GAWK: Report Generator, Formatted Text Output
awk [options] 'program' var=value file...
awk [options] -f programfile var=value file...
awk [options] 'BEGIN{ action;... } pattern{ action;... } END{ action;... }' file ...
The awk program component:
BEGIN statement block, general statement block that can use pattern matching, END statement block
Options:
- F: Specifies the field splitter used for input;
- v var=value: custom variable
- f: Specify awk script to read program from script
Basic format:
awk [options] 'program' file...
program: pattern{action statements;...} is usually in single or double quotation marks.
Patterns and action s:
The pattern section determines when action statements are triggered and when events occur
BEGIN: Actions to be performed before pattern matching
END: Actions to be performed after pattern matching is over
Action states process data and specify it in {};
print $0, $!... $(NF-1).... $NF (last column)
Separator, field, record:
When awk is executed, a delimiter-separated field (field) is marked $1, ...$n is called a domain identifier. $0 is for all domains.
Each line of a file is called a record.
If action is omitted, print $0 will be executed by default.
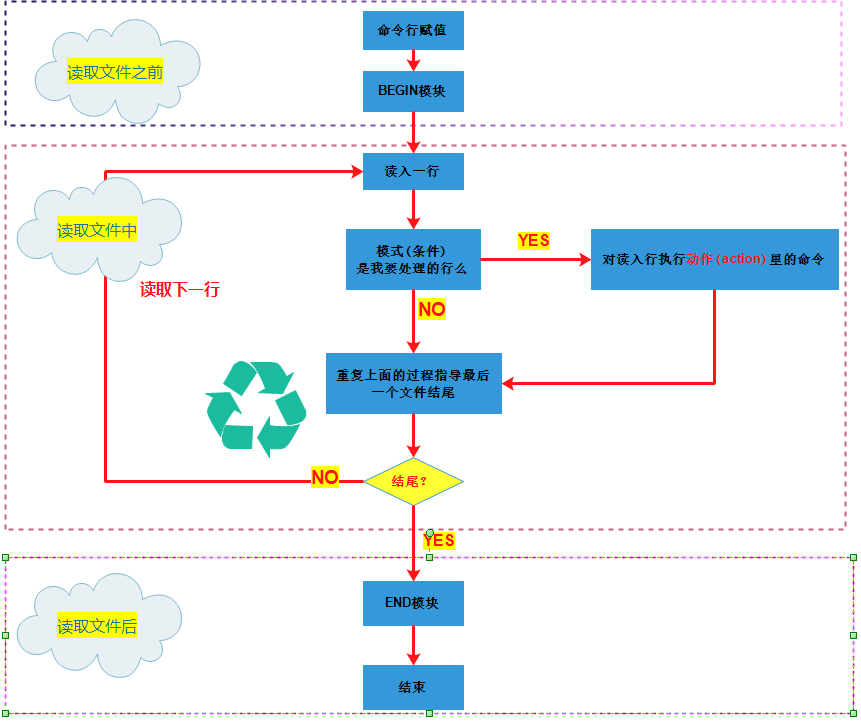
How awk works:
1) Execute the statements in the BEGIN{action;...} statement block;
2) Read a line from a file or standard input (stdin) and execute the pattern{action;...} block, which scans the file line by line and repeats the process from the first line to the last line until all the files have been read.
3) When read to the end of the input stream, execute the END{action;...} block
BEGIN Statement Block: Executed before awk starts reading rows from the input stream. This is an optional Statement Block. Statements such as variable initialization, the header of the printed output table, etc. can usually be written in the BEGIN Statement Block.
END Statement Block: After awk reads all rows from the input stream, it is executed, such as printing the analysis results of all rows. This information summary is completed in the END Statement Block. It is also an optional Statement Block.
Common commands in pattern blocks are the most important and optional part. If no pattern block is provided, default {print} is executed, that is, every read line is printed, and every read line by awk executes the block.
Print format: print item1,item2,...
Comma as delimiter;
2) The output item can be a string or an expression of the field, variable or awk of the current record.
3) If item is omitted, it is equivalent to print $0.
