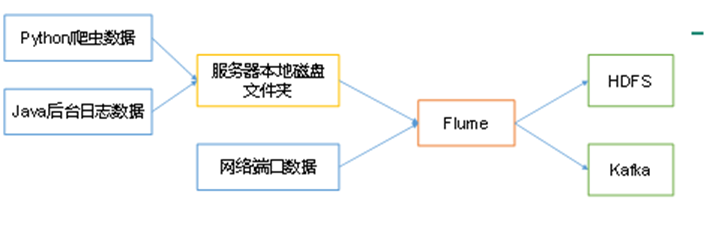
Flume Log Collection System
- Summary
- operating mechanism
- Architecture of Flume Acquisition System
- Flume installation deployment
- A Simple Case of Flume
- Flume custom MySQL Source
- Custom Source Description
- Custom MySQL Source Composition
- Customize MySQL Source steps
- code implementation
- test
- Knowledge Expansion (Understanding)
- Enterprise Real Interview Questions
Summary
Flume is a highly available, reliable and distributed software for collecting, aggregating and transferring massive logs provided by Cloudera.
The core of Flume is to collect data from a data source and then send the collected data to a designated destination (sink). In order to ensure the success of the transport process, before sending to the destination (sink), the data will be cached first. After the data really reaches the destination (sink), flume deletes its cached data.
Flume supports customizing all kinds of data senders to collect all types of data, while Flume supports customizing all kinds of data receivers to ultimately store data. The general acquisition requirement can be realized by simple configuration of flume. For special scenarios, it also has a good ability to customize and expand. Therefore, flume can be applied to most daily constant data acquisition scenarios.
Flume currently has two versions. Flume 0.9X version is called Flume OG (original generation), and Flume 1.X version is called Flume NG (next generation). Flume NG is very different from Flume OG because of its core components, core configuration and code architecture refactoring. Another reason for the change was that Flume was incorporated into apache, and Cloudera Flume was renamed Apache Flume.
Official website: http://flume.apache.org/
operating mechanism
The core role of Flume system is agent, which is a Java process and runs on the log collection node.
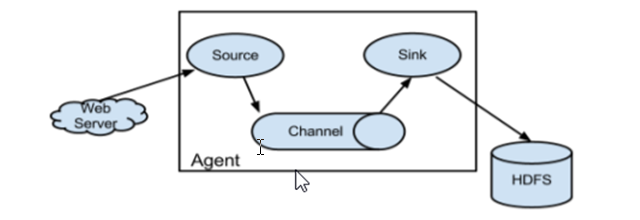
Each agent is equivalent to a data transferor with three components: Source,Channel,Sink
Source: A collection source for docking with data sources to obtain data, including avro, thrift, exec, jms, spooling directory, netcat, syslog, http, legacy
Note:
Avro: A subproject of Apache
Thrift: An RPC Framework for Facebook Open Source
Sink: Sink: Sink: Sink is sinking. The purpose of data collection is to transfer data to the next agent or to the final storage system. Sink component destinations include hdfs, logger, avro, thrift, ipc, file, null, HBase, solr, customization.
Channel: A data transmission channel within an agent for transferring data from source to sink.
In the whole process of data transmission, event flows, which is the most basic unit of data transmission in Flume. Evet encapsulates the transmitted data. If it's a text file, it's usually a row record, and event is also the basic unit of a transaction. Event is a byte array from source, to channel, to sink, and can carry headers information. Event represents the smallest complete unit of data, coming from an external data source to an external destination.
A complete event includes event headers, event body, event information, in which event information is the diary records collected by flume.
Flume comes with two Channels: Memory Channel and File Channel.
Memory Channel is a queue in memory. Memory Channel works in situations where you don't need to care about data loss. If relational data needs to be lost, Memory Channel should not be used because program death, machine downtime, or restart can result in data loss.
File Channel writes all events to disk. Therefore, data will not be lost when the program is shut down or the machine is down.
