Beauty-Jump Table of Algorithms and Data Structure
The bottom level of binary lookup depends on the random access of arrays. If arrays are stored in a chain table, how do we use the binary lookup algorithm?Today, this blog post introduces jump tables, which support fast insertion, deletion, and search operations;
An ordered array of Redis species is achieved by using a jump table.
Understanding Jump Tables
For a single-chain table, even though the data stored in the chain table is ordered, the efficiency of finding data is low and the time complexity is O(n), as shown in the following figure:
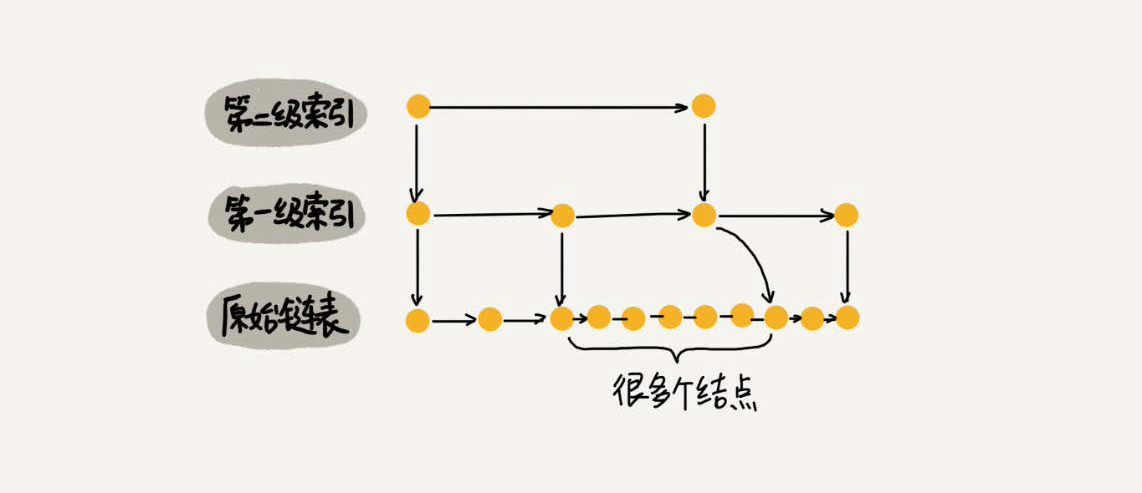
Is it more efficient to create a multilevel index on a chain table?For example, if one node is extracted from each of the two nodes to the next level, the level that is extracted is called the index or index level.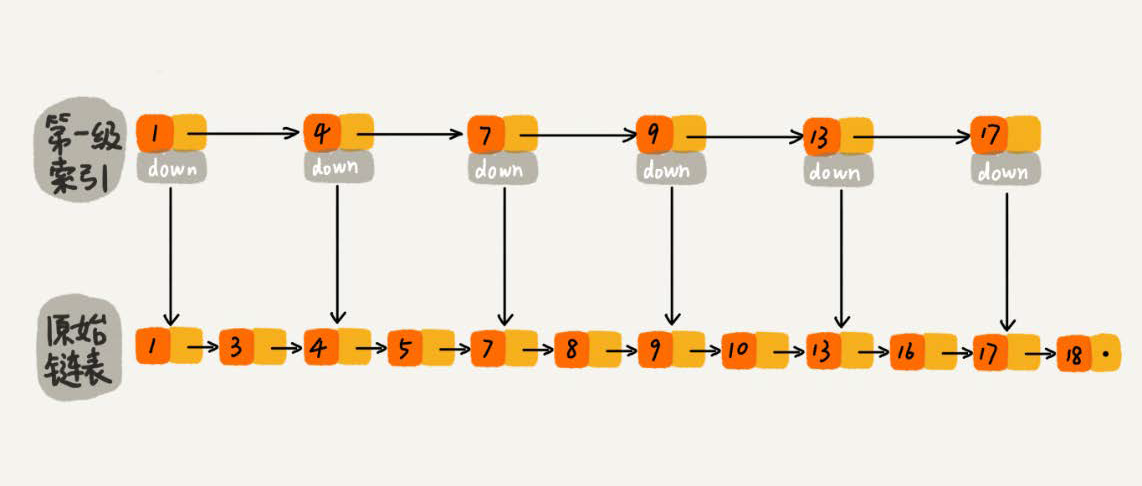
