I often use SQL in my work, which has annoying subtle differences and limitations, but after all, it is the cornerstone of the data industry.Therefore, SQL is indispensable to every data worker.Being proficient in SQL means a lot.
SQL is good, but how can you just be satisfied with "good"?Why not proceed further with SQL?
Statements can trigger SQL restrictions, that is, when you look for data from SQL, it looks for and feeds back on specific databases.This is sufficient for many data extraction or simple data manipulation tasks.
But what if there is more demand?
This article will show you how to do it.
Start from the basics
import pyodbc from datetime import datetime classSql: def__init__(self, database, server="XXVIR00012,55000"): # here we are telling python what to connect to (our SQL Server) self.cnxn = pyodbc.connect("Driver={SQL Server Native Client 11.0};" "Server="+server+";" "Database="+database+";" "Trusted_Connection=yes;") # initialise query attribute self.query ="-- {}\n\n-- Made in Python".format(datetime.now() .strftime("%d/%m/%Y"))
This code is the basis for operating an MS SQL server.As long as you write this code, connecting to SQL through Python only requires:
sql = Sql('database123')
Easy, right?Several things happened at the same time, and the code will be dissected below.class Sql:
First of all, note that this code is contained in a class.The author finds this logical because this particular database has been added or removed in this format.If you see its working process, your ideas will be clearer.
Initialization class:
def __init__(self, database,server="XXVIR00012,55000"):
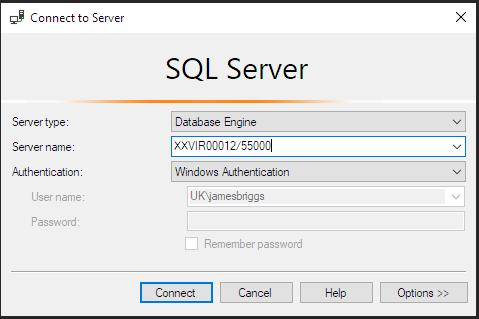
Since the author and colleagues almost always connect to the same server, the author sets the name of this generic browser as the default parameter server.
The name of the server can be found in the Connect to Server dialog box or at the top of the window in MS SQL Server Management Studio:
Next, connect SQL:
self.cnxn =pyodbc.connect("Driver={SQL Server Native Client 11.0};" "Server="+self.server+";" "Database="+self.database+";" "Trusted_Connection=yes;")
The pyodbc module makes this step extremely simple.Just transition the connection string to the pyodbc.connect(...) function and click here for more details.
Finally, the author usually writes a query string in the sql class, which updates with each query passed to the class:
self.query = "-- {}\n\n--Made in Python".format(datetime.now() .strftime("%d/%m/%Y"))
This makes it easier to record code, but it also makes the output more readable and more comfortable for others to read.
Note that in the following code snippet, the author will no longer update the self.query part of the code.
Block
Some of the important functions are very useful and I use them almost every day.These functions focus on passing data in or out of the database.
Start with the following diagram file directory:
For the current project, you need to:
- Import files into SQL
- Merge it into a single table
- Flexible creation of multiple tables based on categories in columns
As SQL classes are enriched, they can be much easier to follow:
import sys sys.path.insert(0, r'C:\\User\medium\pysqlplus\lib') import os from data importSql sql =Sql('database123') # initialise the Sql object directory =r'C:\\User\medium\data\\' # this is where our generic data is stored file_list = os.listdir(directory) # get a list of all files for file in file_list: # loop to import files to sql df = pd.read_csv(directory+file) # read file to dataframe sql.push_dataframe(df, file[:-4]) # now we convert our file_list names into the table names we have imported to SQL table_names = [x[:-4] for x in file_list] sql.union(table_names, 'generic_jan') # union our files into one new table called 'generic_jan' sql.drop(table_names) # drop our original tables as we now have full table # get list of categories in colX, eg ['hr', 'finance', 'tech', 'c_suite'] sets =list(sql.manual("SELECT colX AS 'category' FROM generic_jan GROUP BY colX", response=True)['category']) for category in sets: sql.manual("SELECT * INTO generic_jan_"+category+" FROM generic_jan WHERE colX = '"+category+"'")
Start from scratch.
