1. Customize the Interceptor
1.1 case requirements
When Flume is used to collect the local logs of the server, different types of logs need to be sent to different analysis systems according to different log types.
1.2 demand analysis: Interceptor and Multiplexing ChannelSelector cases
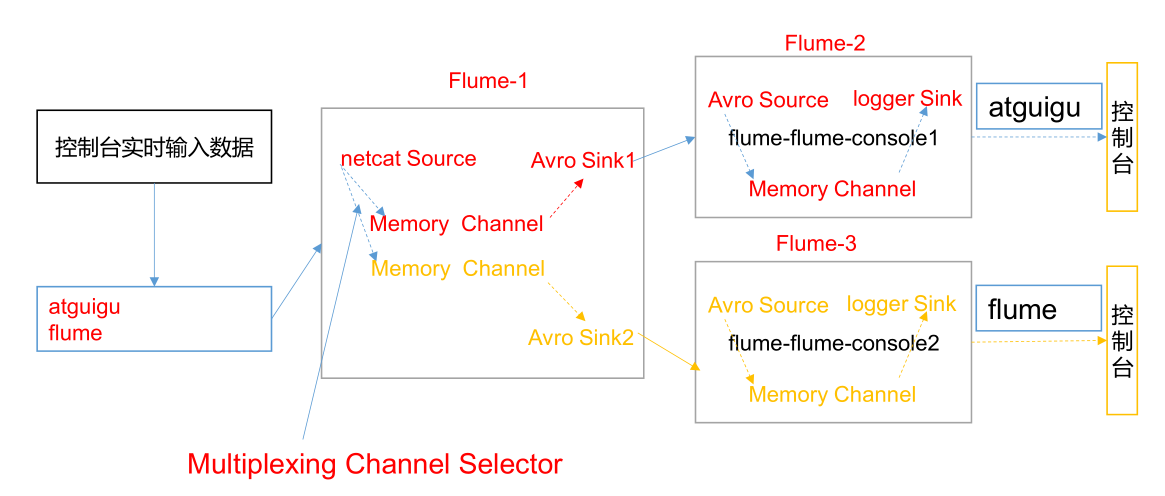
In actual development, there may be many types of logs generated by a server, and different types of logs may need to be sent to different analysis systems. At this time, the Multiplexing structure in Flume topology will be used. The principle of Multiplexing is to send different events to different channels according to the value of a key in the Header of the event. Therefore, we need to customize an Interceptor to assign keys to the headers of different types of events
Different values.
In this case, we simulate logs with port data to simulate whether "bigdata" is included in different types of logs. We need to customize the interceptor to distinguish whether "bigdata" is included in the data and send it to different analysis systems (channels).
1.3 implementation steps
(1) Create a maven project and introduce the following dependencies.
<dependency> <groupId>org.apache.flume</groupId> <artifactId>flume-ng-core</artifactId> <version>1.9.0</version> </dependency>
(2) Define the CustomInterceptor class and implement the Interceptor interface.
package com.bigdata.interceptor;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class TypeInterceptor implements Interceptor {
//Declare a collection of events
private List<Event> addHeaderEvents;
@Override
public void initialize() {
//Initializes a collection of stored events
addHeaderEvents = new ArrayList<>();
}
//Single event interception
@Override
public Event intercept(Event event) {
//1. Get the header information in the event
Map<String, String> headers = event.getHeaders();
//2. Get the body information in the event
String body = new String(event.getBody());
//3. Determine how to add header information according to whether there is "bigdata" in the body
if (body.contains("bigdata")) {
//4. Add header information
headers.put("type", "first");
} else {
//4. Add header information
headers.put("type", "second");
}
return event;
}
//Batch event interception
@Override
public List<Event> intercept(List<Event> events) {
//1. Empty the collection
addHeaderEvents.clear();
//2. Traverse events
for (Event event : events) {
//3. Add header information to each event
addHeaderEvents.add(intercept(event));
}
//4. Return results
return addHeaderEvents;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new TypeInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
(3) Edit flume profile
Configure Flume1 on Hadoop 102 with 1 netcat source, 1 sink group (2 avro sink),
And configure the corresponding ChannelSelector and interceptor.