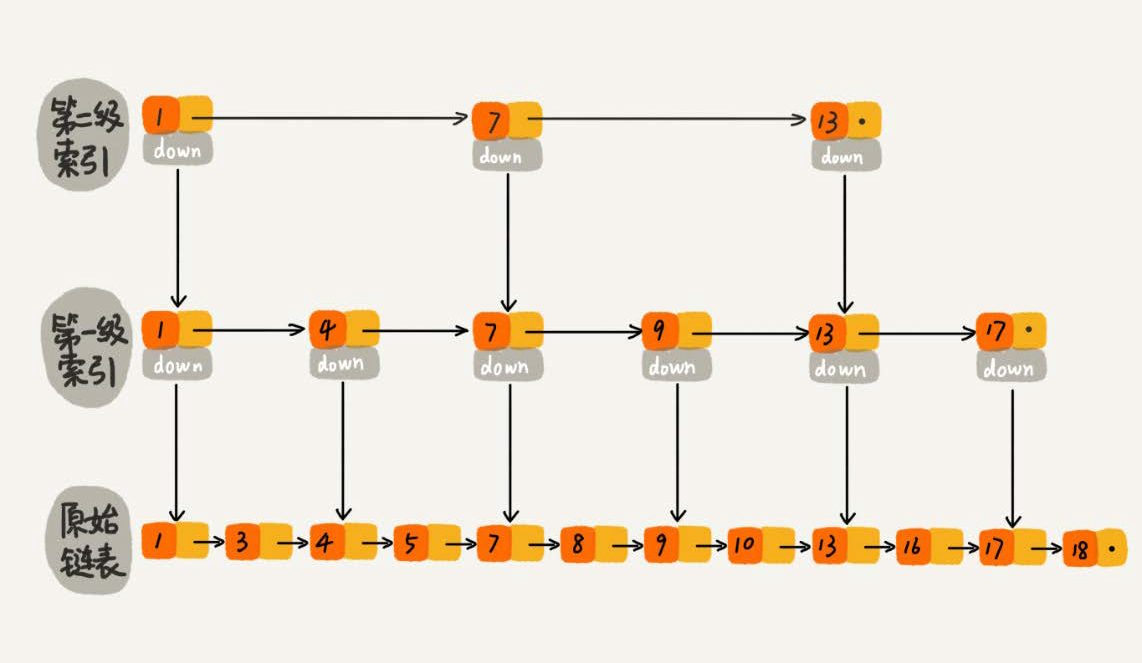
Jump Table Query Efficiency
For a single-chain table with O(n) query efficiency, assuming that there are n nodes in the chain table, if a node is selected as the node of the upper index after every two nodes, then the number of nodes in the first index is n/2, the number of nodes in the second index is n/4, and the number of nodes in the K index is n/(2^k). Finally, the query of the jump table is used.Efficiency is O(logn). The improvement of query efficiency is based on the multi-level index, using the concept of space for time.
Memory consumption of jump tables

For the node-to-equal-ratio column sum of multilevel indexes, the spatial complexity of the jump table is O(n), which requires only additional storage space close to n nodes.
So how do you reduce the memory footprint of the index?
