Auto-encoder
Auto-encoder input feed-forward neural network is a kind of neural network, which uses the idea of sparse coding. Its goal is to reconstruct input by extracting high-order features, not just simple replication. Auto-encoder used to be mainly used for dimensionality reduction and feature extraction, but now it has been extended to generate models.
The model architecture of Auto-encoder can be simply expressed as:
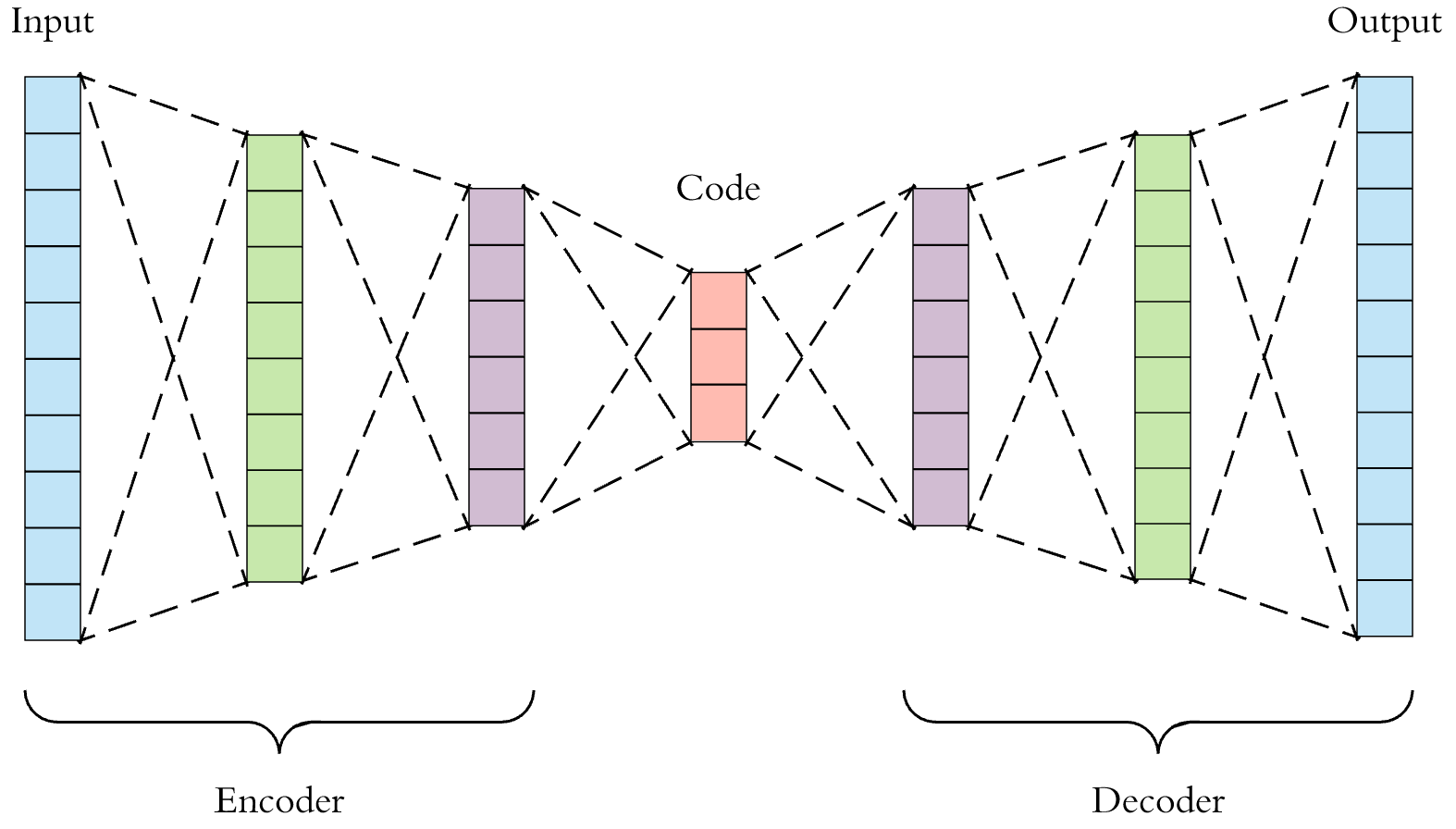
The implementation process is as follows:
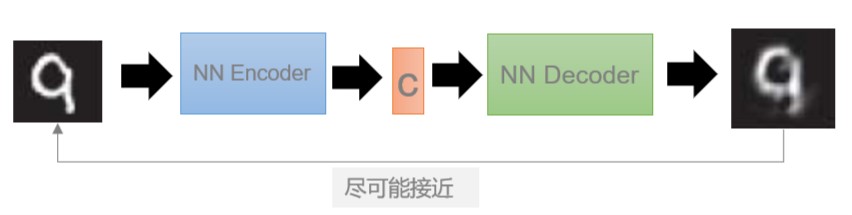
The idea of Auto-encoder is very simple. Let's see how to implement it in code. Tenorflow 2.0 is used here.
