####Detailed notes on springboot
Details: https://www.cnblogs.com/swzx-1213/p/12781836.html
1, Using aop log management: Blog AOP details
1. Import dependency
<!--Log dependency-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.32</version>
</dependency>
<!--Slice dependence-->
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
<version>1.8.4</version>
</dependency>
2. Set section
@org.aspectj.lang.annotation.Aspect
@Component
public class Aspect {
private Logger logger = LoggerFactory.getLogger(this.getClass());
//Define pointcuts
@Pointcut("execution(* com.yan.yong.controller.*.*(..))")
public void log(){}
@Before("log()")
public void doBefore(JoinPoint joinPoint){
ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
HttpServletRequest request = attributes.getRequest();
logger.info("--------before------------");
// Record the request
// logger.info("URL : " + request.getRequestURL().toString());
// logger.info("HTTP_METHOD : " + request.getMethod());
// logger.info("IP : " + request.getRemoteAddr());
logger.info("URL: {},HTTP_METHOD : {},IP : {}",request.getRequestURL().toString(),request.getMethod(),request.getRemoteAddr());
Enumeration<String> enu = request.getParameterNames();
while (enu.hasMoreElements()) {
String name = (String) enu.nextElement();
logger.info("name:{},value:{}", name, request.getParameter(name));
}
}
//Get return value
@AfterReturning(returning = "result",pointcut = "log()")
public void lkj(Object result){
logger.info("result Is:{}",result);
}
@After("log()")
public void after(){
logger.info("------------after---------");
}
}
2, Global exception handling (MVC Architecture)
1. Notes used:
@Component will inject the global exception class into the IOC container
@ControllerAdvice comments on global exception handling
@ExceptionHandler handles certain types of exceptions uniformly
@Component
@ControllerAdvice
public class ControllerExceptionHandler {
private Logger logger = LoggerFactory.getLogger(this.getClass());
@ExceptionHandler(Exception.class)
public ModelAndView handler(HttpServletRequest request,Exception e)throws Exception {
logger.error("URL : {},exceptinMessage :{}",request.getRequestURL(),e.getMessage());
ModelAndView mv = new ModelAndView();
mv.addObject("exception",e);//Return the exception information to the front page
mv.setViewName("error/error");
return mv;
}
}
Front end reception (you can view the exception information by viewing the source code)
<!DOCTYPE html>
<html lang="en" xmlns:th="http://www.thymeleaf.ory">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
error
<!--Receive exception information-->
<div>
<div th:utext="'<!--'" th:remove="tag"></div>
<div th:utext="'Failed Request URL : ' + ${url}" th:remove="tag"></div>
<div th:utext="'Exception message : ' + ${exception.message}" th:remove="tag"></div>
<ul th:remove="tag">
<li th:each="st : ${exception.stackTrace}" th:remove="tag"><span th:utext="${st}" th:remove="tag"></span></li>
</ul>
<div th:utext="'-->'" th:remove="tag"></div>
</div>
</body>
</html>
3, Global exception handling (front and rear end separation)
In the mvc architecture project, the server and client can directly map html, and can also directly return exception information to the client. With the continuous updating and iteration of technology, in order to reduce the coupling between the front and rear ends, the era of front-end and rear-end separation project is opened. At this time, we send a request to the back end. If there is any exception information, we need to use the global exception handling provided by springboot at the back end. After obtaining the exception information, we will uniformly send the exception information to the front end in json format.
Key grasp
1. Unified construction idea of returned information class
2.404 abnormal judgment
3. Custom exception
4. Manually configure the spingboot capture 404
1. Construct a class that returns "status code", "exception information" and "data"
package com.yan.yong.utils;