If one node is extracted from the upper index every two nodes, then the index nodes can be reduced and one index node can be extracted every three or five nodes.
n/3+n/9+n/27+...+9+3+1=n/2, the required memory space is reduced by half;
Efficient dynamic insertion and deletion
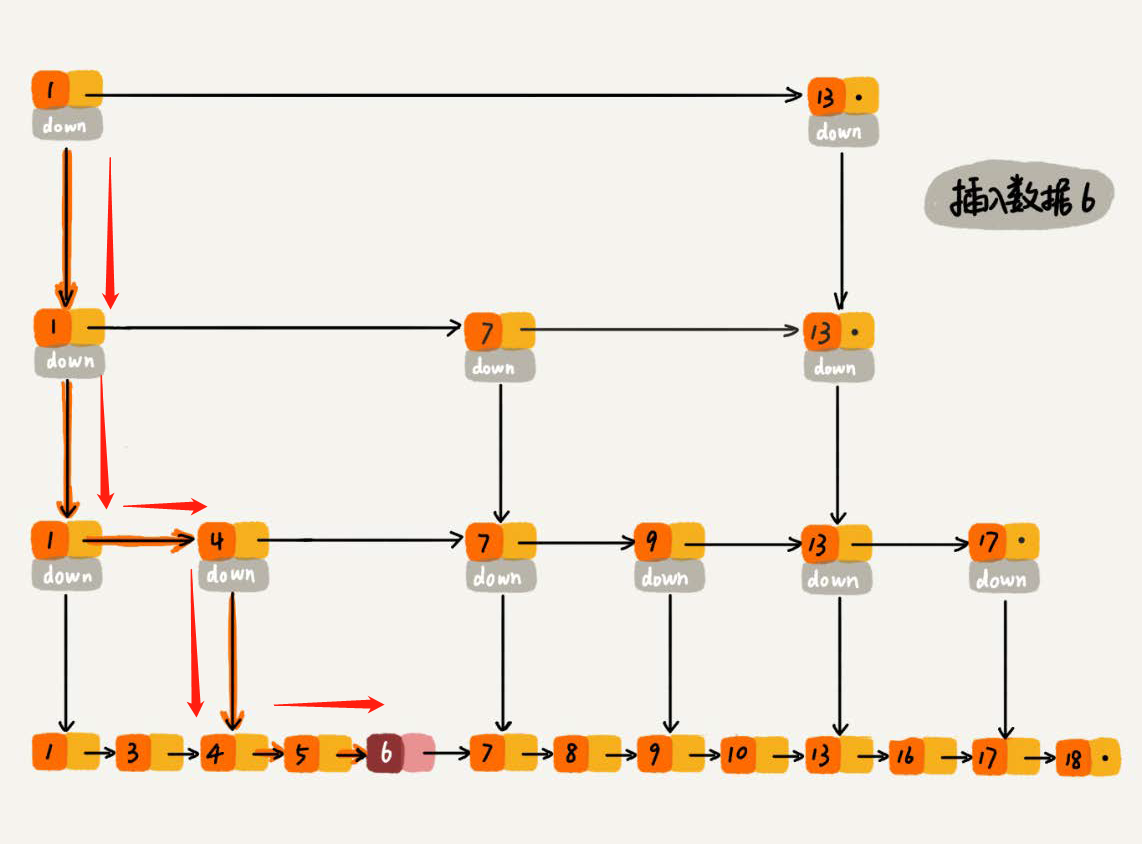
The time complexity of finding a node is O(log(n). For deletion of single-chain list, it is necessary to get the precursor node to delete the node, and then complete the deletion by pointer operation; for two-way Chain list, these problems need not be considered;
Jump table index dynamic update
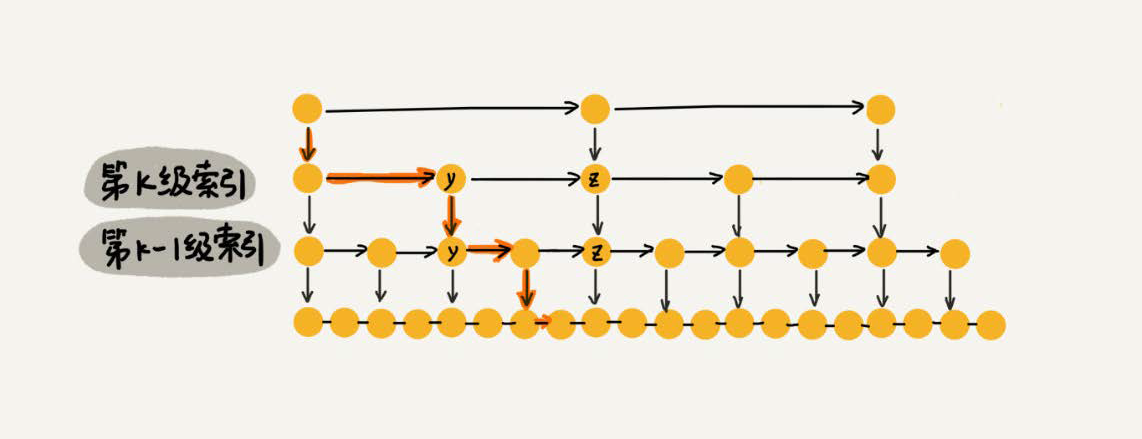
As a dynamic data structure, we need some means to maintain the balance between the index and the size of the original chain table; when the number of nodes in the chain table increases, the index nodes increase accordingly, to avoid the degradation of complexity, and to reduce the performance of search, insert and delete operations;
When we insert a data into the jump table, we can also choose to insert this data into a partial index layer.
A random function is used to determine which level of index a node is inserted into, for example, if a random function generates K, then we add the node to the index between the first and the K levels.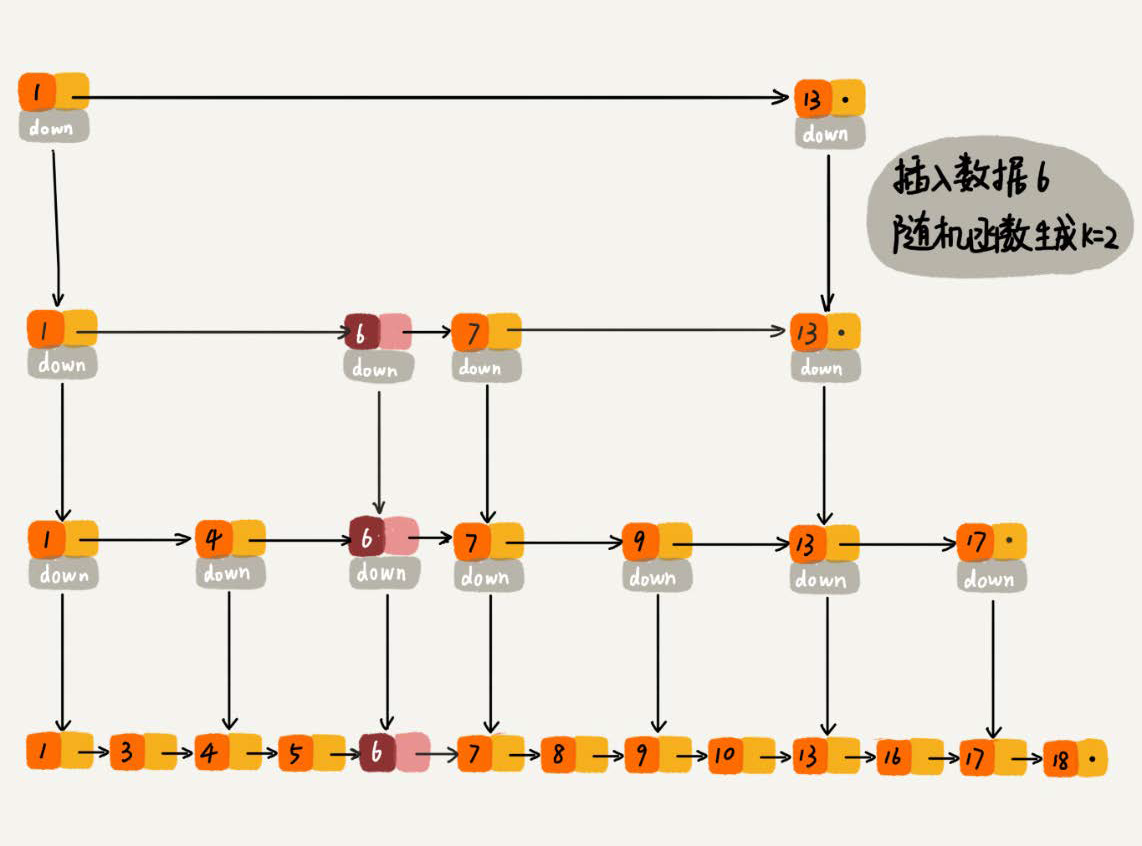
code implementation
