Share today about bitmaps and Bloom filters and hash segmentation.
Bitmap simply means that an integer exists or does not exist in a bit bit. It is suitable for simple search in large data to determine whether an integer exists or not.
In fact, the principle of bitmap is consistent with the direct fixing method of hash table. The fixing value of hash table is a specific type, and the fixing value of bitmap is on a bit, and 0 or 1 on that bit is used to express the existence or non-existence of an integer. like that.
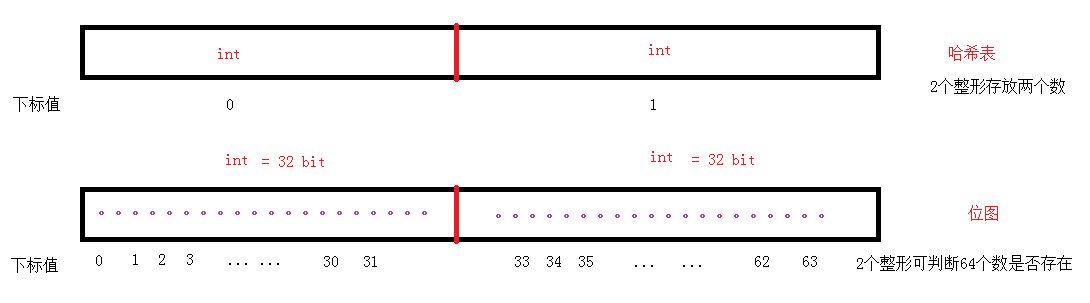
The simple implementation of bitmap code is as follows:
Bitset.h
#pragma once
#include<vector>
class Bitset
{
public:
Bitset(int size)
{
int index = (size>>5)+1;
_a.resize(index);
}
~Bitset()
{
}
void Set(const int num)//Set 1
{
size_t index = num>>5;//subscript
if(index >= _a.size())
{
return ;
}
int pos = num % 32;
_a[index] |= 1<<pos;
}
void Reset(const int num)//Set 0//delete
{
size_t index = num>>5;//subscript
if(index >= _a.size())
{
return ;
}
int pos = num % 32;
_a[index] &= ~(1<<pos);
}
bool Test(const int num)
{
size_t index = num>>5;//subscript
if(index >= _a.size())
{
return false;
}
int pos = num % 32;
if((_a[index] &= 1<<pos) == 0)
return false;
return true;
}
//bool operator[](const int num)
//{
// return Test(num);
//}
protected:
vector<int> _a;
};
void TestBitset()//Test bitmap
{
Bitset s(1000);
s.Set(22);
s.Set(112);
s.Set(221);
s.Set(999);
cout<<"s.Test(22)"<<s.Test(22)<<endl;
cout<<"s.Test(12)"<<s.Test(12)<<endl;
cout<<"s.Test(122)"<<s.Test(122)<<endl;
cout<<"s.Test(112)"<<s.Test(112)<<endl;
cout<<"s.Test(221)"<<s.Test(221)<<endl;
cout<<"s.Test(212)"<<s.Test(212)<<endl;
cout<<"s.Test(2)"<<s.Test(2)<<endl;
cout<<"s.Test(999)"<<s.Test(999)<<endl;
s.Reset(22);
cout<<"s.Reset(22)->s.Test(22)"<<s.Test(22)<<endl;
}
run.cpp
#include<iostream>
using namespace std;
#include"Bitset.h"
int main()
{
cout<<"***Test bitmap***"<<endl;
TestBitset();//Test bitmap
system("pause");
return 0;
}Bitmaps are useful for judging the existence of shaping numbers, while Bloom filters generally determine the existence of any type of instantiated object. Bloom filter can accurately judge that the object does not exist, but its disadvantage is that there may be misjudgement when the object exists.
The bottom layer of the Bloom filter is still a bitmap. The Bloom filter first converts any type into a shaping by hashing. In this process, the shaping may be the same, so when the bitmap is directly fixed, the values of several different objects may be mapped to the same position, that is, the value of several different objects can be mapped to the same position. When identifying a non-existent object, it finds that the mapping location already exists (other existing objects are mapped to this location through hash transformation), which leads to misjudgement. In order to reduce the misjudgment rate of mapping conflicts, we use different hash transformations to map several locations of an object. When searching, we can only judge the existence of all transformed mapping locations. But even so, mapping conflicts cannot be completely avoided. That is to say, misjudgement will still occur.
The diagrams are as follows:
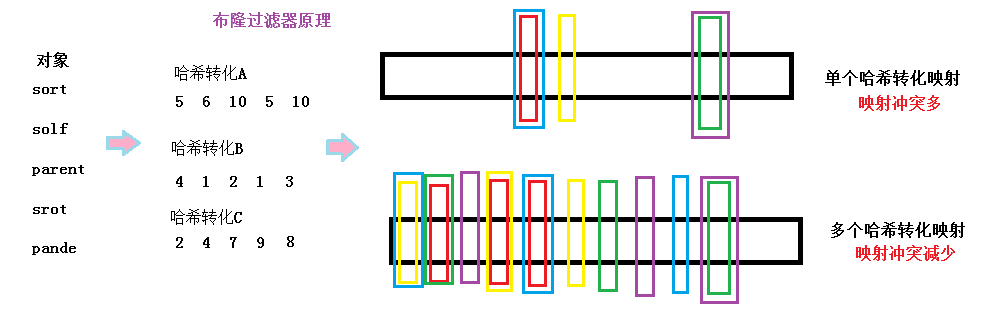
The Bloom filter code is as follows:
Bloomfilter.h
#pragma once
#include"Bitset.h"
//Bloom filter//
struct HashString1
{
size_t BKDRHash(const char *str)
{
register size_t hash = 0;
while (size_t ch = (size_t)*str++)
{
hash = hash * 131 + ch; // It can also be multiplied by 31, 131, 1313, 13131, 131313.
