Search "xxx weather" in any browser, such as Chongqing weather,
We select the first website to crawl, and the url is' ' weathernew.pae.baidu.com/weathernew/pc?query = Chongqing Weather & srcid = 4982 & City_ Name = Chongqing & Province_ Name = Chongqing'
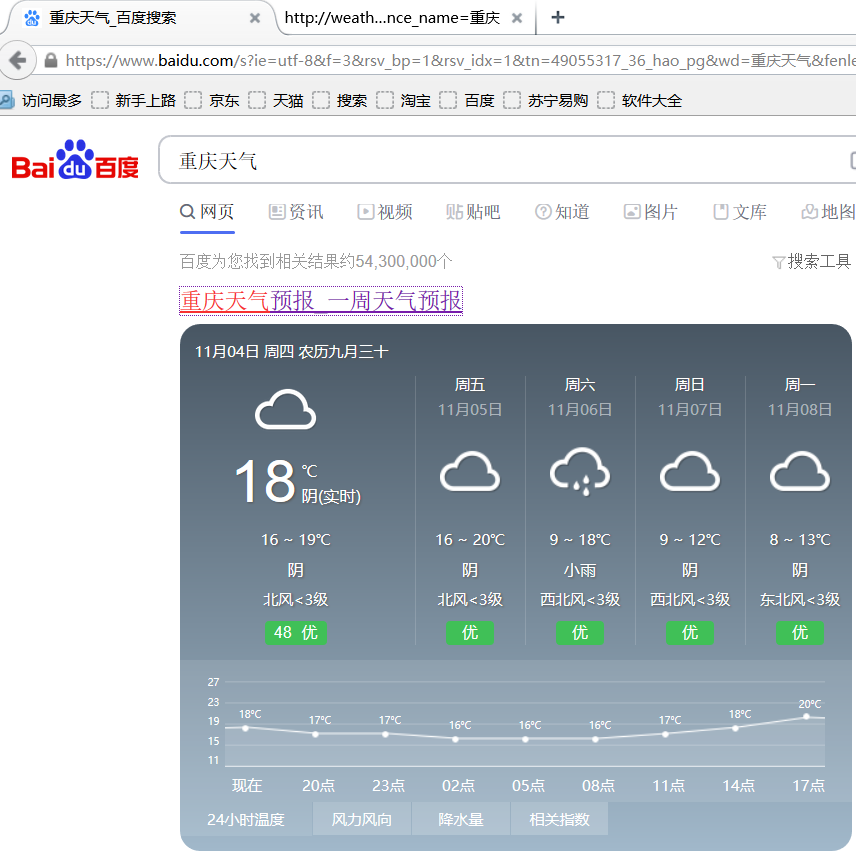
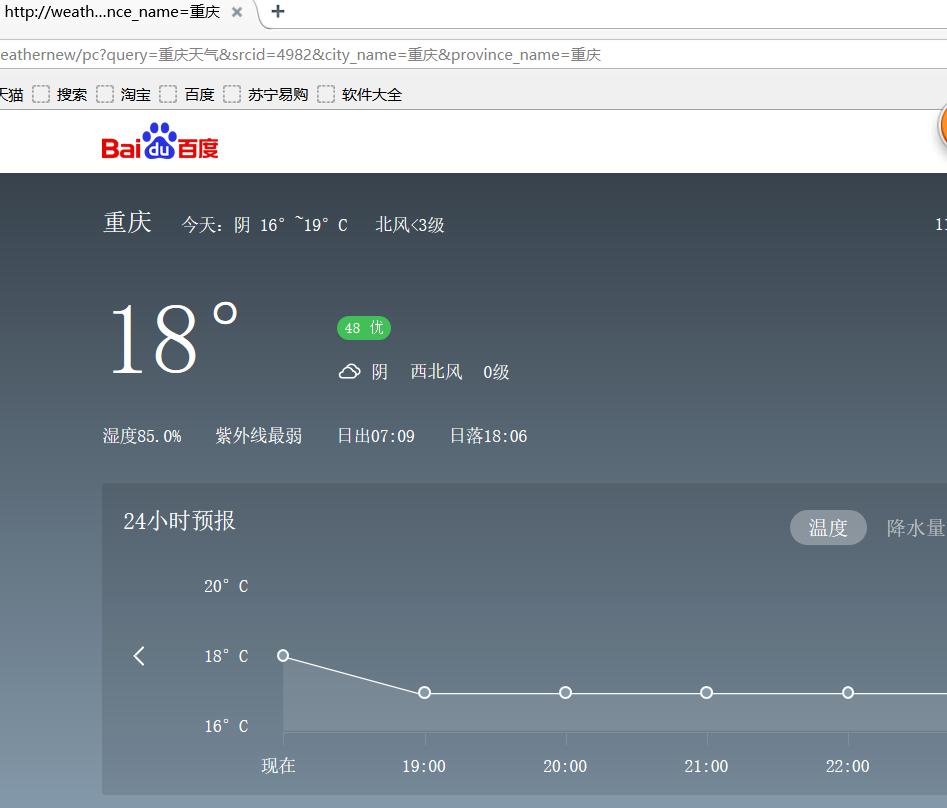
Next, crawl the web page in python:
def Get_tetx(url):
try:
# You can customize the IP pool, or use the native IP or IP proxy pool
agent = get_random_agent()
# Request header file, you can add other parameters by yourself
headers = {'User-Agent': agent}
r = requests.post(url, timeout=30, headers=headers).content.decode('utf-8')
return r
except:
# Error log
logger.info("There are some errors when get the original html!")We output the return value r and view the obtained web page source code; Then you will find that the obtained r is not the same as the < td > < tr > of the web source code, which is very surprising! Did we make a mistake?
Don't worry, let's right-click to view the web page source code
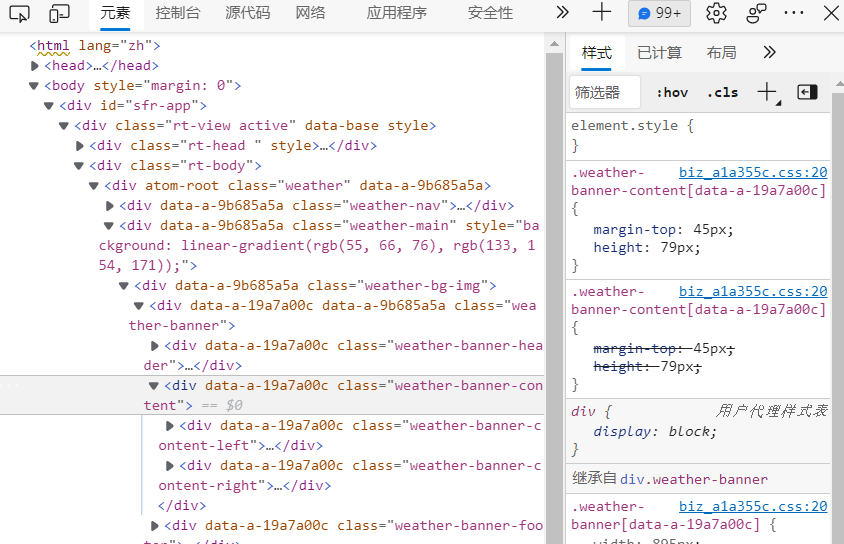
Then click the web button above and refresh the web page
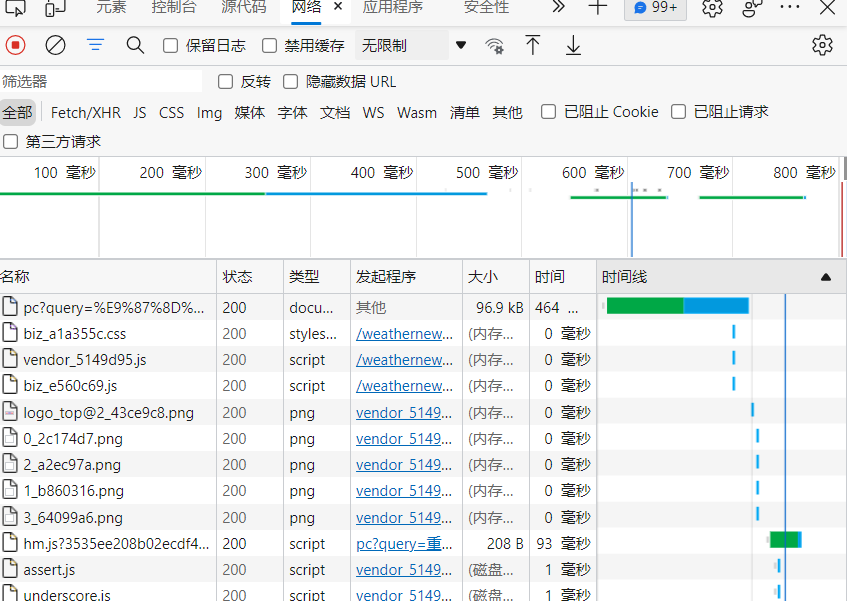
Click the first file to view the response, and you will find that there is no error
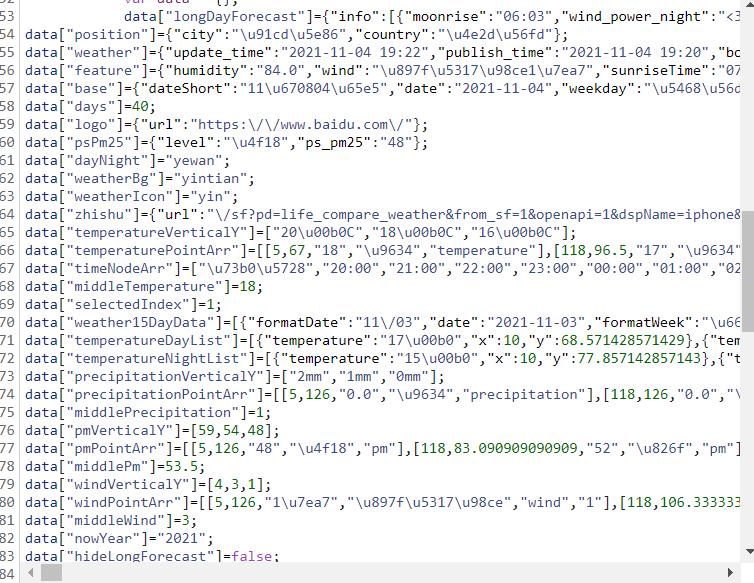
Since the obtained web page code is useless, the next step is to extract the data and analyze r, as we can see