import com.yan.yong.handler.DefindException;
import java.util.HashMap;
import java.util.Map;
public class Msg {
private Integer code;
private String message;
Map<String,Object> map = new HashMap<>();
//json data returned successfully and normally
public static Msg success(){
Msg msg = new Msg();
msg.setCode(200);
msg.setMessage("Operation succeeded");
return msg;
}
//Failed to return json data normally
public static Msg fail(){
Msg msg = new Msg();
msg.setCode(200);
msg.setMessage("Operation succeeded");
return msg;
}
//Return the obtained data
public Msg sendData(String detail,Object object){
Map<String,Object> map = this.map;
map.put(detail,object);
return this;
}
//Return prompt information of custom exception
public static Msg defindException(DefindException e){
Msg msg = new Msg();
msg.setCode(e.getCode());
msg.setMessage(e.getMessage());
return msg;
}
//Return the prompt information of default exception
public static Msg defaultException(Integer code,Exception e){
Msg msg = new Msg();
msg.setCode(code);
msg.setMessage(e.getMessage());
return msg;
}
public Map<String, Object> getMap() {
return map;
}
public void setMap(Map<String, Object> map) {
this.map = map;
}
public Integer getCode() {
return code;
}
public void setCode(Integer code) {
this.code = code;
}
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
}
2. Custom exception class
package com.yan.yong.handler;
public class DefindException extends RuntimeException{
private Integer code;
private String message;
public DefindException(Integer code,String message){
this.code = code;
this.message = message;
}
public Integer getCode() {
return code;
}
@Override
public String getMessage() {
return message;
}
}
3. Handle global exceptions
@Component
@ControllerAdvice
public class ControllerExceptionHandler {
//Console print log
private Logger logger = LoggerFactory.getLogger(this.getClass());
//Automatically collect custom exceptions
@ExceptionHandler(DefindException.class)
@ResponseBody
public Msg defind(HttpServletRequest request, DefindException e){
logger.info("URL : {}; errorMessage : {}",request.getRequestURL(),e.getMessage());
return Msg.defindException(e);
}
//Automatically collect default exceptions
@ExceptionHandler(Exception.class)
@ResponseBody
public Msg defind(HttpServletRequest request,Exception e){
logger.info("URL : {}; errorMessage : {}",request.getRequestURL(),e.getMessage());
if (e instanceof NoHandlerFoundException){
return Msg.defaultException(404,e);
}else {
return Msg.defaultException(500,e);
}
}
}
4.controller layer test
@org.springframework.stereotype.Controller
public class Controller {
@Autowired
private Service service;
//Test 500 error
@GetMapping("/")
public String index(){
int i = 5/0;
return "index";
}
//Test custom exception
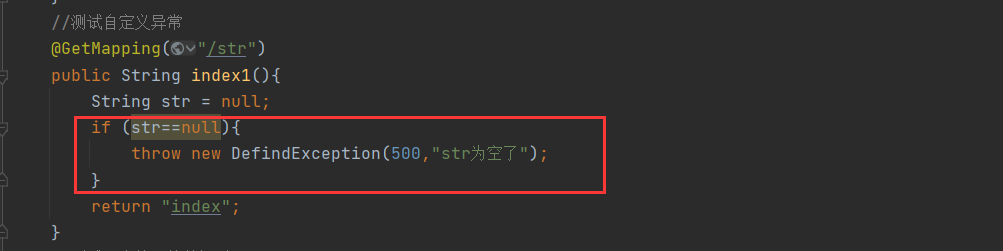
@GetMapping("/str")
public String index1(){
String str = null;
if (str==null){
throw new DefindException(500,"str Is empty");
}
return "index";
}
//Test normal data return
@GetMapping("/data")
@ResponseBody
public Msg index2(){
int a[][]= new int[2][3];
for (int i=0;i<2;i++){
for (int j=0;j<3;j++){
a[i][j]=(int)(Math.random()*10+1);
}
}
return Msg.success().sendData("data",a);
}
5. Precautions
Since springboot does not automatically intercept 404 exceptions, it needs to be configured manually
spring.mvc.throw-exception-if-no-handler-found=true spring.web.resources.add-mappings=false
6. Test
1. Test 500 running error

2. Test custom exception

3. Test the return of normal data

4. Test 404 is abnormal

4, Configuration swagger of interface document: details
1. Introduce dependency
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>2.9.2</version>
</dependency>
2. Precautions:
(1) In global exception handling, the interception configuration of 404 will make static resources inaccessible
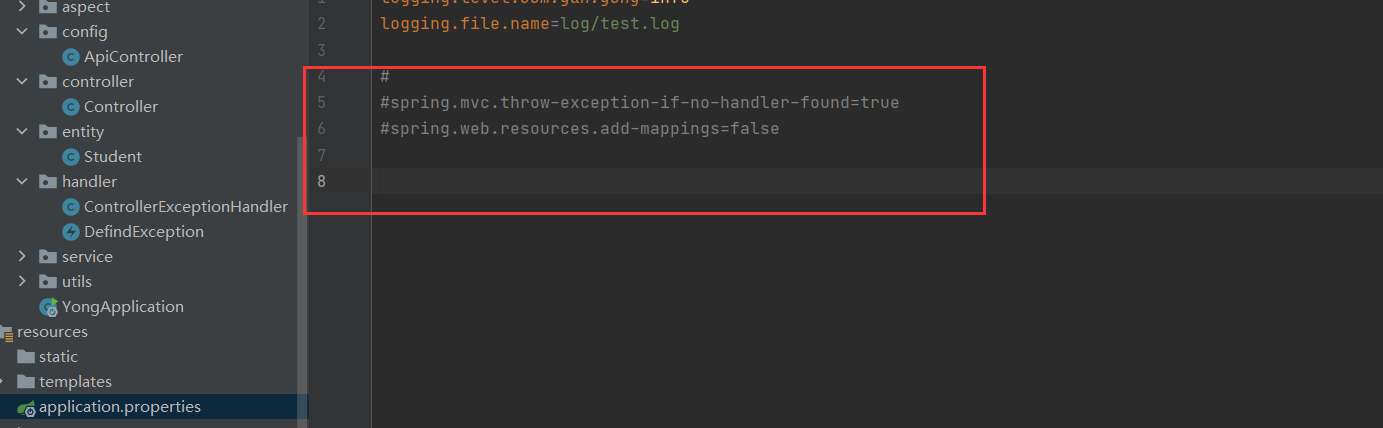
(2) If you cannot access it, you can add the following code to the swagger configuration
public void addResourceHandlers(ResourceHandlerRegistry registry) {