Architecture of Flume Acquisition System
-
Simple structure
Data acquisition by a single agent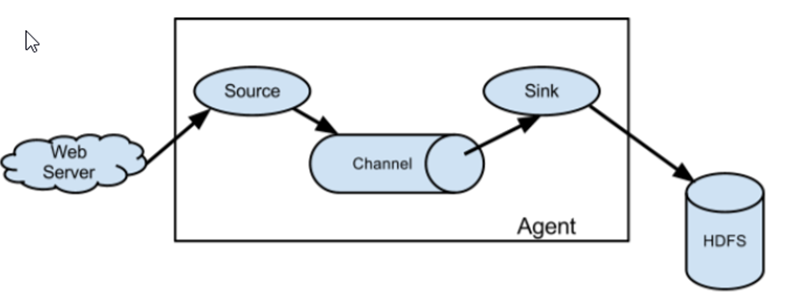
Multiple in series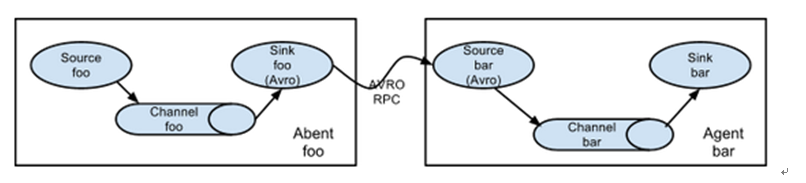
-
Complex structure
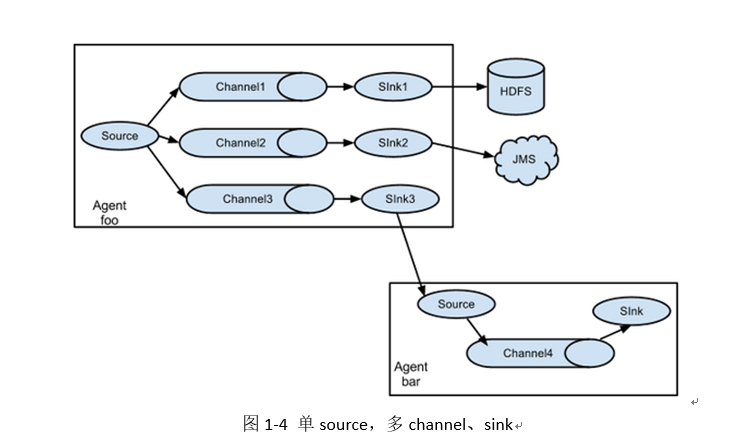
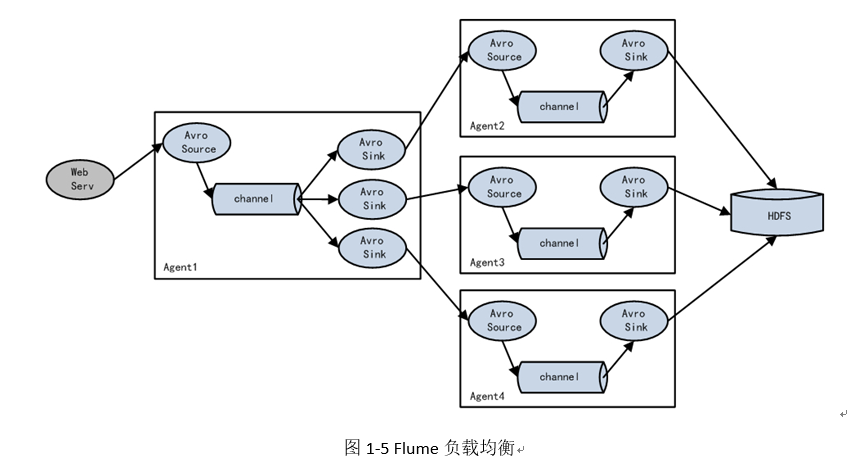
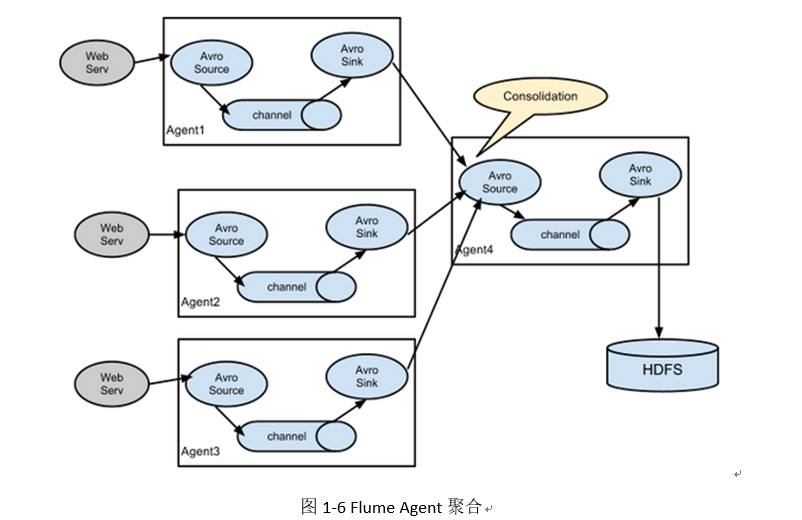
Flume installation deployment
- Upload the installation package to the node where the data source is located and decompress tar-zxvf apache-flume-1.8.0-bin.tar.gz.