data["weather15DayData"] is the local data for the past 15 days, including the date, weather conditions, wind direction during the day and night, wind force, etc
data["temperatureDayList"] is the daytime temperature data; Data ["temperatureinightlist"] is the night temperature data
data["timeNodeArr"] is the temperature forecast for the next 24 hours
We extract the above data through regular expressions:
def get_data(url):
htmlBodyText = Get_tetx(url)
# Get raw weather data
weather_text = htmlBodyText[
htmlBodyText.find('data["weather15DayData"]='):htmlBodyText.find(
'data["temperatureDayList"]')]
# print(weather_text)
# Get raw maximum temperature data
temperatureDayList = htmlBodyText[htmlBodyText.find('data["temperatureDayList"]='):htmlBodyText.find(
'data["temperatureNightList"]')]
# print(temperatureDayList)
# Get minimum temperature data
temperatureNightList = htmlBodyText[htmlBodyText.find('data["temperatureNightList"]'):htmlBodyText.find(
'data["precipitationVerticalY"]')]
# print(temperatureNightList)
# Find high temperature data
max_temperature = re.findall(r'"temperature":"(\d+\.?\d*).*?","x"', temperatureDayList)
print(max_temperature)
# Translate into Chinese characters or numbers
# max_temperature=Change_data(max_temperature)
# It is character type when obtaining and converted to integer type
for i in range(len(max_temperature)):
max_temperature[i] = int(max_temperature[i])
print("The highest temperature data obtained is:", max_temperature)
# Find low temperature data
min_temperature = re.findall(r'"temperature":"(\d+\.?\d*).*?","x"', temperatureNightList)