import java.util.Random; public class SkipList { private static final int MAX_LEVEL = 16; private int levelCount = 1; //Lead Chain List private Node head = new Node(); private Random r = new Random(); //Jump Table Query public Node find(int value){ Node p = head; for(int i = levelCount-1;i>=0;--i) { while(p.forward[i]!=null&&p.forward[i].data<value){ p = p.forward[i]; } } if(p.forward[0]!=null&&p.forward[0].data==value) return p.forward[0]; else{ return null; } } //Jump Table Insertion public void insert(int value){ int level = randomLevel(); Node newNode = new Node(); newNode.data = value; newNode.maxLevel=level; Node update[] = new Node[level]; for(int i=0;i<level;++i) update[i] = head; // record every level largest value which smaller than insert value in update[] Node p = head; for(int i = level - 1;i>=0;--i) { while(p.forward[i]!=null&&p.forward[i].data<value){ p = p.forward[i]; } update[i] = p;//use update save node in search path } // in search path node next node become new node forwords(next) for (int i = 0; i < level; ++i) { newNode.forward[i] = update[i].forward[i]; update[i].forward[i] = newNode; } // update node hight if (levelCount < level) levelCount = level; } public void delete(int value) { Node[] update = new Node[levelCount]; Node p = head; for (int i = levelCount - 1; i >= 0; --i) { while (p.forward[i] != null && p.forward[i].data < value) { p = p.forward[i]; } update[i] = p; } if (p.forward[0] != null && p.forward[0].data == value) { for (int i = levelCount - 1; i >= 0; --i) { if (update[i].forward[i] != null && update[i].forward[i].data == value) { update[i].forward[i] = update[i].forward[i].forward[i]; } } } } // Random level times, if odd number of layers + 1, to prevent pseudo-random private int randomLevel() { int level = 1; for (int i = 1; i < MAX_LEVEL; ++i) { if (r.nextInt() % 2 == 1) { level++; } } return level; } public void printAll() { Node p = head; while (p.forward[0] != null) { System.out.print(p.forward[0] + " "); p = p.forward[0]; } System.out.println(); } public class Node { private int data = -1; private Node forward[] = new Node[MAX_LEVEL]; private int maxLevel = 0; @Override public String toString(){ StringBuilder builder = new StringBuilder(); builder.append("{ data: "); builder.append(data); builder.append("; levels: "); builder.append(maxLevel); builder.append(" }"); return builder.toString(); } } }
Answer opening
Core operations supported by ordered collections in Redis:
- insert data
- Delete data
- Find data
- Find data by interval
- Iterative Output Ordered Sequence
There are other reasons why Redis uses jump tables for ordered collections, such as easier code implementation.Although the implementation of jump table is not simple, it is much better to understand and write than the red and black trees, and simple means good readability and not easy to make mistakes.Also, jump tables are more flexible and can balance execution efficiency and memory consumption effectively by changing index building strategies.