}
return hash;
}
size_t operator()(const string& key)
{
return BKDRHash(key.c_str());
}
};
struct HashString2
{
size_t SDBMHash(const char *str)
{
register size_t hash = 0;
while (size_t ch = (size_t)*str++)
{
hash = 65599 * hash + ch;
}
return hash;
}
size_t operator()(const string& key)
{
return SDBMHash(key.c_str());
}
};
struct HashString3
{
size_t RSHash(const char *str)
{
register size_t hash = 0;
size_t magic = 63689;
while (size_t ch = (size_t)*str++)
{
hash = hash * magic + ch;
magic *= 378551;
}
return hash;
}
size_t operator()(const string& key)
{
return RSHash(key.c_str());
}
};
template<class K= string, class HashStr1 = HashString1,
class HashStr2 = HashString2, class HashStr3 = HashString3>
class BloomFilter//Simple Bloom, no reference counting, no Rset implementation
{
public:
BloomFilter(size_t n)
:_bs(n*6)
,_size(n*6)
{
}
~BloomFilter(){}
//set,test
void Set(const K& num)
{
size_t pos1 = HashStr1()(num);//Imitating Functions Create Temporary Objects
size_t pos2 = HashStr2()(num);
size_t pos3 = HashStr3()(num);
_bs.Set(pos1%_size);//pos1 may be larger than _size
_bs.Set(pos2%_size);
_bs.Set(pos3%_size);
}
bool Test(const K& num)
{
size_t pos1 = HashStr1()(num);
if(!_bs.Test(pos1%_size))
return false;
size_t pos2 = HashStr2()(num);
if(!_bs.Test(pos1%_size))
return false;
size_t pos3 = HashStr3()(num);
if(!_bs.Test(pos1%_size))
return false;
return true;
}
protected:
Bitset _bs;
size_t _size;//count
};
void TestBloom()//Test Bloom Filter
{
BloomFilter<> _bf(1000);
_bf.Set("solf");
_bf.Set("sort");
_bf.Set("good");
_bf.Set("parent");
_bf.Set("uhper");
cout<<"solf?"<<_bf.Test("solf")<<endl;
cout<<"sort?"<<_bf.Test("sort")<<endl;
cout<<"ptres?"<<_bf.Test("ptres")<<endl;
cout<<"parent?"<<_bf.Test("parent")<<endl;
cout<<"uhper?"<<_bf.Test("uhper")<<endl;
}
run.cpp
#include<iostream>
using namespace std;
#include"BloomFilter.h"
int main()
{
cout<<"***Test Bloom Filter***"<<endl;
TestBloom();//Test Bloom Filter
system("pause");
return 0;
}When the data in big data is too large to be put down in memory even using bitmaps, or when it is necessary to determine whether a certain number exists and the number of statistics (not suitable for bitmaps for the time being), it is necessary to use hash segmentation to divide a large data file into several small files that can be accommodated in memory and carry out corresponding segmentation. Operations and so on, to achieve the set goals.
Hash Segmentation:
It is expected that the file N can be stored in memory (because the file hashed is different in size, so try to split the file a little more), convert the object in the file by hash string conversion, and then map to the corresponding file number, that is, write the object to the file. You know, all the big data files are hashed into N files of suitable size.
But if it is just random segmentation, it may still not achieve the effect of segmentation processing, memory may still be unable to store file objects and carry out corresponding operations, it will not be able to complete the purpose of hash segmentation.
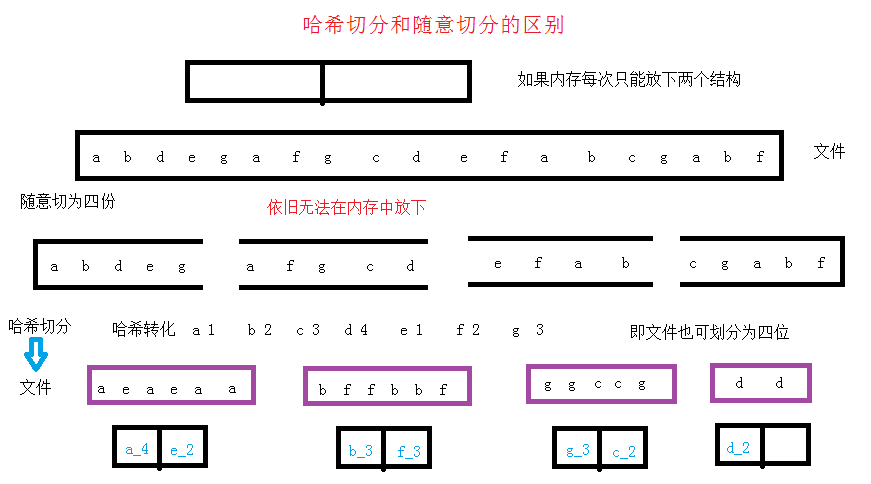
but sometimes, there is not always only one way to accomplish a goal. Every road leads to Rome. There are many kinds of algorithms. They need to learn more and connect more. If you have a better idea, look forward to sharing and discussing them together.
So far to share, thanks! Wish you all a happy learning!