1 HelloWorld case
1) In the windows environment, create a new azkaban.project file. The editing content is as follows: Azkaban flow version: 2.0
Note: the function of this file is to parse the flow file using the new flow API method.
2.0 azkaban supports both properties configuration files and yml configuration files!
3.0 azkaban supports yml configuration files by default!
1.1 yarm syntax:
yml: Concise, suitable for representing data with complex hierarchical relationships!
- yml mainly uses indentation to represent the hierarchical relationship. Once the next line is indented, it means that the next line is the sub attribute of the previous line!
- When indenting, if the indented distance is the same, the level is the same!
- Use a lot of spaces. You can't use tab when indenting. You must use spaces between K-V!
K-V type representation:
k:(Space)v
Object type data, map(k-v)
jack: name: jack age: 20
Single line:
jack: {name: jack,age: 20}
Array type, data, List,Set
fruits: - apple - banana
Single line:
fruits: [apple,banana]

2) Create a new basic.flow file as follows
nodes:
- name: jobA
type: command
config:
command: echo "Hello World"
(1) Name: job name
(2) Type: job type. Command indicates that the way you want to execute the job is command
(3) Config: job configuration
3) Compress the azkaban.project and basic.flow files into a zip file. The file name must be in English.

4) Create a new project in WebServer: http://hadoop102:8081/index
5) Name the project name and add a project description

