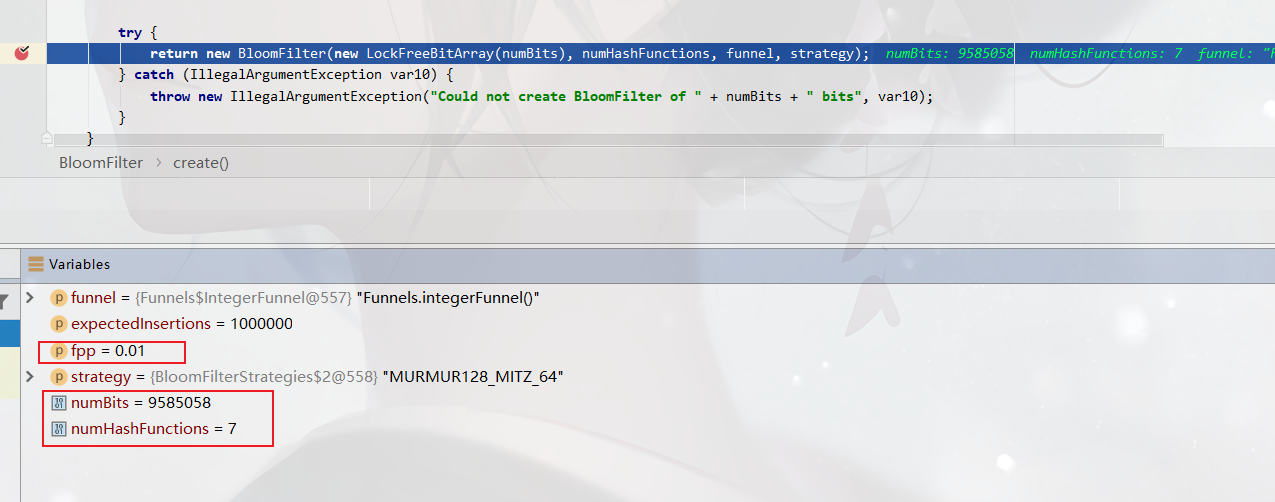
Scenario 1: fpp = 0.01
-
Number of misjudgments: 947
-
Memory size: 9585058 digits
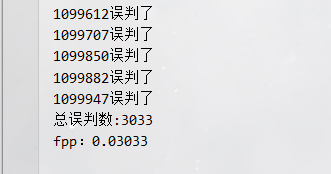
Scenario 2: fpp = 0.03 (default parameter)
-
Number of misjudgments: 3033
-
Memory size: 7298440 digits
Scenario summary
- The misjudgment rate can be adjusted by fpp parameters
- The smaller the fpp, the larger the memory space required: 0.01 needs more than 9 million bits, and 0.03 needs more than 7 million bits.
- The smaller the fpp, the more hash functions are needed to calculate more hash values to store in the corresponding array subscript when adding data to the set. (I forgot to look at the process of bron filtering and storing data above)
The numBits above means to save one million int type numbers, and the number of bits required is more than 72984407 million. Theoretically, there are one million numbers stored. An int is 4 bytes and 32 bits. It needs 481000000 = 32 million bits. If HashMap is used for storage, 64 million bits are required according to the storage efficiency of 50% of HashMap. It can be seen that the storage space of BloomFilter is very small, only about 1 / 10 of that of HashMap
The above numHashFunctions indicate that several hash function operations are required to map whether these numbers exist in different subscripts (0 or 1).
Solve Redis cache avalanche
The bloom filter implemented above using Guava puts the data in local memory. Distributed scenarios are not suitable, and memory cannot be shared.
We can also use Redis to implement bloom filter. Here, redison, a client tool encapsulated by Redis, is used.
The bottom layer uses the data structure bitMap, which is understood as the binary structure mentioned above.
code implementation
pom configuration:
<dependency> <groupId>org.redisson</groupId> <artifactId>redisson-spring-boot-starter</artifactId> <version>3.13.4</version> </dependency>
java code:
package cn.lxiaol.www.bloomfilter;
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
public class RedissonBloomFilter {
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:2020");
config.useSingleServer().setPassword("yiguan789");
// Construct redis
RedissonClient redissonClient = Redisson.create(config);
// Get the bloom filter and give it a name, nickNameList
RBloomFilter<Object> bloomFilter = redissonClient.getBloomFilter("nickNameList");
// Initialize the filter, the expected element is 1 million, the error rate is 3%, and the default is 3%
bloomFilter.tryInit(1000000, 0.03);
//Insert the nickname "pedal old prince" into the filter
bloomFilter.add("Pedal old prince");
//Determine whether the following nicknames are in the bloom filter
//Output false
System.out.println(bloomFilter.contains("Captain Carter"));
//Output true
System.out.println(bloomFilter.contains("Pedal old prince"));
redissonClient.shutdown();
}
}