- Then enter the flume directory, modify flume-env.sh under conf, and configure JAVA_HOME inside.
- Configure the acquisition scheme according to the data acquisition requirement and describe it in the configuration file (the file name can be customized arbitrarily)
- Specify the configuration file of the acquisition scheme and start the flume agent on the corresponding node.
A Simple Case of Flume
-
Receive the netcat port data and print it on the console.
-
First create a new file in the conf directory of flume
vim netcat-logger.conf# Define the names of components in this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe and configure source component r1 a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe and configure sink components: k1 a1.sinks.k1.type = logger # Describes and configures channel components, which are used here as memory caches a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Describe and configure the connection between source channel sink a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
-
Start agent to collect data:
bin/flume-ng agent -c conf -f conf/netcat-logger.conf -n a1 - Dflume.root.logger=INFO,console
- c conf specifies the directory where flume's own configuration files are located
- f con f/netcat-logger.con specifies the acquisition scheme we describe
- n a1 specifies the name of our agent -
test
The first step is to send data to the port where the agent collects and listens, so that the agent has data to adopt. On any machine that can connect with agent nodes:
nc localhost 44444
-
-
Collect directories to HDFS
Collection requirements:Under a specific directory of the server, new files will be generated continuously. Whenever new files appear, it is necessary to collect the files into HDFS.
Define three key elements according to needs
- Source is the source of collection - the directory of monitoring files: spooldir.
- The sink target is sink - HDFS file system: hdfs sink.
- Channel, the transfer channel between source and sink, can be used either as file channel or as memory channel.
Configuration File Writing
vim dirToHDFS.conf# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source ##Note: The same name file cannot be duplicated in the monitoring object a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /root/logs a1.sources.r1.fileHeader = true # Describe the sink a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/ a1.sinks.k1.hdfs.filePrefix = events a1.sinks.k1.hdfs.round = true a1.sinks.k1.hdfs.roundValue = 10 a1.sinks.k1.hdfs.roundUnit = minute a1.sinks.k1.hdfs.rollInterval = 3 a1.sinks.k1.hdfs.rollSize = 20 a1.sinks.k1.hdfs.rollCount = 5 a1.sinks.k1.hdfs.batchSize = 1 a1.sinks.k1.hdfs.useLocalTimeStamp = true #The generated file type, which defaults to Sequencefile available DataStream, is plain text a1.sinks.k1.hdfs.fileType = DataStream # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
Channel parameter interpretation:
capacity: Default the maximum number of event s that can be stored in this channel
Trasaction Capacity: Maximum number of event s that can be obtained from source or sent to sink at a time
Start flumebin/flume-ng agent -c conf -f conf/dirToHDFS.conf -n a1 -Dflume.root.logger=INFO,console
-
Collect files to HDFS
Collection requirements:For example, business systems use log4j to generate logs, and the content of logs is increasing. It is necessary to collect the data appended to the log files into hdfs in real time.
Define three key elements according to needs
- Collection source - Monitoring File Content Update: exec'tail-F file'
- Sinking target, sink-HDFS file system: hdfs sink
- Channel, the transfer channel between source and sink, can be used either as file channel or as memory channel.