6) first.zip file upload

7) Select the file to upload

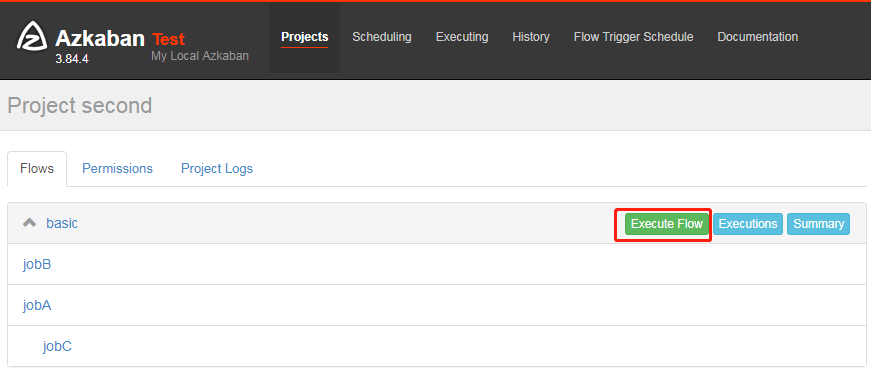
8) Execute task flow
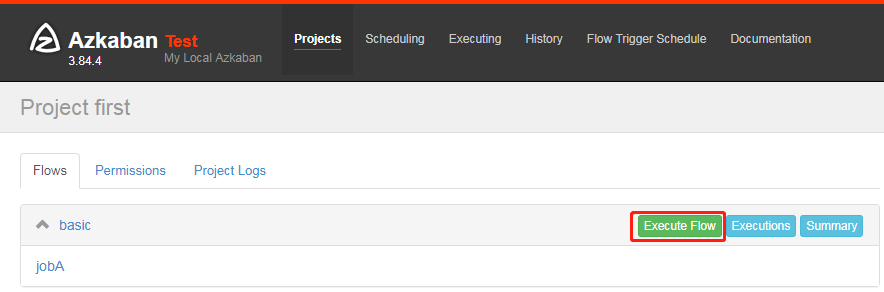
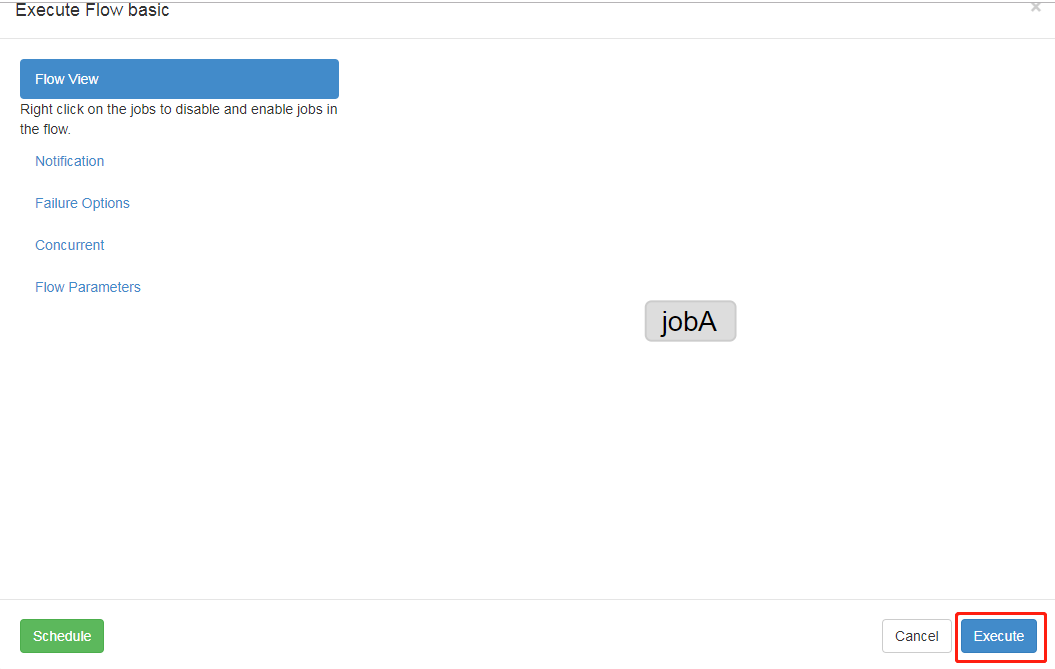
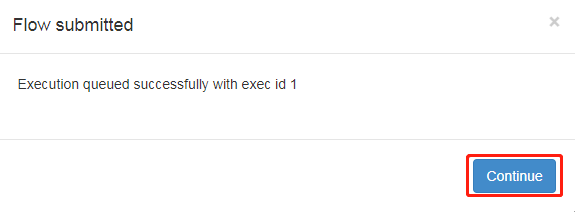
9) In the log, view the running results
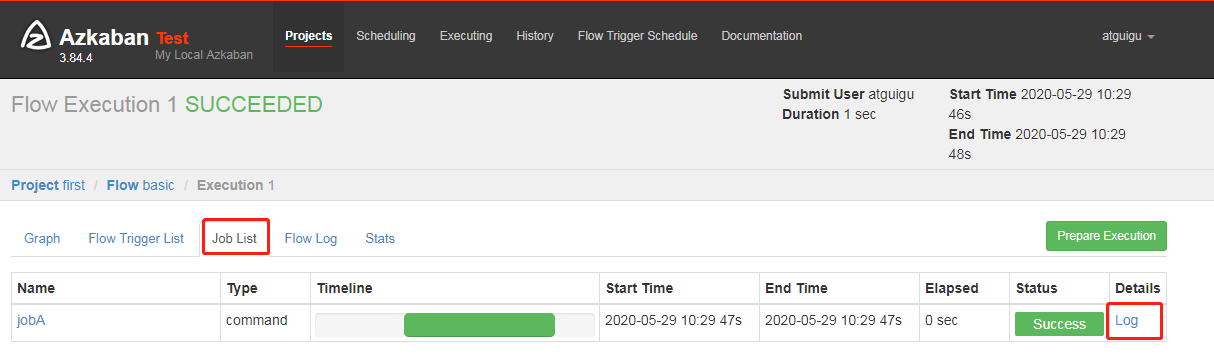

2. Job dependency cases
Requirement: JobC can only be executed after JobA and JobB are executed
Specific steps:
2.1 modify basic.flow as follows
nodes:
- name: jobC
type: command
# jobC depends on JobA and JobB
dependsOn:
- jobA
- jobB
config:
command: echo "I'm JobC"
- name: jobA
type: command
config:
command: echo "I'm JobA"
- name: jobB
type: command
config:
command: echo "I'm JobB"
(1) dependsOn: job dependency, as demonstrated in the following cases
2.2 compress the modified basic.flow and azkaban.project into a second.zip file

2.3 repeat the next steps of HelloWorld.




