11,spark
11.1 introduction to spark
Apache Spark is a unified analysis and computing engine for large-scale data processing
Based on memory computing, Spark improves the real-time performance of data processing in the big data environment, ensures high fault tolerance and high scalability, and allows users to deploy Spark on a large number of hardware to form a cluster.
11.2 difference between spark and Hadoop
Although spark has great advantages over Hadoop, spark cannot completely replace Hadoop. Spark is mainly used to replace the MapReduce calculation model in Hadoop. HDFS can still be used for storage, but the intermediate results can be stored in memory; The built-in scheduling system of spark or the more mature scheduling system YARN can be used for scheduling
In fact, Spark has been well integrated into the Hadoop ecosystem and become an important member. It can realize resource scheduling and management with the help of YARN and distributed storage with the help of HDFS.
In addition, Hadoop can use cheap and heterogeneous machines for distributed storage and computing. However, Spark has slightly higher requirements for hardware and certain requirements for memory and CPU.
11.3 features of spark
-
fast
Compared with Hadoop MapReduce, Spark's memory based operation is more than 100 times faster, and the hard disk based operation is also more than 10 times faster. Spark implements an efficient DAG execution engine that can efficiently process data streams based on memory.
-
Easy to use
Spark supports API s of Java, python, R and Scala, and supports more than 80 advanced algorithms, enabling users to quickly build different applications. Moreover, spark supports interactive Python and scala shells. It is very convenient to use spark clusters in these shells to verify the solution to the problem.
-
currency
Spark provides a unified solution. Spark can be used for batch processing, interactive query (Spark SQL), real-time streaming (Spark Streaming), machine learning (Spark MLlib) and graph calculation (GraphX). These different types of processing can be used seamlessly in the same application. Spark's unified solution is very attractive. After all, any company wants to use a unified platform to deal with the problems encountered and reduce the human cost of development and maintenance and the material cost of deploying the platform.
-
compatibility
Spark can be easily integrated with other open source products. For example, spark can use Hadoop's YARN and Apache Mesos as its resource management and scheduler, and can process all Hadoop supported data, including HDFS, HBase and Cassandra. This is particularly important for users who have deployed Hadoop clusters, because they can use the powerful processing power of spark without any data migration. Spark can also be independent of third-party resource management and scheduler. It implements Standalone as its built-in resource management and scheduling framework, which further reduces the use threshold of spark and makes it very easy for everyone to deploy and use spark.
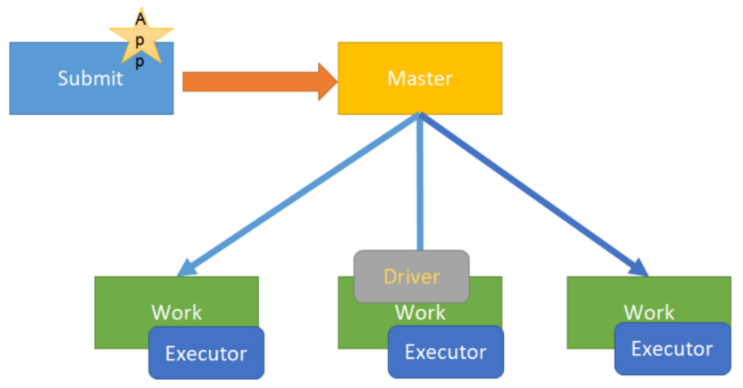
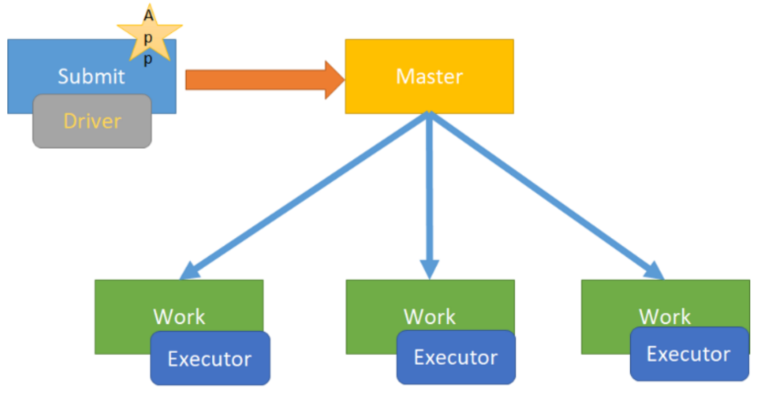
11.4. spark operation mode
1.local mode (stand-alone) – used for development and testing
It is divided into local single thread and local cluster multi thread
2.standalone independent cluster mode - used for development and testing
Typical Mater/slave mode
3. Standalone ha high availability mode - used in production environment
Based on the standalone mode, zk is used to build high availability to avoid single point of failure of the Master
4.on yarn cluster mode - used in production environment
-
Running on the yarn cluster, yarn is responsible for resource management, and Spark is responsible for task scheduling and computing,
Benefits: computing resources are scalable on demand, cluster utilization is high, underlying storage is shared, and data migration across clusters is avoided.
FIFO
Fair
Capacity
5.on mesos cluster mode - less used in China
It runs on the mesos resource manager framework. Mesos is responsible for resource management, and Spark is responsible for task scheduling and calculation
6.on cloud cluster mode - small and medium-sized companies will use cloud services more in the future
For example, AWS EC2 can easily access Amazon S3 using this mode
11.5,spark-shell
● introduction
Previously, we used spark Shell to submit tasks. Spark Shell is an interactive Shell program provided by spark, which is convenient for users to carry out interactive programming. Users can write Spark Program in scala under this command line, which is suitable for learning and testing!
● examples
Spark shell can carry parameters
Spark shell -- Master local [N] the number N indicates that N threads are simulated locally to run the current task
Spark shell -- Master local [*] * means to use all available resources on the current machine
The default parameter is - master local [*]
spark-shell --master spark://node01:7077 , node02:7077 indicates running on the cluster
11.6,spark-submit
- Commit to the standalone cluster
/export/servers/spark/bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://node01:7077 \ --executor-memory 1g \ --total-executor-cores 2 \ /export/servers/spark/examples/jars/spark-examples_2.11-2.2.0.jar \ 10
- Submit to the standalone ha cluster
/export/servers/spark/bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://node01:7077,node02:7077 \ --executor-memory 1g \ --total-executor-cores 2 \ /export/servers/spark/examples/jars/spark-examples_2.11-2.2.0.jar \ 10
- **Submit to the yarn cluster) * * most of the production environments run Spark applications in the cluster deployment mode
/export/servers/spark/bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode cluster \ --driver-memory 1g \ --executor-memory 1g \ --executor-cores 2 \ --queue default \ /export/servers/spark/examples/jars/spark-examples_2.11-2.2.0.jar \ 10
- It is used when submitting to the yarn cluster (client) learning test, and is not used for development
/export/servers/spark/bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode client \ --driver-memory 1g \ --executor-memory 1g \ --executor-cores 2 \ --queue default \ /export/servers/spark/examples/jars/spark-examples_2.11-2.2.0.jar \ 10
11.7 be able to write Wordcount
package cn.itcast.sparkhello
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//1. Create SparkContext
val config = new SparkConf().setAppName("Wordcount").setMaster("local[*]")
val sc = new SparkContext(config)
sc.setLogLevel("WARN")
//2. Read file
//A Resilient Distributed Dataset (RDD)
//It can be simply understood as a distributed collection, but spark encapsulates it a lot,
//Let programmers use it as simple as operating local collections, so that everyone is happy
val fileRDD: RDD[String] = sc.textFile("D:\\Lecture\\190429\\data\\data\\words.txt")
//3. Data processing
//3.1 cut and flatten each line to form a new set of words
//flatMap is to operate and flatten each element in the collection
val wordRDD: RDD[String] = fileRDD.flatMap(_.split(" "))
//3.2 mark each word as 1
val wordAndOneRDD: RDD[(String, Int)] = wordRDD.map((_,1))
//3.3 aggregate according to the key and count the number of each word
//wordAndOneRDD.reduceByKey((a,b)=>a+b)
//First: Previously accumulated results
//Second: Current incoming data
val wordAndCount: RDD[(String, Int)] = wordAndOneRDD.reduceByKey(_+_)
//4. Collect results
val result: Array[(String, Int)] = wordAndCount.collect()
result.foreach(println)
}
}
- What needs to be changed for cluster operation?
11.8 what is rdd
RDD(Resilient Distributed Dataset) is called elastic distributed dataset. It is the most basic data abstraction in Spark. It represents an immutable, divisible and parallel computing set of elements.
Word disassembly
-Dataset: it is a collection that can hold many elements
-Distributed: its elements are distributed storage and can be used for distributed computing
-Resilient: it is elastic. The data in RDD can be saved in memory or disk
11.9 five attributes of rdd
1.A list of partitions :
A partition / a partition list, that is, the basic unit of the dataset.
For RDD, each fragment will be processed by a computing task, and the number of fragments determines the degree of parallelism.
2.A function for computing each split :
A function will be applied to each partition.
3.A list of dependencies on other RDDs:
One RDD depends on multiple other RDDS.
Each transformation of RDD will generate a new RDD, so there will be a pipeline like dependency between RDDS. When some partition data is lost, spark can recalculate the lost partition data through this dependency instead of recalculating all partitions of RDD. (Spark's fault tolerance mechanism)
4.Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned):
Optional. For KV type RDD, there will be a Partitioner, that is, the partition function of RDD
Currently, Spark implements two types of slicing functions, one is hash based HashPartitioner, and the other is range based RangePartitioner. Only for RDDS with key value can there be a Partitioner, and the value of the Partitioner of RDDS with non key value is None. The Partitioner function determines not only the number of partitions of the RDD itself, but also the number of partitions when the parent RDD Shuffle is output.
5.Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file):
Optional, a list that stores the preferred location for accessing each Partition.
For an HDFS file, this list saves the location of the block where each Partition is located. According to the concept of "mobile data is not as good as mobile computing", Spark will try to select those worker nodes with data for task computing when scheduling tasks.
