There's nothing to say. Everyone here is beautiful
- List array
- Vector vector
- Stack stack
- Map mapping dictionary
- Set set
- Queue queue
- Deque bidirectional queue
Pay attention to the official account and exchange with each other. Search by WeChat: Sneak ahead.
- General method of general queue
| Operation method | Throw exception | Blocking thread | Return special value | Timeout exit |
|---|---|---|---|---|
| Insert element | add(e) | put(e) | offer(e) | offer(e, timeout, unit) |
| Removing Elements | remove() | take() | poll() | pull(timeout, unit) |
| inspect | element() | peek() | nothing | nothing |
1 List array
- Elements are saved in order according to the order of entry, and can be repeated
- List has two underlying implementations, one is array and the other is linked list, and the implementation of linked list inherits Collection. Differences between arrays and Collections:
- The array size is fixed and the collection is variable
- The elements of an array can be either a basic type or a reference type, while a collection can only be a reference type
ArrayList
- The bottom layer of ArrayList uses an array that can be dynamically expanded. The difference between ArrayList and ordinary array is that it has no fixed size limit and can add or delete elements
- It is characterized by fast reading speed, fast updating and slow addition and deletion; Memory is adjacent, and the time complexity read according to Index is O(1); Duplicate elements can be stored, but threads are not safe
- Capacity expansion mechanism of ArrayList
//ArrayList openJDK 13
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length) //I can't put it down
elementData = grow(); // Capacity expansion
elementData[s] = e;
size = s + 1;
}
private Object[] grow() {
return grow(size + 1);
}
private Object[] grow(int minCapacity) {
int oldCapacity = elementData.length;
if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
int newCapacity = ArraysSupport.newLength(oldCapacity,
minCapacity - oldCapacity, // minCapacity - oldCapacity == 1
oldCapacity >> 1 ); // oldCapacity == 1/2 oldCapacity
return elementData = Arrays.copyOf(elementData, newCapacity);
} else {
return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];
}
}
- If the current element cannot be placed, it will be expanded to 1.5 times and greater than or equal to 1
// ArraysSupport.newLength
public static int newLength(int oldLength, int minGrowth, int prefGrowth) {
//prefGrowth is 1 / 2 of oldLength and minGrowth is 1. So newLength = 1.5 oldLength
int newLength = Math.max(minGrowth, prefGrowth) + oldLength;
if (newLength - MAX_ARRAY_LENGTH <= 0) { // MAX_ARRAY_LENGTH = Integer.MAX_VALUE - 8
return newLength;
}
return hugeLength(oldLength, minGrowth);
}
LinkedList
- LinkedList nodes do not store real data, but reference objects that store data, and nodes are associated by reference
- LinkedList implements the Queue and Deque interfaces and can be used as a Queue; Search is slow, add and delete is fast, and duplicate elements can be stored, but the thread is not safe
- LRU implementation using LinkedList
public static class LRU<T> {
//Default cache size
private int CAPACITY = 0;
//Reference a two-way linked table
private LinkedList<T> list;
//Constructor
public LRU(int capacity) {
this.CAPACITY = capacity;
list = new LinkedList();
}
//Add an element
public synchronized void put(T object) {
if (list != null && list.contains(object)) {
list.remove(object);
}
removeLeastVisitElement();
list.addFirst(object);
}
//Remove the least recently accessed element
private void removeLeastVisitElement() {
int size = list.size();
//Note that this must be capability - 1, otherwise the size obtained is 1 larger than the original
if (size > (CAPACITY - 1)) {
Object object = list.removeLast();
}
}
//Gets the element below the nth index
public T get(int index) {
return list.get(index);
}
}
- API for LinkedList
public E getFirst() //Get the first element public E getLast() //Get the last element public E removeFirst() // Remove the first element and return public E removeLast() // Removes the last element and returns public void addFirst(E e) //Add head public void addLast(E e) //Add tail public void add(E e) //Add tail public boolean contains(Object o) //Include element o public E peek() //Gets the first element of the header public E element() // Get the first element of the header. If it does not exist, an error is reported public E poll() //Get the first element of the header and remove it public boolean offer(E e) // Call add public boolean offerFirst(E e) // Call addFirst public boolean offerLast(E e) // Call addLast public void push(E e) //Press an element into the head public E pop() //Pop up the first element and remove it. If it does not exist, an error is reported
- ArrayList and LinkedList usage scenarios
- Frequently access an element in the list, or add and delete elements at the end of the list. Use ArrayList
- Frequently add and delete elements at the beginning, middle and end of the list, using LinkedList
Iterator, fast fail and fail safe mechanisms
- Java Iterator (iterator) is not a collection. It is a method for accessing collections. It can be used to iterate over lists, sets and other collections. There are mainly three methods: hashNext(), next(), remove()
- Fail fast is an error mechanism for Java collections. When multiple threads modify the structure of the same set, using the iterator of the set will first detect whether there are concurrent modifications to the set, and then generate a concurrent modificationexception exception prompt
- Fail safe: ensure that the modification of any set structure is based on copy modify, that is, first copy a new set object, then modify the new set object, and finally replace the old set object with the new set object (the address of the old set object points to the new set object). The fail safe mechanism is adopted under the java.util.concurrent package.