registry.addResourceHandler("swagger-ui.html")
.addResourceLocations("classpath:/META-INF/resources/");
registry.addResourceHandler("/webjars/**")
.addResourceLocations("classpath:/META-INF/resources/webjars/");
}
3. Write swagger configuration class
package com.yan.yong.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.ResourceHandlerRegistry;
import springfox.documentation.builders.ApiInfoBuilder;
import springfox.documentation.builders.PathSelectors;
import springfox.documentation.builders.RequestHandlerSelectors;
import springfox.documentation.service.ApiInfo;
import springfox.documentation.spi.DocumentationType;
import springfox.documentation.spring.web.plugins.Docket;
import springfox.documentation.swagger2.annotations.EnableSwagger2;
@Configuration
@EnableSwagger2
public class ApiController {
@Bean
public Docket createRestApi() {
return new Docket(DocumentationType.SWAGGER_2)
// Specify how to build the details of the api document: apiInfo()
.apiInfo(apiInfo())
.select()
// Specifies the package path to generate the api interface
.apis(RequestHandlerSelectors.basePackage("com.yan.yong.controller"))
//Use the @ ApiOperation annotation method to generate api interface documents
//.apis(RequestHandlerSelectors.withMethodAnnotation(ApiOperation.class))
.paths(PathSelectors.any())
//You can set which requests to join the document and which requests to ignore according to the url path
.build();
}
/**
* Set the details of the api document
*/
private ApiInfo apiInfo() {
return new ApiInfoBuilder()
// title
.title("Spring Boot integrate Swagger2")
// Interface description
.description("swagger Nuclear test site")
.version("1.0")
// structure
.build();
}
//404 cannot be accessed
public void addResourceHandlers(ResourceHandlerRegistry registry) {
registry.addResourceHandler("swagger-ui.html")
.addResourceLocations("classpath:/META-INF/resources/");
registry.addResourceHandler("/webjars/**")
.addResourceLocations("classpath:/META-INF/resources/webjars/");
}
}
4. Relevant notes involved

5. Add relevant annotations in the controller to describe the interface and parameters in the interface
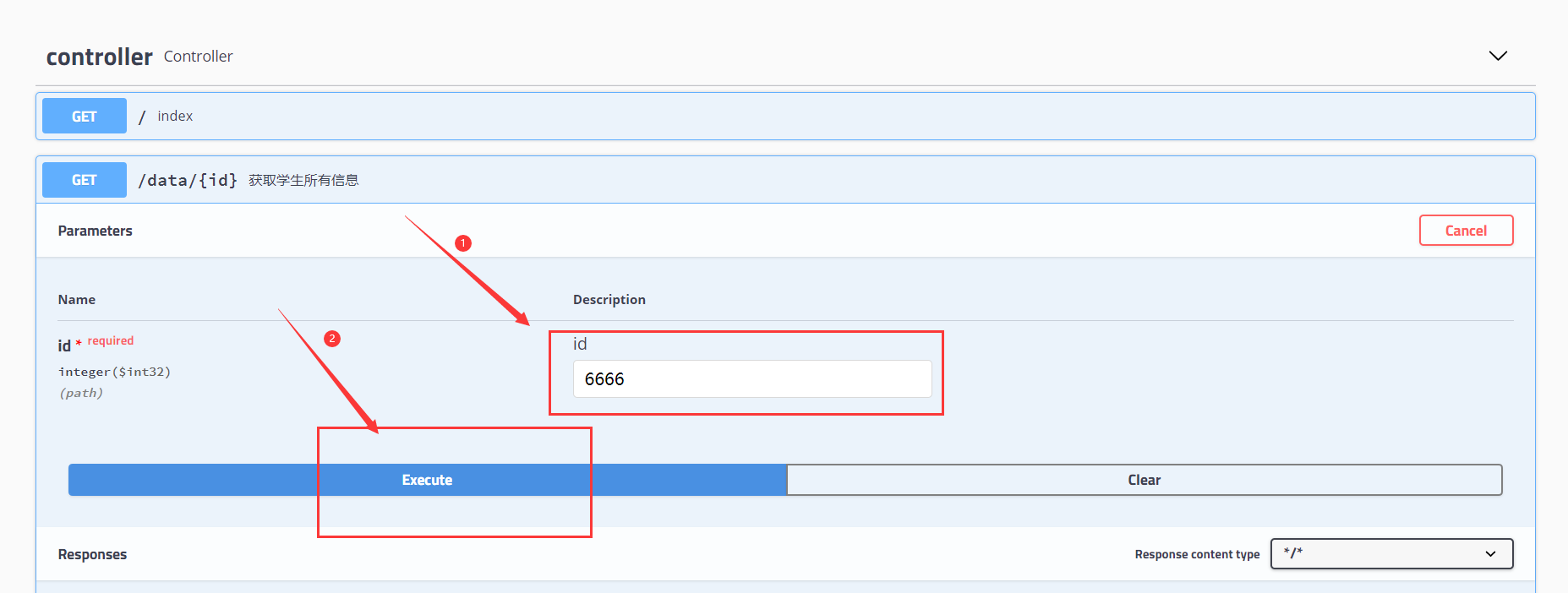
(1) get request (parameter is not of object type)
//Test normal data return
@GetMapping("/data/{id}")
@ApiOperation("Get all student information")//Description of the interface
@ApiImplicitParam(name = "id",value = "id",required = true, paramType = "path",dataType = "int")//Description of request parameters
public Msg index2(@PathVariable("id")Integer id){
System.out.println("id The value of is"+id);
int a[][]= new int[2][3];
for (int i=0;i<2;i++){
for (int j=0;j<3;j++){
a[i][j]=(int)(Math.random()*10+1);
}
}
return Msg.success().sendData("data",a);
}
(2) post request (parameter is object type)
@PostMapping("/student")
@ApiOperation("Incoming student information")//Description of the interface
public Msg addStudent(@RequestBody Student student){
System.out.println(student);
return Msg.success().sendData("studentMessag",student);
}
Related entity class
@Data
@ToString
@ApiModel//Declare api entity model
public class Student {
@ApiModelProperty("Student name")
String name;
@ApiModelProperty("Student age")
Integer age;
@ApiModelProperty("School")
String school;
}
5. Test
(1) Test get request
(2) Test post request

Returned data
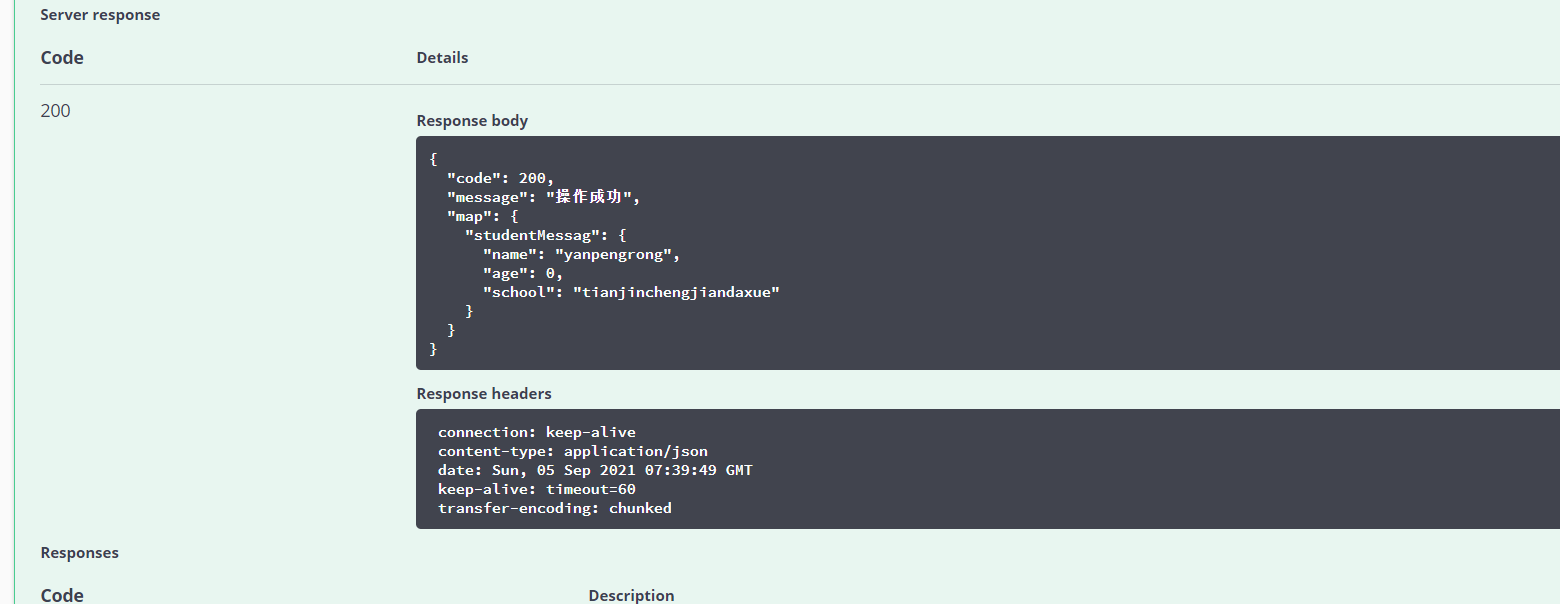
5, Implementation of comment function
1.sql
Find parent comments based on blog_id and parentId==null
<select id="selectParentComment" resultMap="BaseResultMap">
select *
from t_comment
where parent_comment_id = -1 and blog_id = #{blogId}
</select>
Find the corresponding subset of comments according to parentId
<!--Based on parent comments id Find a child comment and the parent nickname of the child comment-->
<select id="selectCommentByParent" parameterType="java.lang.Integer" resultMap="BaseResultMap">
select tc.id id, tc.avatar avatar, tc.content content, tc.create_time create_time, tc.email email, tc.nickname nickname,
