This article was originally created by senlie and should be reproduced at this address: http://www.cnblogs.com/senlie/
1. Summary
Many calculations are conceptually intuitive, but because of the large input data, these calculations can be completed in a reasonable amount of time
It must be distributed across hundreds and thousands of machines.For example, calculate by processing the crawled documents, Web page request logs
Various derived data, such as inverted indexes, various graphical representations of web documents, the number of documents crawled from each host,
A collection of the most frequently queried queries on a given day.
MapReduce is a programming pattern and corresponding implementation for processing and generating large datasets.
The user specifies a map function to process a key-value pair to generate a set of key-value pairs.
And a reduce function to combine real values with the same intermediate key.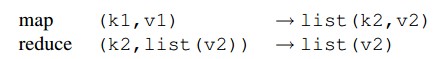
For example, there are a large number of documents in which you want to count the number of occurrences of each document.You can write map and reduce functions like this
map(String key, String value): //key: document name //value: document contents for each word w in value: EmitIntermediate(w, '1'); reduce(String key, Iterator values): //key: a word //values: a list of counts int result = 0; for each v in values: result += ParseInt(v); Emit(AsString(result));
?? Question: map returns a key/value, why does the input to resuce become key/list of values, which is in between
What happened?
Answer:
The map function accepts a key-value pair (such as the document name/document content in the example above) and produces a set of key-value pairs (words/1).While putting this group
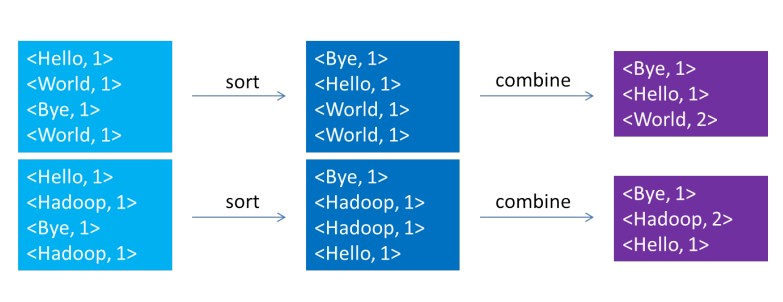
Before key-value pairs are passed to the reduce function, the MapReduce library combines all the real values with the same key value to produce a new set of keys/values (words/times).
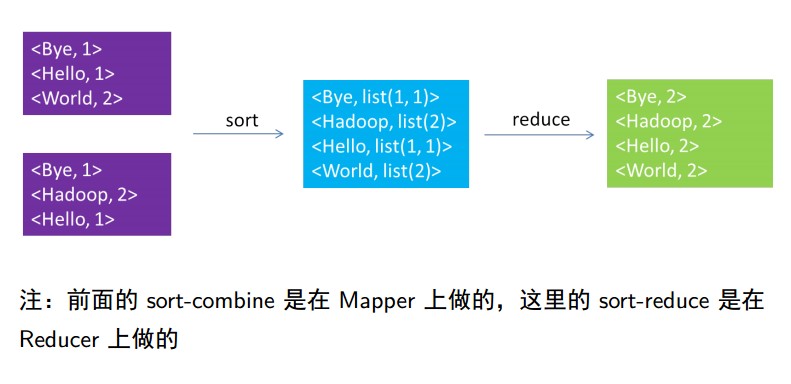
The reduce function accepts key-value pairs from several map functions that are combined by the MapReduce library before being processed by the reduce function
Key/Value List (Word/Number List).The following figure illustrates this process.
(Statement: Picture from seminar show ppt by adonis classmates in the lab)
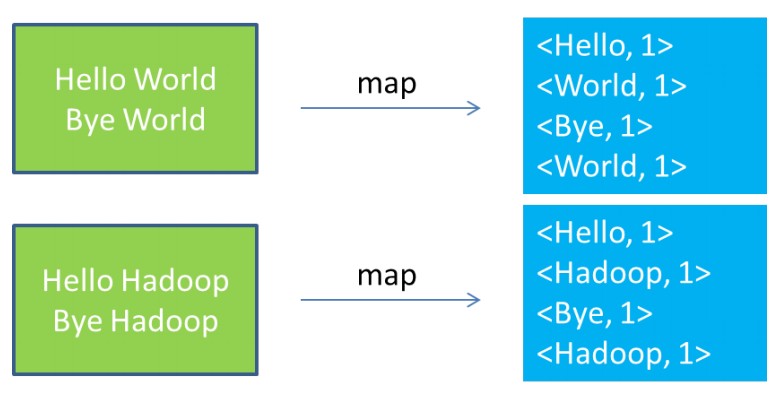
2. Overview of MapReduce execution
By dividing the input data into M slices, the calls to the map function are distributed across multiple machines, and the slices can be identical
Different machines process in parallel.
By dividing the key space of the intermediate result into R slices, calls to the reduce function are distributed across multiple machines.