Configuration File Writing
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /root/logs/test.log a1.sources.r1.channels = c1 # Describe the sink a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path = /flume/tailout/%y-%m-%d/%H%M/ a1.sinks.k1.hdfs.filePrefix = events a1.sinks.k1.hdfs.round = true a1.sinks.k1.hdfs.roundValue = 10 a1.sinks.k1.hdfs.roundUnit = minute a1.sinks.k1.hdfs.rollInterval = 3 a1.sinks.k1.hdfs.rollSize = 20 a1.sinks.k1.hdfs.rollCount = 5 a1.sinks.k1.hdfs.batchSize = 1 a1.sinks.k1.hdfs.useLocalTimeStamp = true #Generated file type, default is Sequencefile, available DataStream, is plain text a1.sinks.k1.hdfs.fileType = DataStream # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
Flume custom MySQL Source
Custom Source Description
Source is the component responsible for receiving data to Flume Agent. Source components can handle various types and formats of log data, including avro, thrift, exec, jms, spooling directory, netcat, sequence generator, syslog, http, legacy. There are many types of source provided by the government, but sometimes they can not meet the actual development needs. At this time, we need to customize some Sources according to the actual needs.
For example: real-time monitoring MySQL, data transmission from MySQL to HDFS or other storage framework, so we need to implement MySQL Source ourselves.
Officials also provide a custom source interface:
Description: https://flume.apache.org/Flume Developer Guide.html#source
Custom MySQL Source Composition

Customize MySQL Source steps
Customizing MySqlSource according to official instructions requires inheriting the AbstractSource class and implementing Configurable and SollableSource interfaces. To achieve the corresponding method:
getBackOffSleepIncrement()// Not yet available
getMaxBackOffSleepInterval()// Not yet available
configure(Context context) // initialize context
Procedure ()// Getting data (Getting data from MySql is a complicated business process, so we define a special class, SQL SourceHelper, to handle the interaction with MySql), encapsulate it as Event and write it to Channel, which is called circularly.
stop()// Close related resources
code implementation
Importing POM dependencies
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.7.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
</dependencies>
Add configuration information
Add jdbc.properties and log4j. properties under ClassPath
jdbc.properties:
dbDriver=com.mysql.jdbc.Driver dbUrl=jdbc:mysql://hadoop102:3306/mysqlsource?useUnicode=true&characterEncoding=utf-8 dbUser=root dbPassword=000000
log4j. properties:
#--------console----------- log4j.rootLogger=info,myconsole,myfile log4j.appender.myconsole=org.apache.log4j.ConsoleAppender log4j.appender.myconsole.layout=org.apache.log4j.SimpleLayout #log4j.appender.myconsole.layout.ConversionPattern =%d [%t] %-5p [%c] - %m%n #log4j.rootLogger=error,myfile log4j.appender.myfile=org.apache.log4j.DailyRollingFileAppender log4j.appender.myfile.File=/tmp/flume.log log4j.appender.myfile.layout=org.apache.log4j.PatternLayout log4j.appender.myfile.layout.ConversionPattern =%d [%t] %-5p [%c] - %m%n
SQLSourceHelper
-
Attribute description:
attribute Description (default in parentheses) |
RunQuery Delay | Query Interval (10000)|
| batchSize | cache size (100)|
| startFrom | Query statement start id (0)|
| CurrtIndex | Query statement current id, need to look up metadata table before each query|
| recordSixe | Number of query returns|
| table | monitored table name|
| columnsToSelect | Query field (*)|
| CusmQuery | User-passed Query Statement|
| query | query statement|
| defaultCharsetResultSet | Encoding Format (UTF-8)| -
Method Description:
Method Explain SQLSourceHelper(Context context) Constructing Method, Initializing Attributes and Obtaining JDBC Connections InitConnection(String url, String user, String pw) Get the JDBC connection checkMandatoryProperties() Verify whether the relevant properties are set (additions can be made in actual development) buildQuery() Construct sql statement according to actual situation, return value String executeQuery() Execute query operation of sql statement, return value List < List > getAllRows(List<List> queryResult) Converting the query results to String facilitates subsequent operations updateOffset2DB(int size) Write offset to the metadata table based on the results of each query execSql(String sql) Executing sql statement method concretely getStatusDBIndex(int startFrom) Getting offset in metadata table queryOne(String sql) Method of obtaining offset actual sql statement execution in metadata table close() close resource -