# Name the components on this agent a1.sources = r1 a1.sinks = k1 k2 a1.channels = c1 c2 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = com.bigdata.flume.interceptor.CustomInterceptor$Builder a1.sources.r1.selector.type = multiplexing a1.sources.r1.selector.header = type a1.sources.r1.selector.mapping.first = c1 a1.sources.r1.selector.mapping.second = c2 # Describe the sink a1.sinks.k1.type = avro a1.sinks.k1.hostname = hadoop103 a1.sinks.k1.port = 4141 a1.sinks.k2.type=avro a1.sinks.k2.hostname = hadoop104 a1.sinks.k2.port = 4242 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Use a channel which buffers events in memory a1.channels.c2.type = memory a1.channels.c2.capacity = 1000 a1.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 c2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c2
Configure an avro source and a logger sink for Flume4 on Hadoop 103.
a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = avro a1.sources.r1.bind = hadoop103 a1.sources.r1.port = 4141 a1.sinks.k1.type = logger a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.sinks.k1.channel = c1 a1.sources.r1.channels = c1
Configure an avro source and a logger sink for Flume3 on Hadoop 104.
a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = avro a1.sources.r1.bind = hadoop104 a1.sources.r1.port = 4242 a1.sinks.k1.type = logger a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.sinks.k1.channel = c1 a1.sources.r1.channels = c1
(4) Start the flume process on Hadoop 102, Hadoop 103 and Hadoop 104 respectively, and pay attention to the sequence.
(5) In Hadoop 102, use netcat to send letters and numbers to localhost:44444.
(6) Observe the logs printed by Hadoop 103 and Hadoop 104.
2 custom Source
2.1 introduction
Source is the component responsible for receiving data to Flume Agent. The source component can handle various types and formats of log data, including avro, thrift, exec, jms, spooling directory, netcat, sequence generator, syslog, http and legacy. There are many official source types, but sometimes they can't
To meet the needs of actual development, we need to customize some source s according to the actual needs.
The official also provides a custom source interface:
https://flume.apache.org/FlumeDeveloperGuide.html#source Customize according to official instructions
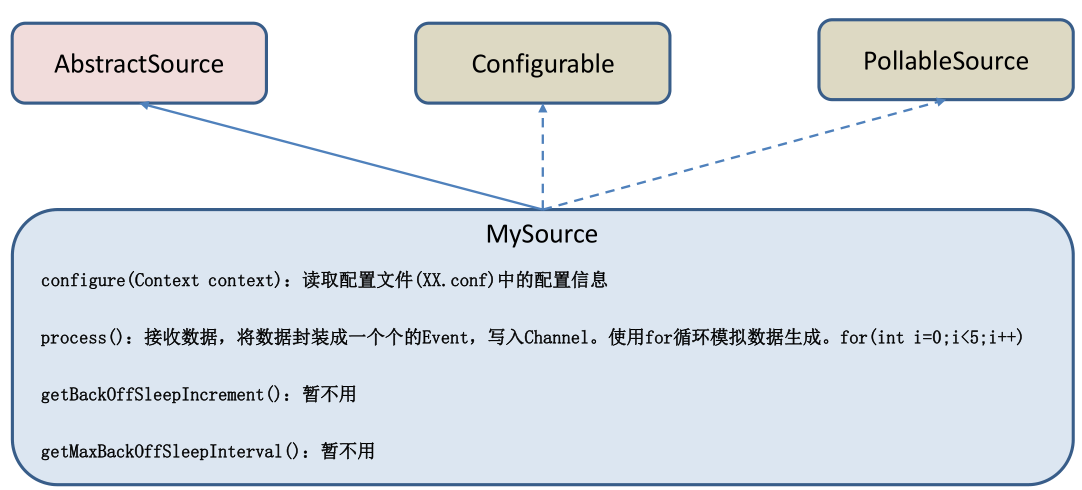
MySource needs to inherit AbstractSource class and implement Configurable and PollableSource interfaces.
Implement corresponding methods:
getBackOffSleepIncrement() //backoff step getmaxbackoffsleepinterval() / / maximum backoff time
Configure (context) / / initialize the context (read the content of the configuration file)
process() / / get the data, package it into an event and write it to channel. This method will be called circularly.
Usage scenario: read MySQL data or other file systems.