11.10. Method of creating rdd
1. It is created by data sets of external storage systems, including local file systems and all data sets supported by Hadoop, such as HDFS, Cassandra, HBase, etc
val rdd1 = sc.textFile("hdfs://node01:8020/wordcount/input/words.txt")
2. Generate a new RDD through operator transformation from the existing RDD
val rdd2=rdd1.flatMap(_.split(" "))
3. Created by an existing Scala collection
val rdd3 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
perhaps
val rdd4 = sc.makeRDD(List(1,2,3,4,5,6,7,8))
The parallelize method is called at the bottom of the makeRDD method
11.11 methods / operators of RDD
The operators of RDD are divided into two categories:
1.Transformation: returns a new RDD
2.Action: the return value is not RDD (no return value or other)
1. transformation operator
| transformation | meaning |
|---|---|
| map(func) | Returns a new RDD, which consists of each input element converted by func function |
| filter(func) | Returns a new RDD, which is composed of input elements whose return value is true after being calculated by func function |
| flatMap(func) | Similar to map, but each input element can be mapped to 0 or more output elements (so func should return a sequence, not a single element) |
| mapPartitions(func) | It is similar to map, but runs independently on each fragment of RDD. Therefore, when running on an RDD of type T, the function type of func must be iterator [t] = > iterator [u] |
| mapPartitionsWithIndex(func) | Similar to mapPartitions, but func takes an integer parameter to represent the index value of the partition. Therefore, when running on an RDD of type T, the function type of func must be (int, interleaver [t]) = > iterator [u] |
| sample(withReplacement, fraction, seed) | Sample the data according to the scale specified by fraction. You can choose whether to use random number for replacement. Seed is used to specify the seed of random number generator |
| union(otherDataset) | Returns a new RDD after combining the source RDD and the parameter RDD |
| intersection(otherDataset) | Returns a new RDD after intersecting the source RDD and the parameter RDD |
| distinct([numTasks])) | After de duplication of the source RDD, a new RDD is returned |
| groupByKey([numTasks]) | Call on a (K,V) RDD and return an (K, Iterator[V]) RDD |
| reduceByKey(func, [numTasks]) | Call on a (K,V) RDD and return a (K,V) RDD. Use the specified reduce function to aggregate the values of the same key. Similar to groupByKey, the number of reduce tasks can be set through the second optional parameter |
| aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) | |
| sortByKey([ascending], [numTasks]) | When called on a (K,V) RDD, K must implement the Ordered interface and return a (K,V) RDD sorted by key |
| sortBy(func,[ascending], [numTasks]) | Similar to sortByKey, but more flexible |
| join(otherDataset, [numTasks]) | Call on RDDS of types (K,V) and (K,W) to return the RDD of (K,(V,W)) of all element pairs corresponding to the same key |
| cogroup(otherDataset, [numTasks]) | Called on RDDS of types (K,V) and (K,W), returns an RDD of type (k, (iteratable, iteratable)) |
| cartesian(otherDataset) | Cartesian product |
| pipe(command, [envVars]) | Pipe rdd |
| coalesce(numPartitions) | Reduce the number of RDD partitions to the specified value. You can do this after filtering a large amount of data |
| repartition(numPartitions) | Repartition RDD |
2. action operator
| action | meaning |
|---|---|
| reduce(func) | Gather all elements in RDD through func function. This function must be interchangeable and parallelable |
| collect() | In the driver, all elements of the dataset are returned as an array |
| count() | Returns the number of RDD elements |
| first() | Returns the first element of the RDD (similar to take(1)) |
| take(n) | Returns an array of the first n elements of a dataset |
| takeSample(withReplacement,num, [seed]) | Returns an array consisting of num elements randomly sampled from the data set. You can choose whether to replace the insufficient part with a random number. Seed is used to specify the seed of the random number generator |
| takeOrdered(n, [ordering]) | Returns the first n elements in natural order or custom order |
| saveAsTextFile(path) | Save the elements of the dataset in the form of textfile to the HDFS file system or other supported file systems. For each element, Spark will call the toString method to replace it with the text in the file |
| saveAsSequenceFile(path) | Save the elements in the dataset to the specified directory in the format of Hadoop sequencefile to enable HDFS or other Hadoop supported file systems. |
| saveAsObjectFile(path) | Save the elements of the dataset to the specified directory in the form of Java serialization |
| countByKey() | For RDD S of type (K,V), a (K,Int) map is returned, indicating the number of elements corresponding to each key. |
| foreach(func) | On each element of the dataset, run the function func to update. |
| foreachPartition(func) | On each partition of the dataset, run the function func |
11.12. checkpoint in spark
Persistence / caching can put data in memory. Although it is fast, it is also the most unreliable; You can also put data on disk, which is not completely reliable! For example, the disk will be damaged.
Checkpoint is created for more reliable data persistence. During checkpoint, the data is generally placed on HDFS, which naturally makes use of the inherent high error tolerance and high reliability of HDFS to achieve the maximum security of data and realize the fault tolerance and high availability of RDD.
Specific usage:
sc.setCheckpointDir("hdfs://node01:8020/ckpdir")
//Setting the checkpoint directory will immediately create an empty directory on HDFS
val rdd1 = sc.textFile("hdfs://node01:8020/wordcount/input/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
rdd1.checkpoint //Save checkpoint for rdd1
rdd1.collect //The Action action will actually execute the checkpoint
//If you want to use rdd1 later, you can read it from the checkpoint
11.13 difference between persistence and Checkpoint
1. Location
Persist and Cache can only be saved on local disk and memory (or off heap memory - in the experiment)
Checkpoint can save data to reliable storage such as HDFS
2. Life cycle
The RDD of Cache and Persist will be cleared after the program ends, or the unpersist method will be called manually
The RDD of Checkpoint still exists after the program ends and will not be deleted
3. Lineage (lineage, dependency chain – actually dependency)
Persist ent and Cache will not lose the dependency chain / dependency relationship between RDD S, because this Cache is unreliable. If there are some errors (such as Executor downtime), it needs to be recalculated by backtracking the dependency chain
Checkpoint will cut off the dependency chain, because checkpoint will save the results in storage such as HDFS, which is more secure and reliable. Generally, there is no need to backtrack the dependency chain
11.14 rdd dependency
Narrow dependency: a partition of the parent RDD is only dependent on a partition of the child RDD
Wide dependency: one partition of the parent RDD will be dependent by multiple partitions of the child RDD (involving shuffle)
-
Role of design width dependence
-
1. For narrow dependence
- Spark can compute in parallel
- If one partition data is lost, you only need to recalculate from the corresponding partition of the parent RDD without recalculating the whole task to improve fault tolerance.
2. For wide dependence
- This is the basis for dividing the Stage
-
-
Special: join (it can be both wide dependence and narrow dependence)
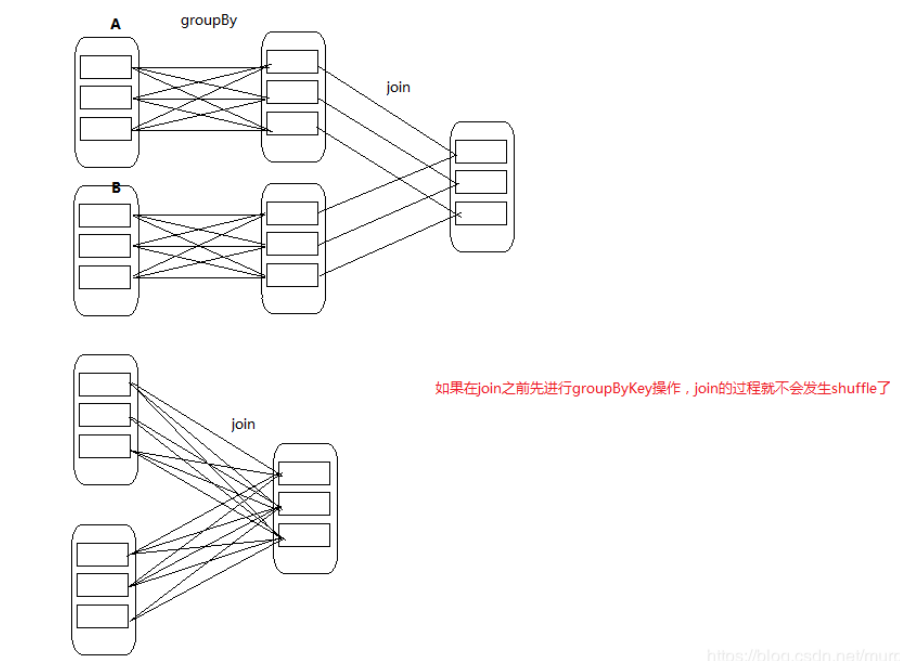
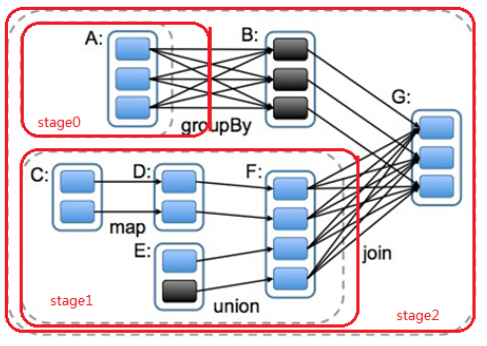
11.15,DAG
DAG(Directed Acyclic Graph) refers to the process of data conversion execution, with direction and no closed loop (in fact, it is the process of RDD execution)
The original RDD forms DAG directed acyclic graph through a series of conversion operations. When a task is executed, the real calculation (a process in which data is operated) can be performed according to the description of DAG. A Spark application can have one or more DAGs, depending on how many actions are triggered.
11.16 stage division
● why are stages divided-- Parallel computing
If a complex business logic has a shuffle, it means that the next Stage can be executed only after the previous Stage produces results, that is, the calculation of the next Stage depends on the data of the previous Stage. Then we can divide a DAG into multiple stages / stages according to shuffle (that is, according to wide dependency). In the same Stage, there will be multiple operator operations to form a pipeline pipeline, and multiple parallel partitions in the pipeline can be executed in parallel.
● how to divide DAG stage s
Spark will use backtracking algorithm to divide DAG into stages according to shuffle / wide dependency. From the back to the front, it will disconnect when it meets wide dependency, and add the current RDD to the current stage / stage when it meets narrow dependency.