Firstly, according to the network model of auto-encoder, we need to design an encoder to get latent code, and then reconstruct it as input of decoder. The goal is to hope that the closer the reconstructed result is to the input of encoder, the better.
In this paper, we use Sequential in tensorflow.keras to construct the model. At the same time, we need to define the encoding and decoding process, so we can get an auto-encoder based on convolution network.
# auto-encoder class auto_encoder(keras.Model): def __init__(self,latent_dim): super(auto_encoder,self).__init__() self.latent_dim = latent_dim self.encoder = keras.Sequential([ keras.layers.InputLayer(input_shape = (28,28,1)), keras.layers.Conv2D(filters = 32,kernel_size = 3,strides = (2,2),activation = 'relu'), keras.layers.Conv2D(filters = 32,kernel_size = 3,strides = (2,2),activation = 'relu'), keras.layers.Flatten(), keras.layers.Dense(self.latent_dim) ]) self.decoder = keras.Sequential([ keras.layers.InputLayer(input_shape = (latent_dim,)), keras.layers.Dense(units = 7 * 7 * 32,activation = 'relu'), keras.layers.Reshape(target_shape = (7,7,32)), keras.layers.Conv2DTranspose( filters = 64, kernel_size = 3, strides = (2,2), padding = "SAME", activation = 'relu'), keras.layers.Conv2DTranspose( filters = 32, kernel_size = 3, strides = (2,2), padding = "SAME", activation = 'relu'), keras.layers.Conv2DTranspose( filters = 1, kernel_size = 3, strides = (1,1), padding = "SAME"), keras.layers.Conv2DTranspose( filters = 1, kernel_size = 3, strides = (1,1), padding = "SAME", activation = 'sigmoid'), ]) def encode(self,x): return self.encoder(x) def decode(self,z): return self.decoder(z)
After defining the model, we need to define its training process. According to the idea of the model, the loss function can be obtained by using Binary Crossentropy. By comparing the input and reconstructed results, the loss can be obtained. Then it can be used to calculate the gradient and update the parameters by back propagation.
# training class train: @staticmethod def compute_loss(model,x): loss_object = keras.losses.BinaryCrossentropy() z = model.encode(x) x_logits = model.decode(z) loss = loss_object(x,x_logits) return loss @staticmethod def compute_gradient(model,x): with tf.GradientTape() as tape: loss = train.compute_loss(model,x) gradient = tape.gradient(loss,model.trainable_variables) return gradient,loss @staticmethod def update(optimizer,gradients,variables): optimizer.apply_gradients(zip(gradients,variables))
After training, we first read a batch of images from MNIST data set, and then pass them into compute_gradient() to get the gradient and loss. Finally, we can get the parameters closer.
# begin training def begin(): train_dataset,test_dataset = load_data(batch_size) model = auto_encoder(latent_dim) optimizer = keras.optimizers.Adam(lr) for epoch in range(num_epochs): start = time.time() last_loss = 0 for train_x,_ in train_dataset: gradients,loss = train.compute_gradient(model,train_x) train.update(optimizer,gradients,model.trainable_variables) last_loss = loss if epoch % 10 == 0: print ('Epoch {},loss: {},Remaining Time at This Epoch:{:.2f}'.format( epoch,last_loss,time.time()-start)) end = time.time() print ('Total time is : %d',(end - start))
The experimental results are as follows:
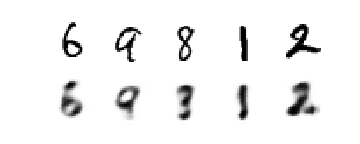
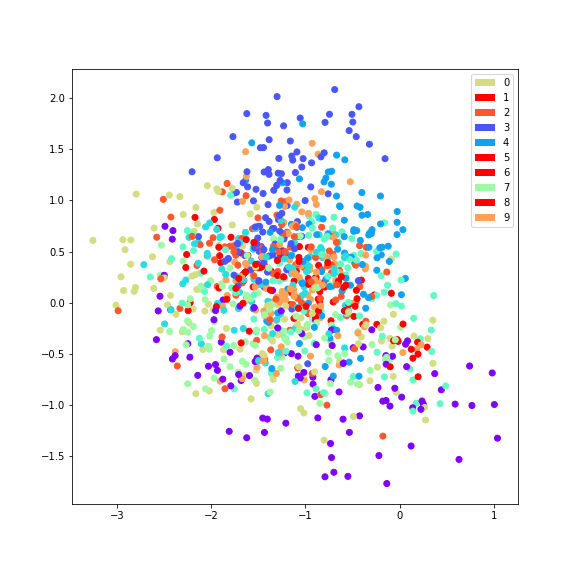
But auto-encoder's compression ability only applies to new samples similar to training samples, and if encoder and decoder's ability is too strong, then the model completely realizes simple memory, rather than expecting latent code to represent important input information.
Denoising Auto-encoder(DAE)
In order to prevent the model from being a simple memory, one way is to add noise to the input and train it to get a noise-free input, where the noise can be sampled from the noise in the Gauss distribution, or it can discard a feature of the input layer immediately, similar to dropout.
