Hadoop Distributed File System (HDFS) is a Java-based distributed file system.
Distributed, scalable and portable file systems are designed to span large clusters of commercial servers. The design of HDFS is based on Google File System (GFS). https://ai.google/research/pubs/pub51) . Like many other distributed file systems, HDFS has a large amount of data and provides transparent access to many clients.
HDFS stores very large files in a reliable and scalable manner: PB(1PB=1024TB, for very large files), GB and MB. It is done using block-structured file systems. A single file is split into fixed-size blocks and stored on computers in the cluster. Files consisting of multiple blocks usually do not store all blocks in one machine.
HDFS ensures reliability by replicating blocks and distributing copies in clusters. The default replication factor is 3, which means that each block exists three times on the cluster. Block-level replication ensures data availability even if a single machine fails.
This chapter first introduces the core concepts of HDFS and explains how to use native built-in commands to interact with the file system.
HDFS overview
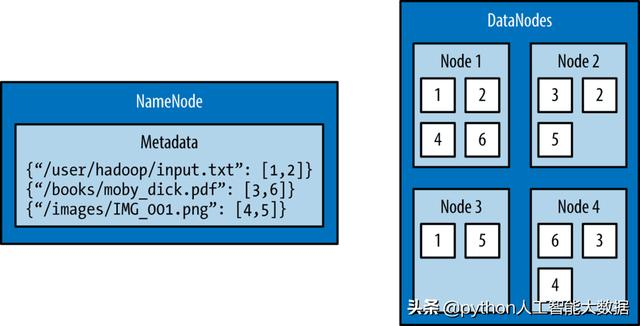
The architecture design of HDFS consists of two processes: a NameNode process saves metadata of the file system and one or more DataNode process blocks. NameNode and DataNode can run on one machine, but HDFS clusters usually include dedicated machines running NameNode processes, and possibly thousands of computers running DataNode processes.
NameNode is the most important machine in HDFS. It stores metadata of the entire file system: file name, file permissions, and the location of the corresponding block for each file. To allow fast access, NameNode stores the entire metadata structure in memory.
NameNode also tracks block replication to ensure that machine failures do not result in data loss. Because NameNode has a single point of failure, the second NameNode can be used to generate a snapshot of the main NameNode memory structure, thereby reducing the risk of data loss when NameNode fails.
The machine that stores blocks in HDFS is called DataNode. DataNode is usually a commercial machine with large storage capacity. Unlike NameNode, a small amount of DataNode fails and HDFS will continue to function properly. When DataNode fails, NameNode copies the missing blocks to ensure a minimum number of replicates.
HDFS interaction
Interacting with HDFS mainly uses HDFS scripts
$ hdfs COMMAND [-option <arg>]
Reference material
- python test development project reality-directory
- python Toolbook Download - Continuous Update
- python 3.7 Quick Start Tutorial - Catalogue
- Original address
- python test development library
- [Massive downloads of books related to this article] ( https://github.com/china-testing/python-api-tesing/blob/master/books.md
General File Operation
Perform basic file operations on HDFS using dfs subcommands. The dfs command supports many file operations similar to those in the Linux shell.
$ hdfs COMMAND [-option <arg>]
Note: The hdfs command runs with the privileges of the system user. The following example runs with the user of "hduser".
To list the contents of directories in HDFS, use the - ls command:
$ hdfs dfs -mkdir /user $ hdfs dfs -mkdir /user/hduser $ hdfs dfs -ls / Found 1 items drwxr-xr-x - hduser_ supergroup 0 2019-01-21 16:37 /user $ hdfs dfs -ls -R /user drwxr-xr-x - hduser_ supergroup 0 2019-01-21 16:45 /user/hduser
put and get data
$ hdfs dfs -put /home/hduser_/input.txt /user/hduser $ hdfs dfs -cat /user/hduser/input.txt https://china-testing.github.io/ $ dfs -get /user/hduser/input.txt /home/hduser_/test.txt
Command Reference
$ hdfs dfs Usage: hadoop fs [generic options] [-appendToFile <localsrc> ... <dst>] [-cat [-ignoreCrc] <src> ...] [-checksum <src> ...] [-chgrp [-R] GROUP PATH...] [-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...] [-chown [-R] [OWNER][:[GROUP]] PATH...] [-copyFromLocal [-f] [-p] [-l] [-d] <localsrc> ... <dst>] [-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] [-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] <path> ...] [-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>] [-createSnapshot <snapshotDir> [<snapshotName>]] [-deleteSnapshot <snapshotDir> <snapshotName>] [-df [-h] [<path> ...]] [-du [-s] [-h] [-x] <path> ...] [-expunge] [-find <path> ... <expression> ...] [-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] [-getfacl [-R] <path>] [-getfattr [-R] {-n name | -d} [-e en] <path>] [-getmerge [-nl] [-skip-empty-file] <src> <localdst>] [-help [cmd ...]] [-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [<path> ...]] [-mkdir [-p] <path> ...] [-moveFromLocal <localsrc> ... <dst>] [-moveToLocal <src> <localdst>] [-mv <src> ... <dst>] [-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>] [-renameSnapshot <snapshotDir> <oldName> <newName>] [-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...] [-rmdir [--ignore-fail-on-non-empty] <dir> ...] [-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]] [-setfattr {-n name [-v value] | -x name} <path>] [-setrep [-R] [-w] <rep> <path> ...] [-stat [format] <path> ...] [-tail [-f] <file>] [-test -[defsz] <path>] [-text [-ignoreCrc] <src> ...] [-touchz <path> ...] [-truncate [-w] <length> <path> ...] [-usage [cmd ...]] Generic options supported are: -conf <configuration file> specify an application configuration file -D <property=value> define a value for a given property -fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations. -jt <local|resourcemanager:port> specify a ResourceManager -files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster -libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath -archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines The general command line syntax is: command [genericOptions] [commandOptions]
More help can be HDFS dfs-usage or HDFS dfs-help