- Disadvantage 1 - copy ing a collection will produce a large number of objects, resulting in a waste of memory space.
- Disadvantage 2 - the collection data obtained during the collection iteration cannot be guaranteed to be the latest content
CopyOnWriteArrayList
- Thread safety of CopyOnWriteArrayList: CopyOnWriteArrayList will lock when writing. In order to ensure write safety, a new array will be copied during write operation, and then the old array will be overwritten; Does not affect read performance
public class CopyOnWriteArrayList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
//Reentrant lock
final transient ReentrantLock lock = new ReentrantLock();
//Array, operated only through the get and set methods
private transient volatile Object[] array;
....
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();//Get the current array
int len = elements.length;//Get length
//Copy current array
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements); //Call the set method to set the new array to the current array
return true;
} finally {
lock.unlock();//Unlock
}
}
- Disadvantages of CopyOnWriteArrayList
- When CopyOnWrite is writing, the memory of two objects will be stationed in the memory at the same time, resulting in a waste of memory
- CopyOnWrite container can only guarantee the final consistency of data, but can not guarantee the real-time consistency of data. If you want to write data that can be read immediately, please do not use the CopyOnWrite container. There is no concept of blocking and waiting
- What is the difference between CopyOnWriteArrayList and Collections.synchronizedList
- CopyOnWriteArrayList has poor write performance, while multithreaded read performance is better
- The write performance of Collections.synchronizedList is much better than that of CopyOnWriteArrayList in the case of multi-threaded operation, and the read performance is not as good as that of CopyOnWriteArrayList because the synchronized keyword is used in the read operation
Thread safe List
- A: Use Vector; B: Use Collections.synchronized() to return a thread safe List; C: Using CopyOnWriteArrayList
List API example
boolean contains(Object o) // Include o boolean isEmpty(); // Is it empty int size(); //Collection element Iterator<E> iterator(); // Return iterator Object[] toArray(); // Convert to Object array <T> T[] toArray(T[] a); // Convert to concrete type array boolean add(E e); // Add tail boolean remove(Object o); // Remove o boolean containsAll(Collection<?> c); //Whether to register for the examination set c boolean addAll(Collection<? extends E> c);// Consolidation c boolean retainAll(Collection<?> c);//Keep elements that exist only in set c void clear(); // Clear collection elements void sort(Comparator<? super E> c) //Sort by Comparator E get(int index); // Get element by subscript E set(int index, E element); // Set the element of the index E remove(int index); // Remove the element of the index <E> List<E> of(E e1.....) // jdk 9 List<E> copyOf(Collection<? extends E> coll) // copy
2 Vector
Differences between ArrayList, Vector and LinkedList
- Vector is a thread safe replica of ArrayList
- Vector inherits and implements List features: the underlying data structure is array, fast query and thread safety
API example for Vector
boolean synchronized contains(Object o); boolean synchronized isEmpty(); boolean synchronized containsAll(Collection<?> c); boolean addAll(Collection<? extends E> c); public synchronized boolean add(E e) public synchronized E get(int index); public synchronized E set(int index, E element); public synchronized E firstElement() public synchronized void removeElementAt(int index) public synchronized E lastElement() public synchronized void setElementAt(E obj, int index) public synchronized E remove(int index) public void clear() Iterator<E> iterator();
3 Stack
- Stack is a subclass provided by Vector, which is used to simulate the data structure of "stack" (LIFO, last in, first out)
- Thread safe, null value allowed
API example of Stack
public E push(E item) //Push into the top of the stack public synchronized E pop() // Pop up the stack top element. If it does not exist, an error is reported public synchronized E peek() // Get the stack top element without removing it public boolean empty() // Is the stack empty public synchronized int search(Object o) // Search element
