MapReduce programming model
MapReduce divides the whole operation process into two stages: Map stage and Reduce stage
The Map phase consists of a certain number of Map tasks
Input data format analysis: InputFormat
Input data processing: Mapper
Data grouping: Partitioner
The Reduce phase consists of a certain number of Reduce tasks
Data remote copy
Data is sorted by key
Data processing: Reducer
Data output format: OutputFormat
Map stage
InputFormat (default TextInputFormat)
Mapper
Combiner(local Reducer)
Partitioner
Reduce stage
Reducer
OutputFormat (default TextOutputFormat)
Java programming interface
Java programming interface;
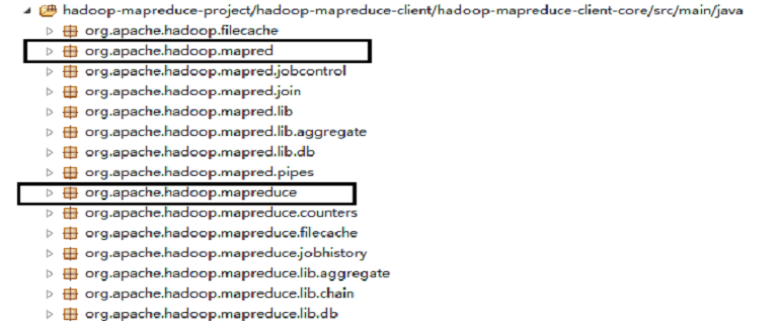
Old API: java package: org.apache.hadoop.mapred
New API: java package: org.apache.hadoop.mapreduce
New API has better expansibility;
The two programming interfaces are only exposed to users in different forms, and the internal execution engine is the same;
Java old and new API
Starting from Hadoop 1.0.0, all distributions contain both old and new API s;
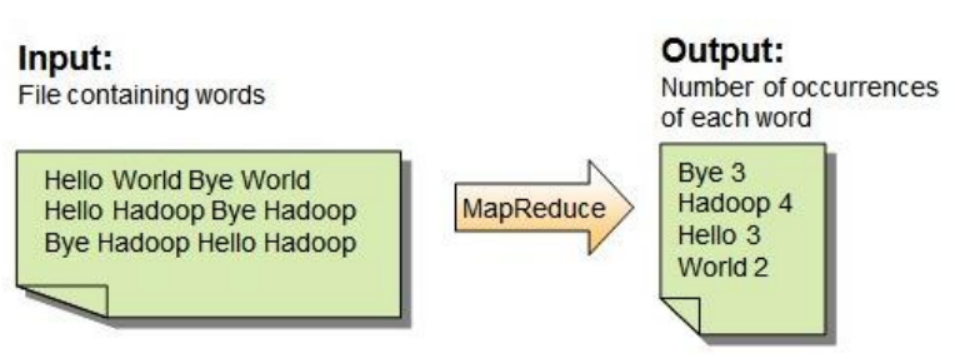
Example 1: WordCount problem
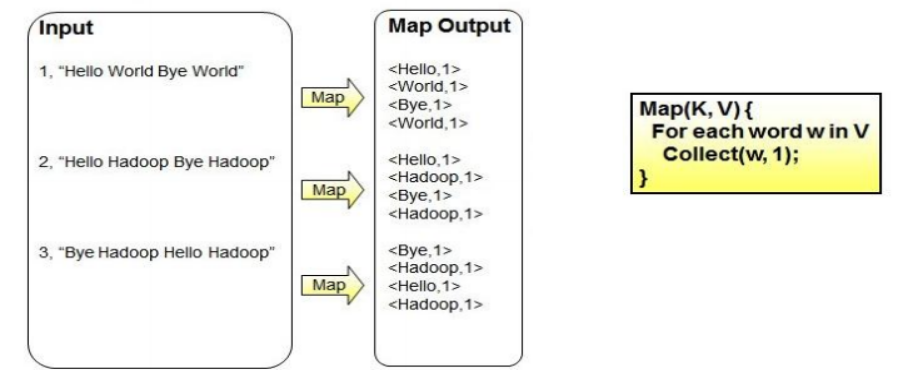
WordCount problem - map stage
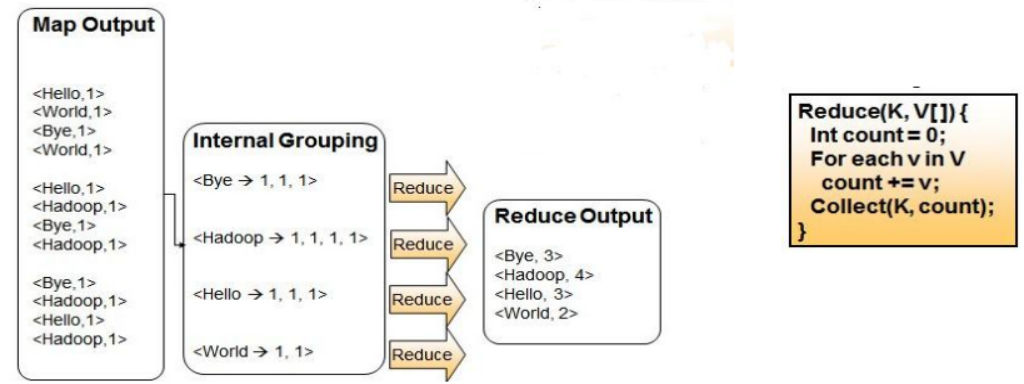
WordCount problem - reduce phase
WordCount problem design and implementation of mapper

WordCount problem: design and implementation of reducer

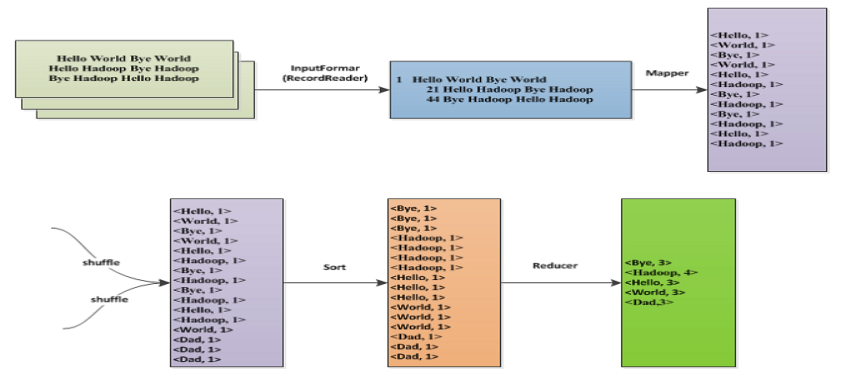
WordCount problem - data flow
Sample code
package com.vip; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * Word statistics * @author huang * */ public class WordCountTest { public static class MyMapper extends Mapper<Object, Text, Text, IntWritable>{ //First define two outputs, k2,v2 Text k2 = new Text() ; IntWritable v2 = new IntWritable() ; /* * hello you * hello me * * 1.<k1,v2> It's the form of < 0, hello you >, < 10, hello me > * Convert to * 2.<k2,v2>--> <hello,1><you,1><hello,1><me,1> * */ @Override protected void map(Object key, Text value, Context context) throws IOException, InterruptedException { //Process the data in each line to get the word String[] words = value.toString().split(" "); for (String word : words) { k2.set(word); //Word is the word in every line v2.set(1); //The number of times each word appears is 1 context.write(k2, v2); //output } } } //3. partition all k2 and v2 output //4. After the shuffle phase, the result is < Hello, {1,1} > < me, {1} > < you, {1} > //Phase 3 and 4 are all done by hadoop framework itself //reduce public static class MyReduce extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { //Define two outputs first IntWritable v3 = new IntWritable() ; int count = 0 ; for (IntWritable