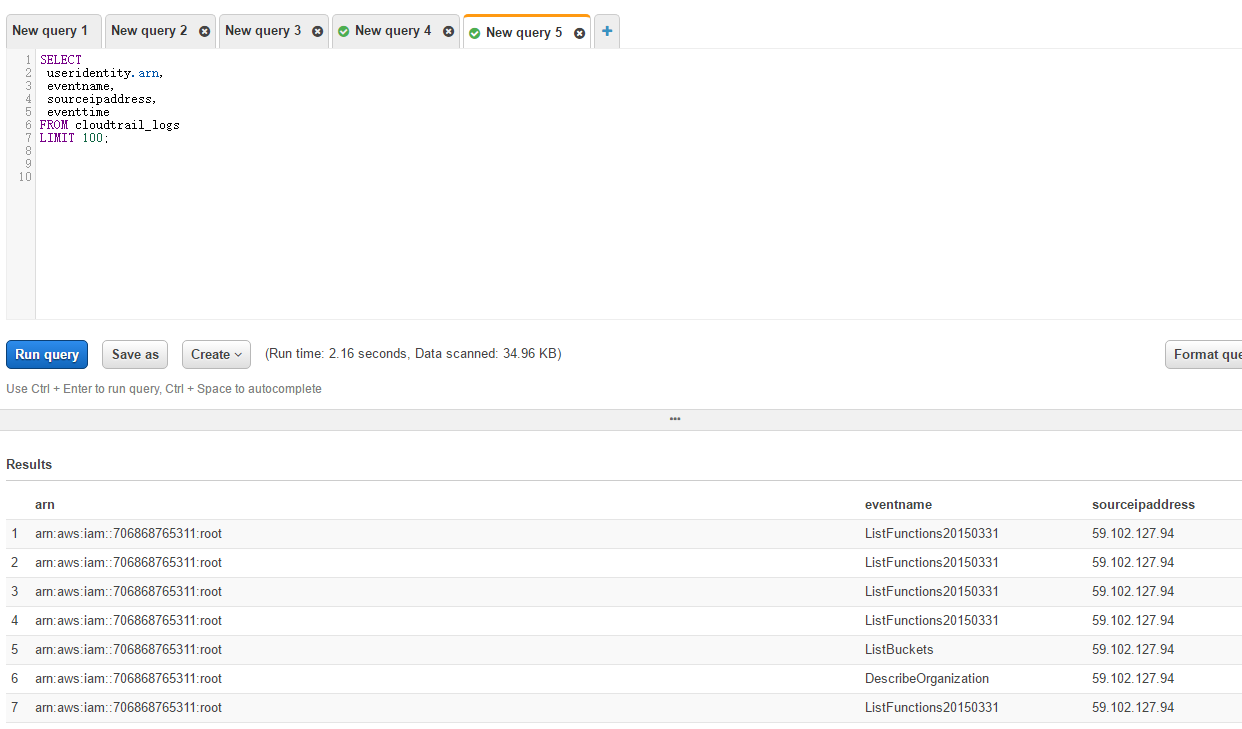
In AWS, Athena can be used to analyze the logs saved in S3. He can convert the logs into the format of database tables, so that they can be queried through sql statements. This function is similar to using logparser to analyze Exchange or IIS logs on a windows Server.
Let's do a demonstration, record the management log through Cloudtrail, and then query the log content through Athena.
First, choose cloudtrail, which is a logging service. The difference between cloudtrail and cloudwatch is that this service focuses more on audit. Its content is about when, what account, and what IP operations are performed.
Click Create Trail
Take a name and create a new S3 bucket to save the log
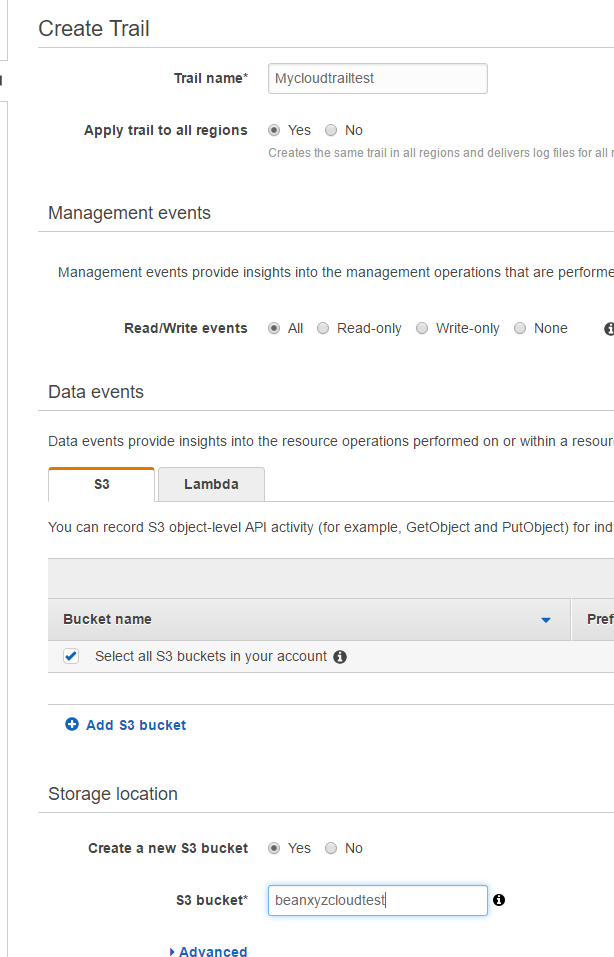
After creation, you can see that he is automatically recording the latest log
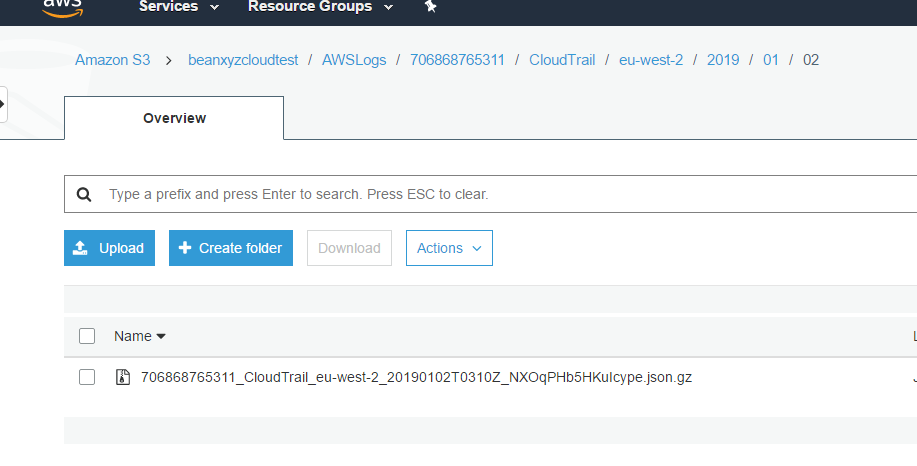
Then choose Athena
Skip the wizard and go directly to the editor of the querier. Here is the place to edit the SQL statement. Here I create a database directly
Next, create a table to obtain data from the specified S3 Bucket.