Stacked data structure
defpush_dataframe(self, data, table="raw_data", batchsize=500): # create execution cursor cursor = self.cnxn.cursor() # activate fast execute cursor.fast_executemany =True # create create table statement query ="CREATE TABLE ["+ table +"] (\n" # iterate through each column to be included in create table statement for i inrange(len(list(data))): query +="\t[{}] varchar(255)".format(list(data)[i]) # add column (everything is varchar for now) # append correct connection/end statement code if i !=len(list(data))-1: query +=",\n" else: query +="\n);" cursor.execute(query) # execute the create table statement self.cnxn.commit() # commit changes # append query to our SQL code logger self.query += ("\n\n-- create table\n"+ query) # insert the data in batches query = ("INSERT INTO [{}] ({})\n".format(table, '['+'], [' # get columns .join(list(data)) +']') + "VALUES\n(?{})".format(", ?"*(len(list(data))-1))) # insert data into target table in batches of 'batchsize' for i inrange(0, len(data), batchsize): if i+batchsize >len(data): batch = data[i: len(data)].values.tolist() else: batch = data[i: i+batchsize].values.tolist() # execute batch insert cursor.executemany(query, batch) # commit insert to SQL Server self.cnxn.commit()
This function is included in the SQL class and makes it easy to insert the Pandas dataframe into the SQL database.
It is useful when you need to upload a large number of files.However, the real reason Python can insert data into SQL is because of its flexibility.
It's really frustrating to be able to insert specific tags in SQL across a dozen Excel workbooks.But there's Python on the side.Now a function has been built that reads tags using Python and inserts tags into SQL.
Manual (function)
defmanual(self, query, response=False): cursor = self.cnxn.cursor() # create execution cursor if response: returnread_sql(query, self.cnxn) # get sql query output to dataframe try: cursor.execute(query) # execute except pyodbc.ProgrammingErroras error: print("Warning:\n{}".format(error)) # print error as a warning self.cnxn.commit() # commit query to SQL Server return"Query complete."
This function is actually used in the union and drop functions.Only make it as easy as possible to process SQL code.
The response parameter extracts the query output to the DataFrame.The colX in the generic_jan table can be used to extract all unique values as follows:
sets =list(sql.manual("SELECT colX AS 'category' FROM generic_jan GROUP BYcolX", response=True)['category'])
Union (function)
Build the manual function, and create the union function is simple:
defunion(self, table_list, name="union", join="UNION"): # initialise the query query ="SELECT * INTO ["+name+"] FROM (\n" # build the SQL query query +=f'\n{join}\n'.join( [f'SELECT [{x}].* FROM [{x}]'for x in table_list] ) query +=") x" # add end of query self.manual(query, fast=True) # fast execute
Creating a union function is simply a looping reference to the table name proposed by table_list to construct a UNION function query for a given table name.It is then processed with self.manual(query).
Drop (function)
It is possible to upload a large number of tables to the SQL server.While feasible, it can quickly overload the database.To solve this problem, you need to create a drop function:
defdrop(self, tables): # check if single or list ifisinstance(tables, str): # if single string, convert to single item in list for for-loop tables = [tables] for table in tables: # check for pre-existing table and delete if present query = ("IF OBJECT_ID ('["+table+"]', 'U') IS NOT NULL " "DROP TABLE ["+table+"]") self.manual(query) # execute
Similarly, this function is also because the manual function is extremely simple.Operators can choose to enter characters into tables, delete individual tables, or provide tables with a list name to delete multiple tables.
When these very simple functions are combined, you can take advantage of Python to greatly enrich the functionality of SQL.
The author himself uses this method almost every day, which is simple and effective.
Hope you can help other users find a way to incorporate Python into their SQL paths. Thank you for reading!
Text source network, for learning purposes only. If there is infringement, contact for deletion.
I've put together good technical articles and a summary of my experience in my public number, Python Circle.
Don't panic, I have a set of learning materials, including 40 + e-books, 600 + teaching videos, involving Python basics, crawlers, frames, data analysis, machine learning, etc. Don't be afraid you won't learn!There are also learning and communication groups to learn and progress together ~
