I won't talk about the process of installing Python and Selenium. Let's go directly to the code below. The goal is to download all the documents (PDF format) of a certain issue of a journal on HowNet. Here with Educational research Take this journal as an example, Download all the documents in issue 5 of 2021.
1 download Chrome's Webdriver
To manipulate the browser with Selenium, you first need to download the WebDriver corresponding to the browser. The WebDriver corresponding to Chrome can be
Chrome webdriver download address
Note that the browser version and WebDriver version must match, otherwise an error may be reported. The version of Google browser is set
→
\rightarrow
→ about Chrome.
2 code
2.1 import related packages
from selenium import webdriver from selenium.webdriver.common.by import By import time
If the Selenium version used is Selenium 4, line 2 is required. If it is an earlier version, you can not.
2.2 setting WebDriver
path='D:\Webdriver\chromedriver_win32\chromedriver'
my_browser=webdriver.Chrome(executable_path=path)
my_browser.implicitly_wait(15)
my_browser.get('https://navi.cnki.net/knavi/journals/WGJY/detail?uniplatform=NZKPT')
There are several points to note:
- path refers to the directory where the downloaded webdriver is located. For example, I'm here in'd: \ webdriver \ chromedriver '_ Win32 ', but the directory needs to be followed by webdriver's file name without suffix. exe. For example, my webdriver's file name was originally' chromedriver.exe ', and in the code, it can only write'd: \ webdriver \ chromedriver'_ Win32 \ chromedriver ', without. exe!
- This is implicitly_wait() is the number of seconds that the program needs to wait during operation. Specifically, the execution speed of the program is very fast, but the loading of web pages takes time. For example, if you use a program to find an element called 'button' on a web page, the program may have completed the search process before the web page is loaded, but at this time, because your web page is not loaded, it must not be found and an error will be reported. This is implicitly_wait(15) means that if the program cannot find the specified element on the web page, it will look for it every half a second. If it cannot find it within 15 seconds, it will report an error.
- ‘ https://navi.cnki.net/knavi/journals/WGJY/detail?uniplatform=NZKPT ’This is the website of this journal. I tested it in the environment of education network, so I can download it directly. The general network can't be downloaded without registering and purchasing.
Hello! This is the welcome page displayed by the Markdown editor for the first time. If you want to learn how to use the Markdown editor, you can read this article carefully to understand the basic grammar of Markdown.
2.3 find the corresponding element of the journal name on the web page
This journal website is like this
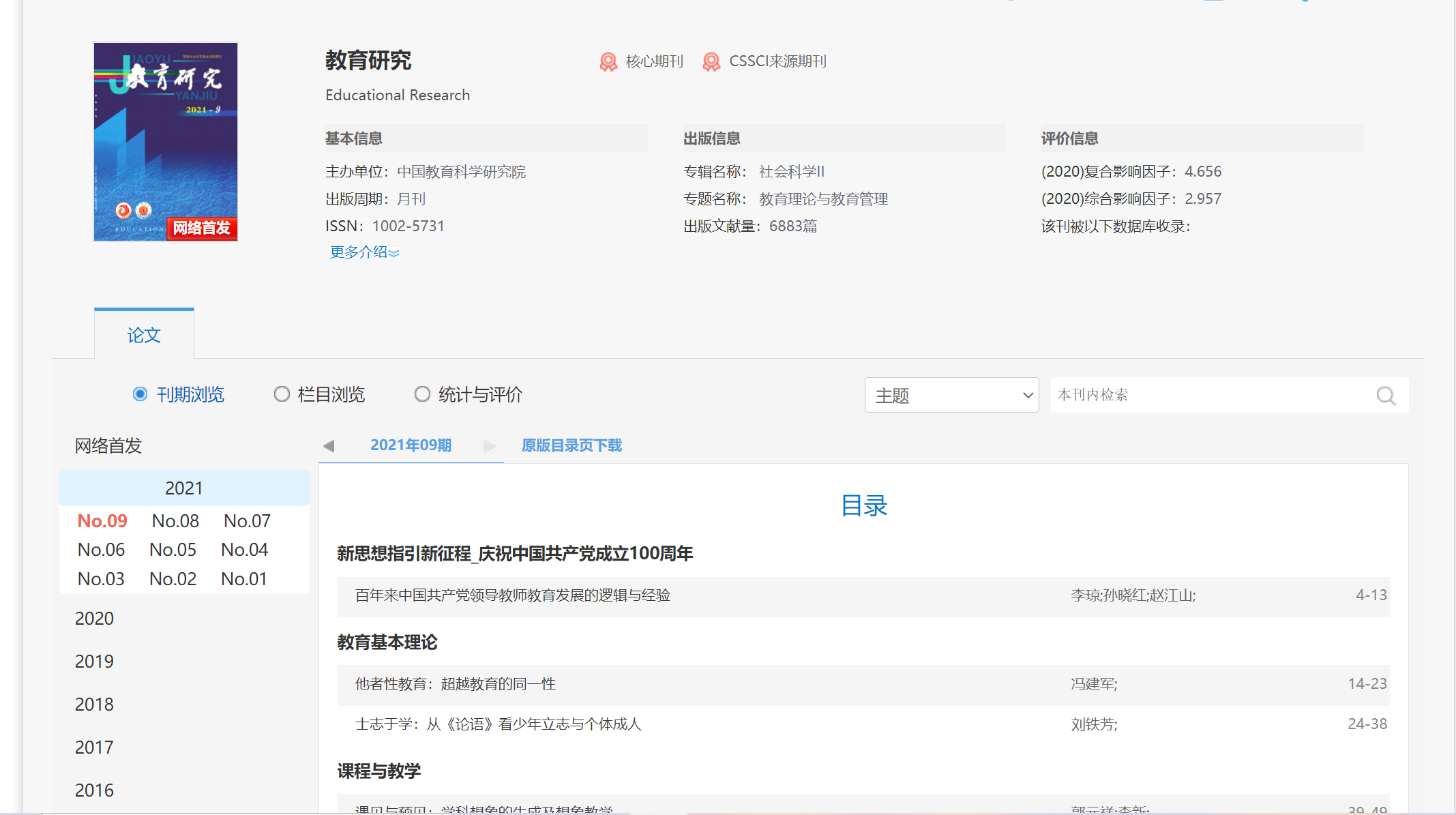
The code is as follows
year='2021'; vol='05'; # Click the corresponding year and number of issues my_browser.find_element(By.ID,'yq'+year+vol).click(); # Wait 2s, wait until the web page is loaded time.sleep(2) # Find the box where the journal is located paperList = my_browser.find_element(By.ID,'CataLogContent'); # Find the element corresponding to the journal name in this box papers=paperList.find_elements(By.CSS_SELECTOR,'.name > a'); # Print out the number of periodicals len(papers)
2.4 downloading journals
The steps I download here are as follows,
- Open the download page of all journals;
- Turn off the page where the first journal is located;
- Click the "PDF download" button on each download page in turn.
The code is as follows:
# Click to open all journal download pages
for paper in papers:
paper.click();
# Close the original window
my_browser.close();
# Record handles to all windows
currentHandles=my_browser.window_handles;
# Click the PDF download of each window in turn
for my_handle in currentHandles:
my_browser.switch_to_window(my_handle);
pdfDown = my_browser.find_element_by_id('pdfDown')
time.sleep(3); # HowNet's response is slow. It needs to wait a few seconds
pdfDown.click();
time.sleep(5); # HowNet's response is slow. It needs to wait a few seconds
When the download is complete, close the browser.