Scrapy crawler framework
To the most professional web crawler framework learning part, we should play a better spirit to meet new challenges.
1. Installation
pip install scrapy
After installation, enter the following command to test the effect:
scrapy -h
The correct response indicates that the installation has been successful.
2. Brief description of scripy framework
Scratch is a crawler framework. It is a collection of software structure and functional components that can help users realize professional web crawlers.
How to understand? In fact, it can be considered that this framework has several small components that work together to form a data flow and form such a large collection of components. The following figure shows the components of the framework:
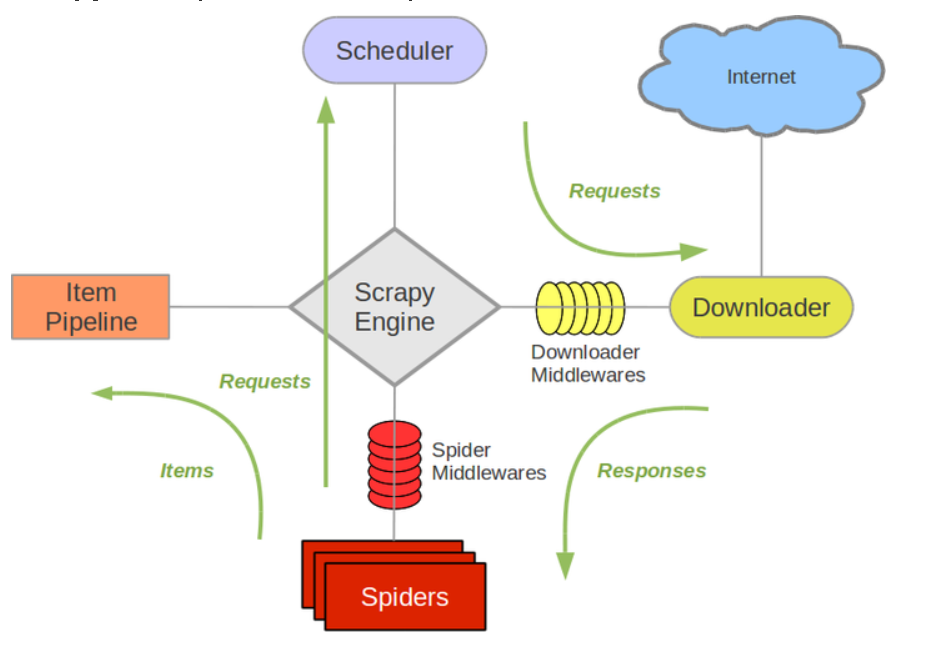
Here, to realize the crawler function, we should start with Spider and Item Pipeline. Because Engine and Downloader are existing function implementations, so is Scheduler.
At this time, the essence of crawler is to improve the configuration of crawler framework.
3. Requests and scrape
Similarities:
- Both can request and crawl web pages
- Good usability and simple documentation
- There are no functions to handle js, submit forms and deal with verification codes
difference:
| request | scrapy |
|---|---|
| Page level crawler | Web crawler |
| Function library | frame |
| Insufficient consideration of concurrency and low efficiency | Good concurrency |
| The focus is on page download | The focus is on reptile structure |
| Flexible customization | General customization flexibility |
| Easy to use | It's a little difficult to get started |
4. Scripy common commands
The common command formats of scripy are as follows:
scrapy <command> [option] [args]
Among them, command is mainly a common command, including the following:
| command | explain | format |
|---|---|---|
| startproject | Create a new crawler | scrapy startproject [dir] |
| genspider | Create a crawler | scrapy genspider [option] |
| settings | Get crawler configuration information | scrapy settings [options] |
| crawl | Run a crawler | scrapy crawl |
| list | List all crawlers in the project | scrapy list |
| shell | Start url debug command line | scrapy shell [url] |
A project is a large framework in which many crawlers can be placed in the project, which is equivalent to a downloader within the project.
Moreover, this automation is suitable for script operation and focuses on function.
5. Examples of Scrapy
1. Build a crawler project:
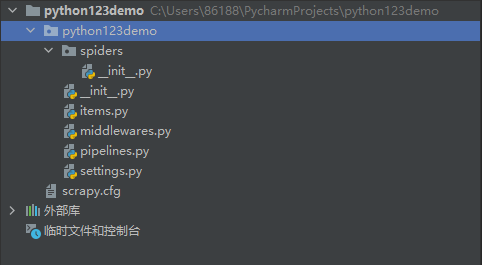
The file directory is shown in the figure above.
The project name is python123demo, and the next layer is the deployment configuration file config and user-defined Python code, which is usually consistent with the project name.
On the next level, we also have these python files, which correspond to several of the five functional components.
2. Create a crawler

The generated content is as follows:
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
allowed_domains = ['python123.io']
start_urls = ['http://python123.io/']
def parse(self, response):
pass
Of course, we can also manually generate the part that completes the creation of the crawler.
3. Configure crawler
For the crawler created above, we try to save an html page into an html file.
class DemoSpider(scrapy.Spider):
name = 'demo'
#allowed_domains = ['python123.io']
start_urls = ['http://python123.io/ws/demo.html']
#Returns the crawler and parses it
def parse(self, response):
fname = response.url.split('/')[-1]
with open(fname , 'wb') as f:
f.write(response.body)
self.log('Save file %s.' % name)
Second, run:
scrapy crawl demo
The results are as follows:
<html><head><title>This is a python demo page</title></head> <body> <p class="title"><b>The demo python introduces several python courses.</b></p> <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p> </body></html>
6,yield
Is a generator, a function that continuously generates values, and the function containing the yield statement is a generator.
Each time the generator generates a value, the function is frozen and awakened to produce a new value.
def gen(n): for i in range(n): yield i**2
The above content function is to generate the square value of a number less than n. Because the generator returns a return value and is inside a loop.
Advantages of generator:
1. Better storage space
2. More flexible response
3. Flexible use
summary
The above is the introduction of the basic concepts of scripy. The practice part still needs to be completed by your own experience and accumulation. Thank you for reading.