Chapter 1 basic concepts of Impala
1.1 what is Impala
Cloudera provides interactive SQL query function with high performance and low latency for HDFS and HBase data.
Based on Hive, it uses memory computing, takes into account data warehouse, and has the advantages of real-time, batch processing, multi concurrency and so on.
It is the preferred PB level big data real-time query and analysis engine for CDH platform.
1.2 advantages and disadvantages of impala
1.2.1 advantages
1) Based on memory operation, there is no need to write intermediate results to disk, which saves a lot of I/O overhead.
2) Without converting to Mapreduce, it can directly access the data stored in HDFS and HBase for job scheduling, which is fast.
3) The I/O scheduling mechanism supporting Data locality is used to allocate data and computing on the same machine as much as possible, reducing network overhead.
4) Various file formats are supported, such as TEXTFILE, SEQUENCEFILE, RCFile and Parquet.
5) You can access hive's metastore to directly analyze hive data.
1.2.2 disadvantages
1) It relies heavily on memory and is entirely dependent on hive.
2) In practice, the partition is more than 10000, and the performance is seriously degraded.
3) Only text files can be read, not custom binaries.
4) Whenever a new record / file is added to the data directory in HDFS, the table needs to be refreshed.
1.3 Impala architecture
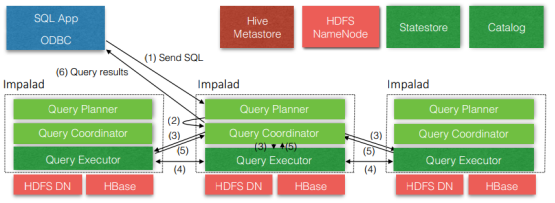
As can be seen from the above figure, Impala itself includes three modules: Impalad, statestore (storing Hive metadata) and catalog (pulling real data). In addition, it also relies on Hive Metastore and HDFS.
1)impalad:
Receiving the request from the client, executing the Query and returning it to the central coordination node;
The daemon on the child node is responsible for maintaining communication and reporting to the statestore.
2)Catalog:
Distribute the published metadata information to each impalad;
Receive all requests from statestore.
3)Statestore:
Collect resource information, health status of each impalad process distributed in the cluster, and synchronize node information;
Chapter 2 installation of Impala
2.1 relevant address of impala
1) Impala's official website
2) Impala document view
http://impala.apache.org/impala-docs.html
3) Download address
http://impala.apache.org/downloads.html
2.2 installation mode of impala
Cloudera Manager (CDH first)
Let's use Cloudera Manager to install Impala
1) Click Add Service on the home page
2) Select Impala service
1. Assign roles
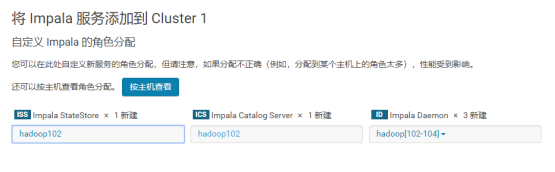
Note: it is best to deploy StateStore and CataLog Sever on the same node separately.
2. Configure Impala
3. Start Impala
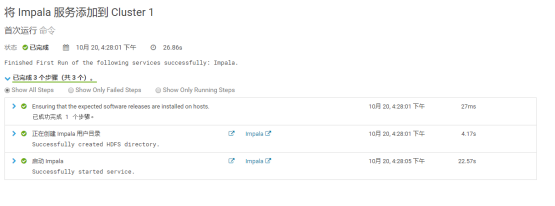
4. Installation succeeded
2.3 monitoring management of impala
You can access the monitoring management page of Impala through the following link:
1) View StateStore
http://hadoop102:25010/
2) View Catalog
http://hadoop102:25020/
2.4 initial experience of impala
1) Start Impala
[root@hadoop102 ~]# impala-shell
2) View database
[hadoop102:21000] > show databases;
3) Open default database
[hadoop102:21000] > use default;
4) Displays the tables in the database
[hadoop102:21000] > show tables;
5. Create a student table
[hadoop102:21000] > create table student(id int, name string)
> row format delimited
> fields terminated by '\t';
6. Import data into the table
hadoop102:21000] > load data inpath '/student.txt' into table student;
be careful:
1) Close (modify the configuration dfs.permissions of hdfs to false) or modify the permission of hdfs, otherwise impala has no write permission
[hdfs@hadoop102 ~]$ hadoop fs -chmod 777 /
2) Impala does not support importing local files into tables
7. Query
[hadoop102:21000] > select * from student;
8. Exit impala
[hadoop102:21000] > quit;
Chapter 3 operation commands of Impala
3.1 external shell of impala
| option | describe |
|---|---|
| centered text | Right aligned text right |
| -h, --help | display help information |
| -v or --version | display version information |
| -i hostname, --impalad=hostname | Specifies the host to which the impalad daemon is running. The default port is 21000. |
| -q query, --query=query | Pass a shell command from the command line. After executing this statement, the shell exits immediately. |