awk '{print "hello,awk"}' awk –F: '{print}' /etc/passwd # - F specifies that the partitioner is a colon awk –F: '{print "wang"}' /etc/passwd
awk –F: '{print $1}' /etc/passwd awk –F: '{print $0}' /etc/passwd awk –F: '{print $1"\t"$3}' /etc/passwd tail –3 /etc/fstab |awk '{print $2,$4}'
Variables:
FS: Input field separator, default blank character;
awk -v FS=':' '{print $1,FS,$3}' file
OFS: Output field separator, default to blank characters; specify what the separator is when output, generally can be replaced by separator symbols, similar to the following ORS role
awk -v FS=':' -v OFS=':' '{print $1,$2,$3}' file
[root@mysql-141 ~]# awk -v FS=':' -v OFS='#' '{print $1,$2,$3}' /etc/passwd
root#x#0
bin#x#1
daemon#x#2
adm#x#3
RS: Enter the record delimiter, specify the newline character at the time of input, the original newline character is still valid;
awk -v RS=' ' '{print}' file
ORS: Output record delimiter, with specified symbols instead of newline characters;
awk -v RS=' ' -v ORS='$$$' '{print}' file
NF: Number of fields
awk -F: '{print NF}' file awk -F: '{print $(NF-1)}' file
# Display the first column, the third column, the penultimate column and the last column of the file[root@mysql-141 ~]# awk -F : '{print $1,$2,$(NF-1),$NF}' /etc/passwd
root x /root /bin/bash
bin x /bin /sbin/nologin
daemon x /sbin /sbin/nologin
adm x /var/adm /sbin/nologin
NR: Line Number
awk -F: '{print NR,$1}' file # Similar to FNR awk END'{print NR}' file
[root@mysql-141 ~]# awk END'{print NR}' /etc/passwd #After reading the contents of the file, count the number of rows
26awk 'NR==2,NR==6{print NR,$0}}' file #Display 2-6 lines of file
FNR: Line numbers of each file are counted separately.
awk -F: '{print FNR,$1}' file1 file2...[root@mysql-141 ~]# awk -F: '{print FNR,$1}' /etc/passwd
1 root
2 bin
3 daemon
4 adm
5 lp
6 sync
7 shutdown
8 halt
FILENAME: Current file name; how many lines of file content will awk output
awk '{print FILENAME}' FILE1 FILE2...[root@mysql-141 ~]# awk '{print FILENAME}' /etc/passwd |wc -l
26
[root@mysql-141 ~]# wc -l /etc/passwd
26 /etc/passwd
ARGV: Array that holds the parameters given on the command line.
awk 'BEGIN {print ARGV[0]}' /etc/fstab /etc/inittab awk 'BEGIN {print ARGV[1]}' /etc/fstab /etc/inittab
[root@mysql-141 ~]# awk 'BEGIN {print ARGV[1]}' /etc/fstab /etc/inittab # Amount to shell Inside $1 $2 $3 Concept
/etc/fstab
[root@mysql-141 ~]# awk 'BEGIN {print ARGV[2]}' /etc/fstab /etc/inittab
/etc/inittab
[root@mysql-141 ~]# awk 'BEGIN {print ARGV[0]}' /etc/fstab /etc/inittab
awk
[root@mysql-141 ~]# awk 'BEGIN {print ARGV[3]}' /etc/fstab /etc/inittab
Arithmetic operators:
x+y x-y x*y x/y x^y x%y
- x: Convert to negative number;
+ x: Converts to a value. Variables are automatically forced to convert strings into integers through + join operations. Non-numerals are converted to 0. The first non-numeric character is found and automatically ignored later.
String operators: unsigned operators, string connections
Assignment operator:
= += -= *= /= %= ^= ++ --
The comparison operator:
== != > >= < <=
Pattern matcher:
~ Whether the content on the left is matched by the pattern on the right
Whether it does not match;
[root@mysql-141 ~]# awk -F: '$0 ~ /root/{print $1}' /etc/passwd # Print the first column by matching the rows containing root with: as the delimiterroot
operator[root@mysql-141 ~]# awk '$0 ~ "^root"' /etc/passwd # Match all content, starting with the root line at the beginning of the term
root:x:0:0:root:/root:/bin/bash[root@mysql-141 ~]# awk -F: '$3==0' /etc/passwd # Match lines with colons as delimiters and columns with 0 in the third column
root:x:0:0:root:/root:/bin/bash
cat >>/tmp/reg.txt<<EOF Zhang Dandan 41117397 :250:100:175 Zhang Xiaoyu 390320151 :155:90:201 Meng Feixue 80042789 :250:60:50 Wu Waiwai 70271111 :250:80:75 Liu Bingbing 41117483 :250:100:175 Wang Xiaoai 3515064655 :50:95:135 Zi Gege 1986787350 :250:168:200 Li Youjiu 918391635 :175:75:300 Lao Nanhai 918391635 :250:100:175 EOF

Operator:
With&&
Or||
No!