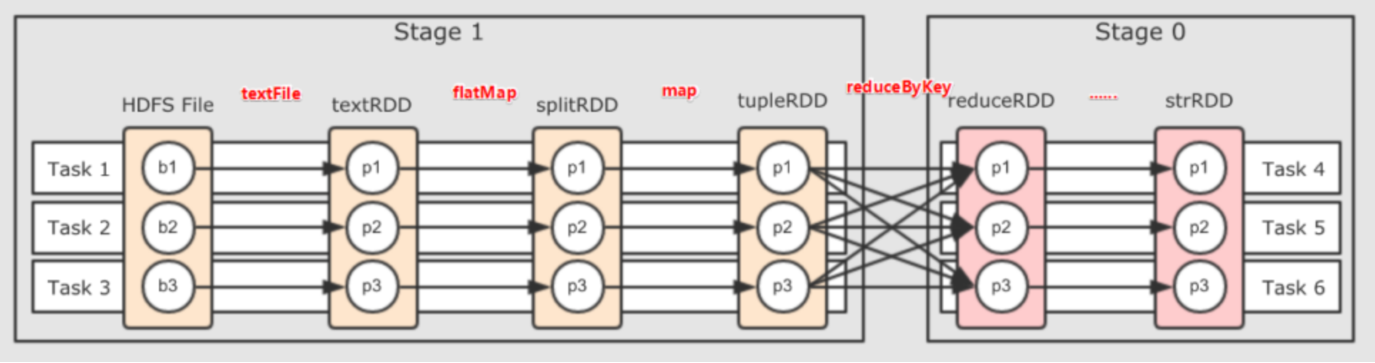
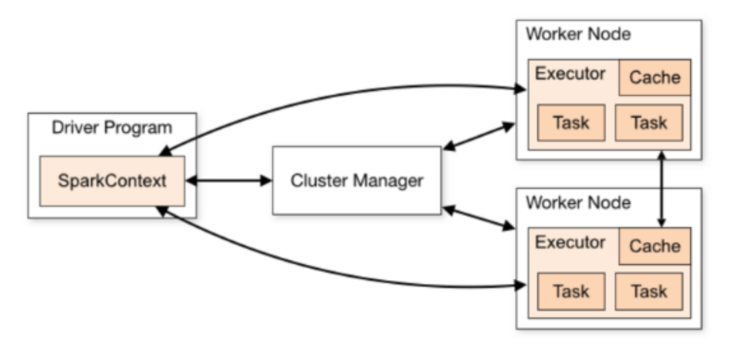
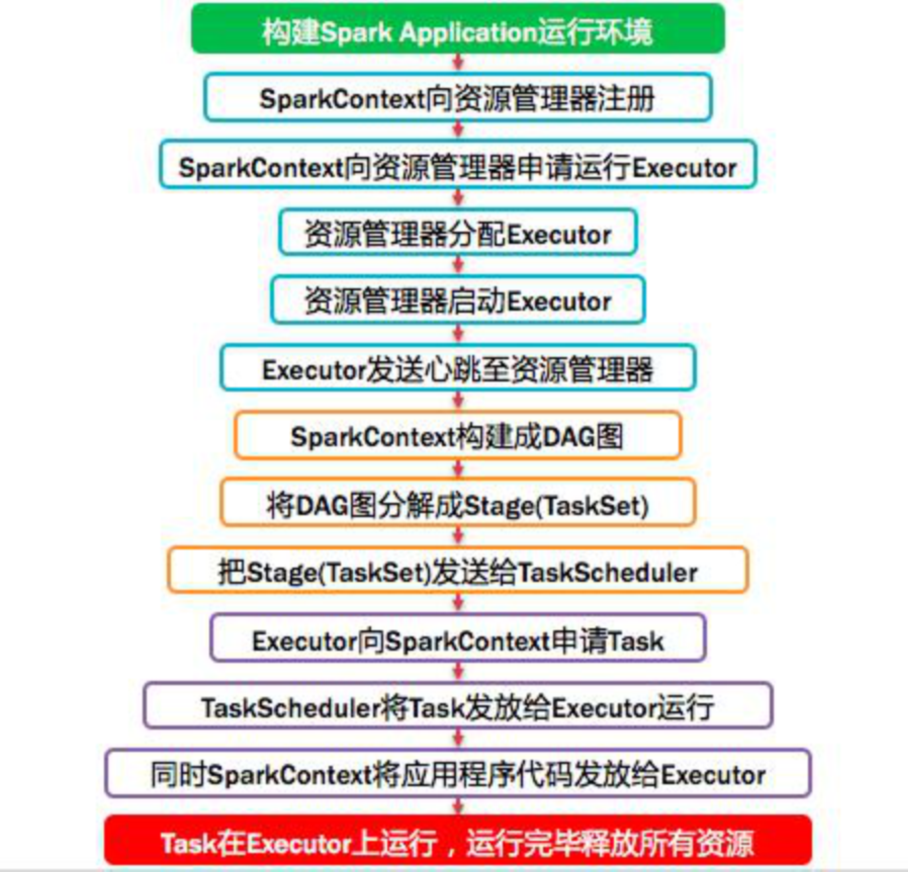
11.17 operation process of spark Program
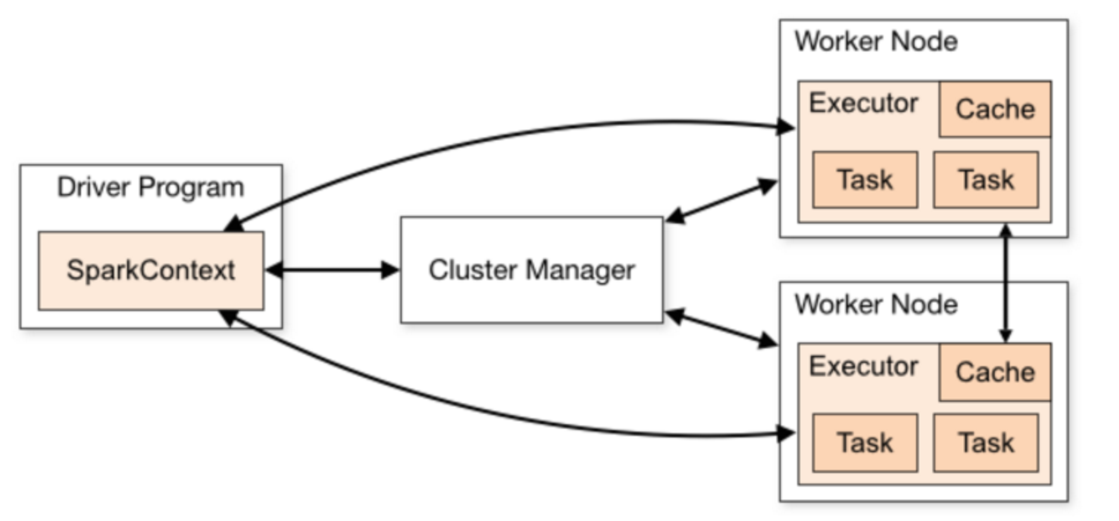
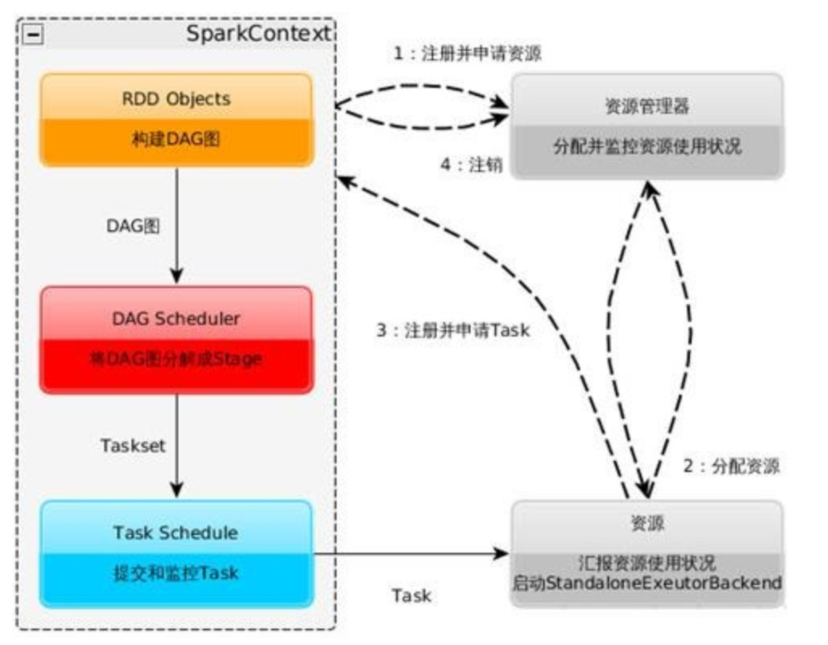
- Detailed process
11.18,DataFrame & DataSet
-
dataframe
The predecessor of DataFrame is SchemaRDD, which has been renamed DataFrame since Spark 1.3.0. It no longer directly inherits from RDD, but implements most of the functions of RDD itself.
DataFrame is a distributed data set based on RDD, similar to the two-dimensional table of traditional database, with Schema meta information (which can be understood as the column name and type of database)
-
dataSet
DataSet is a new interface added in spark 1.6.
Compared with RDD, it saves more description information, which is conceptually equivalent to a two-dimensional table in a relational database.
Compared with DataFrame, it saves type information, is strongly typed, and provides compile time type checking.
DataSet contains the function of DataFrame, which is unified in Spark2.0. DataFrame is represented as DataSet[Row], that is, a subset of DataSet. DataFrame is actually Dateset[Row].