4 Map
- Map is used to save data with mapping relationship. There are two kinds of mapped data in map: key and value. They can make any reference type of data, but the key cannot be repeated. Therefore, the corresponding value can be retrieved through the specified key
- Please note that!!! Map does not inherit the Collection interface
TreeMap(1.8JDK)
- Inheriting AbstractMap, TreeMap is implemented based on red black tree, which can ensure that containsKey, get, put and remove operations can be completed within log(n) time complexity, with high efficiency. (the principle of red and black numbers will not be discussed here, and a special article will be written later)
- On the other hand, because TreeMap is implemented based on red black tree, the keys of TreeMap are orderly
HashMap
- HashMap inherits the AbstractMap class and implements Map, which is a hash table. Its stored content is key value mapping. HashMap implements the Map interface, stores data according to the HashCode value of the key, has fast access speed, allows the key of one record to be null at most, and does not support thread synchronization. HashMap is unordered, that is, the insertion order is not recorded
- How HashMap handles hash conflicts and several solutions to hash conflicts
- Open addressing
- If the currently calculated position has been stored during the hash of linear probe, it will be searched backward in sequence until the empty position is found or all positions are not empty
- The secondary probe uses an auxiliary hash function so that the subsequent probe position adds an offset to the previous probe position, which depends on the probe number i in the form of quadratic. The hash function form of secondary exploration is: h(k,i)=(h'(k,i)+c1*i + c2 * i^2) mod m
- The dual hash uses two auxiliary hash functions h1 and h2. The initial hash position is h1(k), and the subsequent hash position adds an offset h2(k)*i mod m
- Chain address method
- Chain address method - if there is a hash collision, create a linked list to store the same elements
- Open addressing method is easy to cause hash collision and slow query
- Open addressing
- The underlying implementation of HashMap is array + linked list + red black tree. The initial HashMap capacity of the null parameter is 16, and the default loading factor is 0.75. The value of 0.75 is because 0.5 is easy to waste space, and the value of 1 needs to fill each bucket. It is difficult to achieve the actual situation, resulting in a large number of hash collisions. Therefore, take the intermediate value
- The capacity of HashMap is generally the power of 2. You can directly use "bit and" to calculate the hash value, which is faster than modular calculation
Hashtable
- Inherited from Dictionary, it has been basically eliminated
- The operation of HashTable is almost the same as that of HashMap. The main difference is that HashTable adds synchronized locks to almost all methods in order to achieve multithreading safety, and the result of locking is that the efficiency of HashTable operation is very low
- HashMap allows one key to be null and multiple values to be null; But HashTable does not allow null keys or values
- Hash mapping: through unconventional design, the hash algorithm of HashMap designs the length of the underlying table as a power of 2, and uses bit sum operation instead of modular operation to reduce operation consumption; The hash algorithm of HashTable first makes the hash value less than the maximum integer value, and then performs scattering operation by taking modulus
LinkedHashMap
- The element access process of LinkedHashMap is basically similar to that of HashMap, but the implementation details are slightly different. Of course, this is determined by the characteristics of LinkedHashMap itself, because it additionally maintains a two-way linked list to maintain the iterative order. In addition, LinkedHashMap can well support LRU algorithm. The combination of HashMap and two-way linked list is LinkedHashMap
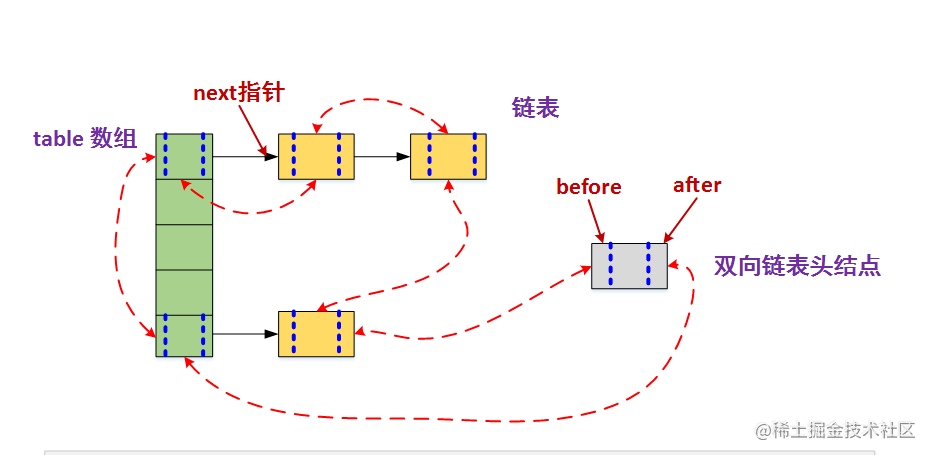
WeakHashMap