tc.blog_id blog_id, tc.parent_comment_id parent_comment_id,tp.nickname parentNickname,tc.adminComment
from t_comment tc
left join t_comment tp
on tc.parent_comment_id = tp.id
where tc.parent_comment_id = #{id}
</select>
2. Use recursive traversal to sort out the child comment set corresponding to each parent comment
@Service
public class CommentServiceImpl {
@Autowired
private CommentMapper commentMapper;
public int insertComment(Comment comment){//Add comments
return commentMapper.insertSelective(comment);
}
public List<Comment> listCommentByBlogId(Integer blogId) {//Get all the comments, then classify the comments, and finally return to the controller
List<Comment> comments1 = commentMapper.selectParentComment(blogId);//Query the first level comments whose parent_comment_id is empty
combineChildren(comments1);
System.out.println("First level comments"+comments1);
return comments1;
}
private void combineChildren(List<Comment> comments) {//Receive first level comments here
for (Comment comment : comments) {
List<Comment> replys1 = commentMapper.selectCommentByParent(comment.getId());//Find the corresponding secondary directory according to the id of the primary comment
for(Comment reply1 : replys1) {
//Loop iteration, find the children and store them in tempReplys
recursively(reply1);
}
//Modify the reply collection of the top-level node to the collection after iterative processing
comment.setReplyComment(tempReplys);
//Clear temporary storage area
tempReplys = new ArrayList<>();
}
}
//Store the collection of all children found by iteration
private List<Comment> tempReplys = new ArrayList<>();
private void recursively(Comment comment) {
tempReplys.add(comment);//Secondary comments are stored in a temporary list
List<Comment> comment3 = commentMapper.selectCommentByParent(comment.getId());//Find out whether there is a corresponding level 3 comment according to the id of the level 2 comment
if (comment3.size()>0) {//If there are three-level comments, continue to traverse according to the three-level comments
for (Comment reply : comment3) {
recursively(reply);
// Tempreplies. Add (reply); / / store the found three-level comments in the temporary list
// List<Comment> comments4 = commentMapper.selectCommentByParent(reply.getId());
// If (comments4. Size() > 0) {/ / if level 4 Comments still exist, keep traversing
// recursively(reply);
// }
}
}
}
}
Additional test documents are required to be transmitted up and down
Here is the reference
6, Tag many to many query function
1. Basic knowledge required
1. Conversion between numbers and strings
Number to string: String.valueOf(i)
String to number: Integer.parseInt(str)
2. Dynamic sql for batch query
<!-- According to the drama code id list Query drama dictionary -->
<select id="selectByIds" resultMap="DramaImageResultMap">
select * from drama where drama_id in
<foreach collection="dramaIds" item="dramaId" open="(" close=")" separator=",">
#{dramaId}
</foreach>
</select>
2. When adding or deleting a blog
Since blogs and tags are many to many, three tables need to be changed at the same time when adding a blog, namely blog table, tag table and association table. Below, I will describe the implementation process of adding a blog from the perspective of each table.
It should be noted that in the blog table, I store tag IDS in the form of "string", that is, a table field corresponds to multiple tag IDs
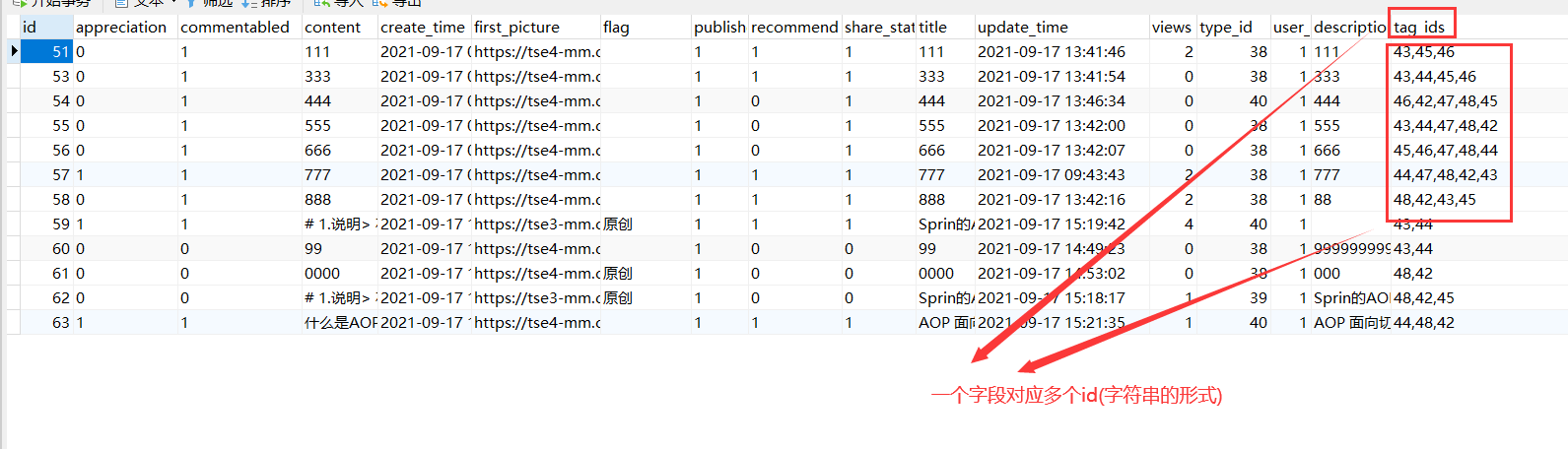
1. Add blog table
When we add a new blog and click publish, multiple tags will be passed to the server in the form of string, and then they will be received by the mapping entity object and stored in the database through the persistence layer. There is no special operation part in this process.
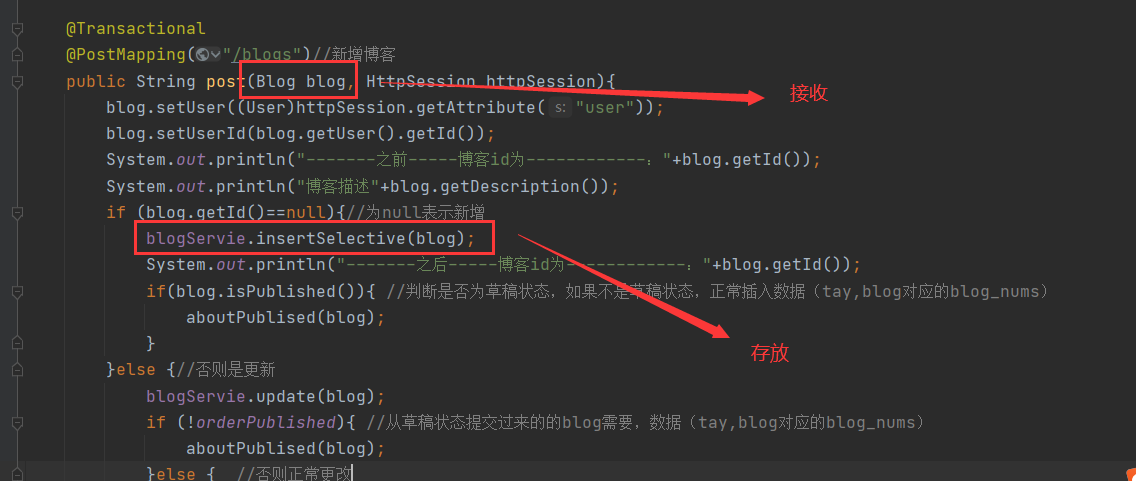

2. Adding label tables and associated tables
After adding a blog, you need to add corresponding tags and associated tables. Therefore, the key problem is how to convert the string tag set into a numeric tag set.