# min_temperature = Change_data(min_temperature)
# print(min_temperature)
for i in range(len(min_temperature)):
min_temperature[i] = int(min_temperature[i])
print("The lowest temperature data obtained is:", min_temperature)
for i in range(len(self.min_temperature)):
temperature[i] = (max_temperature[i] + min_temperature[i]) / 2
print("The average temperature is:", temperature)
# Get date
year_date = re.findall(r'"date":"(.*?)","formatWeek"', weather_text)
print('The obtained date is:', year_date)
# # Get weather
# weather_data = re.findall(r'"weatherText":"(.*?)"}', weather_text)
# weather_data = Change_data(weather_data)
# print('the weather condition obtained is: ', weather_data)
#
# # Get daytime wind direction
# wind_day_data = re.findall(r'"windDirectionDay":"(.*?)","windDirectionNight"', weather_text)
# wind_day_data = Change_data(wind_day_data)
# print('Get wind direction in the day: ', wind_day_data)
#
# # Get the wind direction at night
# wind_night_data = re.findall(r'"windDirectionNight":"(.*?)","windPowerDay"', weather_text)
# wind_night_data = Change_data(wind_night_data)
# print('Get wind direction at night: ', wind_night_data)
#
# # Get wind
# wind_level = re.findall(r'"windPowerDay":"(.*?)","windPowerNight":', weather_text)
# wind_level = Change_data(wind_level)
# print(wind_level)
#
# def Change_data(data_list):
# for i in range(len(data_list)):
# data_list[i] = data_list[i].encode('utf-8').decode('unicode_escape')
# return data_list
In the process of data extraction, there will be such data as \ u9634. It is found that there can be results when trying to output. It shows that this kind of data is only encrypted, but there is no user-defined data type, so it is still relatively simple, just need to convert the format
The process of crawling Chongqing weather data here is basically over, but what if we climb Beijing weather and Nanjing Weather? Change url?
It's a method, but it's cumbersome
We're on the original url ' weathernew.pae.baidu.com/weathernew/pc?query = Chongqing Weather & srcid = 4982 & City_ Name = Chongqing & Province_ Name = Chongqing 'observe in? After that, the web page transmits the keywords we query. Can it be easier for us to change the parameters each time?
city_name = input('Please enter the name of the city to query:')
url = 'http://weathernew.pae.baidu.com/weathernew/pc?query="{}"&srcid=4982&city_name="{}"&province_name="{}"'.format(city_name, city_name, city_name)Use the above code form to test, and the personal test is feasible!
At the same time, there is also a bug: what if the input content is not the city name, or the query cannot be found???
It's simple! All sorts of strange things are as like as two peas. We can tell if we want to find out what we want (even if we can't find the city, we will return the wrong content rather than empty): the data content can be found out in a strange way, but the web pages that are not accessible are exactly the same.
