Big Data Learning 06_Hadoop: An Overview of MapReduce
Overview of MapReduce
MapReduce Core
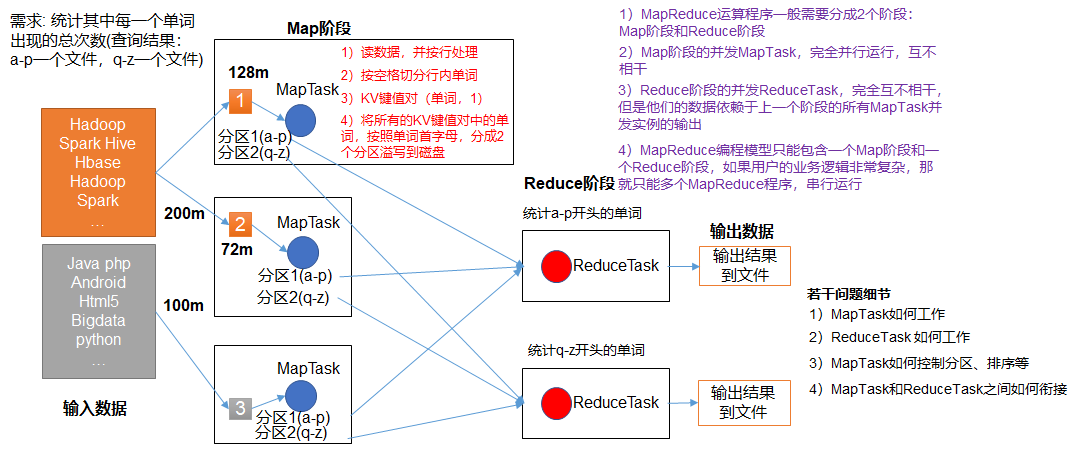
The MapReduce operator is divided into at least two phases
- The first phase of the MapTask concurrent instance runs completely in parallel and is not related to each other
- The second phase of the ReduceTask concurrent instance runs completely in parallel and is independent of each other. However, their data depends on the output of all MapTask concurrent instances in the previous phase.
- The MapReduce programming model can only contain one Map phase and one Reduce phase, and if the business logic is complex, it can only run multiple MapReduce programs in serial.
A complete MapReduce program has three types of instance processes at distributed runtime:
- MrAppMaster: Responsible for process scheduling and state coordination throughout the program
- MapTask: Is responsible for the entire data processing process in the Map phase
- ReduceTask: Responsible for the entire data processing process in the Reduce phase
MapReduce Programming Specification
-
Mapper class
- User-defined Mapper classes inherit Mapper parent classes from jar packages
- Mapper's input data is in the form of KV pairs (KV types can be customized)
- Business logic in Mapper is written in the map() method
- Mapper's output data is in the form of KV pairs (KV types can be customized)
- The MapTask process calls the map() method once for each group <K, V>
-
Reducer class
- User-defined Reducer class inherits Reducer parent class from jar package
- Reducer's input data type corresponds to Mapper's output data type
- Reducer's business logic is written in the reduce() method
- The ReduceTask process calls the reduce() method once for each group <k, v>
-
Driver class
A client equivalent to a YARN cluster that submits our entire program to the YARN cluster, submitting a job object encapsulating the relevant operational parameters of the MapReduce program -
MapReduce has the following data serialization types
Java Type Hadoop type boolean BooleanWritable byte ByteWritable int IntWritable float FloatWritable long LongWritable double DoubleWritable String Text map MapWritable array ArrayWritable
MapReduce Case Practice 1: WordCount
-
Environmental preparation:
- Add the location of the jar package for hadoop to the system path
- Create a new Maven project, add the following dependencies
<dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>RELEASE</version> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <version>2.8.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.7</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.7</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.7</version> </dependency> </dependencies>
-
Write a program

- Writing Mapper classes
package cn.maoritian.mapreduce; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { // Four type parameters of Mapper object KEYIN, VALUEIN, KEYOUT, VALUEOUT // KEYIN: Type of input key: LongWritable // VALUEIN: Type of input value: Text (line content) // KEYOUT: Type of output key: Text (word string) // VALUEOUT: Type of output value: IntWritable (occurrences) Text k = new Text(); IntWritable v = new IntWritable(1); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1 Get a row String line = value.toString(); // 2 Cut String[] words = line.split(" "); // 3 Output for (String word : words) { k.set(word); context.write(k, v); } } }
- Write the Reducer class:
package cn.maoritian.mapreduce; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { // Four type parameters of Reducer object KEYIN, VALUEIN, KEYOUT, VALUEOUT // KEYIN: Type of input key: Text (word string) // VALUEIN: Type of input value: IntWritable (occurrences) // KEYOUT: Type of output key: Text (word string) // VALUEOUT: Type of output value: IntWritable (summation of occurrences) int sum; IntWritable v = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { // 1. Accumulative Sum sum = 0; for (IntWritable count : values) { sum += count.get(); } // 2. Output v.set(sum); context.write(key, v); } }
- Write the Driver class:
package cn.maoritian.mapreduce; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordcountDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { // 1. Get configuration information and encapsulate tasks Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); // 2. Set the jar load path to be the path of the driver class job.setJarByClass(WordcountDriver.class); // 3. Set up map and reduce classes job.setMapperClass(WordcountMapper.class); job.setReducerClass(WordcountReducer.class); // 4. Set map output job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 5. Set the final output kv type job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); https://github.com/srccodes/hadoop-common-2.2.0-bin/tree/master/ // 6 Set input and output paths FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 7 Submit and Exit boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } }
There are a series of egg-handling problems when running on Windows. This question
- Writing Mapper classes
-
Package the program into a jar package, right-click on the project, click Run as->Maven install to package, and after packaging, the generated jar package will be found in the target directory, renamed wc.jar, and transferred to the hadoop directory.
Use the command below to execute the MapReduce program.hadoop jar wc.jar cn.maoritian.mapreduce.WordcountDriver /wcinput/input.txt /wcoutput/
Hadoop serialization
-
The meaning of Hadoop serialization, why not use Java serialization framework?
MapReduce's data serialization type contains eight basic data types that we can use to serialize Java Bean data types by combining them.
Java serialization is a heavyweight serialization framework (Serializable). Serialized objects come with a lot of extra information (various checks, headers, inheritance systems, etc.) which is not easy to transfer efficiently across the network. So Hadoop developed a serialization mechanism (Writable). -
Implementation of Hadoop Serialization Interface
The steps to serialize the bean object are as follows:- Implement Writable interface
- When deserializing, the null parameter constructor needs to be invoked reflectively, so the null parameter construct must be present
public Bean Class name() { super(); }
- Override serialization method write()
@Override public void write(DataOutput out) throws IOException { out.writeLong(parameter1); out.writeLong(parameter2); out.writeLong(parameter3); }
- Override the deserialization method readFields()
@Override public void readFields(DataInput in) throws IOException { //parameter1 = in.readLong(); //parameter2 = in.readLong(); //parameter3 = in.readLong(); }
- Note that the order of deserialization is exactly the same as that of serialization
- To display the results in a file, you can override the toString() method, with fields separated by \t for subsequent use
- If you need to transfer custom bean s in a key, you also need to implement the Comparable interface, because the Shuffle process in the MapReduce box requires that keys must be sorted.