3 automatic failure retry case
Requirement: if the task fails to be executed, it needs to be retried 3 times, and the retry interval is 10000ms
Specific steps:
3.1 compiling configuration flow
nodes:
- name: JobA
type: command
config:
command: sh /not_exists.sh
retries: 3
retry.backoff: 10000
This sh file does not exist
Parameter Description:
Retries: number of retries
retry.backoff: retry interval
3.2 compress the modified basic.flow and azkaban.project into four.zip file

3.3 repeat the next steps of HelloWorld.


3.4 execute and observe one failure + three retries
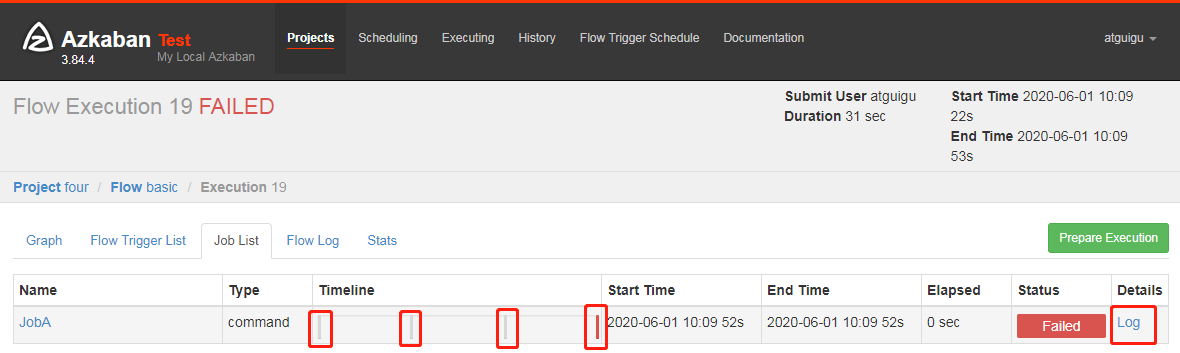
3.5 you can also click the Log in the figure above to see in the task Log that it has been executed 4 times in total
. 
3.6 you can also add the task failure retry configuration in the Flow global configuration. At this time, the retry configuration will be applied to all jobs
The cases are as follows:
config:
retries: 3
retry.backoff: 10000
nodes:
- name: JobA
type: command
config:
command: sh /not_exists.sh
4 manual failure retry cases
Requirement: JobA = "JobB (dependent on A) =" JobC = "JobD =" JobE = "JobF". In the production environment, any Job may hang up. You can execute the Job you want to execute according to your needs.
Specific steps:
4.1 compiling configuration flow
nodes:
- name: JobA
type: command
config:
command: echo "This is JobA."
- name: JobB
type: command
dependsOn:
- JobA
config:
command: echo "This is JobB."
- name: JobC
type: command
dependsOn:
- JobB
config:
command: echo "This is JobC."
- name: JobD
type: command
dependsOn:
- JobC
config:
command: echo "This is JobD."
- name: JobE
type: command
dependsOn:
- JobD
config:
command: echo "This is JobE."
- name: JobF
type: command
dependsOn:
- JobE
config:
command: echo "This is JobF."
4.2 compress the modified basic.flow and azkaban.project into five.zip file