Get the tag id and convert it to a numeric set
Use the split method of String to divide the "String label set" with comma separator into single characters, and then convert it into numeric type through Integer.parseInt() method. Traverse the converted numeric type. At this time, do the corresponding operations of "label table" and "association table"
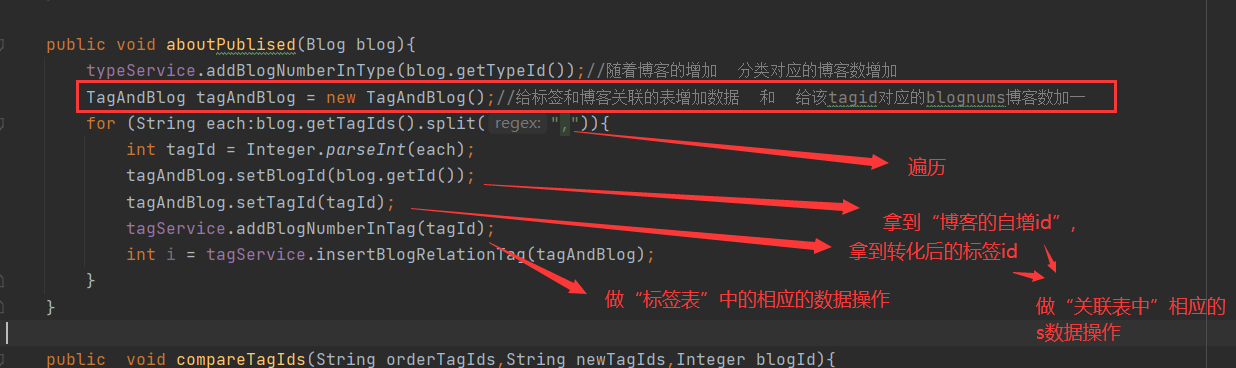
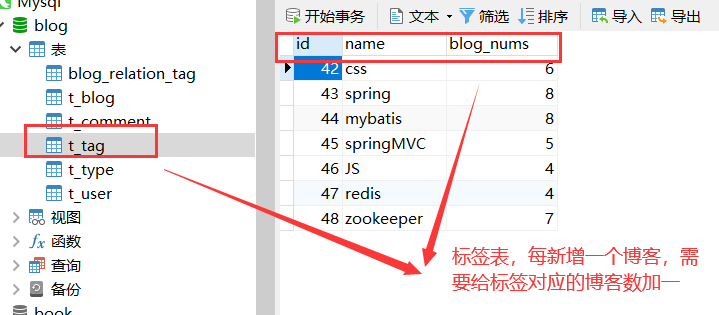
For each new blog, you need to add a set of corresponding id associations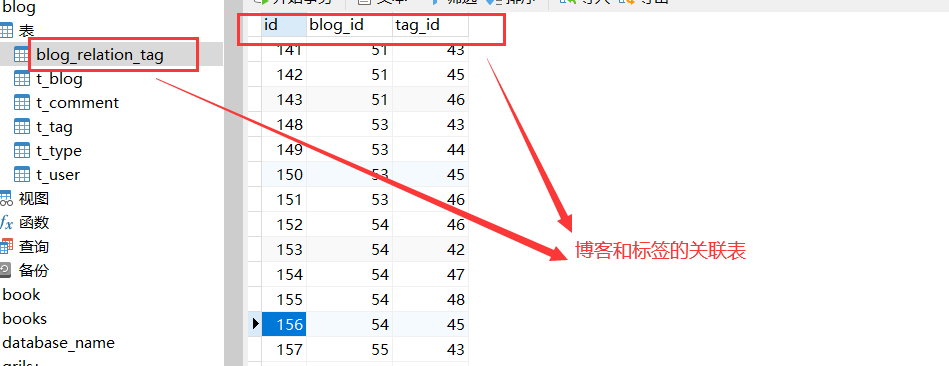
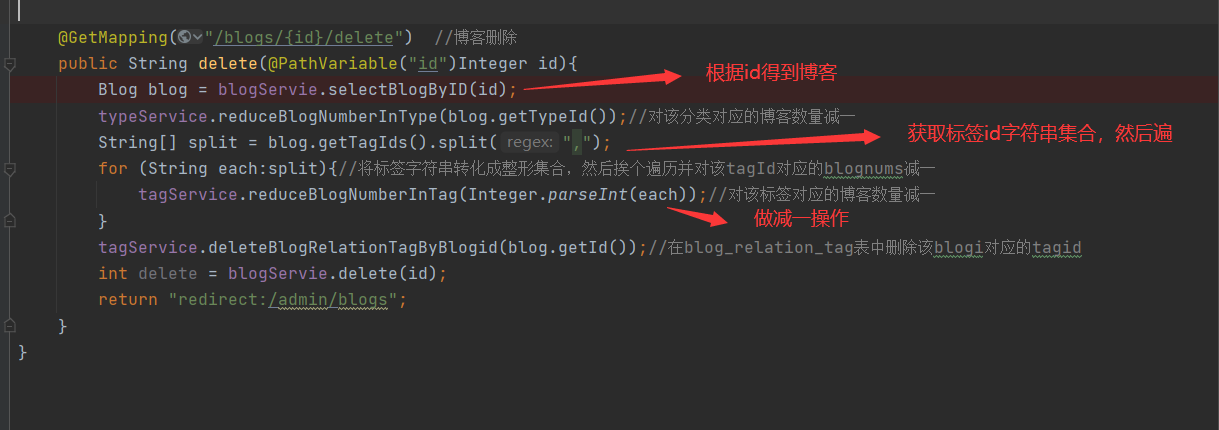
4. Delete
The deletion operation is much easier. Get the id of the blog, find out the corresponding tag id set (this article is only for tags, not including the classification module), delete the blog according to the blog id, and delete the corresponding relationship in the corresponding "association table" according to the tag id set
In addition, you also need to subtract the "number of blogs" corresponding to the tag id by one in the "tag table" according to the tag id
3. When modifying a blog
The reason why the "blog modification" is recorded separately is that the operation of the module is relatively complex, and all the logic codes are based on their own ideas. There is no reference standard. I don't know whether it is the best writing method, but I can run the function, and there are no errors after many tests. It is still worth recording.
The following describes the normal execution logic process of the module: (only for tags, excluding other contents)
After modifying the tag, click Submit and get the "modified" tag in the controller. We need to judge whether those tags are new, abandoned and not modified.
For new: get the id corresponding to the new tag, add one to the number of blogs corresponding to it in the tag table, and add a group of correspondence in the association table.
For discarded: get the id corresponding to the discarded tag, subtract one from the number of blogs in the tag table, and delete a group of corresponding relationships in the association table.
For unchanged: keep unchanged and do nothing.
So the core of the problem is how to filter out those that are new, those that are discarded and those that are unchanged. So how to compare multiple tag sets with another set containing multiple tags, and then make the correct filtering?
Solution:
- When you click "Edit" to enter the editing page, get the "tag set in string form" assigned to the controller according to the blog id as the "old tag set", then edit and submit, and then get the modified "new tag set".