code analysis
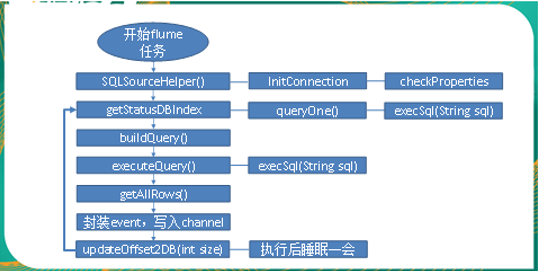
-
code implementation
import org.apache.flume.Context; import org.apache.flume.conf.ConfigurationException; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.io.IOException; import java.sql.*; import java.text.ParseException; import java.util.ArrayList; import java.util.List; import java.util.Properties; public class SQLSourceHelper { private static final Logger LOG = LoggerFactory.getLogger(SQLSourceHelper.class); private int runQueryDelay, //Time interval between two queries startFrom, //Start id currentIndex, //Current id recordSixe = 0, //Number of returned results per query maxRow; //Maximum number of bars per query private String table, //Tables to be operated on columnsToSelect, //Columns of user-incoming queries customQuery, //Input Query Statement by User query, //Constructed Query Statement defaultCharsetResultSet;//Coding set //Context, used to retrieve configuration files private Context context; //Assignment of a defined variable (default value) can be modified in the configuration file of the flume task private static final int DEFAULT_QUERY_DELAY = 10000; private static final int DEFAULT_START_VALUE = 0; private static final int DEFAULT_MAX_ROWS = 2000; private static final String DEFAULT_COLUMNS_SELECT = "*"; private static final String DEFAULT_CHARSET_RESULTSET = "UTF-8"; private static Connection conn = null; private static PreparedStatement ps = null; private static String connectionURL, connectionUserName, connectionPassword; //Loading static resources static { Properties p = new Properties(); try { p.load(SQLSourceHelper.class.getClassLoader().getResourceAsStream("jdbc.properties")); connectionURL = p.getProperty("dbUrl"); connectionUserName = p.getProperty("dbUser"); connectionPassword = p.getProperty("dbPassword"); Class.forName(p.getProperty("dbDriver")); } catch (IOException | ClassNotFoundException e) { LOG.error(e.toString()); } } //Get the JDBC connection private static Connection InitConnection(String url, String user, String pw) { try { Connection conn = DriverManager.getConnection(url, user, pw); if (conn == null) throw new SQLException(); return conn; } catch (SQLException e) { e.printStackTrace(); } return null; } //Construction method SQLSourceHelper(Context context) throws ParseException { //Initialization context this.context = context; //Default parameters: Get the parameters in the flume task configuration file and use the default values if you can't read them. this.columnsToSelect = context.getString("columns.to.select", DEFAULT_COLUMNS_SELECT); this.runQueryDelay = context.getInteger("run.query.delay", DEFAULT_QUERY_DELAY); this.startFrom = context.getInteger("start.from", DEFAULT_START_VALUE); this.defaultCharsetResultSet = context.getString("default.charset.resultset", DEFAULT_CHARSET_RESULTSET); //No default parameters: Get the parameters in the flume task configuration file this.table = context.getString("table"); this.customQuery = context.getString("custom.query"); connectionURL = context.getString("connection.url"); connectionUserName = context.getString("connection.user"); connectionPassword = context.getString("connection.password"); conn = InitConnection(connectionURL, connectionUserName, connectionPassword); //Check the configuration information and throw an exception if there is no default parameter and no assignment checkMandatoryProperties(); //Get the current id currentIndex = getStatusDBIndex(startFrom); //Building Query Statements query = buildQuery(); } //Check the configuration information (tables, query statements, and database connection parameters) private void checkMandatoryProperties() { if (table == null) { throw new ConfigurationException("property table not set"); } if (connectionURL == null) { throw new ConfigurationException("connection.url property not set"); } if (connectionUserName == null) { throw new ConfigurationException("connection.user property not set"); } if (connectionPassword == null) { throw new ConfigurationException("connection.password property not set"); } } //Constructing sql statements private String buildQuery() { String sql = ""; //Get the current id currentIndex = getStatusDBIndex(startFrom); LOG.info(currentIndex + ""); if (customQuery == null) { sql = "SELECT " + columnsToSelect + " FROM " + table; } else { sql = customQuery; } StringBuilder execSql = new StringBuilder(sql); //Using id as offset if (!sql.contains("where")) { execSql.append(" where "); execSql.append("id").append(">").append(currentIndex); return execSql.toString(); } else { int length = execSql.toString().length(); return execSql.toString().substring(0, length - String.valueOf(currentIndex).length()) + currentIndex; } } //Execute queries List<List<Object>> executeQuery() { try { //Every time a query is executed, sql is regenerated because the id is different customQuery = buildQuery(); //A collection of results List<List<Object>> results = new ArrayList<>(); if (ps == null) { // ps = conn.prepareStatement(customQuery); } ResultSet result = ps.executeQuery(customQuery); while (result.next()) { //A collection of data (multiple columns) List<Object> row = new ArrayList<>(); //Put the returned results into the collection for (int i = 1; i <= result.getMetaData().getColumnCount(); i++) { row.add(result.getObject(i)); } results.add(row); } LOG.info("execSql:" + customQuery + "\nresultSize:" + results.size()); return results; } catch (SQLException e) { LOG.error(e.toString()); // Reconnection conn = InitConnection(connectionURL, connectionUserName, connectionPassword); } return null; } //Convert the result set to a string, each data is a list set, and each small list set is converted to a string. List<String> getAllRows(List<List<Object>> queryResult) { List<String> allRows = new ArrayList<>(); if (queryResult == null || queryResult.isEmpty()) return allRows; StringBuilder row = new StringBuilder(); for (List<Object> rawRow : queryResult) { Object value = null; for (Object aRawRow : rawRow) { value = aRawRow; if (value == null) { row.append(","); } else { row.append(aRawRow.toString()).append(","); } } allRows.add(row.toString()); row = new StringBuilder(); } return allRows; } //Update the offset metadata status and call it every time the result set is returned. The offset value of each query must be recorded for intermittent running data in the program, with id as offset void updateOffset2DB(int size) { //Use source_tab as KEY, insert if it does not exist, and update if it does (each source table corresponds to a record) String sql = "insert into flume_meta(source_tab,currentIndex) VALUES('" + this.table + "','" + (recordSixe += size) + "') on DUPLICATE key update source_tab=values(source_tab),currentIndex=values(currentIndex)"; LOG.info("updateStatus Sql:" + sql); execSql(sql); } //Execute sql statements private void execSql(String sql) { try { ps = conn.prepareStatement(sql); LOG.info("exec::" + sql); ps.execute(); } catch (SQLException e) { e.printStackTrace(); } } //offset to get the current id private Integer getStatusDBIndex(int startFrom) { //Query the current id from the flume_meta table String dbIndex = queryOne("select currentIndex from flume_meta where source_tab='" + table + "'"); if (dbIndex != null) { return Integer.parseInt(dbIndex); } //If there is no data, it means that it is the first query or that the data has not been stored in the data table, returning the original value. return startFrom; } //Execution statement to query a data (current id) private String queryOne(String sql) { ResultSet result = null; try { ps = conn.prepareStatement(sql); result = ps.executeQuery(); while (result.next()) { return result.getString(1); } } catch (SQLException e) { e.printStackTrace(); } return null; } //Closing related resources void close() { try { ps.close(); conn.close(); } catch (SQLException e) { e.printStackTrace(); } } int getCurrentIndex() { return currentIndex; } void setCurrentIndex(int newValue) { currentIndex = newValue; } int getRunQueryDelay() { return runQueryDelay; } String getQuery() { return query; } String getConnectionURL() { return connectionURL; } private boolean isCustomQuerySet() { return (customQuery != null); } Context getContext() { return context; } public String getConnectionUserName() { return connectionUserName; } public String getConnectionPassword() { return connectionPassword; } String getDefaultCharsetResultSet() { return defaultCharsetResultSet; } }
MySQLSource
Code implementation:
import java.text.ParseException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
public class SQLSource extends AbstractSource implements Configurable, PollableSource {