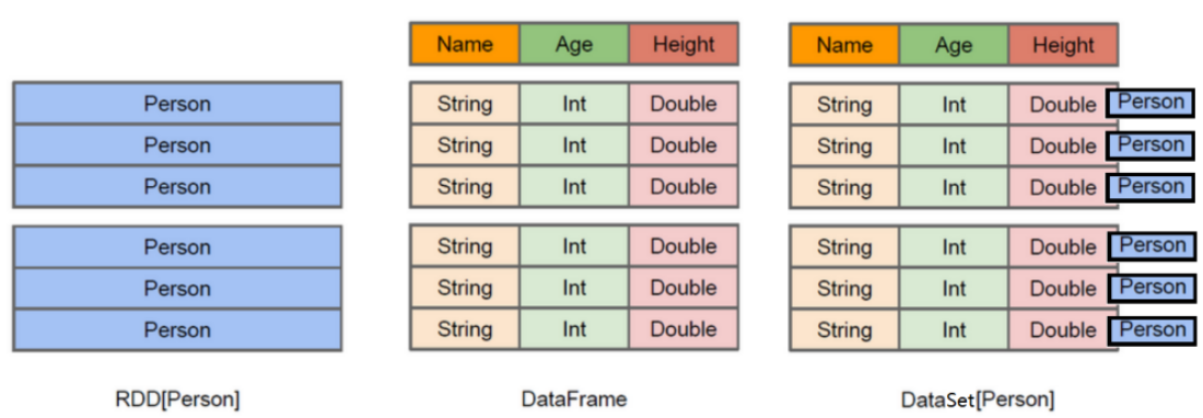
summary
DataFrame = RDD - Generic + Schema + SQL + optimization
DataFrame = DataSet[Row]
DataSet = DataFrame + generic
DataSet = RDD + Schema + SQL + optimization
11.19. Getting to know dataframe
1. Read text file
establish RDD
val lineRDD= sc.textFile("hdfs://node01:8020/person.txt").map(_.split(" ")) //RDD[Array[String]]
3.definition case class(Equivalent to table schema)
case class Person(id:Int, name:String, age:Int)
4.take RDD and case class relation
val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt)) //RDD[Person]
5.take RDD convert to DataFrame
val personDF = personRDD.toDF //DataFrame
6.View data and schema
personDF.show
+---+--------+---+
| id| name|age|
+---+--------+---+
| 1|zhangsan| 20|
| 2| lisi| 29|
| 3| wangwu| 25|
| 4| zhaoliu| 30|
| 5| tianqi| 35|
| 6| kobe| 40|
+---+--------+---+
personDF.printSchema
7.registry
personDF.createOrReplaceTempView("t_person")
8.implement SQL
spark.sql("select id,name from t_person where id > 3").show
9.You can also SparkSession structure DataFrame
val dataFrame=spark.read.text("hdfs://node01:8020/person.txt")
dataFrame.show //Note: the directly read text file does not have complete schema information
dataFrame.printSchema
2. Read json file
1.stay spark shell Execute the following command to read the data
val jsonDF= spark.read.json("file:///export/servers/spark/examples/src/main/resources/people.json")
2.Then you can use DataFrame Function operation of
jsonDF.show
3. Read parquet file
1.stay spark shell Execute the following command to read the data
val parquetDF=spark.read.parquet("file:///export/servers/spark/examples/src/main/resources/users.parquet")
2.Then you can use DataFrame Function operation of
parquetDF.show
11.20. Several ways to create dataframe
1. Add Schema with specified column name
package cn.itcast.sql
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
object CreateDFDS {
def main(args: Array[String]): Unit = {
//1. Create SparkSession
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2. Read file
val fileRDD: RDD[String] = sc.textFile("D:\\data\\person.txt")
val linesRDD: RDD[Array[String]] = fileRDD.map(_.split(" "))
val rowRDD: RDD[(Int, String, Int)] = linesRDD.map(line =>(line(0).toInt,line(1),line(2).toInt))
//3. Convert RDD to DF
//Note: there was no toDF method in RDD. To add a method to it in the new version, you can use implicit conversion
import spark.implicits._
val personDF: DataFrame = rowRDD.toDF("id","name","age")
personDF.show(10)
personDF.printSchema()
sc.stop()
spark.stop()
}
}
2. Reflection inference Schema – master
package cn.itcast.sql
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
object CreateDFDS3 {
def main(args: Array[String]): Unit = {
//1. Create SparkSession
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL")
.getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2. Read file
val fileRDD: RDD[String] = sc.textFile("D:\\data\\person.txt")
val linesRDD: RDD[Array[String]] = fileRDD.map(_.split(" "))
val rowRDD: RDD[Person] = linesRDD.map(line =>Person(line(0).toInt,line(1),line(2).toInt))
//3. Convert RDD to DF
//Note: there was no toDF method in RDD. To add a method to it in the new version, you can use implicit conversion
import spark.implicits._
//Note: the generic type of rowRDD above is Person, which contains Schema information
//Therefore, SparkSQL can be automatically obtained and added to DF through reflection
val personDF: DataFrame = rowRDD.toDF
personDF.show(10)
personDF.printSchema()
sc.stop()
spark.stop()
}
case class Person(id:Int,name:String,age:Int)
}
3. StructType specifies Schema - understand
package cn.itcast.sql
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types._
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
object CreateDFDS2 {
def main(args: Array[String]): Unit = {
//1. Create SparkSession
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2. Read file
val fileRDD: RDD[String] = sc.textFile("D:\\data\\person.txt")
val linesRDD: RDD[Array[String]] = fileRDD.map(_.split(" "))
val rowRDD: RDD[Row] = linesRDD.map(line =>Row(line(0).toInt,line(1),line(2).toInt))
//3. Convert RDD to DF
//Note: there was no toDF method in RDD. To add a method to it in the new version, you can use implicit conversion
//import spark.implicits._
val schema: StructType = StructType(Seq(
StructField("id", IntegerType, true),//Null allowed
StructField("name", StringType, true),
StructField("age", IntegerType, true))
)
val personDF: DataFrame = spark.createDataFrame(rowRDD,schema)
personDF.show(10)
personDF.printSchema()
sc.stop()
spark.stop()
}
}
11.21 principle of sparkStreaming
Spark Streaming is a real-time computing framework based on Spark Core. It can consume data from many data sources and process data in real time. It has the characteristics of high throughput and strong fault tolerance.
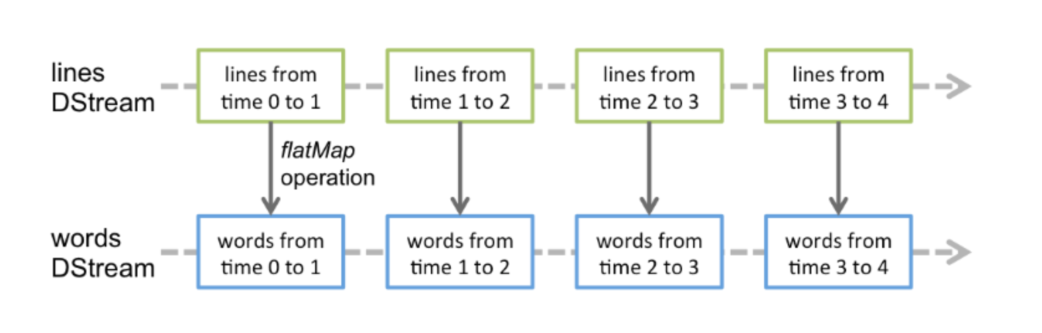
11.21.1 data abstraction
The basic abstraction of Spark Streaming is dstream (discrete stream, continuous data stream), which represents the continuous data stream and the result data stream after various Spark operators.
- 1.DStream is essentially a series of time continuous RDD S
- The operation of DStream data is also carried out in RDD units.
11.22. Use updateStateByKey(func) for accumulation
package cn.itcast.streaming
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object WordCount2 {
def main(args: Array[String]): Unit = {
//1. Create StreamingContext
//spark.master should be set as local[n], n > 1
val conf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc,Seconds(5))//5 means that the data is segmented in 5 seconds to form an RDD
//requirement failed: ....Please set it by StreamingContext.checkpoint().
//Note: we use updateStateByKey below to accumulate current data and historical data
//So where does historical data exist? We need to set up a checkpoint directory for him
ssc.checkpoint("./wc")//HDFS under development
//2. Monitor the data received by the Socket
//ReceiverInputDStream is the RDD composed of all received data, which is encapsulated into DStream. The next operation on DStream is to operate on RDD
val dataDStream: ReceiverInputDStream[String] = ssc.socketTextStream("node01",9999)
//3. Operation data
val wordDStream: DStream[String] = dataDStream.flatMap(_.split(" "))
val wordAndOneDStream: DStream[(String, Int)] = wordDStream.map((_,1))
//val wordAndCount: DStream[(String, Int)] = wordAndOneDStream.reduceByKey(_+_)
//====================Use updateStateByKey to accumulate current data and historical data====================
val wordAndCount: DStream[(String, Int)] =wordAndOneDStream.updateStateByKey(updateFunc)
wordAndCount.print()
ssc.start()//open
ssc.awaitTermination()//Wait for grace to stop
}
//currentValues: the value value of the current batch, such as: 1,1,1 (take hadoop in the test data as an example)
//historyValue: the historical value accumulated before. The first time no value is 0, and the second time is 3
//The goal is to return the current data + historical data as a new result (the next historical data)
def updateFunc(currentValues:Seq[Int], historyValue:Option[Int] ):Option[Int] ={
val result: Int = currentValues.sum + historyValue.getOrElse(0)
Some(result)
}
}
11.23,reduceByKeyAndWindow
package cn.itcast.streaming
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object WordCount3 {
def main(args: Array[String]): Unit = {
//1. Create StreamingContext
//spark.master should be set as local[n], n > 1
val conf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc,Seconds(5))//5 means that the data is segmented in 5 seconds to form an RDD
//2. Monitor the data received by the Socket
//ReceiverInputDStream is the RDD composed of all received data, which is encapsulated into DStream. The next operation on DStream is to operate on RDD
val dataDStream: ReceiverInputDStream[String] = ssc.socketTextStream("node01",9999)
//3. Operation data
val wordDStream: DStream[String] = dataDStream.flatMap(_.split(" "))
val wordAndOneDStream: DStream[(String, Int)] = wordDStream.map((_,1))
//4. Use the window function to count WordCount
//Reducefunc: (V, V) = > V, set function
//windowDuration: Duration, window length / width
//slideDuration: Duration, window sliding interval
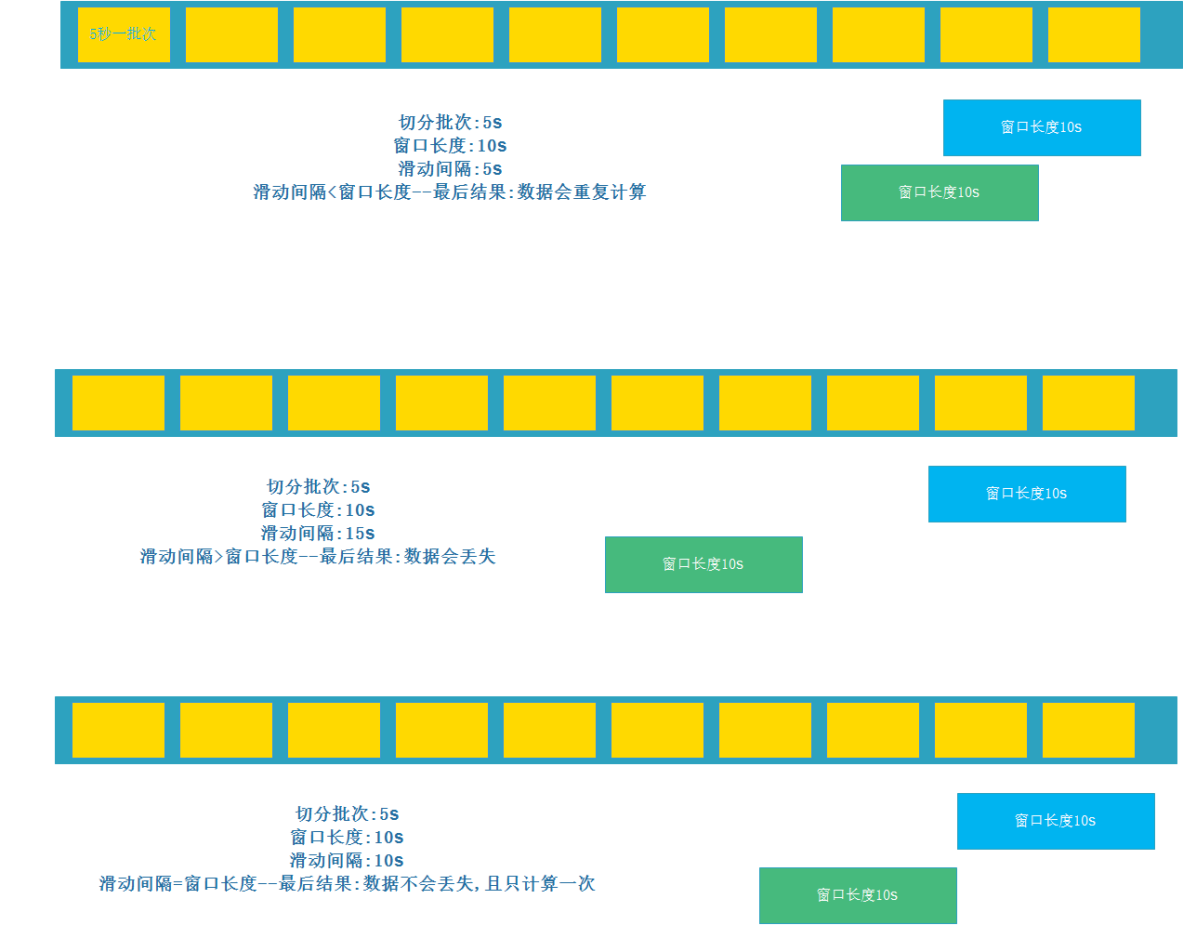
//Note: windowDuration and slideDuration must be multiples of batchDuration
//Windowsduration = slideduration: data will not be lost or double calculated = = it will be used in development
//Windowsduration > slideduration: data will be calculated repeatedly = = it will be used in development
//Windowsduration < slideduration: data will be lost
//The following code indicates:
//windowDuration=10
//slideDuration=5
//Then the execution result is to calculate the data of the last 10s every 5s
//For example, in the development, you are asked to count the data of the last hour and calculate it every 1 minute. How should the parameters be set?