| -f query_file, --query_file= query_file | Pass an SQL query in a file. File contents must be separated by semicolons. |
| -o filename or --output_file filename | Save all query results to the specified file. It is usually used to save the query results when a single query is executed on the command line using the - q option. |
| -c | Continue execution when query execution fails |
| -d default_db or --database=default_db | Specifying the database to use after startup is the same as using the use statement to select the database after establishing a connection. If it is not specified, the default database is used |
| -r or --refresh_after_connect | Refresh Impala metadata after establishing connection |
| -p, --show_profiles | For each query executed in the shell, the query execution plan is displayed |
| -B(–delimited) | To format output |
| –output_delimiter=character | Specify separator |
| –print_header | Print column names |
1) Connect to the impala host of the specified Hadoop 103
[root@hadoop102 datas]# impala-shell -i hadoop103
2) Use - q to query the data in the table and write the data to the file
[hdfs@hadoop103 ~]$ impala-shell -q 'select * from student' -o output.txt
3) Continue execution when query execution fails
[hdfs@hadoop103 ~]$ vim impala.sql select * from student; select * from stu; select * from student; [hdfs@hadoop103 ~]$ impala-shell -f impala.sql (add-c Failure will continue) [hdfs@hadoop103 ~]$ impala-shell -c -f impala.sql
4) After creating the table in hive, use - r to brush the new metadata
hive> create table stu(id int, name string); [hadoop103:21000] > show tables; Query: show tables +---------+ | name | +---------+ | student | +---------+ [hdfs@hadoop103 ~]$ impala-shell -r [hadoop103:21000] > show tables; Query: show tables +---------+ | name | +---------+ | stu | | student | +---------+
5) Display query execution plan
[hdfs@hadoop103 ~]$ impala-shell -p [hadoop103:21000] > select * from student;
6) To format output
[root@hadoop103 ~]# impala-shell -q 'select * from student' -B --output_delimiter="\t" -o output.txt [root@hadoop103 ~]# cat output.txt 1001 tignitgn 1002 yuanyuan 1003 haohao 1004 yunyun
3.2 internal shell of impala
| option | describe |
|---|---|
| Help | display help information | |
| explain | Show execution plan |
| profile | (execute after the query is completed) query the underlying information of the latest query |
| shell | Execute shell command without exiting impala shell |
| version | Display version information (same as impala shell - V) |
| connect | Connect impalad host, default port 21000 (same as impala shell - I) |
| refresh | Incremental refresh metabase |
| invalidate metadata | Full refresh metabase (same as impala shell - R) |
| history | Historical command |
1) View execution plan
explain select * from student;
2) Query the underlying information of the last query
[hadoop103:21000] > select count(*) from student; [hadoop103:21000] > profile;
3) View hdfs and linux file systems
[hadoop103:21000] > shell hadoop fs -ls /; [hadoop103:21000] > shell ls -al ./;
4) Refreshes the metadata of the specified table
hive> load data local inpath '/opt/module/datas/student.txt' into table student; [hadoop103:21000] > select * from student; [hadoop103:21000] > refresh student; [hadoop103:21000] > select * from student;
5) View history commands
[hadoop103:21000] > history;
Chapter 4 data types of Impala
| Hive data type | Impala data type | length |
|---|---|---|
| TINYINT | TINYINT | 1byte signed integer |
| SMALINT | SMALINT | 2byte signed integer |
| INT | INT | 4byte signed integer |
| BIGINT | BIGINT | 8byte signed integer |
| BOOLEAN | BOOLEAN | Boolean type, true or false |
| FLOAT | FLOAT | Single-precision floating-point |
| DOUBLE | DOUBLE | Double precision floating point number |
| STRING | STRING | Character series. Character sets can be specified. Single or double quotation marks can be used. |
| TIMESTAMP | TIMESTAMP | Time type |
| BINARY | I won't support it | Byte array |
Note: Although Impala supports array, map and struct complex data types, it does not fully support them. The general processing method is to convert complex types into basic types and create tables through hive.