4.3 repeat the next steps of HelloWorld.
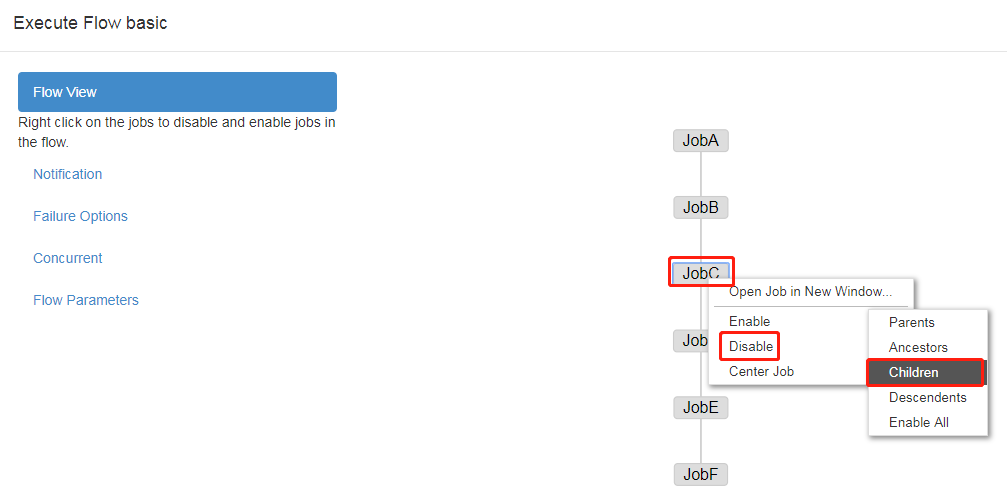
Both Enable and Disable have the following parameters:
Parents: the previous task of the job
Antecessors: all tasks before the job
Children: a task after the job
Descendants: all tasks after the job
Enable All: all tasks
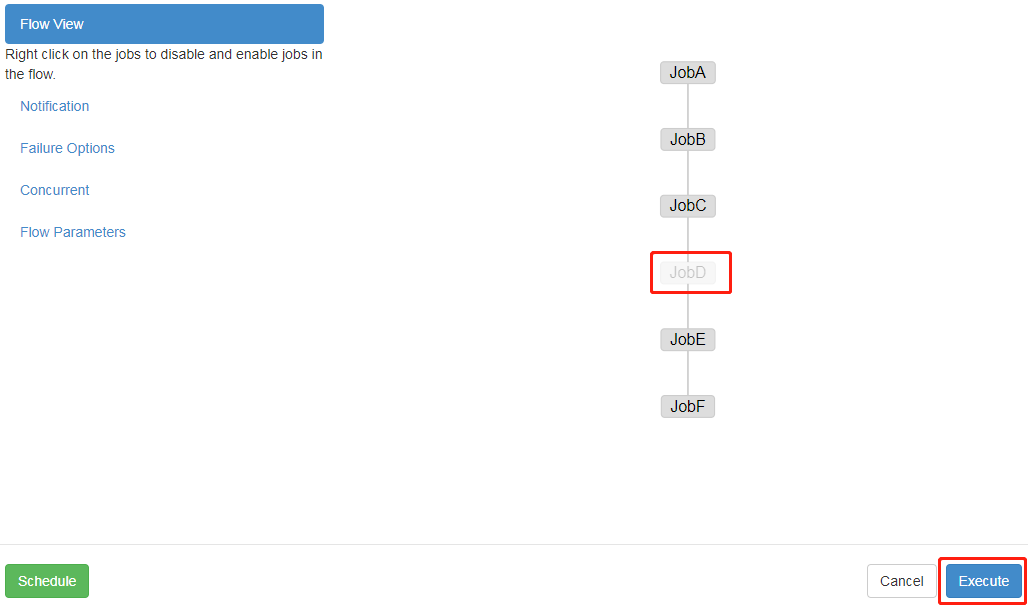
4.4 corresponding tasks can be selectively executed according to requirements.