//windowDuration=Minutes(60)
//slideDuration=Minutes(1)
val wordAndCount: DStream[(String, Int)] = wordAndOneDStream.reduceByKeyAndWindow((a:Int,b:Int)=>a+b,Seconds(10),Seconds(5))
wordAndCount.print()
ssc.start()//open
ssc.awaitTermination()//Wait for grace to stop
}
}
11.24. Spark streaming integration kafka
11.24.1 Receiver receiving method (not commonly used)
- Kafkautils.createdstream (not used in development, just understand, but may be asked in the interview)
- As a resident Task, the Receiver runs in the Executor waiting for data, but one Receiver is inefficient. It needs to start multiple receivers, manually merge data (unions), and then process them, which is very troublesome
- If the Receiver hangs up, data may be lost, so you need to turn on wal (pre write log) to ensure data security, and the efficiency will be reduced!
- The Receiver connects to the Kafka queue through zookeeper and calls the Kafka high-level API. The offset is stored in zookeeper and maintained by the Receiver,
- In order to ensure no data loss during spark consumption, an offset will also be saved in the Checkpoint, which may cause data inconsistency
- Therefore, no matter from what point of view, the Receiver mode is not suitable for development and has been eliminated
package cn.itcast.streaming
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.immutable
object SparkKafka {
def main(args: Array[String]): Unit = {
//1. Create StreamingContext
val config: SparkConf =
new SparkConf().setAppName("SparkStream").setMaster("local[*]")
.set("spark.streaming.receiver.writeAheadLog.enable", "true")
//Enable the WAL pre write log to ensure the reliability of the data source
val sc = new SparkContext(config)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc,Seconds(5))
ssc.checkpoint("./kafka")
//==============================================
//2. Prepare configuration parameters
val zkQuorum = "node01:2181,node02:2181,node03:2181"
val groupId = "spark"
val topics = Map("spark_kafka" -> 2)//2 means that the partition corresponding to each topic uses two threads to consume,
//The rdd partition of ssc is different from the topic partition of kafka. Increasing the number of consuming threads does not increase the number of parallel processing data of spark
//3. Get the topic data in kafka through the receiver receiver. You can run more receivers in parallel to read the data in kafak topic. Here are three
val receiverDStream: immutable.IndexedSeq[ReceiverInputDStream[(String, String)]] = (1 to 3).map(x => {
val stream: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(ssc, zkQuorum, groupId, topics)
stream
})
//4. Use the union method to merge the dstreams generated by all receiver s
val allDStream: DStream[(String, String)] = ssc.union(receiverDStream)
//5. Get the data of topic (String, String). The first String represents the name of topic, and the second String represents the data of topic
val data: DStream[String] = allDStream.map(_._2)
//==============================================
//6.WordCount
val words: DStream[String] = data.flatMap(_.split(" "))
val wordAndOne: DStream[(String, Int)] = words.map((_, 1))
val result: DStream[(String, Int)] = wordAndOne.reduceByKey(_ + _)
result.print()
ssc.start()
ssc.awaitTermination()
}
}
11.24.2 Direct connection mode (common)
- Kafkautils.createdirectstream (used in development, required to master)
- Direct mode is to directly connect kafka partitions to obtain data, and directly read data from each partition, which greatly improves the parallel ability
- Kafka low-level API (underlying API) is called in Direct mode. offset is stored and maintained by itself. Spark maintains it in checkpoint by default, eliminating inconsistency with zk
- Of course, you can also maintain the offset manually by storing it in mysql and redis
- Therefore, based on the Direct mode, it can be used in development, and with the help of the characteristics of Direct mode + manual operation, it can ensure the accuracy of data Exactly once
package cn.itcast.streaming
import kafka.serializer.StringDecoder
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object SparkKafka2 {
def main(args: Array[String]): Unit = {
//1. Create StreamingContext
val config: SparkConf =
new SparkConf().setAppName("SparkStream").setMaster("local[*]")
val sc = new SparkContext(config)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc,Seconds(5))
ssc.checkpoint("./kafka")
//==============================================
//2. Prepare configuration parameters
val kafkaParams = Map("metadata.broker.list" -> "node01:9092,node02:9092,node03:9092", "group.id" -> "spark")
val topics = Set("spark_kafka")
val allDStream: InputDStream[(String, String)] = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)
//3. Get topic data
val data: DStream[String] = allDStream.map(_._2)
//==============================================
//WordCount
val words: DStream[String] = data.flatMap(_.split(" "))
val wordAndOne: DStream[(String, Int)] = words.map((_, 1))
val result: DStream[(String, Int)] = wordAndOne.reduceByKey(_ + _)
result.print()
ssc.start()
ssc.awaitTermination()
}
}
11.25,shuffle
History of spark shuffle evolution
- Spark 0.8 and earlier Hash Based Shuffle
- Spark 0.8.1 introduces File Consolidation mechanism for Hash Based Shuffle
- Spark 0.9 introduces ExternalAppendOnlyMap
- Spark 1.1 introduces Sort Based Shuffle, but the default is Hash Based Shuffle
- Spark 1.2 changes the default Shuffle mode to Sort Based Shuffle
- Spark 1.4 introduces tungsten sort based shuffle
- Spark 1.6 tungsten sort incorporated into Sort Based Shuffle
- Spark 2.0 Hash Based Shuffle exits the stage of history
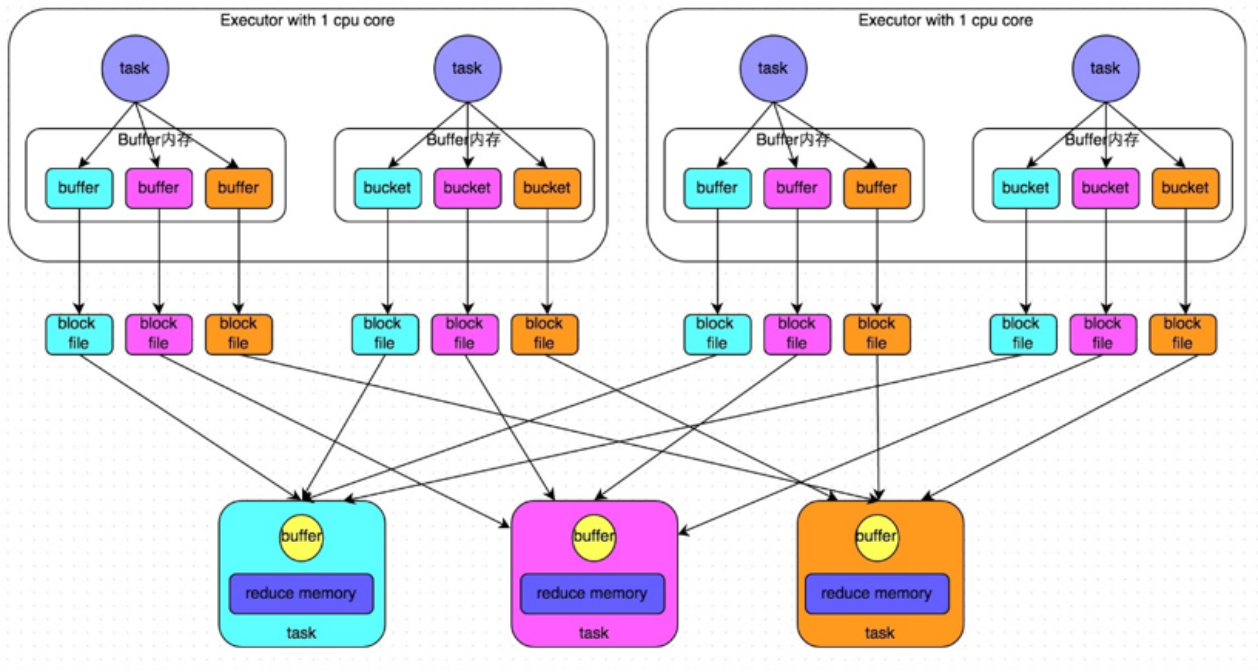
1. Non optimized HashShuffleManager
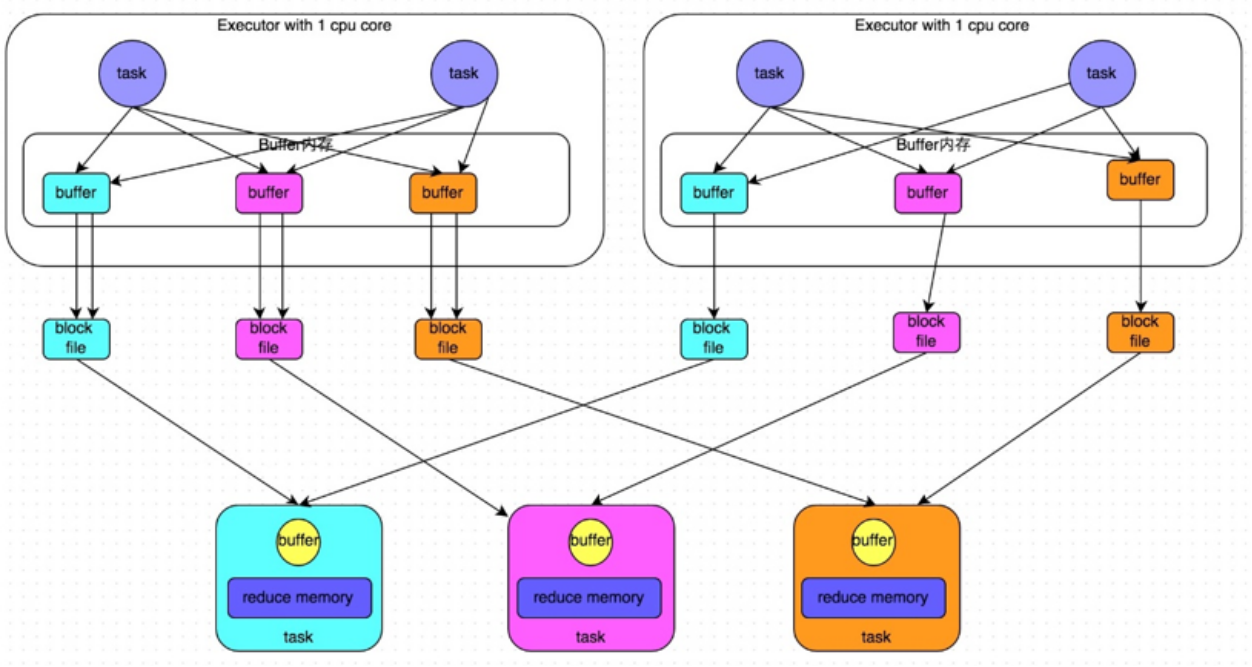
2. Optimized HashShuffleManager
After the consolidate mechanism is enabled, in the shuffle write process, the task does not create a disk file for each task in the downstream stage. At this time, the concept of shuffleFileGroup appears. Each shuffleFileGroup corresponds to a batch of disk files. The number of disk files is the same as that of tasks in the downstream stage.