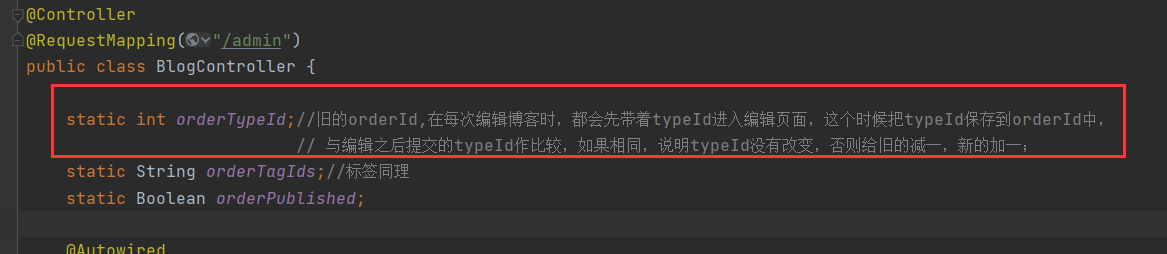
2. Convert the tag set in string form into numeric list
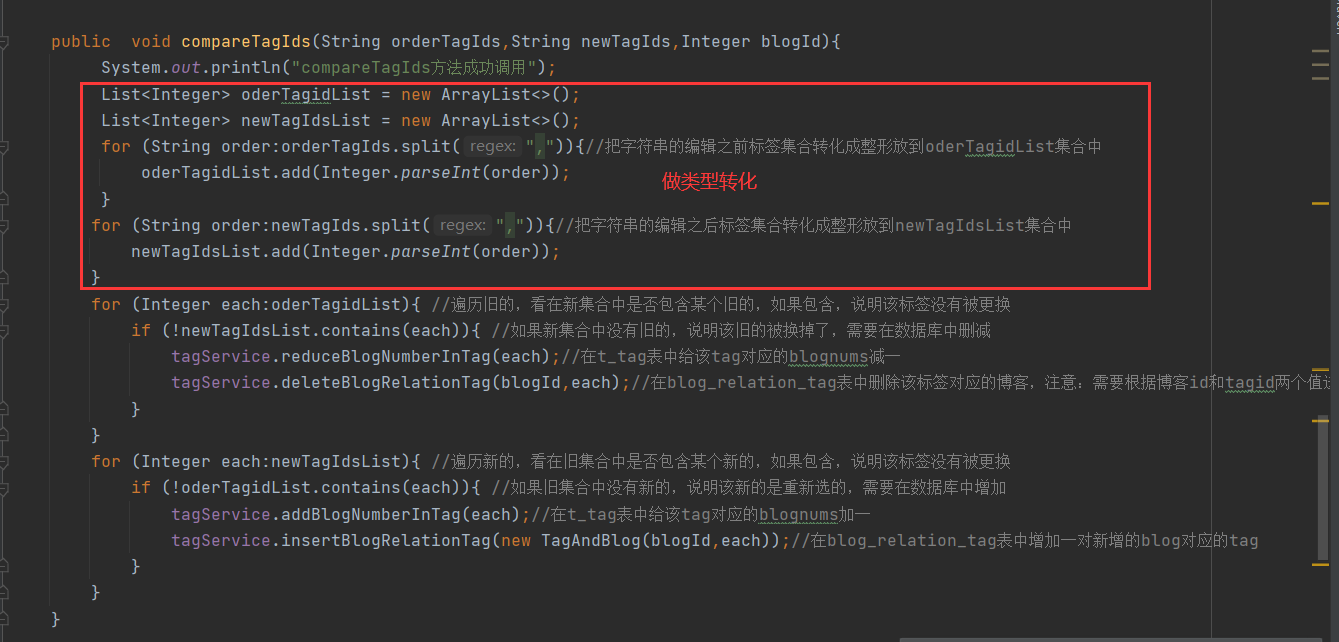
3. Two steps are required before and after finding out the modification
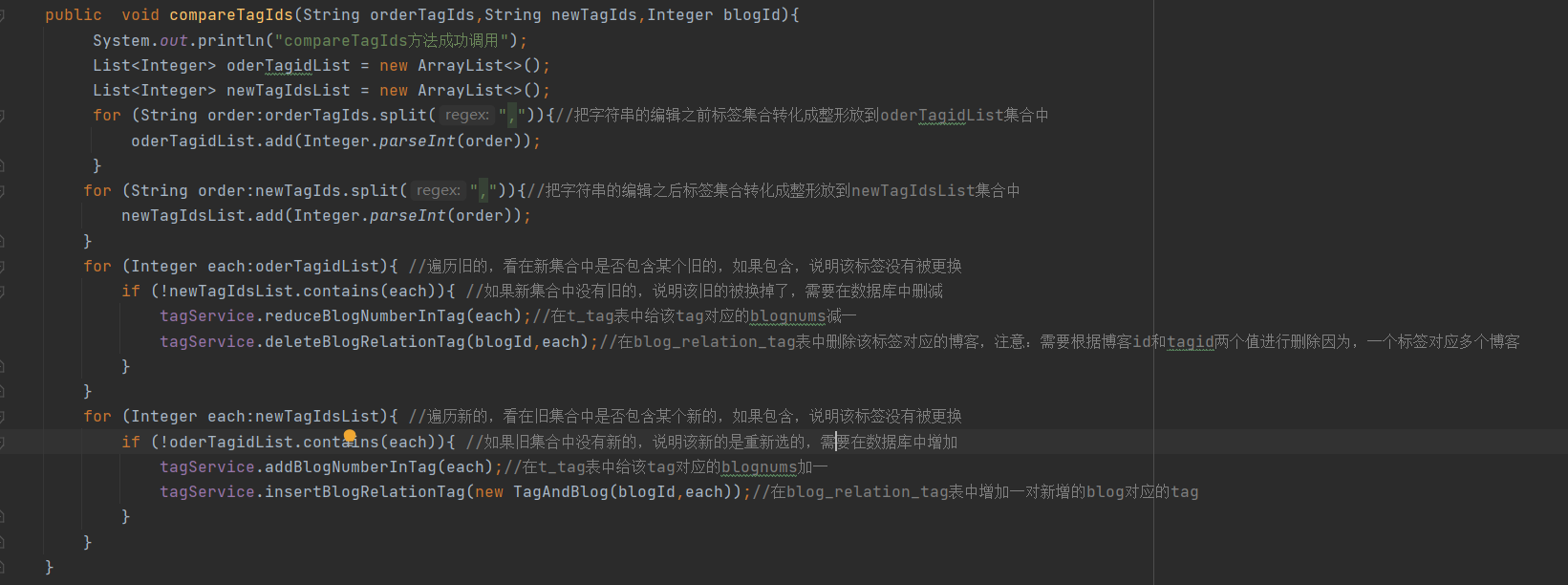
(1) First traverse the old list, and then query in the new list. If the new list contains the old "tag id", it means that the id has not been replaced. If the new list does not contain "tag id", it means that the id is new. For the new id, it is mentioned above and will not be repeated.