//Print logs
private static final Logger LOG = LoggerFactory.getLogger(SQLSource.class);
//Define sqlHelper
private SQLSourceHelper sqlSourceHelper;
@Override
public long getBackOffSleepIncrement() {
return 0;
}
@Override
public long getMaxBackOffSleepInterval() {
return 0;
}
@Override
public void configure(Context context) {
try {
//Initialization
sqlSourceHelper = new SQLSourceHelper(context);
} catch (ParseException e) {
e.printStackTrace();
}
}
@Override
public Status process() throws EventDeliveryException {
try {
//Query data table
List<List<Object>> result = sqlSourceHelper.executeQuery();
//Collection of event s
List<Event> events = new ArrayList<>();
//Store event header collection
HashMap<String, String> header = new HashMap<>();
//If there is return data, encapsulate the data as event
if (!result.isEmpty()) {
List<String> allRows = sqlSourceHelper.getAllRows(result);
Event event = null;
for (String row : allRows) {
event = new SimpleEvent();
event.setBody(row.getBytes());
event.setHeaders(header);
events.add(event);
}
//Write event to channel
this.getChannelProcessor().processEventBatch(events);
//Update offset information in data tables
sqlSourceHelper.updateOffset2DB(result.size());
}
//Waiting time
Thread.sleep(sqlSourceHelper.getRunQueryDelay());
return Status.READY;
} catch (InterruptedException e) {
LOG.error("Error procesing row", e);
return Status.BACKOFF;
}
}
@Override
public synchronized void stop() {
LOG.info("Stopping sql source {} ...", getName());
try {
//close resource
sqlSourceHelper.close();
} finally {
super.stop();
}
}
}
test
Jar Packet Homing
- Put MySql driver packages in Flume's lib directory
[atguigu@hadoop102 flume]$ cp \ /opt/sorfware/mysql-libs/mysql-connector-java-5.1.27/mysql-connector-java-5.1.27-bin.jar \ /opt/module/flume/lib/
- Pack the project and place the Jar package in Flume's lib package directory.
Configuration File Homing
- Create a configuration file and open it
[atguigu@hadoop102 job]$ touch mysql.conf [atguigu@hadoop102 job]$ vim mysql.conf
- Add the following
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = com.bw.flume.SQLSource a1.sources.r1.connection.url = jdbc:mysql://192.168.9.102:3306/mysqlsource a1.sources.r1.connection.user = root a1.sources.r1.connection.password = 000000 a1.sources.r1.table = student a1.sources.r1.columns.to.select = * #a1.sources.r1.incremental.column.name = id #a1.sources.r1.incremental.value = 0 a1.sources.r1.run.query.delay=5000 # Describe the sink a1.sinks.k1.type = logger # Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
MySql table ranking
-
Create MySqlSource database
CREATE DATABASE mysqlsource;
-
Create data table Student and metadata table Flume_meta under MySqlSource database
CREATE TABLE `student` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) NOT NULL, PRIMARY KEY (`id`) ); CREATE TABLE `flume_meta` ( `source_tab` varchar(255) NOT NULL, `currentIndex` varchar(255) NOT NULL, PRIMARY KEY (`source_tab`) );
-
Add data to tables
1 zhangsan 2 lisi 3 wangwu 4 zhaoliu
View the results
-
Task execution
[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a1 \ --conf-file job/mysql.conf -Dflume.root.logger=INFO,console
-
Result presentation
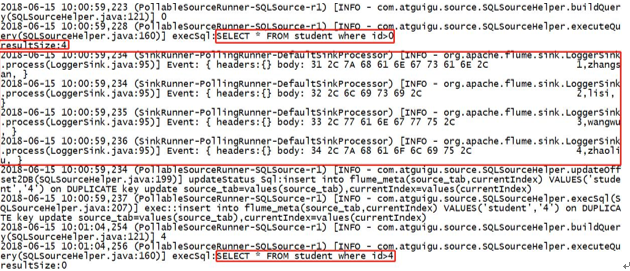
Knowledge Expansion (Understanding)
Common regular expression grammar
| Metacharacters | describe |
|---|---|
| ^ | Matches the starting position of the input string. If the Multiline property of the RegExp object is set, ^ also matches the position after " n" or " r". |
| $ | Matches the end position of the input string. If the Multiline property of the RegExp object is set, $also matches the position before " n" or " r". |
| * | Match any previous subexpression. For example, zo* can match "z", "zo" and "zoo". * Equivalent to {0,}. |
| + | Match the previous subexpression one or more times (greater than or equal to one time). For example, "zo+" can match "zo" and "zoo", but not "z". + Equivalent to {1,}. |
| [a-z] | Character range. Matches any character within the specified range. For example, "[a-z]" can match any lowercase letter character from "a" to "z". Note: Only when hyphens are inside a character group and appear between two characters, can they represent the range of characters; if the beginning of a character group is produced, only the hyphens themselves can be represented. |
Enterprise Real Interview Questions
How do you monitor Flume data transmission?