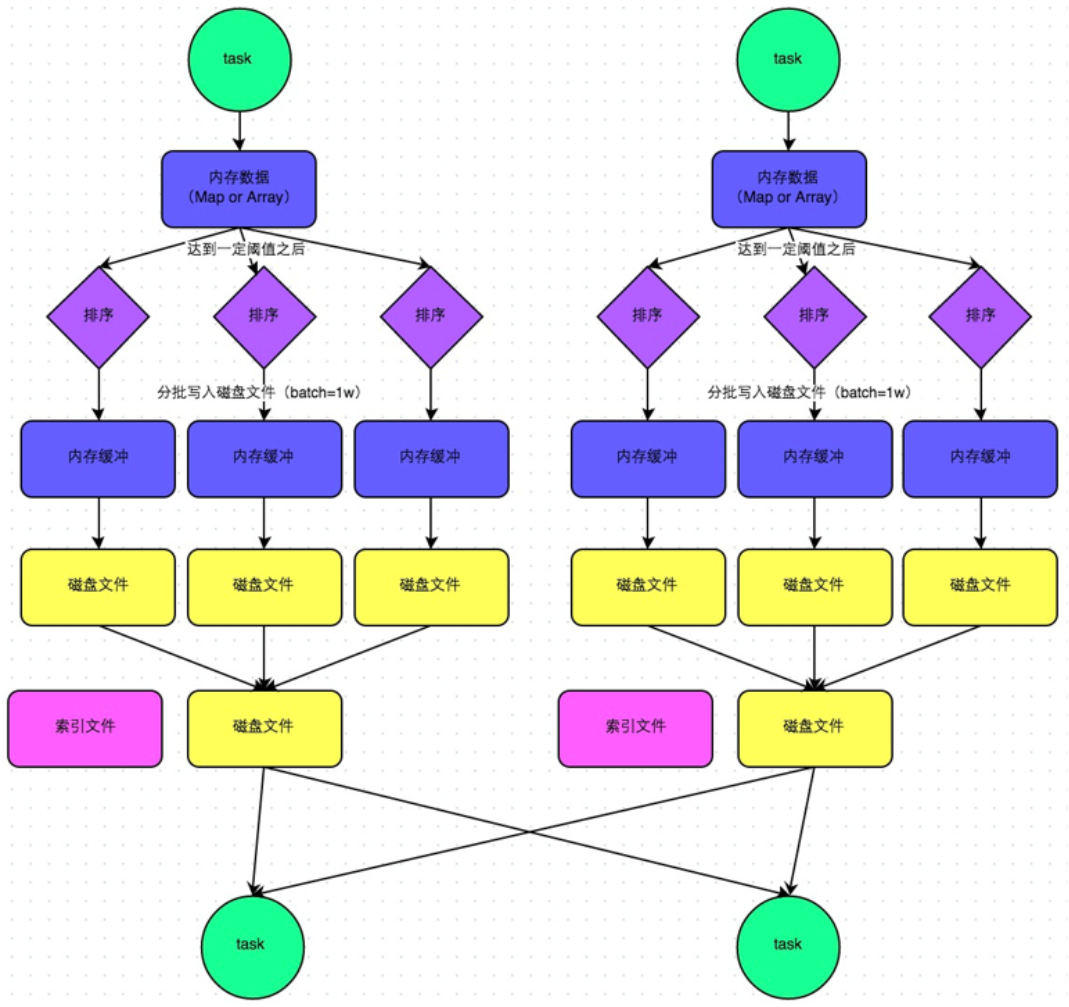
3,SortShuffle
The Sort Based Shuffle is introduced later. The task on the map side will sort the records according to Partition id and key. At the same time, all results are written to a data file and an index file is generated at the same time.
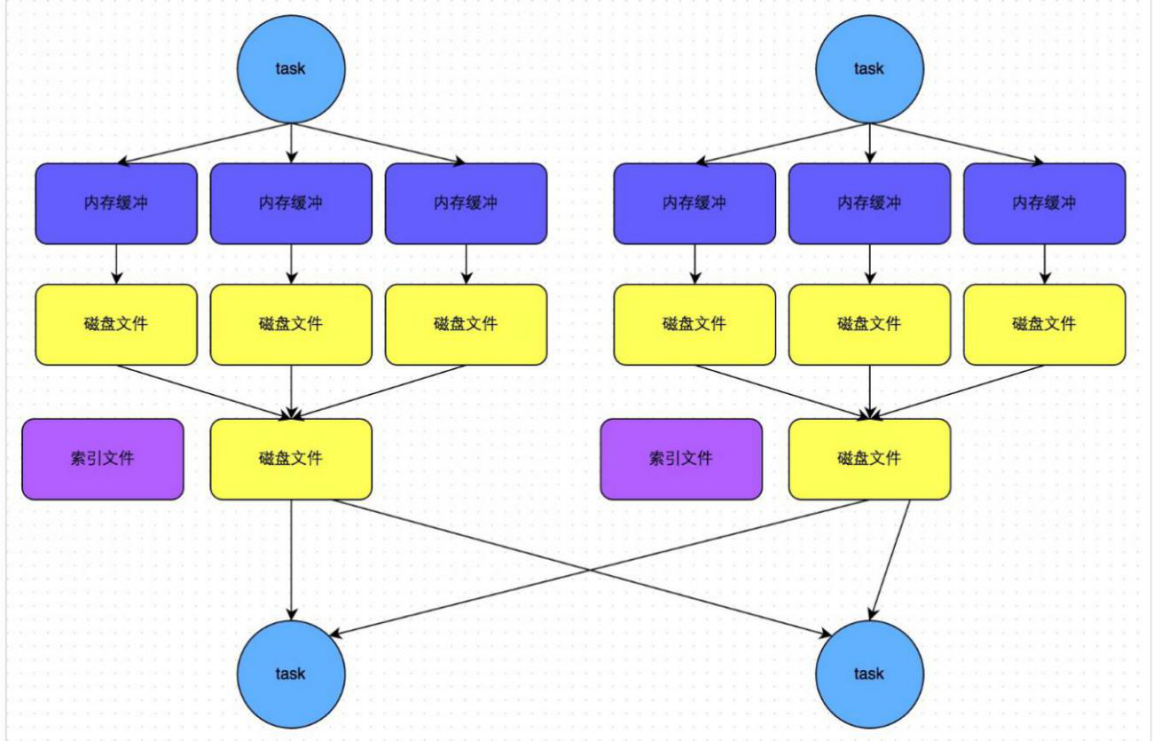
4. bypass mechanism of sortshuffle
The trigger conditions of bypass operation mechanism are as follows:
-
The number of shuffle map task s is less than the value of the spark.shuffle.sort.bypassMergeThreshold=200 parameter.
-
Is not a shuffle operator of an aggregate class.
Each task will create a temporary disk file for each downstream task, hash the data by key, and then write the key to the corresponding disk file according to the hash value of the key. Of course, when writing a disk file, you also write to the memory buffer first, and then overflow to the disk file after the buffer is full. Finally, all temporary disk files will also be merged into one disk file and a separate index file will be created.
The disk writing mechanism as like as two peas in the process of HashShuffleManager is the same as the unoptimized one, because all of them create a surprising number of disk files. Therefore, a small number of final disk files also make the performance of shuffle read better than that of the unoptimized hashshufflemanager
5,Tungsten-Sort Based Shuffle
Later, tungsten sort based shuffle is introduced, which directly uses out of heap memory and a new memory management model to save memory space and a lot of gc in order to improve performance.
11.26. spark performance tuning
1. Basic tuning
1.1. Resource parameter setting
The first step of Spark performance tuning is to allocate more resources to tasks. Within a certain range, increasing the allocation of resources is directly proportional to the improvement of performance. After realizing the optimal resource allocation, consider the performance tuning strategy discussed later.
/opt/soft/spark/bin/spark-submit \ --class com.bigdata.spark.Analysis \ --num-executors 80 \ --driver-memory 6g \ --executor-memory 6g \ --executor-cores 3 \ /opt/soft/spark/jar/spark.jar \
| name | explain |
|---|---|
| –num-executors | Configure the number of executors. The default number of executors is 2 |
| –driver-memory | Configure Driver memory (little impact) 1G by default |
| –executor-memory | Configure the memory size of each Executor. The default is 1G |
| –executor-cores | The number of CPU core s configured for each Executor is 1 core by default |
Adjustment principle: try to adjust the resources allocated to the task to the maximum of available resources.
| name | analysis |
|---|---|
| Increase the number of executors | When resources allow, increasing the number of executors can improve the parallelism of task execution. For example, if there are 4 executors and each Executor has 2 CPU core s, 8 tasks can be executed in parallel. If the number of executors is increased to 8 (if resources allow), 16 tasks can be executed in parallel. At this time, the parallel ability is doubled. |
| Increase the number of CPU core s per Executor | When resources allow, increasing the number of CPU cores per Executor can improve the parallelism of task execution. For example, if there are 4 executors and each Executor has 2 CPU cores, 8 tasks can be executed in parallel. If the number of CPU cores of each Executor is increased to 4 (if resources allow), 16 tasks can be executed in parallel. At this time, the parallel ability is doubled. |
| Increase the amount of memory per Executor | When resources allow, increasing the memory of each Executor can improve the performance in three ways: 1. More data can be cache d (i.e. caching RDD), and the data written to the disk can be reduced accordingly, or even not written to the disk, reducing the possible disk IO; 2. More memory can be provided for the shuffle operation, that is, there is more space to store the data pulled by the reduce end, and the data written to the disk can be reduced accordingly, or even not written to the disk, reducing the possible disk IO; 3. It can provide more memory for task execution. Many objects may be created during task execution. Small memory will cause frequent GC. After increasing memory, frequent GC can be avoided and the overall performance can be improved. |
1.2. Parallelism setting
Parallelism in Spark jobs refers to the number of task s in each stage.
If the parallelism setting is unreasonable and the parallelism is too low, it will lead to a great waste of resources.
For example, with 20 executors, each Executor is allocated 3 CPU cores, while the Spark job has 40 tasks, so the number of tasks allocated to each Executor is 2, which makes each Executor have one CPU core idle, resulting in a waste of resources.