Then we enter a nonexistent address and return the error page content. It is clear that the returned text content is only "this city query has not been opened yet"
Then we will take this as a signal to extract the returned content. If there is content extracted, we will terminate the program and output the queried content (error message); If the content of the query is empty, continue to run the next operation
# Get web content
html_text = Get_tetx(url)
# Parsing web pages through BeautifulSoup
soup = BeautifulSoup(html_text, 'html.parser')
# Get main content
htmlBodyText = soup.body.prettify()
# logger.info("the obtained web page content is:")
# print(htmlBodyText)
# Process the content of the original web page
pattern = re.compile(r'\s|\n|<br>', re.S)
htmlBodyText = pattern.sub('', htmlBodyText)
# Judge whether the query city is reasonable
try:
text_data = re.findall(r'<p>(.*?)</p>', htmlBodyText)
if text_data != '':
logger.info(self.text_data[0])
os._exit(0) # Close the execution of the program
else:
return htmlBodyText
except:
return htmlBodyText
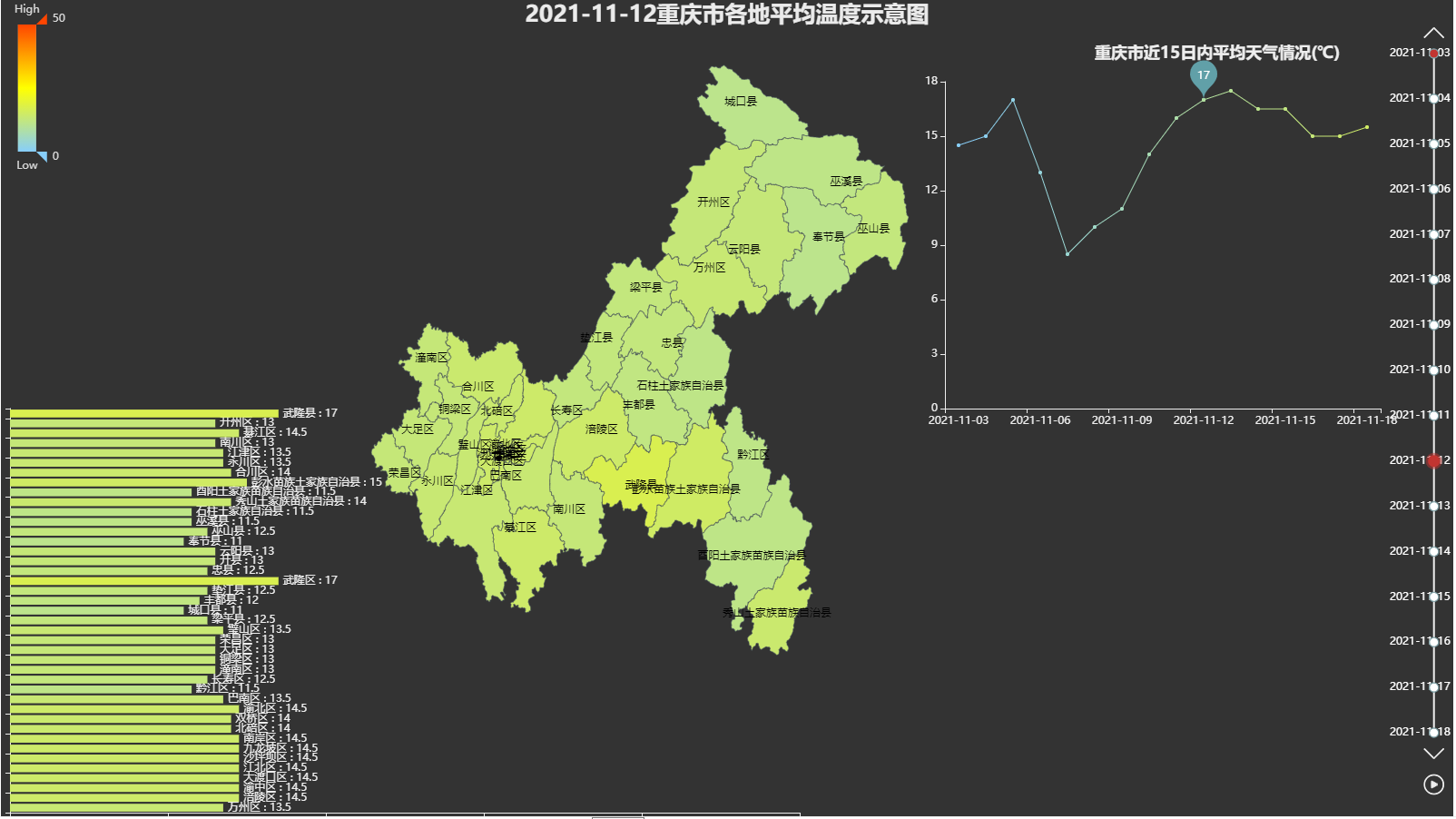
In this way, we can easily query the weather conditions around. The obtained data can also be drawn through pyechards, such as:
We have limited academic knowledge. We can only achieve this level for the time being. It is estimated that there are still undetected bug s. I hope you can make more corrections. I will study with an open mind!