The following diagram shows the entire process of the MapReduce operation.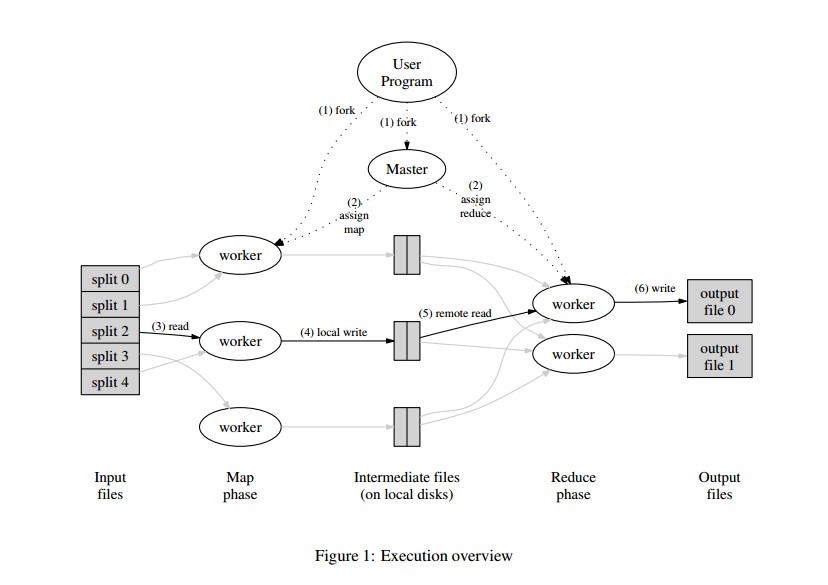
1). The M apReduce Library in the client program first divides the input files into M-sized slices, usually 16 or 64 MB in size.
Then start copying the client on the machine in the cluster
2). One of the programs has a special backup, which is the primary node.Others are the slave nodes that are assigned tasks by the master node.
The primary node has M map tasks and R reduce tasks to assign to those idle slave nodes.
3). A map task is assigned to a node that reads from the input slice and parses the key-value pairs from the input to be passed to
User-defined map function that generates key-value pairs of intermediate results and caches them in memory
4). Key-value pairs in memory are periodically written to the local disk and divided into R slices by the slicing function.
The positions of these fragments are returned to the primary node, which tells reduce where they are from
5. Reduc reads from RPC(remote procedure call) when the slave node is notified of the location of the slice by the master node
Those cached data, when read, will sort key values, then combine key-value pairs with the same key values to form a list of keys/values
6).reduce traverses sorted and merged intermediate data from the node, passing each key/value list pair to the customer-defined reduce function.
The result returned by the reduce function is added to the result file of this reduce from the node.
7). When all map slave and reduce slave nodes are completed, the master node wakes up the client.
If the MapReduce program completes successfully, the result file is stored in R output files.
3. Examples
This example counts the number of occurrences of each word in a set of input files
#include "mapreduce/mapreduce.h"
//user's map function
class WordCounter : public Mapper{
public:
virtual void Map(const MapInput &input){
const string &text = input.value();
const int n = text.size();
for(int i = 0; i < n; ){
//Ignore space before word
while(i < n && isspace(text[i])) i++;
//Find the end of the word
int start = i;
while(i < n && !isspace(text[i])) i++;
if(start < i) Emit(text.substr(start, i - start), "1");
}
}
};
REGISTER_MAPPER(WordCounter); // What is this for?
//User's reduce function
class Adder : public Reducer {
// Don't add a public keyword here?
virtual void Reduce(ReduceInput *input){
//Add up the values with the same key value
int64 value = 0;
while(!input->done()){
value != StringToInt(input->value());
input->NextValue();
}
Emit(IntToString(value));
}
}
REGISTER_REDUCER(Adder);
int main(int argc, char **argv){
ParseCommandLineFlags(argc, argv);
MapReduceSpecification spec;
//Save list of input files into "spec"
for(int i = 1; i < argc; i++){
MapReduceInput *input = spec.add_input();
input->set_format("text");
input->set_filepattern(argv[i]);
input->set_mapper_class("WordCounter");
}
//Specify Output File
MapReduceOutput *out = spec.output();
out->set_filebase("gfs/test/freq");
out->set_num_tasks(100);
out->set_format("text");
out->set_reducer_class("Adder");
//Optional: Save bandwidth by running portions and operations on map nodes
out->set_combiner_class("Adder");
//Adjustment Parameters: Use up to 2000 machines with up to 100 MB of memory per task
spec.set_machines(2000);
spec.set_map_megabytes(100);
spec.set_reduce_megabytes(100);
//Run
MapReduceResult result;
if(!MapReduce(spec, &result)) abort();
//When it fails, abort, if it runs here, it succeeds.
return 0;
}
Reference resources:
MapReduce: Simplified Data Processing on Large Clusters
Reprinted at: https://www.cnblogs.com/senlie/p/3871617.html