Spark officials recommend that the number of tasks should be set to 2 ~ 3 times the total number of CPU cores of spark jobs. The reason why the number of recommended tasks is not equal to the total number of CPU cores is that the execution time of tasks is different. Some tasks are fast and some tasks are slow. If the number of tasks is equal to the total number of CPU cores, the CPU core will be idle after the execution of fast tasks is completed. If the number of tasks is set to 2 ~ 3 times of the total number of CPU cores, the CPU core will immediately execute the next task after one task is executed, which reduces the waste of resources and improves the efficiency of spark job operation.
val conf = new SparkConf().set("spark.default.parallelism", "500")
3. Using cache and checkpoint
Spark persistence is not a problem in most cases, but sometimes the data may be lost. If the data is lost, the lost data needs to be recalculated, cached and used after calculation. In order to avoid data loss, you can choose to checkpoint this RDD, that is, persist the data to a fault-tolerant file system (e.g. HDFS).
After an RDD is cached and checkpointed, if the cache is found to be lost, it will give priority to check whether the checkpoint data store exists. If there is, it will use the checkpoint data without recalculation. That is, checkpoint can be regarded as the guarantee mechanism of cache. If the cache fails, it will use the checkpoint data.
The advantage of using checkpoint is that it improves the reliability of Spark jobs. In case of cache problems, there is no need to recalculate the data. The disadvantage is that the data needs to be written to HDFS and other file systems during checkpoint, which consumes a lot of performance.
sc.setCheckpointDir('HDFS')
rdd.cache/persist(memory_and_disk)
rdd.checkpoint
4. Using broadcast variables
Suppose that the current task is configured with 20 executors, 500 tasks are specified, and a 20M variable is shared by all tasks. At this time, 500 copies will be generated among the 500 tasks, consuming 10G memory of the cluster. If broadcast variables are used, each Executor will save one copy, consuming 400M memory in total, reducing the memory consumption by 5 times.}
val Broadcast variable name= sc.broadcast(Will be Task Variables used,That is, the variables that need to be broadcast) Broadcast variable name.value//Get broadcast variable
5. Using kryo serialization
By default, spark uses the Java serialization mechanism. Spark officially claims that the performance of Kryo serialization mechanism is about 10 times higher than that of Java serialization mechanism. Spark does not use Kryo as the serialization class library by default because it does not support serialization of all objects. At the same time, Kryo requires users to register the types to be serialized before use, which is not convenient, but from Spark 2.0.0 At the beginning of the version, Shuffling RDDs of simple type, simple type array and string type have used Kryo serialization by default.
//Create a SparkConf object
val conf = new SparkConf().setMaster(...).setAppName(...)
//Using Kryo serialization Library
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
//Register a custom collection of classes in the Kryo serialization library
conf.set("spark.kryo.registrator", "bigdata.com.MyKryoRegistrator");
6. Localization waiting time setting
| name | analysis |
|---|---|
| PROCESS_LOCAL | Process localization, task and data are in the same Executor, and the performance is the best. |
| NODE_LOCAL | Node localization. Task and data are in the same node, but task and data are not in the same Executor. Data needs to be transmitted between processes. |
| RACK_LOCAL | Rack localization: task s and data are on two nodes in the same rack, and data needs to be transmitted between nodes through the network. |
| NO_PREF | For task s, it's the same where you get it. There's no good or bad. |
| ANY | Tasks and data can be anywhere in the cluster, and not in a rack, with the worst performance. |
In the Spark project development stage, you can use the client mode to test the program. At this time, you can see relatively complete log information locally. There is a clear level of task data localization in the log information. If most of them are PROCESS_LOCAL, there is no need to adjust. However, if many levels are NODE_LOCAL and ANY, you need to adjust the localization Adjust the waiting time. By extending the localization waiting time, see if the localization level of the task has been improved and whether the running time of the Spark job has been shortened.
Note that too much is better than too little. Do not extend the localization waiting time too long, which will increase the running time of Spark jobs because of a large number of waiting times.
val conf = new SparkConf().set("spark.locality.wait", "6")
2. Operator tuning
2.1 reuse of rdd
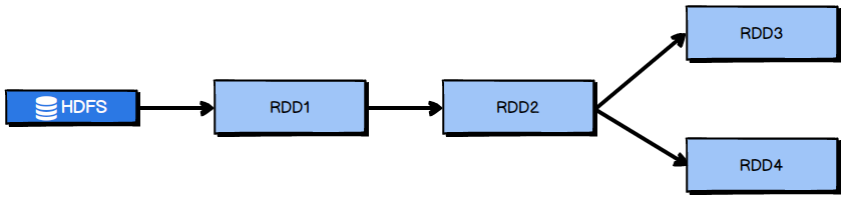
When operating RDD, avoid repeated calculation of RDD under the same operator and calculation logic, as shown in Figure 2-1:
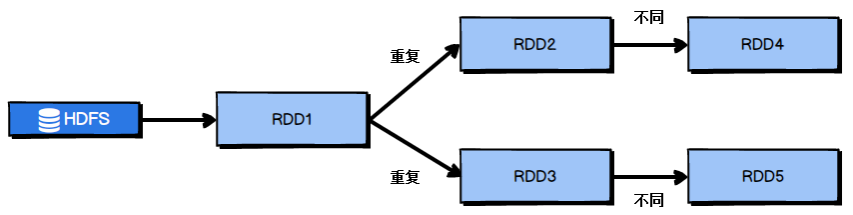
Modify the RDD computing architecture in Figure 2-1 to obtain the optimization results as shown in Figure 2-2:
2.2 filter as soon as possible
After obtaining the initial RDD, we should consider filtering out the unnecessary data as soon as possible, so as to reduce the occupation of memory, so as to improve the operation efficiency of Spark jobs.
2.3,foreachpartition
rrd.foreache(...) / / represents each element
rrd.forPartitions(...) / / / represents the iterator composed of data of each partition
foreachPartition takes each partition of RDD as a traversal object and processes the data of one partition at a time, that is, if the database related operations are involved, the data of one partition only needs to create a database connection.
2.4. filter+coalesce reduce zoning
In the Spark task, we often use the filter operator to filter the data in RDD. In the initial stage of the task, the amount of data loaded from each partition is similar, but once filter filtering is carried out, the amount of data in each partition may vary greatly, as shown in Figure 2-6:
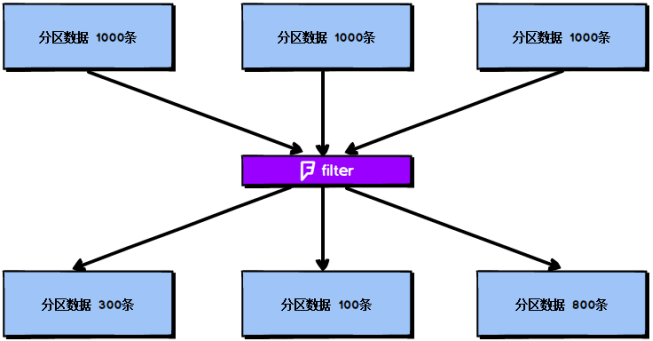
According to figure 2-6, we can find two problems:
-
The amount of data in each partition becomes smaller. If you still process the current data according to the number of tasks equal to the previous partition, it will waste task computing resources;
-
The data volume of each partition is different, which will lead to different data volume to be processed by each task when processing the data of each partition, which may lead to the problem of data skew.
For the above two problems, we analyze them respectively:
- To solve the first problem, since the amount of data in the partition has become smaller, we hope to redistribute the partition data, such as converting the data from the original four partitions into two partitions. In this way, we only need to use the following two task s to process, so as to avoid the waste of resources.
- For the second problem, the solution is very similar to the solution of the first problem. Redistribute the partition data so that the amount of data in each partition is the same, which avoids the problem of data skew.
2.5. reducebykey local pre aggregation
Compared with ordinary shuffle operations, a remarkable feature of reduceByKey is that it will conduct local aggregation on the map side. The map side will combine the local data first, and then write the data to the file created by each task in the next stage.
Based on the local aggregation feature of reduceByKey, we should consider using reduceByKey instead of other shuffle operators, such as groupByKey. The operation principles of reduceByKey and groupByKey are shown in Figure 2-9 and figure 2-10:
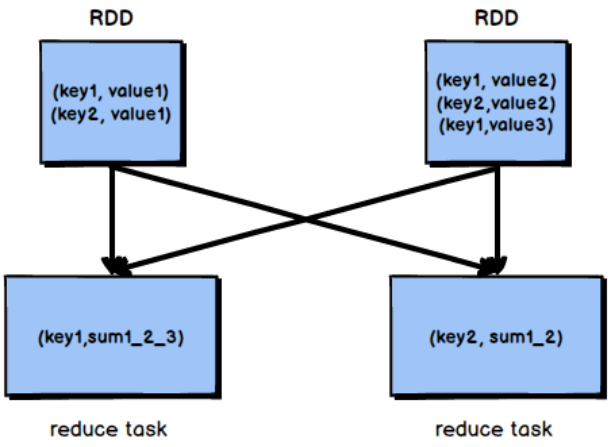
Figure 2-9 groupByKey principle
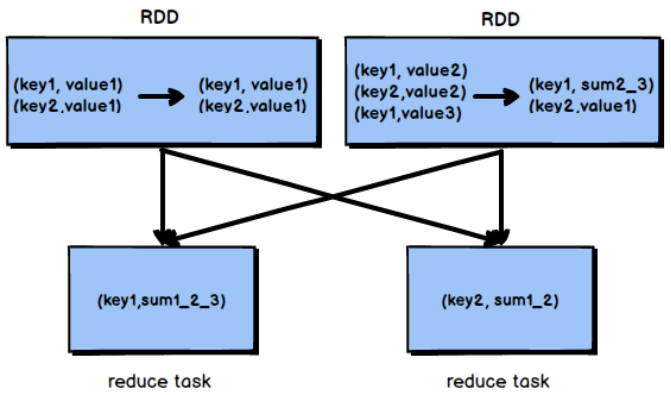
Figure 2-10 principle of reducebykey
According to the above figure, groupByKey will not aggregate the map side, but shuffle all the map side data to the reduce side, and then aggregate the data at the reduce side. Because reduceByKey has the feature of map side aggregation, the amount of data transmitted on the network is reduced, so the efficiency is significantly higher than that of groupByKey.
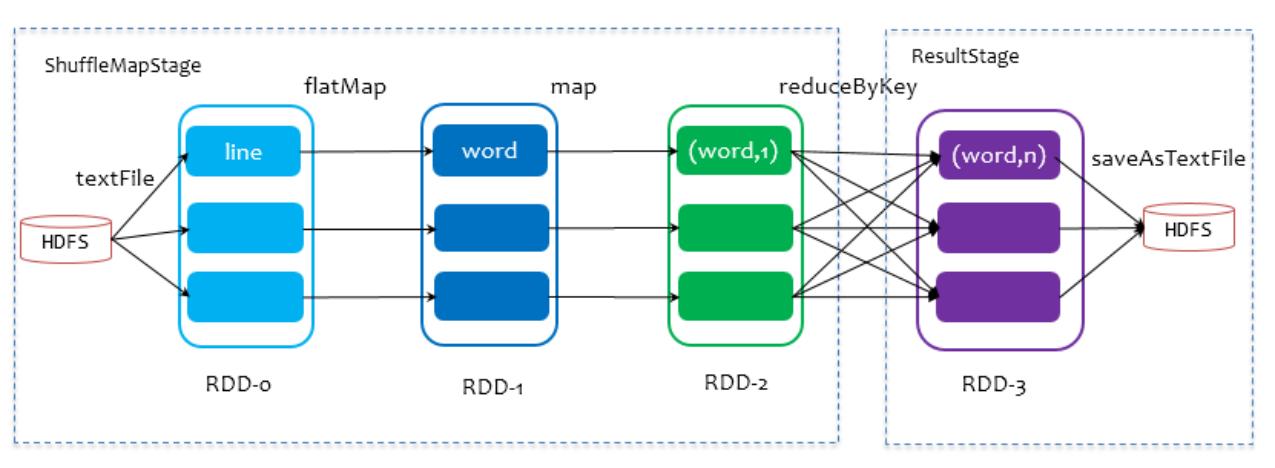
3. shuffle tuning
When dividing stages, the last stage is called finalStage, which is essentially a ResultStage object. All previous stages are called ShuffleMapStage. The end of the ShuffleMapStage is accompanied by the writing of the shuffle file to disk.