(2) Then traverse the new list and query in the old list. If the old list contains the old "tag id", it means that the id has not been replaced. If the old list does not contain the "tag id", it means that the id is discarded. For the discarded, it is mentioned above and will not be repeated.
The specific implementation details are as follows;
4. When saving a blog
Record blog preservation mainly involves the front-end page display and code optimization. The most important thing is that I ignored the "part related to the front-end display" when I did it for the first time. Finally, I found a problem in the test, which is not small. It is necessary to reconstruct the interface of blog addition and editing. At that time, it was all in accordance with my own ideas, I don't know if it's the best. If someone finds that my code needs to be improved, please don't hesitate to give me advice. Yan will be very grateful.
Saving is actually saving the edited blog in the form of a draft. Since it is a draft, it should not be displayed on the front page, including (association table, label, classification data).
What was the problem I encountered at that time?
Since the draft cannot be displayed on the front page, the data of relevant classifications, labels and associated tables cannot be stored in the database. Then, after editing and publishing again, the previous draft is an "Edit" operation, and the "draft status" is changed to "publish status". At this time, the blog will directly enter the editing interface without adding. In this way, the blog's (association table, label, classification data) has not been stored in the database from beginning to end.
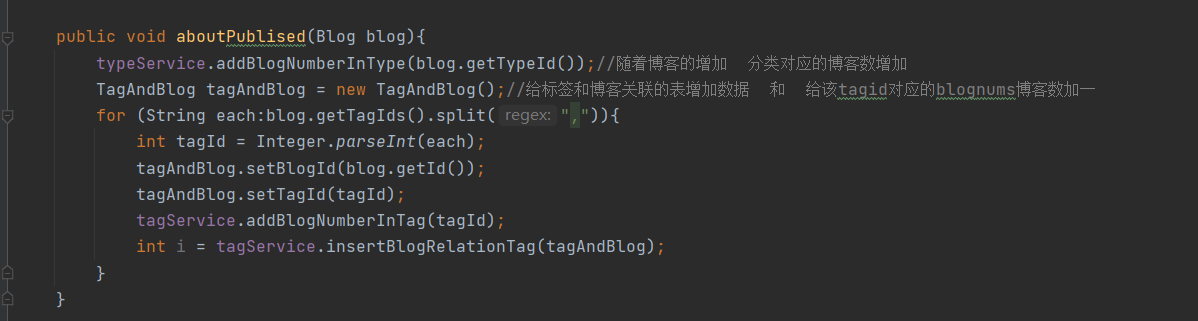
How to solve it?
Judge according to the status of publish or not

Encapsulation method aboutPublished()
7, Solution of conflict between foreach tag and pageInfo
1. Demand