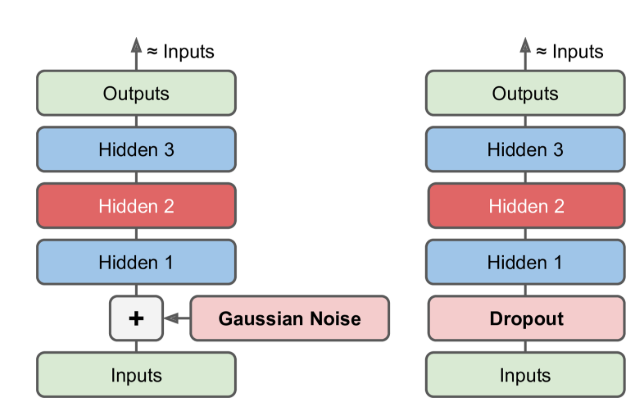
In addition, there are many types of auto-encoders, such as Contrative Auto-encoder(CAE), Stacked Auto-encoder(SAE), and other models of networks combined with auto-encoder.
Complete implementation code:
# -*- coding: utf-8 -*- """ Created on Tue Sep 3 23:53:28 2019 @author: dyliang """ from __future__ import absolute_import,print_function,division import tensorflow as tf import tensorflow.keras as keras import numpy as np import matplotlib.pyplot as plt import time import plot # auto-encoder class auto_encoder(keras.Model): def __init__(self,latent_dim): super(auto_encoder,self).__init__() self.latent_dim = latent_dim self.encoder = keras.Sequential([ keras.layers.InputLayer(input_shape = (28,28,1)), keras.layers.Conv2D(filters = 32,kernel_size = 3,strides = (2,2),activation = 'relu'), keras.layers.Conv2D(filters = 32,kernel_size = 3,strides = (2,2),activation = 'relu'), keras.layers.Flatten(), keras.layers.Dense(self.latent_dim) ]) self.decoder = keras.Sequential([ keras.layers.InputLayer(input_shape = (latent_dim,)), keras.layers.Dense(units = 7 * 7 * 32,activation = 'relu'), keras.layers.Reshape(target_shape = (7,7,32)), keras.layers.Conv2DTranspose( filters = 64, kernel_size = 3, strides = (2,2), padding = "SAME", activation = 'relu'), keras.layers.Conv2DTranspose( filters = 32, kernel_size = 3, strides = (2,2), padding = "SAME", activation = 'relu'), keras.layers.Conv2DTranspose( filters = 1, kernel_size = 3, strides = (1,1), padding = "SAME"), keras.layers.Conv2DTranspose( filters = 1, kernel_size = 3, strides = (1,1), padding = "SAME", activation = 'sigmoid'), ]) def encode(self,x): return self.encoder(x) def decode(self,z): return self.decoder(z) # training class train: @staticmethod def compute_loss(model,x): loss_object = keras.losses.BinaryCrossentropy() z = model.encode(x) x_logits = model.decode(z) loss = loss_object(x,x_logits) return loss @staticmethod def compute_gradient(model,x): with tf.GradientTape() as tape: loss = train.compute_loss(model,x) gradient = tape.gradient(loss,model.trainable_variables) return gradient,loss @staticmethod def update(optimizer,gradients,variables): optimizer.apply_gradients(zip(gradients,variables)) # hpy latent_dim = 100 num_epochs = 10 lr = 1e-4 batch_size = 1000 train_buf = 60000 test_buf = 10000 # load data def load_data(batch_size): mnist = keras.datasets.mnist (train_data,train_labels),(test_data,test_labels) = mnist.load_data() train_data = train_data.reshape(train_data.shape[0],28,28,1).astype('float32') / 255. test_data = test_data.reshape(test_data.shape[0],28,28,1).astype('float32') / 255. train_data = tf.data.Dataset.from_tensor_slices(train_data).batch(batch_size) train_labels = tf.data.Dataset.from_tensor_slices(train_labels).batch(batch_size) train_dataset = tf.data.Dataset.zip((train_data,train_labels)).shuffle(train_buf) test_data = tf.data.Dataset.from_tensor_slices(test_data).batch(batch_size) test_labels = tf.data.Dataset.from_tensor_slices(test_labels).batch(batch_size) test_dataset = tf.data.Dataset.zip((test_data,test_labels)).shuffle(test_buf) return train_dataset,test_dataset # begin training def begin(): train_dataset,test_dataset = load_data(batch_size) model = auto_encoder(latent_dim) optimizer = keras.optimizers.Adam(lr) for epoch in range(num_epochs): start = time.time() last_loss = 0 for train_x,_ in train_dataset: gradients,loss = train.compute_gradient(model,train_x) train.update(optimizer,gradients,model.trainable_variables) last_loss = loss # if epoch % 10 == 0: print ('Epoch {},loss: {},Remaining Time at This Epoch:{:.2f}'.format( epoch,last_loss,time.time()-start)) plot.plot_AE(model, test_dataset) if __name__ == '__main__': begin()