1. map and reduce side buffer size
map end
During the Spark task, if the amount of data processed by the map side of the shuffle is large, but the size of the map side buffer is fixed, the map side buffer data may spill into the disk file frequently, resulting in very low performance. By adjusting the size of the map side buffer, frequent disk IO operations can be avoided, So as to improve the overall performance of Spark tasks.
The default configuration of the map side buffer is 32KB. If each task processes 640KB data, 640 / 32 = 20 overflow writes will occur. If each task processes 64000KB data, 64000 / 32 = 2000 overflow writes will occur, which has a very serious impact on performance.
The configuration method of map side buffer is shown in code listing 2-7:
val conf = new SparkConf()
.set("spark.shuffle.file.buffer", "64")
reduce end
In the Spark Shuffle process, the buffer buffer size of the shuffle reduce task determines the amount of data that the reduce task can buffer each time, that is, the amount of data that can be pulled each time. If the memory resources are sufficient, appropriately increasing the size of the pull data buffer can reduce the number of times of pulling data, reduce the number of network transmission, and improve the performance.
The size of the data pull buffer on the reduce side can be set through the spark.reducer.maxSizeInFlight parameter, which defaults to 48MB. The setting method of this parameter is shown in code listing 2-8:
val conf = new SparkConf()
.set("spark.reducer.maxSizeInFlight", "96")
2. Retry times and waiting time interval of reduce end
retry count
During Spark Shuffle, when the reduce task pulls its own data, it will automatically retry if it fails due to network exceptions and other reasons. For those jobs with particularly time-consuming shuffle operations, it is recommended to increase the maximum number of retries (3 by default) to avoid data pull failure due to JVM full gc or network instability. In practice, it is found that for the shuffle process with a large amount of data (billions to tens of billions), adjusting this parameter can greatly improve the stability.
//Configuration of retries for pulling data at the reduce end
val conf = new SparkConf()
.set("spark.shuffle.io.maxRetries", "6")
Waiting interval
In the Spark Shuffle process, if the reduce task fails to pull its own data due to network exceptions, it will automatically retry. After a failure, it will wait for a certain time interval to retry. You can increase the interval length (5s by default) to increase the stability of the shuffle operation.
val conf = new SparkConf()
.set("spark.shuffle.io.retryWait", "60s")
3. bypass mechanism on threshold
When you use SortShuffleManager, if you really don't need sorting operations, it is recommended to increase this parameter to be greater than the number of shuffle read task s. At this time, the map side will not be sorted, reducing the performance overhead of sorting.
val conf = new SparkConf()
.set("spark.shuffle.sort.bypassMergeThreshold", "400")
4. Data skew
4.1. Causes of tilt caused by pretreatment
● 1. Filtration
If it is allowed to discard some data in the Spark job, you can consider filtering the key that may cause data skew and filtering the data corresponding to the key that may cause data skew, so that data skew will not occur in the Spark job.
● 2. Use random key
When operators such as groupByKey and reduceByKey are used, random keys can be used to realize double aggregation, as shown in Figure 3-1:
4.2. Improve reduce parallelism
The increase of the parallelism of the reduce side increases the number of tasks on the reduce side, and the amount of data allocated to each task will be reduced accordingly, so as to alleviate the problem of data skew.
1. Setting of parallelism at reduce end
In most shuffle operators, you can pass in a parallelism setting parameter, such as reduceByKey(500). This parameter will determine the parallelism of the reduce end in the shuffle process. During the shuffle operation, a specified number of reduce task s will be created. For shuffle statements in Spark SQL, such as group by and join, you need to set a parameter, spark.sql.shuffle.partitions, which represents the parallelism of shuffle read task. The default value is 200, which is a little too small for many scenarios.
Usage scenarios are limited:
This scheme usually cannot completely solve the problem of data skew, because if there are some extreme cases, such as 1 million data corresponding to a key, no matter how many tasks you increase, the key corresponding to 1 million data will certainly be allocated to a task for processing, so data skew is bound to occur.
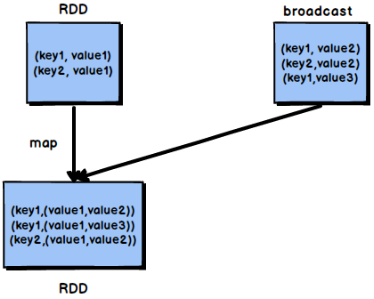
4.3. Using mapjoin
Ordinary join will go through the shuffle process. Once shuffled, it is equivalent to pulling the data of the same key into a shuffle read task for join. At this time, it is reduce join. However, if an RDD is relatively small, broadcast small RDD full data + map operator can be used to achieve the same effect as join, that is, map join. At this time, shuffle operation and data skew will not occur.
Core ideas
Instead of using the join operator for connection operation, the Broadcast variable and map class operator are used to realize the join operation, so as to completely avoid the shuffle class operation and completely avoid the occurrence and occurrence of data skew. Pull the data in the smaller RDD directly to the memory of the Driver through the collect operator, and then create a Broadcast variable for it; Then, execute the map operator on another RDD. In the operator function, obtain the full amount of data of the smaller RDD from the Broadcast variable, and compare it with each data of the current RDD according to the connection key. If the connection key is the same, connect the data of the two RDDS in the way you need.
According to the above ideas, the shuffle operation will not occur at all, and the data skew problem that may be caused by the join operation is fundamentally eliminated.
11.27 common problems in spark Development
1. Memory overflow
spark's common problems are nothing more than oom
Let's first look at Spark's memory model:
The memory in SparkExecutor is divided into three blocks, one is execution memory, the other is storage memory and other memory.
-
Execution memory is the execution memory. The document says that join and aggregate are executed in this part of memory, and the shuffle data will be cached in this memory first, and then written to the disk when it is full, which can reduce IO. In fact, the map process is also executed in this memory.
-
storage memory is the place where broadcast, cache and persist data are stored.
-
other memory is the memory reserved for itself during program execution.
The problem of OOM usually occurs in the memory of execution, because after the memory of storage is full, the old data in the memory will be directly discarded, which has an impact on the performance, but there will be no problem of OOM.
The OOM problem in Spark is no more than the following three cases
- Memory overflow during map execution
- Memory overflow after shuffle
- driver memory overflow
1,Driver heap OOM
Scenario 1: the user generates large objects on the Driver port, for example, creates a large collection data structure
Solution:
1.1. Consider converting the large object into an Executor side load. For example, call sc.textFile/sc.hadoopFile, etc
1.2. If it is unavoidable, self evaluate the memory occupied by the large object and increase the driver memory value accordingly
Scenario 2: collect data from the Executor and return to the Driver
Solution:
2.1. It is not recommended to collect large data from the Executor itself. It is recommended to convert the Driver's operation on the collected data into the Executor's RDD operation
2.2. If it cannot be avoided, self evaluate the memory required by collect and increase the driver memory value accordingly
Scenario 3: data consumption of Spark framework
- Now, after spark 1.6, it is mainly consumed by Spark UI data, depending on the cumulative number of tasks
Solution:
3.1. The number of partitions, for example, is calculated automatically from the partitions of HDFS load. However, subsequent user operations such as filtering have greatly reduced the amount of data. At this time, the partitions can be reduced.
3.2. Controlled by the parameter spark.ui.retainedstages (default 1000) / spark.ui.retainedjobs (default 1000)
3.3. There is no way to avoid it. Increase the memory accordingly
2. The executor running map task is out of memory
resolvent:
1. Increase the Executor memory (i.e. in heap memory), and the requested out of heap memory will also increase
--executor-memory 5G
2. Increase out of heap memory -- conf spark.yarn.executor.memoryoverhead 2048M
--conf spark.executor.memoryoverhead 2048M
(by default, the requested out of heap memory is 10% of the Executor's memory. When really processing big data, problems will occur here, resulting in repeated crash of spark job and failure to run; at this time, this parameter will be adjusted to at least 1G (1024M), or even 2G and 4G)
3. Memory overflow in the shuffle (reduce) phase
- reduce task pulls data from the map. Reduce aggregates data while pulling data. The reduce segment has a piece of aggregate memory (executor memory * 0.2)
terms of settlement:
1. Increase the memory proportion of reduce aggregation and set spark.shuffle.memoryFraction
2. Increase the size of executor memory -- executor memory 5g
3. Reduce the amount of data pulled by reduce task each time. Set spark.reducer.maxSizeInFlight 24m
2. shuffle file pull failure caused by gc
In Spark jobs, sometimes a shuffle file not found error occurs, which is a very common error report. Sometimes after this error occurs, choose to execute it again and no longer report this error.
The possible reason for the above problems is that during the Shuffle operation, the task of the later stage wants to pull data from the Executor where the task of the previous stage is located. As a result, the other party is executing GC. Executing GC will cause all work sites in the Executor to stop, such as BlockManager and network communication based on netty, which will lead to the fact that the data pulled by the later task has not been pulled for half a day When the file is pulled, an error of shuffle file not found will be reported, and this error will not occur again in the second execution.
You can adjust the Shuffle performance by adjusting the two parameters: the retry times of pulling data at the reduce end and the time interval of pulling data at the reduce end. Increasing the parameter value increases the retry times of pulling data at the reduce end and the waiting time interval after each failure.
val conf = new SparkConf()
.set("spark.shuffle.io.maxRetries", "6")
.set("spark.shuffle.io.retryWait", "60s")
3. yarn_cluster mode JVM stack memory overflow
In the yarn client mode, the Driver runs on the local machine. The PermGen configuration of the JVM used by Spark is the Spark class file on the local machine. The size of the JVM permanent generation is 128MB. There is no problem when running on the client for testing.
In the cluster mode, the Driver runs on a node of the YARN cluster, using the default settings that have not been configured, and the PermGen permanent generation size is 82MB. The operation reports an OOM error.
To solve the above problems, increase the capacity of PermGen, and set the relevant parameters in the spark submit script.
--conf spark.driver.extraJavaOptions="-XX:PermSize=128M -XX:MaxPermSize=256M"