Example:[root@mysql-141 ~]# awk -F : '$3>=0 && $3<=1000 {print $1}' /etc/passwd
root
bin
daemon
adm
lp[root@mysql-141 ~]# awk -F : '$3==0 || $3>=1000 {print $1}' /etc/passwd
root
[root@mysql-141 ~]# awk -F : '!($3==0) {print $1}' /etc/passwd
bin
daemon
adm
lp[root@mysql-141 ~]# awk -F : '!($3>=500) {print $3}' /etc/passwd
0
1
2
3
4
5
6
awk PATTERN:
If not specified: empty mode, match each row;
(2), / regular expression /: Only rows that can be matched by a pattern need to be enclosed in //
awk '/^UUID/{print $1}' /etc/passwd awk '!/^UUID/{print $1}' /etc/passwd
3) relational expression: relational expression, the result is not "true" will be processed;
True: The result is a non-zero value, non-empty string;
False: The result is an empty string or a zero value;
awk -F : 'i=1;j=1{print i,j}' /etc/passwd awk '!0' /etc/passwd ; awk '!1' /etc/passwd awk –F : '$3>=1000{print $1,$3}' /etc/passwd awk -F : '$3<1000{print $1,$3}' /etc/passwd[root@mysql-141 ~]# awk -F : '$NF=="/bin/bash"{print $1,$NF}' /etc/passwd
root /bin/bash
lipeng /bin/bash[root@mysql-141 ~]# awk -F : '$NF ~ /nologin$/{print $1,$NF}' /etc/passwd
bin /sbin/nologin
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin
mail /sbin/nologin
uucp /sbin/nologin
Lineranges: line range:
startline,endine:/pat1/,/pat2/, does not support direct digital formatting:
[root@mysql-141 ~]# awk -F: '/^root\>/,/^nobody\>/{print $1}' /etc/passwd root bin daemon adm lp nobody [root@mysql-141 ~]# awk -F: '(NR>=10&&NR<=20){print NR,$1}' /etc/passwd 10 uucp 11 operator 12 games 13 gopher 14 ftp
awk array concept:
Preparatory knowledge: Understanding two awk arithmetic methods
1) Accumulative operation 1+1+1
I = I + 1 I initial state is 0
i++
eg: Number of empty lines in the statistics/etc/services file
First mileage: Find empty lines in files
awk '/^$/' /etc/services
Second mileage: counting the number of empty lines
awk '/^$/{i=i+1;print i}' /etc/services
PS: All string information in awk will be recognized as variable name information, calling variables is not required to add a $symbol.
To display the specified string information in awk, double quotation marks are added outside the string.
[root@oldgirl ~]# awk '/^$/{i=i+1;print i}' /etc/services 1 # i=i+1 i=0 i=0+1 --> i=1 2 # i=i+1 i=1 i=1+1 --> i=2 3 # i=2 i=2+1 --> i=3 4 5 6 7 8 9 10 11 12 13 14 15 16
[root@oldgirl ~]# awk '/^$/{i=i+1}END{print i}' /etc/services # After loading the file content, make statistics 16
2) Sum operation 10+20+5
The initial state of I = I + $n I is 0 $n, which column of numerical information is selected
[root@oldgirl ~]# seq 10|awk '{i=i+$0;print i}' 1 i=i+$0 i=0 $0=1 i=0+1 -- 1 1 2 i=i+$0 i=1 $0=2 i=1+2 -- 3 3 3 i=i+$0 i=3 $0=3 i=3+3 -- 6 6 4 10 5 15 6 21 7 28 8 36 9 45 10 55[root@mysql-141 ~]# seq 10|awk '{i=i+$0;print i}'
1
3
6
10
15
21
28
36
45
55
3) The representation of arrays
The contents in parentheses in an array
hotel [Element 01]=xiaolizi1 - - Call print xiaolizi1 [Element 01] - - xiaolizi1
hotel [element 02]=xiaolizi2 - - Call print xiaolizi2 [element 02] - - xiaolizi2
Array Statistics Command Composition Description:
1) Find out the information to be counted
$1
2) Specify statistics as elements of an array
h[$1]
3) Using statistical formulas to perform operations
h[$1]=h[$1]+1 --- i=i+1
4) Display the result information of the operation
a only looks at the result information of an element.
awk '{h[$1]=h[$1]+1}END{print h["101.226.61.184"]}' access.log 5
b depends on the result information of all elements
awk '{h[$1]=h[$1]+1}END{print h["101.226.61.184"],h["114.94.29.165"]}' access.log
# Streamlined post-command
awk '{h[$1]++}END{for(name in h)print name,h[name]}' access.log
for name in 101.226.61.184 114.94.29.165
print h[$name]
==>
For (name in h) - > echo name = H = first element information
echo name=h = second element information
Description: Loop read array name == read each element name information
cat >>url.txt<<EOF
http://www.etiantian.org/index.html
http://www.etiantian.org/1.html
http://post.etiantian.org/index.html
http://mp3.etiantian.org/index.html
http://www.etiantian.org/3.html
http://post.etiantian.org/2.html
EOF
awk '{h[$1]++}END{for(name in h)print name,h[name]}' access.log
[root@mysql-141 ~]# awk '{h[$1]++}END{for(name in h)print name,h[name]}' access.log
101.226.61.184 5
27.154.190.158 2
218.79.64.76 2
114.94.29.165 1
Step 1: Define array information
awk '{h[$1]}' access.log
Explanation: The elements in an array are the information you focus on the columns to be counted.
Step 2: Statistical calculation and formulation
awk '{h[$1]=h[$1]+1}' access.log
Step 3: Write element loop information
awk '{h[$1]=h[$1]+1}END{for(name in h)}' access.log
Step 4: Output results information
awk '{h[$1]=h[$1]+1}END{for(name in h) print name,h[name]}' access.log