1, Demand scenario analysis
In the actual operation and management process of data platform, the scale of data table tends to grow to a very large scale with the access of more business data and the construction of data application. Data managers often hope to use the analysis of metadata to better grasp the kinship of different data tables, so as to analyze the upstream and downstream dependency of data.
This article introduces how to analyze the blood relationship of a table according to the input and output table of job ID in maxcompute information schema.
2, Scheme design ideas
Maxcompute information schema provides the task history of the job detail data of the access table, which contains the upstream and downstream dependency of the job ID, input tables, and output tables fields. According to these three fields, the blood relationship of the table is statistically analyzed
1. According to the job history of a certain day, obtain the details of the input table, output table and job ID fields in the tasks history table, and then analyze and count the upstream and downstream dependency of each table in a certain period of time.
2. According to the upstream and downstream dependence of the table, the relationship of bleeding margin was inferred.
3, Scheme implementation method
Refer to example 1:
(1) Query the upstream and downstream dependent SQL processing of a table according to the job ID as follows:
select t2.input_table, t1.inst_id, replace(replace(t1.output_tables,"[",""),"]","") as output_table from information_schema.tasks_history t1 left join ( select ---Remove table start and end[ ] trans_array(1,",",inst_id, replace(replace(input_tables,"[",""),"]","")) as (inst_id,input_table) from information_schema.tasks_history where ds = 20190902 )t2 on t1.inst_id = t2.inst_id where (replace(replace(t1.output_tables,"[",""),"]","")) <> "" order by t2.input_table limit 1000;
The results are as follows:
(2) According to the results, we can get the input table output table and the connected job ID of each table, that is, the blood relationship of each table.
The blood relationship map is as follows: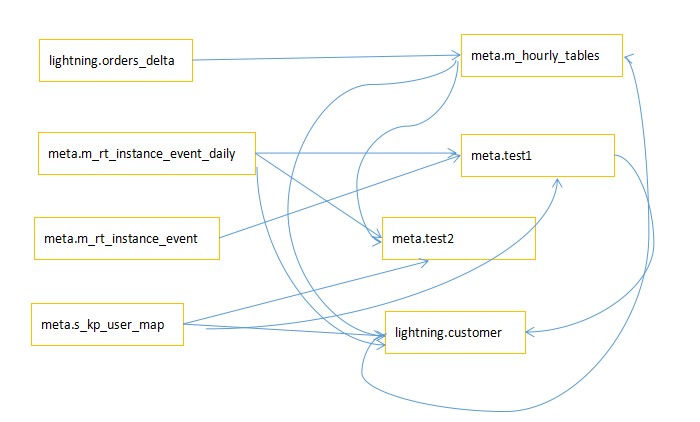
The middle line is the job ID, the starting line is the input table, and the direction indicated by the arrow is the output table.
Refer to example 2:
The following way is to analyze blood relationship by setting partition and combining DataWorks:
(1) Design storage result table Schema
CREATE TABLE IF NOT EXISTS dim_meta_tasks_history_a ( stat_date STRING COMMENT 'Date of Statistics', project_name STRING COMMENT 'entry name', task_id STRING COMMENT 'task ID', start_time STRING COMMENT 'start time', end_time STRING COMMENT 'End time', input_table STRING COMMENT 'Input table', output_table STRING COMMENT 'Output table', etl_date STRING COMMENT 'ETL Running time' );
(2) Key parsing sql
SELECT '${yesterday}' AS stat_date ,'project_name' AS project_name ,a.inst_id AS task_id ,start_time AS start_time ,end_time AS end_time ,a.input_table AS input_table ,a.output_table AS output_table ,GETDATE() AS etl_date FROM ( SELECT t2.input_table ,t1.inst_id ,replace(replace(t1.input_tables,"[",""),"]","") AS output_table ,start_time ,end_time FROM ( SELECT * ,ROW_NUMBER() OVER(PARTITION BY output_tables ORDER BY end_time DESC) AS rows FROM information_schema.tasks_history WHERE operation_text LIKE 'INSERT OVERWRITE TABLE%' AND ( start_time >= TO_DATE('${yesterday}','yyyy-mm-dd') and end_time <= DATEADD(TO_DATE('${yesterday}','yyyy-mm-dd'),8,'hh') ) AND(replace(replace(output_tables,"[",""),"]",""))<>"" AND ds = CONCAT(SUBSTR('${yesterday}',1,4),SUBSTR('${yesterday}',6,2),SUBSTR('${yesterday}',9,2)) )t1 LEFT JOIN( SELECT TRANS_ARRAY(1,",",inst_id,replace(replace(input_tables,"[",""),"]","")) AS (inst_id,input_table) FROM information_schema.tasks_history WHERE ds = CONCAT(SUBSTR('${yesterday}',1,4),SUBSTR('${yesterday}',6,2),SUBSTR('${yesterday}',9,2)) )t2 ON t1.inst_id = t2.inst_id where t1.rows = 1 ) a WHERE a.input_table is not null ;
(3) Task dependency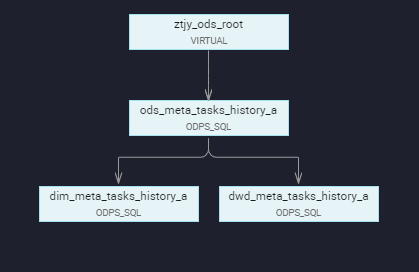
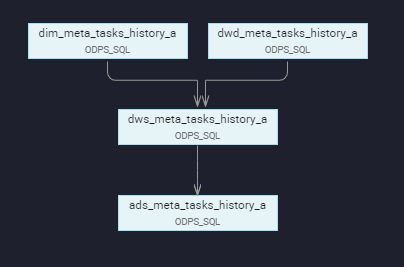
(4) Ultimate kinship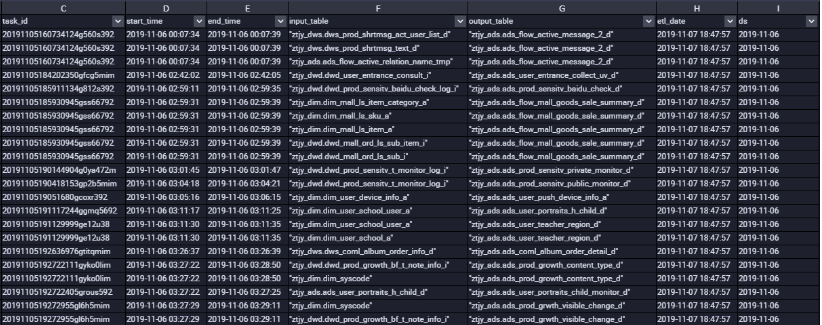
The above blood relationship analysis is based on their own thinking and practice to complete. Real business scenarios need to be verified together. So I hope that you can make corresponding sql changes according to your business needs if you need. If there is any improper handling, I hope to give more advice. I'm making adjustments.
This article is Alibaba cloud content and cannot be reproduced without permission.