In the "tag" column of the client, when a tag is clicked, all blogs about the tag will be queried and presented in the form of list, dominated by background logic
2. My solution

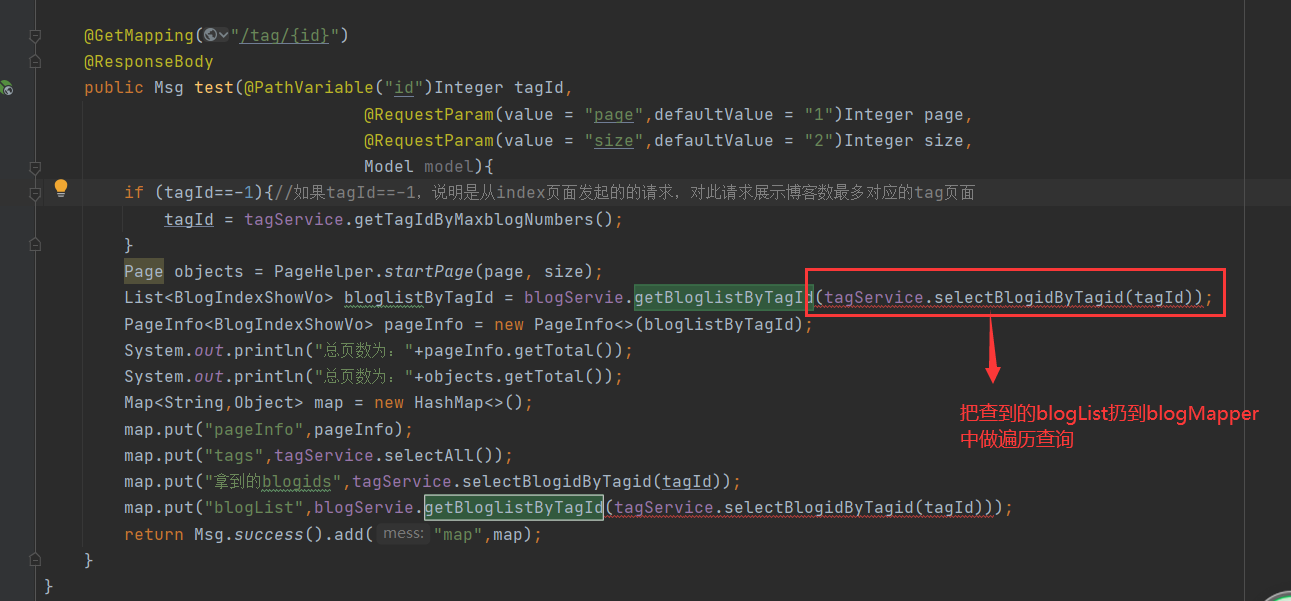
3. Problems
pageinfo cannot normally display the total number of records queried
After some tracking and inspection, it is related to foreach in sql statements. The specific reasons are not very understood
1. Use the foreach tag hi
reference material:
https://blog.csdn.net/douzhenwen/article/details/112025079
https://www.jianshu.com/p/af138ede8580
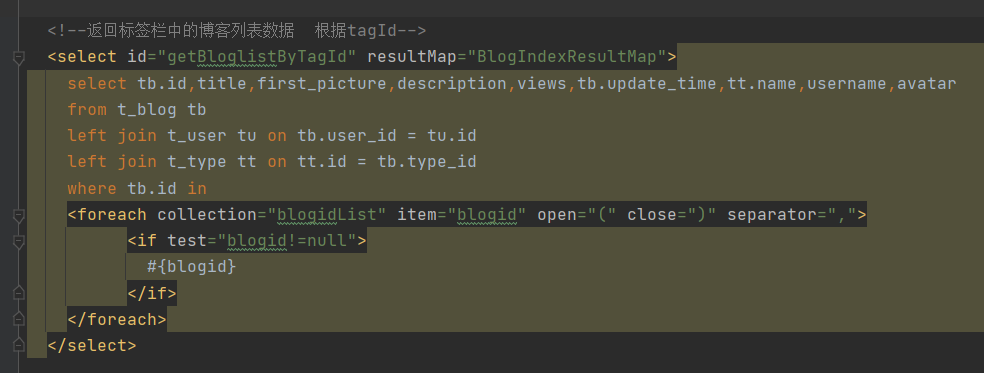
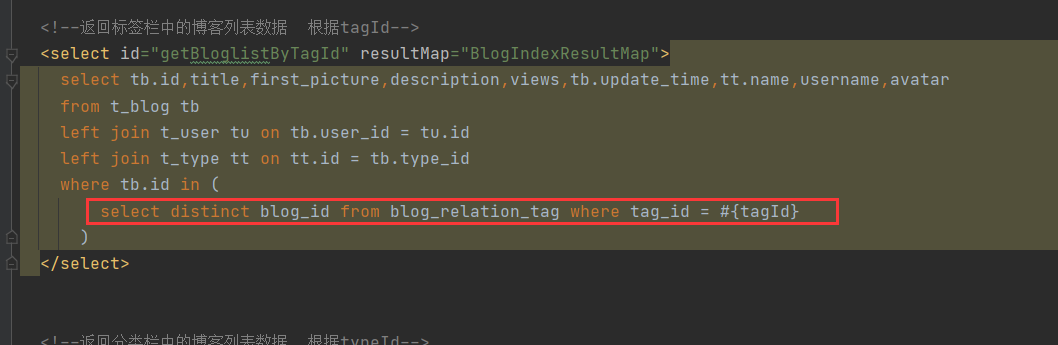
4. Change ideas
Use subquery
(1) No, you need to get to the blog first_ relation_ Find out the related list in the tag association table and pass it into the blog table
(2) Instead, you can directly add a sub query to the sql of the query blog set, and hand over step (1) to the sub query to complete
8, Query summary of sql statements used in the project
9, Summary of usage differences between Ajax and Ajax in thymeleaf
10, Get auto increment id
My method (I don't know if I can automatically obtain the self increasing id, which is amazing)
Generate id using singleton mode
private static int getSYN_BLOGID(){
if (SYN_BLOGID == null){
SYN_BLOGID=;
return SYN_BLOGID;
}
return SYN_BLOGID;
}
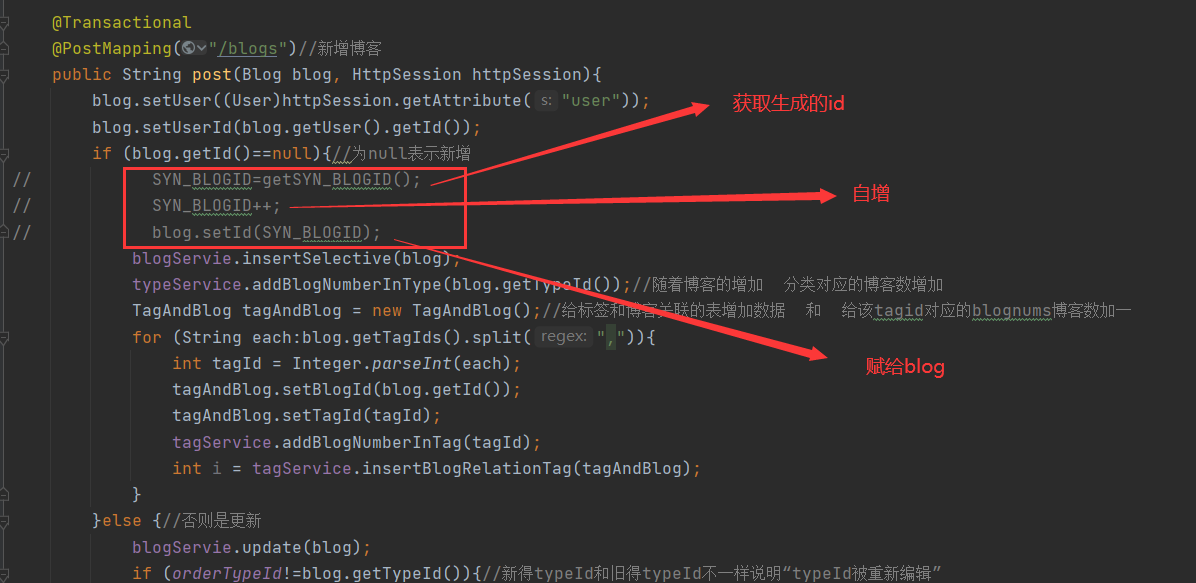
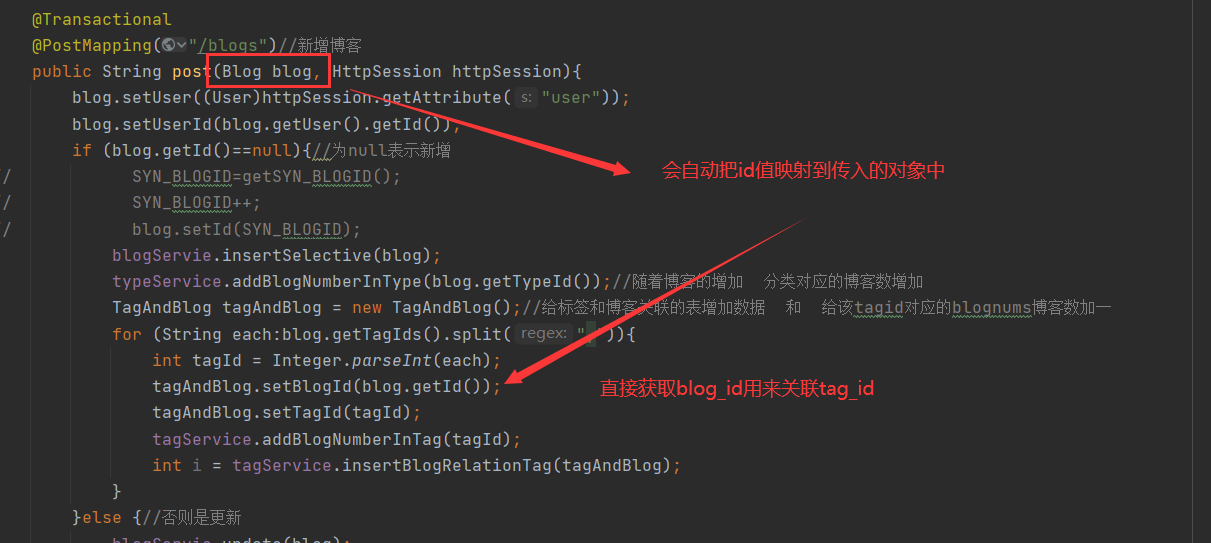
When adding a blog, because the blog and tag have a many to many relationship, the id association table is needed to maintain the relationship between the two tables. However, when adding a blog, generally, the id is null, so how to get the blog_id and tag_ What about id association?
mybatis provides an example in the mapper mapping file
<insert id="insertSelective" useGeneratedKeys="true" //Allow JDBC to support automatic generation of primary keys keyProperty="id" //Automatically map to the id attribute in the object parameterType="com.lrm.po.Blog">