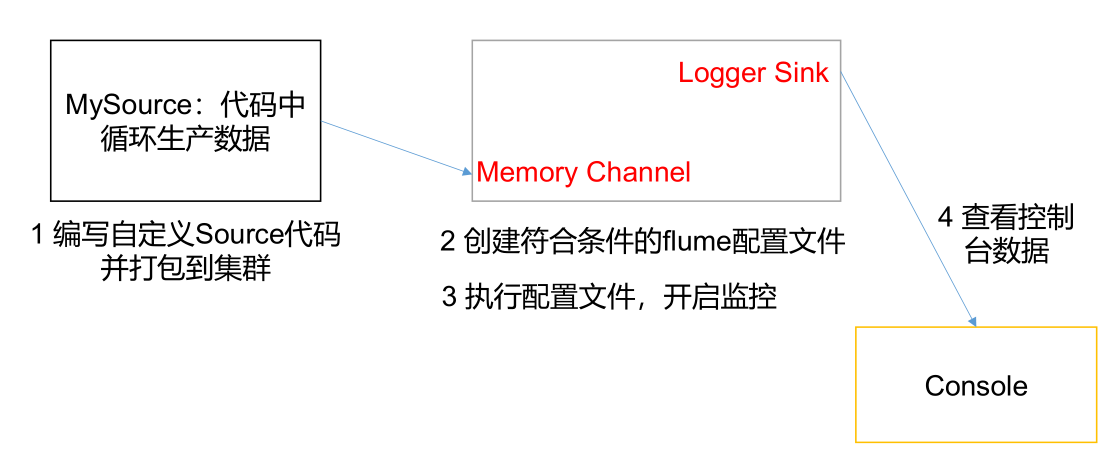
2.2 requirements: user defined Source
Flume is used to receive data, prefix each data and output it to the console. The prefix can be configured from the flume configuration file.
2.3 analysis: user defined Source
2.4 coding
(1) Import pom dependencies
<dependencies> <dependency> <groupId>org.apache.flume</groupId> <artifactId>flume-ng-core</artifactId> <version>1.9.0</version> </dependency>
(2) Write code
package com.bigdata;
import org.apache.flume.Context;
import org.apache.flume.EventDeliveryException;
import org.apache.flume.PollableSource;
import org.apache.flume.conf.Configurable;
import org.apache.flume.event.SimpleEvent;
import org.apache.flume.source.AbstractSource;
import java.util.HashMap;
public class MySource extends AbstractSource implements
Configurable, PollableSource {
//Define the fields that the configuration file will read in the future
private Long delay;
private String field;
//Initialize configuration information
@Override
public void configure(Context context) {
delay = context.getLong("delay");
field = context.getString("field", "Hello!");
}
@Override
public Status process() throws EventDeliveryException {
try {
//Create event header information
HashMap<String, String> hearderMap = new HashMap<>();
//Create event
SimpleEvent event = new SimpleEvent();
//Loop encapsulation event
for (int i = 0; i < 5; i++) {
//Set header information for events
event.setHeaders(hearderMap);
//Set content for event
event.setBody((field + i).getBytes());
//Write events to channel
getChannelProcessor().processEvent(event);
Thread.sleep(delay);
}
} catch (Exception e) {
e.printStackTrace();
return Status.BACKOFF;
}
return Status.READY;
}
@Override
public long getBackOffSleepIncrement() {
return 0;
}
@Override
public long getMaxBackOffSleepInterval() {
return 0;
}
}
2.5 testing
(1) Pack
Package the written code and put it in the lib directory of flume (/ opt/module/flume).
(2) Configuration file
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = com.bigdata.MySource a1.sources.r1.delay = 1000 #a1.sources.r1.field = bigdata # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
(3) Open task
[bigdata@hadoop102 flume]$ pwd /opt/module/flume [bigdata@hadoop102 flume]$ bin/flume-ng agent -c conf/ -f job/mysource.conf -n a1 -Dflume.root.logger=INFO,console
(4) Result display

3. Customize Sink
3.1 introduction
Sink constantly polls events in the Channel and removes them in batches, and writes these events in batches to the storage or indexing system, or is sent to another Flume Agent.
Sink is completely transactional. Before bulk deleting data from the Channel, each sink starts a transaction with the Channel. Once batch events are successfully written out to the storage system or the next Flume Agent, sink will commit transactions using the Channel. Once the transaction is committed, the Channel deletes the event from its own internal buffer.
Sink component destinations include hdfs, logger, avro, thrift, ipc, file, null, HBase, solr, and custom. There are many types of sink officially provided, but sometimes they can not meet the needs of actual development. At this time, we need to customize some sink according to the actual needs.