We can create it through the wizard, but it's cumbersome
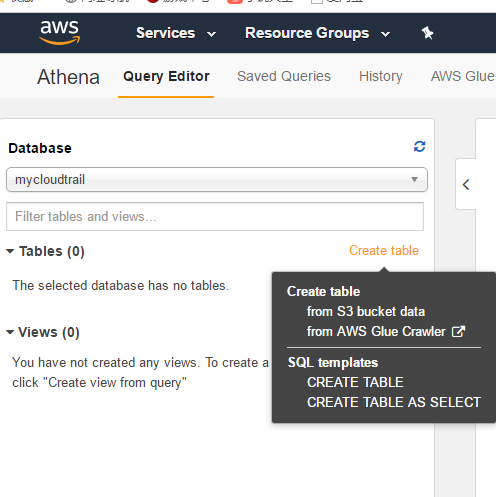
It's easier to create by script. Note the address of S3 bucket in the last line
CREATE EXTERNAL TABLE cloudtrail_logs (
eventversion STRING,
useridentity STRUCT<
type:STRING,
principalid:STRING,
arn:STRING,
accountid:STRING,
invokedby:STRING,
accesskeyid:STRING,
userName:STRING,
sessioncontext:STRUCT<
attributes:STRUCT<
mfaauthenticated:STRING,
creationdate:STRING>,
sessionissuer:STRUCT<
type:STRING,
principalId:STRING,
arn:STRING,
accountId:STRING,
userName:STRING>>>,
eventtime STRING,
eventsource STRING,
eventname STRING,
awsregion STRING,
sourceipaddress STRING,
useragent STRING,
errorcode STRING,
errormessage STRING,
requestparameters STRING,
responseelements STRING,
additionaleventdata STRING,
requestid STRING,
eventid STRING,
resources ARRAY<STRUCT<
ARN:STRING,
accountId:STRING,
type:STRING>>,
eventtype STRING,
apiversion STRING,
readonly STRING,
recipientaccountid STRING,
serviceeventdetails STRING,
sharedeventid STRING,
vpcendpointid STRING
)
ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde'
STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://mycloudtrailbucket-faye/AWSLogs/757250003982/';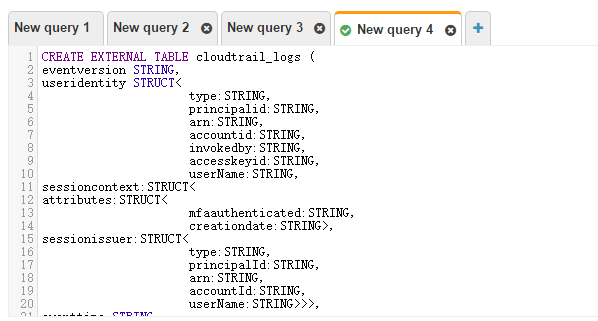
How to create a table successfully
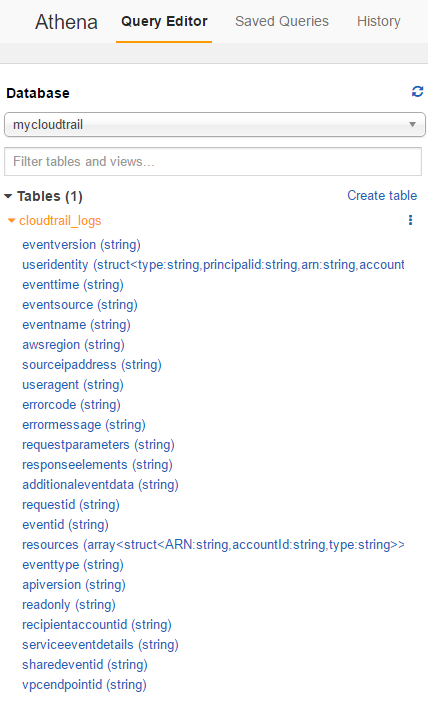
We can make a simple query as follows.