Use third-party framework Ganglia to monitor Flume in real time.
Flume's Source, Sink, Channel role? What type of Source do you have?
- Effect
Source components are designed to collect data and can process various types and formats of log data, including avro, thrift, exec, jms, spooling directory, netcat, sequence generator, syslog, http, legacy
The Channel component caches the collected data and can be stored in either Moory or File.
Sink components are components used to send data to destinations, including Hdfs, Logger, avro, thrift, ipc, file, Hbase, solr, custom
2. The Source type adopted by our company is:Monitor background logs: exec
Monitor the background log generation port: netcat
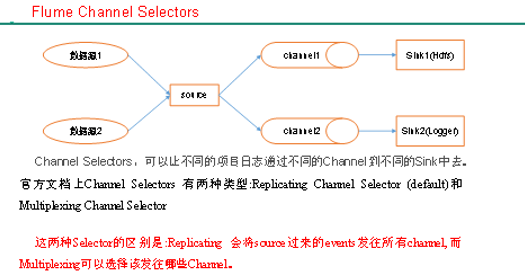
Channel Selectors of Flume
Flume parameter tuning
-
Source
Increasing the number of Sources (increasing the number of FileGroups when using Tair Dir Source) can increase the ability of Sources to read data. For example, when a directory produces too many files, it is necessary to split the file directory into multiple file directories and configure multiple Sources to ensure that Sources have sufficient capacity to obtain the newly generated data.
The batchSize parameter determines the number of events that Source transports to Channel in a batch. Properly increasing this parameter can improve the performance of Source when it transports Event to Channel.
-
Channel
Channel performs best when type chooses memory, but may lose data if the Flume process crashes unexpectedly. Channel's fault tolerance is better when type chooses file, but its performance is worse than memory channel.
Data Dirs can improve performance by configuring multiple directories on different disks when using file Channel.
Capacity parameter determines the maximum number of events that Channel can accommodate. The transactionCapacity parameter determines the maximum number of event entries written by Source to channel and the maximum number of event entries read by Sink from channel each time. Transaction Capacity requires batchSize parameters larger than Source and Link.
-
Sink
Increasing the number of Sinks can increase Sink's ability to consume event s. Sink is not the more the better enough, too much Sink will occupy system resources, resulting in unnecessary waste of system resources.
The batchSize parameter determines the number of events Sink reads from Channel in batches at a time. Properly adjusting this parameter can improve the performance of Sink moving event from Channel.
Transaction mechanism of Flume
Flume transaction mechanism (similar to database transaction mechanism): Flume uses two separate transactions to transfer events from Soucrce to Channel and from Channel to Sink, respectively. For example, spooling directory source creates an event for each line of a file. Once all events in a transaction are passed to Channel and submitted successfully, Soucrce marks the file as complete. Similarly, transactions handle the transfer process from Channel to Sink in a similar way, and if for some reason the event cannot be logged, the transaction will roll back. And all events are kept in Channel, waiting to be relayed.
Why can't Flume collect data without losing it?
Channel storage can be stored in File, and data transmission has its own transactions.