The official also provides a user-defined sink interface:
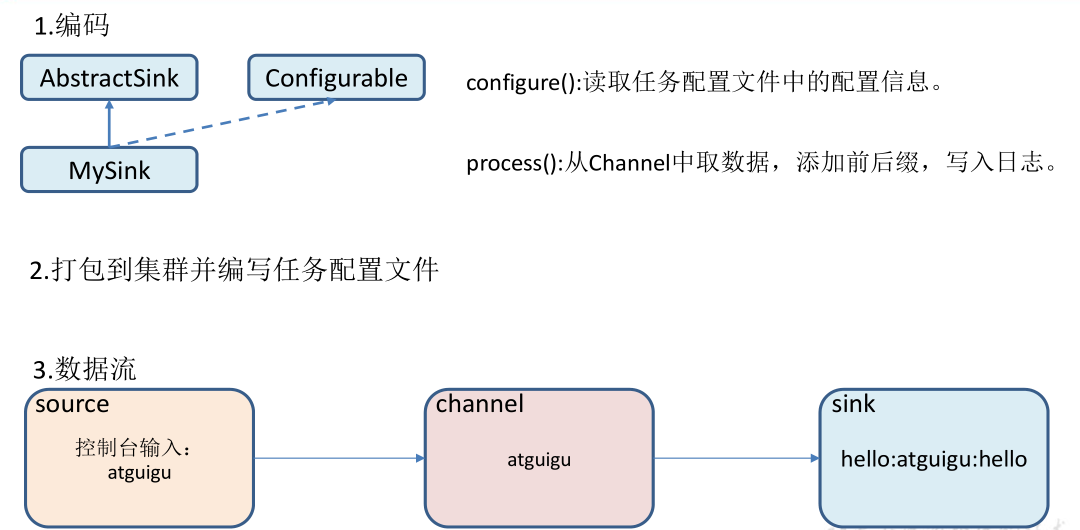
https://flume.apache.org/FlumeDeveloperGuide.html#sink According to the official instructions, customizing MySink needs to inherit the AbstractSink class and implement the Configurable interface.
Implement corresponding methods:
Configure (context) / / initialize the context (read the content of the configuration file)
process() / / read and obtain data (event) from the Channel. This method will be called circularly.
Usage scenario: read Channel data and write it to MySQL or other file systems.
3.2 requirements
Flume is used to receive data, add prefixes and suffixes to each data at the Sink end, and output to the console. The prefix and suffix can be configured in the flume task configuration file.
Process analysis:
3.3 coding
package com.bigdata;
import org.apache.flume.*;
import org.apache.flume.conf.Configurable;
import org.apache.flume.sink.AbstractSink;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class MySink extends AbstractSink implements Configurable {
//Create Logger object
private static final Logger LOG =
LoggerFactory.getLogger(AbstractSink.class);
private String prefix;
private String suffix;
@Override
public Status process() throws EventDeliveryException {
//Declare return value status information
Status status;
//Gets the Channel bound by the current Sink
Channel ch = getChannel();
//Get transaction
Transaction txn = ch.getTransaction();
//Declare event
Event event;
//Open transaction
txn.begin();
//Read the events in the Channel until the end of the loop is read
while (true) {
event = ch.take();
if (event != null) {
break;
}
}
try {
//Handling events (printing)
LOG.info(prefix + new String(event.getBody()) +
suffix);
//Transaction commit
txn.commit();
status = Status.READY;
} catch (Exception e) {
//Exception encountered, transaction rolled back
txn.rollback();
status = Status.BACKOFF;
} finally {
//Close transaction
txn.close();
}
return status;
}
@Override
public void configure(Context context) {
//Read the contents of the configuration file, with default values
prefix = context.getString("prefix", "hello:");
//Read the contents of the configuration file without default value
suffix = context.getString("suffix");
}
}
3.4 testing
(1) Pack
Package the written code and put it in the lib directory of flume (/ opt/module/flume).
(2) Configuration file
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = com.bigdata.MySink #a1.sinks.k1.prefix = bigdata: a1.sinks.k1.suffix = :bigdata # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
(3) Open task
[bigdata@hadoop102 flume]$ bin/flume-ng agent -c conf/ -f job/mysink.conf -n a1 -Dflume.root.logger=INFO,console [bigdata@hadoop102 ~]$ nc localhost 44444 hello OK bigdata OK
(4) Result display