value : values) { count += value.get() ; } v3.set(count); //Output result data context.write(key, v3); } } //We have finished the function writing of map and reduce, and put them together to mapreduce for execution public static void main(String[] args) throws Exception { //Load configuration information Configuration conf = new Configuration() ; //Set tasks Job job = Job.getInstance(conf, "word count") ; job.setJarByClass(WordCountTest.class); //Specify the mapper/reducer business class to be used by the job job.setMapperClass(MyMapper.class); job.setReducerClass(MyReduce.class); //Specifies the kv type of the final output data job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //Specify the directory of the job's input original file FileInputFormat.addInputPath(job, new Path(args[0])); //Specify the directory where the output of the job is located FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true)?0:1) ; } }
package com.vip; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; //Maximum value public class MapReduceCaseMax extends Configured implements Tool{ //Writing map public static class MaxMapper extends Mapper<Object, Text, LongWritable, NullWritable>{ //Define a minimum long max = Long.MIN_VALUE ; @Override protected void map(Object key, Text value, Context context) throws IOException, InterruptedException { //Cut string, default separator space, tab StringTokenizer st = new StringTokenizer(value.toString()) ; while(st.hasMoreTokens()){ //Get two values String num1 = st.nextToken() ; String num2 = st.nextToken() ; //Conversion type long n1 = Long.parseLong(num1) ; long n2 = Long.parseLong(num2) ; //Judgement and comparison if(n1 > max){ max = n1 ; } if(n2 > max){ max = n2 ; } } } // @Override protected void cleanup(Context context) throws IOException, InterruptedException { context.write(new LongWritable(max), NullWritable.get()); } } @Override public int run(String[] args) throws Exception { /*Set task and main class*/ Job job = Job.getInstance(getConf(), "MaxFiles") ; job.setJarByClass(MapReduceCaseMax.class); /*Set the class of the map method*/ job.setMapperClass(MaxMapper.class); /*Set the type of key and value output*/ job.setOutputKeyClass(LongWritable.class); job.setOutputValueClass(NullWritable.class); /*Set input and output parameters*/ FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); /*Submit the job to the cluster and wait for the task to complete*/ boolean isSuccess = job.waitForCompletion(true); return isSuccess ? 0 : 1 ; } public static void main(String[] args) throws Exception { int res = ToolRunner.run(new MapReduceCaseMax(), args) ; System.exit(res); } }