- WeakHashMap is also a hash table. Its stored content is also a key value mapping, and both keys and values can be null
- The key of WeakHashMap is "weak key". In the WeakHashMap, when a key is no longer strongly referenced, it will be automatically removed from the WeakHashMap by the JVM, and then its corresponding key value pair will also be removed from the WeakHashMap. JAVA reference type and ThreadLocal
ConcurrentHashMap(1.8JDK)
- ConcurrentHashMap is a multi thread safe version of HashMap. It uses fine-grained locks and cas to improve security and high concurrency in multi-threaded environment
- The underlying data structure is array + linked list / red black tree (an introduction will be written later)
ConcurrentSkipListMap learn about a wave
- Concurrent skiplistmap is a map based on jump linked list. It uses cas technology to achieve thread safety and high concurrency
- Advantages of ConcurrentSkipListMap over ConcurrentHashMap
- The key s of ConcurrentSkipListMap are ordered.
- ConcurrentSkipListMap supports higher concurrency. The access time of ConcurrentSkipListMap is log (N), which is almost independent of the number of threads. In other words, when the amount of data is certain, the more concurrent threads, the more its advantages can be reflected in the ConcurrentSkipListMap
Range of key values for NavigableMap and ConcurrentNavigableMap operations
- TreeMap implements NavigableMap. ConcurrentNavigableMap TreeMap for high concurrency thread safety
- NavigableMap provides a navigation method that returns the closest match for a given search target. Look directly at the API
K lowerKey(K key) // Find the first value smaller than the specified key K floorKey(K key) // Find the first key less than or equal to the specified key K ceilingKey(K key) // Find the first value greater than or equal to the specified key K higherKey(K key) // Find the first value greater than the specified key Map.Entry<K,V> firstEntry() // Get minimum value Map.Entry<K,V> lastEntry() // Get maximum Map.Entry<K,V> pollFirstEntry() // Delete the smallest element Map.Entry<K,V> pollLastEntry() // Delete the largest element NavigableMap<K,V> descendingMap() //Returns a Map in reverse order // NavigableMap with return value less than toKey NavigableMap<K,V> headMap(K toKey, boolean inclusive) // NavigableMap with return value greater than fromKey NavigableMap<K,V> tailMap(K fromKey, boolean inclusive) // The return value is less than the fromKey NavigableMap whose toKey is greater than NavigableMap<K,V> subMap(K fromKey, boolean fromInclusive, K toKey, boolean toInclusive)
5 Set
- Set features: elements are not placed in order, and elements cannot be repeated. If repeated elements are added, the first added object will be retained. Fast access speed
Several implementation subclasses of Set and their characteristics
- TreeSet: the underlying data structure is implemented by binary tree, and the elements are unique and ordered; Uniqueness also requires rewriting hashCode and equals() methods. The binary tree structure ensures the order of elements
- According to different construction methods, it is divided into natural sorting (parameterless construction) and comparator sorting (parameterless construction). Natural sorting requires that elements must implement the comparable interface and rewrite the compareTo() method inside
- HashSet: it is implemented by hash table. The data in HashSet is unordered and can be put into null, but only one null can be put into it. The values in both cannot be repeated, just like the unique constraint in the database
- HashSet is implemented based on HashMap algorithm, and its performance is usually better than TreeSet
- For the Set designed for quick search, we usually use HashSet. TreeSet is used only when sorting is required
- LinkedHashSet: the underlying data structure is realized by linked list and hash table. The linked list ensures that the order of elements is consistent with the storage order, and the hash table ensures the uniqueness of elements with high efficiency. But threads are not safe
ConcurrentSkipListSet
- Implementation based on ConcurrentSkipListMap
CopyOnWriteArraySet
- Implementation based on CopyOnWriteArrayList
BitSet