@Override public int compareTo(FlowBean o) { // Reverse order, from large to small return this.hashCode() - o.hashCode(); }
MapReduce Case Practice 2: FlowCount
- Demand: Count the total upstream traffic, downstream traffic and total traffic consumed by each mobile phone number:
Input data format:Output data format:7 13560436666 120.196.100.99 1116 954 200 id Mobile number Network ip Up traffic Down traffic Network status code
13560436666 1116 954 2070 Mobile Number Up Traffic Down Traffic Total Traffic
- Needs Analysis:

- Write a program:
- FlowBean object for writing traffic statistics
import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.Writable; //1. Implement Writable interface public class FlowBean implements Writable { private long upFlow; // Upstream Flow private long downFlow; // Downstream Flow private long sumFlow; // Total Flow //2. Reflection calls to null parameter constructors are required for deserialization public FlowBean() { super(); } //3. Implement serialization methods @Override public void write(DataOutput out) throws IOException { out.writeLong(upFlow); out.writeLong(downFlow); out.writeLong(sumFlow); } //4. Deserialization methods //5. Deserialization methods must read in the same order as writing serialization methods @Override public void readFields(DataInput in) throws IOException { this.upFlow = in.readLong(); this.downFlow = in.readLong(); this.sumFlow = in.readLong(); } //6. To output the serialized object later, implement its toString() method @Override public String toString() { return upFlow + "\t" + downFlow + "\t" + sumFlow; } public void set(long upFlow, long downFlow, long sumFlow) { this.upFlow = upFlow; this.downFlow = downFlow; this.sumFlow = sumFlow; } }
- Writing Mapper classes
import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import cn.maoritian.bean.FlowBean; public class FlowCountMapper extends Mapper<LongWritable, Text, Text, FlowBean> { //Four type parameters of Mapper object KEYIN, VALUEIN, KEYOUT, VALUEOUT // KEYIN: Type of input key: LongWritable // VALUEIN: Type of input value: Text (line content) // KEYOUT: Type of output key: Text (mobile number) // VALUEOUT: Type of output value: FlowBean (traffic statistics) Text k = new Text(); FlowBean v = new FlowBean(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1. Get a row String line = value.toString(); // 2. Cut to get fields String[] fields = line.split("\t"); String phoneNum = fields[1]; // Phone number long upFlow = Long.parseLong(fields[fields.length - 3]); // Upstream Flow long downFlow = Long.parseLong(fields[fields.length - 2]); // Downstream Flow // 3. Output k.set(phoneNum); v.set(downFlow, upFlow, upFlow + downFlow); context.write(k, v); } }
- Writing Reducer classes
import java.io.IOException; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import cn.maoritian.bean.FlowBean; public class FlowCountReducer extends Reducer<Text, FlowBean, Text, FlowBean> { // Four type parameters of Reducer object KEYIN, VALUEIN, KEYOUT, VALUEOUT // KEYIN: Type of input key: Text (mobile number) // VALUEIN: Type of input value: FlowBean (Traffic Statistics) // KEYOUT: Type of output key: Text (mobile number) // VALUEOUT: Type of output value: FlowBean (traffic statistics) long sum_upFlow = 0; long sum_downFlow = 0; FlowBean resultBean = new FlowBean(); @Override protected void reduce(Text key, Iterable<FlowBean> values, Context context)throws IOException, InterruptedException { //1. Traversal summation for (FlowBean flowBean : values) { sum_upFlow += flowBean.getUpFlow(); sum_downFlow += flowBean.getDownFlow(); } //2. Output resultBean.set(sum_upFlow, sum_downFlow, sum_upFlow+sum_downFlow); context.write(key, resultBean); } }
- Writing Driver Driver Classes
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import cn.maoritian.bean.FlowBean; public class FlowCountDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { // 1. Get configuration information and encapsulate tasks Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); // 2. Set the jar load path to be the path of the driver class job.setJarByClass(FlowCountDriver.class); // 3. Set up map and reduce classes job.setMapperClass(FlowCountMapper.class); job.setReducerClass(FlowCountReducer.class); // 4. Set map output job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(FlowBean.class); // 5. Set the final output kv type job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); // 6. Set input and output paths FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 7. Submit and Exit boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } }
- FlowBean object for writing traffic statistics