Chapter 5 DDL data definition
5.1 creating database
CREATE DATABASE [IF NOT EXISTS] database_name [COMMENT database_comment] [LOCATION hdfs_path];
Note: Impala does not support with dbproperty... Syntax
[hadoop103:21000] > create database db_hive
> WITH DBPROPERTIES('name' = 'ttt');
Query: create database db_hive
WITH DBPROPERTIES('name' = 'ttt')
ERROR: AnalysisException: Syntax error in line 2:
WITH DBPROPERTIES('name' = 'ttt')
^
Encountered: WITH
Expected: COMMENT, LOCATION
5.2 query database
5.2.1 display database
[hadoop103:21000] > show databases; [hadoop103:21000] > show databases like 'hive*'; Query: show databases like 'hive*' +---------+---------+ | name | comment | +---------+---------+ | hive_db | | +---------+---------+ [hadoop103:21000] > desc database hive_db; Query: describe database hive_db +---------+----------+---------+ | name | location | comment | +---------+----------+---------+ | hive_db | | | +---------+----------+---------+
5.2.2 delete database
[hadoop103:21000] > drop database hive_db; [hadoop103:21000] > drop database hive_db cascade; Note: Impala I won't support it alter database Syntax, when the database is USE Statement cannot be deleted when it is selected======
5.3 creating tables
5.3.1 management table
[hadoop103:21000] > create table if not exists student2(
> id int, name string
> )
> row format delimited fields terminated by '\t'
> stored as textfile
> location '/user/hive/warehouse/student2';
[hadoop103:21000] > desc formatted student2;
5.3.2 external table
[hadoop103:21000] > create external table stu_external(
> id int,
> name string)
> row format delimited fields terminated by '\t' ;
5.4 zoning table
5.4.1 create partition table
[hadoop103:21000] > create table stu_par(id int, name string)
> partitioned by (month string)
> row format delimited
> fields terminated by '\t';
5.4.2 importing data into the table
[hadoop103:21000] > alter table stu_par add partition (month='201810');
[hadoop103:21000] > load data inpath '/student.txt' into table stu_par partition(month='201810');
[hadoop103:21000] > insert into table stu_par partition (month = '201811')
> select * from student;
be careful:
If the partition does not, load data Partitions cannot be created automatically when importing data.
5.4.3 query data in partition table
[hadoop103:21000] > select * from stu_par where month = '201811';
5.4.4 add zoning
1,Add a single partition [hadoop103:21000] > alter table stu_par add partition (month='201812'); 2,Add multiple partitions [hadoop103:21000] > alter table stu_par add partition (month='201812') partition (month='201813');
5.4.5 delete partition
1,Delete a single partition [hadoop103:21000] > alter table stu_par drop if exists partition (month='201812'); 2,Delete multiple partitions [hadoop103:21000] > alter table stu_par drop if exists partition (month='201812'),partition (month='201813');
5.4.5 viewing partitions
[hadoop103:21000] > show partitions stu_par;
5.4.6 adding table notes
[hadoop103:21000] >alter table stu_par set TBLPROPERTIES ('comment' = 'Note Content ')
5.4.7 modify field notes
[hadoop103:21000] >ALTER TABLE Table name CHANGE Column name to change column name after change type after change COMMENT 'notes'
5.4.8 modify table name
[hadoop103:21000] >ALTER TABLE [old_db_name.]old_table_name RENAME TO [new_db_name.]new_table_name
5.4.9 adding columns
[hadoop103:21000] >ALTER TABLE name ADD COLUMNS (col_spec[, col_spec ...])