- BitSet is a bit operated object with values of only 0 or 1, i.e. false and true. A long array is maintained internally, and there is only one long initially. Therefore, the minimum size of BitSet is 64. As more and more elements are stored, the BitSet will expand dynamically, and finally N long will be stored internally
- For example, count the data that does not appear in the 4 billion data, sort the 4 billion different data, etc\
- There are now 10 million random numbers, ranging from 100 million to 100 million. Now it is required to write an algorithm to find the number between 100 million and 100 million that is not in the random number
void and(BitSet set) // The two bitsets do and operate, and the results are stored in the current BitSet void andNot(BitSet set) // Two bitsets and non operations void flip(int index) // Inverts a specified index boolean intersects(BitSet bitSet) // Is there an intersection int cardinality() //Returns the number of true/1 void clear() // Reset void clear(int startIndex, int endIndex) // startIndex~endIndex reset int nextSetBit(int startIndex) //Retrieves the index that appears first after startIndex as 1 int nextClearBit(int startIndex) //Retrieves the index of the first bit that appears as 0 after startIndex
6 Queue
- The concept of Queue queue is a special linear table, which only allows elements to enter the Queue from one end of the Queue and get out of the Queue from the other end (get elements), just as we usually Queue for settlement (be polite and don't jump in the Queue). The data structure of Queue is the same as that of List. It can be implemented based on array and linked List. The Queue is usually in offer at one end and out poll at the other end
PriorityQueue
- PriorityQueue is a queue sorted by priority, that is, vip can jump the queue. Priority queues require Java The Comparable and Comparator interfaces sort objects, and the elements in them are prioritized when sorting
- PriorityBlockingQueue is a thread safe PriorityQueue
BlockingQueue
- BlockingQueue solves the problem of how to "transmit" data efficiently and safely in multithreading. These efficient and thread safe queue classes bring great convenience for us to quickly build high-quality multithreaded programs. Task queues commonly used for threads
- DelayQueue
- DelayQueue is an implementation of BlockingQueue without boundary. Adding elements must implement the Delayed interface. When the producer thread calls methods such as put to add elements, it will trigger the compareTo method in the Delayed interface to sort
- The consumer thread views the elements at the head of the queue, paying attention to viewing rather than taking them out. Then the getDelay method of the element is invoked. If the value returned by this method is 0 or 0, the consumer thread takes the element from the queue and processes it. If the value returned by the getdelay method is greater than 0, the consumer thread blocks until the first element expires
Queue API
boolean add(E e); //Add to the end of the queue boolean offer(E e); // Join the end of the queue and return the result E remove(); //Remove header element E poll(); // Get the header element and remove it E element(); // Get the header element. If it does not exist, an error is reported E peek(); // Get the header element without removing it
7 Deque (bidirectional queue)
- Deque interface represents a "double ended queue". Double ended queues can add and delete elements from both ends at the same time. Therefore, deque implementation classes can be used as queues or stacks
- Subclasses of Deque: LinkedList, ArrayDeque, LinkedBlockingDeque
Deque's API
void addFirst(E e); //Add head void addLast(E e); //Add tail boolean offerFirst(E e); //Add the header and return the result boolean offerLast(E e); //Add the tail and return the result E removeFirst(); // Remove first element E removeLast(); // Remove last element E getFirst(); //Get the first element. If it does not exist, an error is reported E getLast(); //Get the last element. If it does not exist, an error will be reported E pollFirst(); //Get the first element and remove it E pollLast(); //Gets the last element and removes it E peekFirst(); //Get the first element E peekLast(); // Get the last element void push(E e); //Add head E pop(); //Pop up header element