5.4.10 delete columns
[hadoop103:21000] > ALTER TABLE name DROP [COLUMN] column_name
5.4.11 change the name and type of the column
[hadoop103:21000] > ALTER TABLE name CHANGE column_name new_name new_type
Chapter 6 DML data operation
6.1 data import (basically similar to hive)
Note: impala does not support load data local inpath
6.2 data export
1) impala does not support insert overwrite... Syntax to export data
2) Impala data export generally uses impala -o
[root@hadoop103 ~]# impala-shell -q 'select * from student' -B --output_delimiter="\t" -o output.txt [root@hadoop103 ~]# cat output.txt 1001 tignitgn 1002 yuanyuan 1003 haohao 1004 yunyun Impala I won't support it export and import command
Chapter 7 inquiry
The basic syntax is roughly the same as hive's query statement
Impala does not support CLUSTER BY, DISTRIBUTE BY, SORT BY
Bucket table is not supported in Impala
Impala does not support COLLECT_SET(col) and expand (col) functions
Impala supports windowing functions
[hadoop103:21000] > select name,orderdate,cost,sum(cost) over(partition by month(orderdate)) from business;
Chapter 8 functions
8.1 user defined functions
1) Create a Maven project Hive
2) Import dependency
<dependencies> <!-- https://mvnrepository.com/artifact/org.apache.hive/hive-exec --> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>1.2.1</version> </dependency> </dependencies>
3) Create a class
package com.atguigu.hive;
import org.apache.hadoop.hive.ql.exec.UDF;
public class Lower extends UDF {
public String evaluate (final String s) {
if (s == null) {
return null;
}
return s.toLowerCase();
}
}
4) Print a jar package and upload it to the server / opt/module/jars/udf.jar
5.) upload the jar package to the specified directory of hdfs
hadoop fs -put hive_udf-0.0.1-SNAPSHOT.jar /
6) Create function
[hadoop103:21000] > create function mylower(string) returns string location '/hive_udf-0.0.1-SNAPSHOT.jar' symbol='com.atguigu.hive_udf.Hive_UDF';
7) Using custom functions
[hadoop103:21000] > select ename, mylower(ename) from emp;
8) View customized functions through show functions
[hadoop103:21000] > show functions; Query: show functions +-------------+-----------------+-------------+---------------+ | return type | signature | binary type | is persistent | +-------------+-----------------+-------------+---------------+ | STRING | mylower(STRING) | JAVA | false | +-------------+-----------------+-------------+---------------+
Chapter 9 storage and compression
| file format | Compression coding | Can Impala be created directly | Can I insert it directly |
|---|---|---|---|
| Parquet | Snappy (default), GZIP; | Yes | Support: CREATE TABLE, INSERT, query |
| Text | LZO,gzip,bzip2,snappy | Yes. Do not specify the CREATE TABLE statement of the STORED AS clause. The default file format is uncompressed text | Support: CREATE TABLE, INSERT, query. If you use LZO compression, you must create tables and load data in Hive |
| RCFile | Snappy, GZIP, deflate, BZIP2 | Yes. | Only query is supported and data is loaded in Hive |
| SequenceFile | Snappy, GZIP, deflate, BZIP2 | Yes. | Only query is supported and data is loaded in Hive |
Note: impala does not support ORC format
1) Create a table in parquet format and insert data for query
[hadoop104:21000] > create table student2(id int, name string) row format delimited fields terminated by '\t' stored as PARQUET; [hadoop104:21000] > insert into table student2 values(1001,'zhangsan'); [hadoop104:21000] > select * from student2;
2) Creating a table in sequenceFile format and inserting data will cause an error
[hadoop104:21000] > insert into table student3 values(1001,'zhangsan'); Query: insert into table student3 values(1001,'zhangsan') Query submitted at: 2018-10-25 20:59:31 (Coordinator: http://hadoop104:25000) Query progress can be monitored at: http://hadoop104:25000/query_plan?query_id=da4c59eb23481bdc:26f012ca00000000 WARNINGS: Writing to table format SEQUENCE_FILE is not supported. Use query option ALLOW_UNSUPPORTED_FORMATS to override.
Chapter 10 optimization
1. Try to deploy StateStore and Catalog to the same node to ensure their normal traffic.
2. The execution efficiency of Impala is improved by limiting the memory of Impala Daemon (256M by default) and the number of StateStore worker threads.
3, SQL optimization, call the execution plan before using.
4. Select the appropriate file format for storage to improve the query efficiency.
5. Avoid generating many small files (if there are small files generated by other programs, you can use the intermediate table to store the small file data in the intermediate table, and then insert the data of the intermediate table into the final table through insert... select...)
6. Use appropriate partition technology and calculate according to partition granularity
7. Use compute stats to collect table information. When a content table or partition changes significantly, recalculate the relevant statistical data table or partition. Because the difference in the number of rows and different values may cause impala to select different join orders, the queries used in the table.
[hadoop104:21000] > compute stats student;
Query: compute stats student
±----------------------------------------+
| summary |
±----------------------------------------+
| Updated 1 partition(s) and 2 column(s). |
±----------------------------------------+
8. Network io Optimization:
a.Do conditional filtering as much as possible b.use limit Words and sentences
c. Avoid beautifying output when exporting files
d. Minimize the refresh of full metadata